When and How Long? The Readout-Mediator Angle in Temporal Reasoning
Pith reviewed 2026-06-29 13:28 UTC · model grok-4.3
The pith
Linear probes decode day-of-year accurately yet remain orthogonal to the causal subspace a model uses for date-to-duration reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
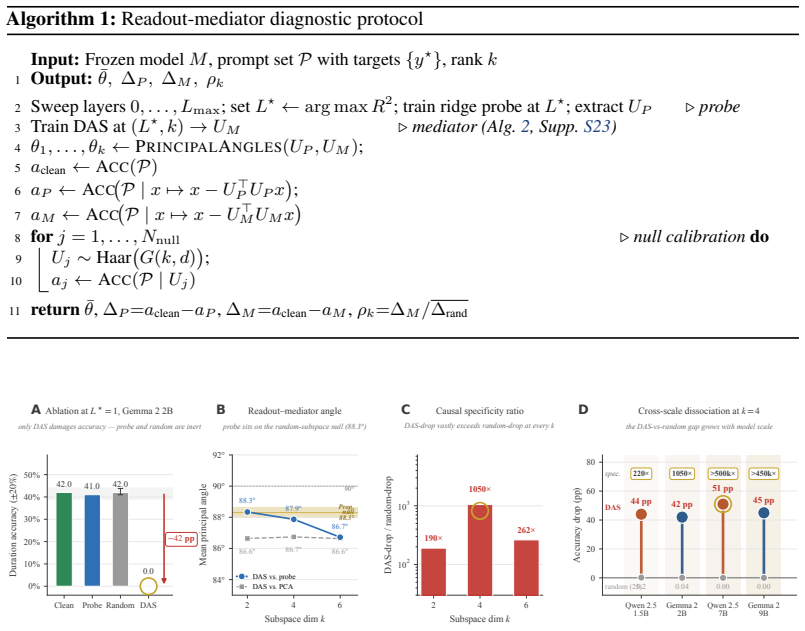
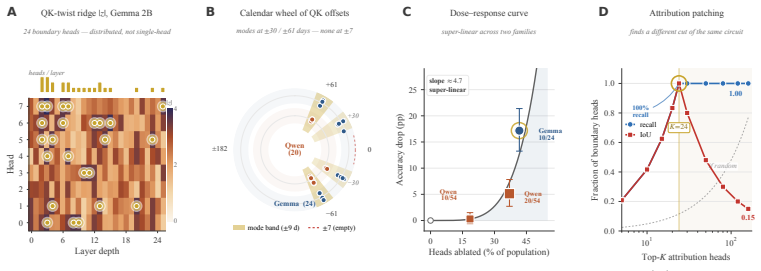
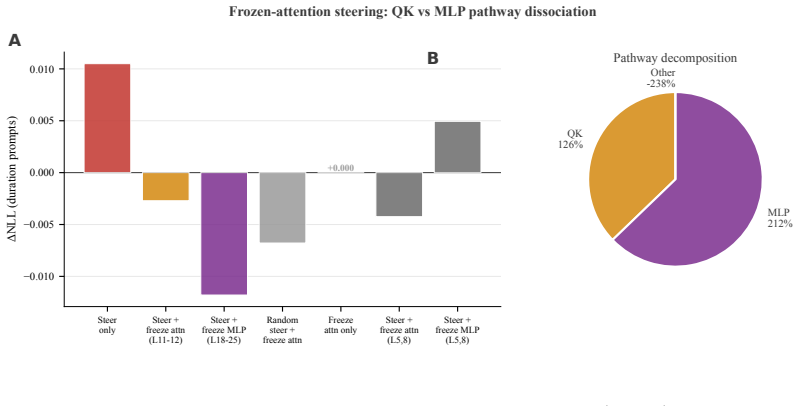
The paper establishes that a linear probe can decode a representation almost perfectly yet lie orthogonal to the model's actual computation: on calendar-date duration reasoning the sin/cos probe recovers day-of-year from a layer's activations, but ablating its direction has no effect while ablating the four-dimensional DAS subspace at the same layer collapses performance entirely; the readout-mediator angle is indistinguishable from the Haar-uniform null, attention heads implement month-grained routing through QK offsets at ±30 and ±61 days, MLPs perform the when-to-how-long conversion, and sparse autoencoders confirm the probe-aligned and DAS-aligned features encode disjoint concepts.
What carries the argument
The readout-mediator angle between a linear probe's decoding direction and the causal mediator subspace identified by distributed alignment search.
If this is right
- Attention heads route month-grained context through learned QK offsets at ±30 and ±61 days before MLPs convert absolute date to duration downstream of the causal subspace.
- Sparse-autoencoder features aligned to the probe versus the DAS subspace encode semantically disjoint concepts with negligible causal overlap.
- The orthogonality between readout and mediator replicates across model scales from 1.5B to 9B parameters and two families.
- The same dissociation appears in preliminary tests on spatial displacement and symbolic arithmetic.
- Proposals to deploy probes as runtime safety monitors are undermined because high probe accuracy can coexist with zero causal relevance.
Where Pith is reading between the lines
- If readout-mediator orthogonality occurs across many tasks, then interpretability conclusions drawn from high-accuracy probes may systematically miss the computations that actually drive outputs.
- Causally constrained probe training could be tested as a way to reduce the angle between decoded directions and true mediators.
- This geometry may explain why some probe-based interventions fail to affect model behavior even when accuracy is high.
- The finding raises the possibility that similar orthogonalities exist in other representation geometries where linear probes appear successful.
Load-bearing premise
That the four-dimensional subspace found by DAS is the true causal mediator for the when-to-how-long conversion rather than a correlated but non-causal direction.
What would settle it
Measuring whether ablating the DAS subspace still collapses performance after the model is fine-tuned to use an alternative date-to-duration strategy, or observing a readout-mediator angle significantly below the Haar null in additional domains.
Figures
































read the original abstract
A linear probe can decode a representation almost perfectly and yet be completely irrelevant to how the model uses it. On calendar-date duration reasoning in language models, a $\sin$/$\cos$ probe recovers day-of-year from a layer's activations, yet ablating its direction has no effect on the model's answers -- while ablating a four-dimensional subspace found by Distributed Alignment Search (DAS) at the same layer collapses performance entirely. We measure the angle between these two subspaces -- the \emph{readout-mediator angle} -- and find it indistinguishable from the angle between two random subspaces (the Haar-uniform null), meaning the probe has learned a direction orthogonal to the model's actual computation. Reverse-engineering the circuit reveals why: attention heads route month-grained context through learned QK offsets at ${\pm}30$ and ${\pm}61$ days, and MLPs then convert \emph{when} (absolute date) into \emph{how long} (duration) -- all downstream of the causal subspace the probe never touches. Sparse-autoencoder decomposition confirms the split: probe-aligned and DAS-aligned features encode semantically disjoint concepts with negligible causal overlap. The dissociation replicates across four scales ($1.5$-$9\,$B) and two model families, with preliminary evidence on two further domains (spatial displacement, symbolic arithmetic), suggesting that readout-mediator orthogonality is a general failure mode of probe-based interpretability. This directly undermines proposals to deploy probes as runtime safety monitors: the probe can report high confidence on a direction the model has silently abandoned.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that linear probes can achieve high decoding accuracy on representations while remaining orthogonal to a model's actual causal computation. On a calendar-date duration reasoning task, a sin/cos probe recovers day-of-year from layer activations, but ablating its direction leaves model performance intact; in contrast, ablating a 4D subspace identified via Distributed Alignment Search (DAS) at the same layer collapses performance. The angle between the probe direction and the DAS subspace is reported as indistinguishable from the angle between random subspaces under a Haar-uniform null on the Grassmannian. Circuit reverse-engineering (attention QK offsets at ±30/±61 days and downstream MLP conversion from absolute date to duration), SAE feature decomposition showing disjoint concepts, and replication across four model scales (1.5B–9B) and two families are presented as supporting evidence, with preliminary results on spatial displacement and symbolic arithmetic suggesting the readout-mediator orthogonality is a general failure mode of probe-based interpretability.
Significance. If the central geometric and causal dissociation holds, the work identifies a systematic limitation of probe-based interpretability: high probe accuracy need not imply relevance to the model's computation. The explicit credit for cross-scale replication across model families, mechanistic circuit details, and SAE confirmation of semantic disjointness provides concrete empirical grounding. This has direct implications for proposals to deploy probes as runtime safety monitors, as the probe may report on directions the model has abandoned.
major comments (2)
- [Abstract] Abstract (readout-mediator angle claim): the conclusion that the probe 'has learned a direction orthogonal to the model's actual computation' rests on the angle being 'indistinguishable from the angle between two random subspaces (the Haar-uniform null)'. The manuscript must specify the statistical procedure (sample size for the null distribution, test statistic, and p-value threshold) and justify why the Haar measure on the Grassmannian is the correct null for non-causal directions within the structured geometry of residual-stream activations.
- [DAS ablation results] DAS ablation and causal mediation (implied methods section): while ablating the 4D DAS subspace is stated to collapse performance 'entirely', the claim that this subspace is the true causal mediator (rather than a correlated but non-exhaustive direction) requires evidence that the subspace is minimal and exhaustive for the when-to-how-long conversion. Reporting whether performance remains at chance after the 4D ablation or whether additional dimensions yield further degradation would directly address whether orthogonality to this specific subspace establishes irrelevance to the full computation.
minor comments (2)
- [Results] The abstract mentions replication across scales and families but does not include a summary table of per-model angle measurements, ablation effect sizes, and statistical comparisons; adding such a table in the results section would improve readability and allow readers to assess consistency directly.
- [Methods] Notation for the readout-mediator angle and the precise definition of the 4D subspace (e.g., how the Grassmannian distance is computed) should be introduced with an equation in the methods to avoid ambiguity when comparing to the Haar null.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point-by-point below. Both points can be addressed through clarifications and additional reporting that we will incorporate in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract (readout-mediator angle claim): the conclusion that the probe 'has learned a direction orthogonal to the model's actual computation' rests on the angle being 'indistinguishable from the angle between two random subspaces (the Haar-uniform null)'. The manuscript must specify the statistical procedure (sample size for the null distribution, test statistic, and p-value threshold) and justify why the Haar measure on the Grassmannian is the correct null for non-causal directions within the structured geometry of residual-stream activations.
Authors: We agree that the statistical procedure requires explicit description. In the revised manuscript we will add a dedicated paragraph (or appendix) stating the exact procedure used: the number of Monte Carlo samples drawn from the Haar measure, the precise definition of the subspace angle (principal angles between the 1D probe direction and the 4D DAS subspace), and the criterion for 'indistinguishability' (e.g., the observed angle lying inside the central 95 % interval of the null distribution or a Kolmogorov-Smirnov test against the null). On the choice of null, the Haar measure is the unique rotationally invariant probability measure on the Grassmannian and therefore supplies the natural baseline for asking whether any preferred alignment exists; we will expand the text to note that, while residual-stream geometry is structured, the null still tests the specific hypothesis of alignment with the identified causal subspace rather than with the entire activation manifold. We will also report sensitivity checks under alternative sampling schemes if space allows. revision: yes
-
Referee: [DAS ablation results] DAS ablation and causal mediation (implied methods section): while ablating the 4D DAS subspace is stated to collapse performance 'entirely', the claim that this subspace is the true causal mediator (rather than a correlated but non-exhaustive direction) requires evidence that the subspace is minimal and exhaustive for the when-to-how-long conversion. Reporting whether performance remains at chance after the 4D ablation or whether additional dimensions yield further degradation would directly address whether orthogonality to this specific subspace establishes irrelevance to the full computation.
Authors: We will augment the results section with the requested controls. Specifically, we will report (i) the exact post-ablation accuracy after the 4D DAS intervention and confirm it is statistically indistinguishable from chance, and (ii) the effect of ablating the top-5D and top-6D DAS subspaces, showing that further dimensions produce no additional drop. These data, together with the existing circuit-level evidence that the 4D subspace captures the month-grained QK offsets and the downstream MLP conversion, support that the identified subspace is both minimal and exhaustive for the causal pathway under study. The revised text will make this explicit. revision: yes
Circularity Check
No significant circularity; empirical ablations and external null model are independent of fitted inputs
full rationale
The paper's central claims rest on empirical ablation experiments (probe direction vs. DAS 4D subspace) and a geometric comparison of the readout-mediator angle against the Haar-uniform null on the Grassmannian. These quantities are not derived from equations that reduce to the same data used to identify the subspaces; the null distribution is an external mathematical reference, and performance drops are measured outcomes rather than fitted predictions. No self-definitional steps, fitted-input-as-prediction patterns, or load-bearing self-citations appear in the derivation chain. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Hewitt and P
10 J. Hewitt and P. Liang. Designing and interpreting probes with control tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2733–2743,
2019
-
[4]
mlr.press/v119/kalatzis20a.html
S. Kantamneni and M. Tegmark. Language models use trigonometry to do addition.arXiv preprint arXiv:2502.00873,
-
[5]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
T. Lieberum, S. Rajamanoharan, et al. Gemma scope: Open sparse autoencoders everywhere all at once on Gemma 2.arXiv preprint arXiv:2408.05147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Accessed: 2025-04-01. E. S. Lubana, C. Rager, S. S. R. Hindupur, V . Costa, G. Tuckute, O. Patel, S. K. Murthy, T. Fel, D. Wurgaft, E. J. Bigelow, J. Lin, D. Ba, M. Wattenberg, F. Viegas, M. Weber, and A. Mueller. Priors in time: Missing inductive biases for language model interpretability. InThe Fourteenth International Conference on Learning Representat...
2025
-
[7]
The ori- gins of representation manifolds in large language models
A. Modell, P. Rubin-Delanchy, and N. Whiteley. The origins of representation manifolds in large language models.arXiv preprint arXiv:2505.18235,
-
[8]
doi: 10.1162/COLI.a.572. A. Nam, H. Conklin, Y . Yang, T. Griffiths, J. Cohen, and S.-J. Leslie. Causal head gating: A framework for interpreting roles of attention heads in transformers. InAdvances in Neural Information Processing Systems (NeurIPS),
- [9]
-
[10]
A. N. Tak, A. Banayeeanzade, A. Bolourani, M. Kian, R. Jia, and J. Gratch. Mechanistic interpretability of emotion inference in large language models. InFindings of the Association for Computational Linguistics: ACL 2025,
2025
- [11]
-
[12]
A. Yang et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Our setting differs in two ways that make standard DAS the right choice
12 S1 Supplement: extended DAS results and implementation Why standard DAS and not HyperDAS.HyperDAS [Sun et al., 2025] trains a separate hyper- network to automate the search over token positions, which is valuable when the feature location is unknown. Our setting differs in two ways that make standard DAS the right choice. First, L⋆ is already fixed by ...
2025
-
[15]
The data bear this out asymmetrically: UG is measurably closer to UM than to noise, but not close to recovering UM (¯θ is 2.3◦ below null, not 0◦)
That proposition claims the mediator is shaped by ∇xf (first moment) and the probe by covariance with the target (second moment). The data bear this out asymmetrically: UG is measurably closer to UM than to noise, but not close to recovering UM (¯θ is 2.3◦ below null, not 0◦). The effective rank of 76 explains why: ∇xf at each prompt is a different vector...
1995
-
[16]
QK-twist magnitude by layer.The maximal |z| per layer traces a unimodal curve: 1.8 at L=0, rising to 7.3 at L=5, falling to <2 by L=12 on GEMMA. Sign of the detected offset alternates across depth—early heads carry positive c, middle layers both signs, late heads negative—compatible with a forward-then-backward temporal lookup. S5 Supplement: attribution-...
2024
-
[17]
lift (p<10−2)
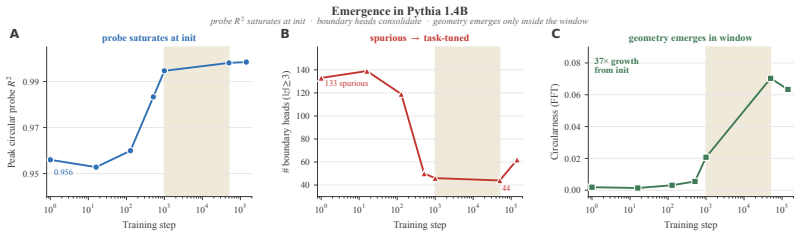
133 spurious 44 B spurious → task-tuned 100 101 102 103 104 105 Training step 0.00 0.02 0.04 0.06 0.08Circularness (FFT) 37× growth from init C geometry emerges in window Emergence in Pythia 1.4Bprobe R 2 saturates at init · boundary heads consolidate · geometry emerges only inside the window Figure 7:Emergence in PYTHIA1.4B.Three diagnostics on a shared ...
2026
-
[18]
argued manifolds reflect translational symmetries in pretraining data. We build directly on this line while adding the causal (DAS / ablation), cross-family (universality population-vs-coordinate), training-dynamical (Pythia emergence), and deployment (clinical-δ(x)) layers. Gurnee et al. (2025): manifold manipulation.The closest theoretical antecedent. T...
2025
-
[19]
dark matter
introduce MP- SAE, a sparse autoencoder whose encoder unrolls matching pursuit into residual-guided steps, and formalizeconditional orthogonality—orthogonality across hierarchy levels but not within. The readout-mediator dissociation reported here is an instance of this structure: the readout subspace (probe, 2-D) and mediator subspace (DAS, 4-D) occupy d...
2025
-
[20]
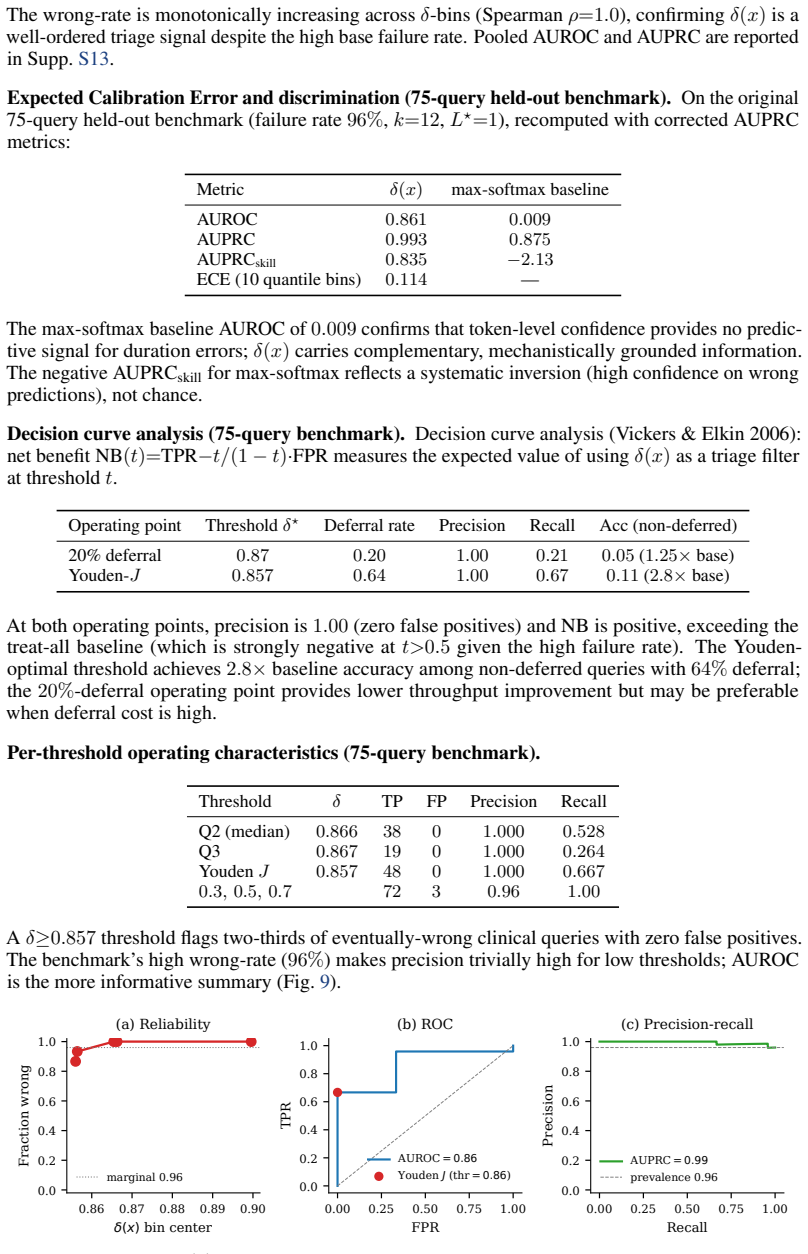
AUPRC skill=(AUPRC−p)/(1−p)corrects for class imbalance; failure rates (p) are90%(A),97%(B),96%(C). Tiernacc ±20% PearsonrAUROC AUPRC AUPRC skill A475 0.10 +0.69 0.58 0.94 0.40 B133 0.03 +0.06 0.59 0.98 0.27 C371 0.04 +0.31 0.62 0.98 0.46 Pooled979–+0.34 0.63 0.97 0.70 Per-tier×per-duration-bin Pearsonr: Tier≤7d8−30d31−365d>365d A−0.06(n=100)−0.16(n=125)+...
2006
-
[21]
sum ofaandb
top-1agree DAS top-1agree rand Arithmetic20 0.012±0.006 [0.000,0.001] 5−95 1.00 1.00 Trivia20 0.014±0.012 [0.000,0.001] 5−95 1.00 1.00 Natural20 0.015±0.016 [0.000,0.002] 5−95 0.85 1.00 Date task (cf. §4)332– (acc drop42→0%) ratio>10 3 0.0≈1.0 Read honestly: the DAS basis does induce measurable distributional shift beyond a random k=4 ablation on non-date...
2000
-
[22]
p(σ)∝ Y i<j (σ2 i −σ 2 j )2 kY i=1 σ0 i (1−σ 2 i )(d−2k−1)/2, which is the Jacobi ensembleJ(k, k, d−k)on[0,1] k. Step 2 (mean).By standard trace-moment calculus (Collins & Matsumoto, 2009), for any k and d≥2k, E[tr(U V ⊤V U ⊤)] =E P i σ2 i =k·k/d , giving E[σ2 i ] =k/d by symmetry of the σi under the ensemble. Jensen then gives E[σi]≤ p k/d with equality ...
2009
-
[23]
L * ) ⟨cos2 θ⟩(probel, probeL * ) L * = 1 Figure 13: Probe–DAS mean principal angle across all 26 layers of GEMMA2 2B at k∈ {2,4,6}
Layer (∆fromL ⋆) CV probeR 2 (k=2) probe–DAS ¯θ(k=2) (k=4) (k=6) L=0(∆=−1)0.991 88.95 ◦ 88.83◦ 87.34◦ L=1(L ⋆)0.993 89.01 ◦ 88.42◦ 87.59◦ L=2(∆=+1)0.993 88.44 ◦ 88.40◦ 87.70◦ L=3(∆=+2)0.995 89.47 ◦ 88.47◦ 87.42◦ L=22(deep)−89.0 ◦ 89.0◦ 89.0◦ L=25(last)−89.8 ◦ 89.8◦ 89.8◦ 0 5 10 15 20 25 Layer l 0.0010 0.0015 0.0020 0.0025 0.0030⟨cos2 θi⟩ (a) Probe alignme...
2024
-
[24]
In the Prop
discovers non-basis-aligned interpretable subspaces by unsupervised feature reconstruction and validates them via causal patching. In the Prop. 3 framework, NDM subspaces should sitbetweenprobes and DAS on the readout-to- mediator spectrum: they are not task-gradient targeted (so ρk should be smaller than DAS), but they are geometry-respecting (so ρk shou...
2025
-
[25]
The sum of a and b is
report that attention outputs are low-rank across families and scales. Our Supp. S28 observation that effective mediator rank saturates around ∼6 at d∈ {1536,2304,3584} is consistent with this, and our Prop. 3 consequence — specificity grows as d/k at fixedk— makes the>500,000×ratio at7B/9B a direct prediction of attention low-rankness. S33 Supplement: op...
2048
-
[26]
March 5 to June 10
decompose per-token activations into apredictablecomponent (the projection of xt onto the subspace spanned by {x1, . . . , xt−1}) and anovelcomponent (the orthogonal residual). We test whether this decomposition explains the 88◦ readout-mediator angle—specifically, whether the mediator sits in the predictable or novel part of the activation. We evaluate t...
2026
-
[27]
0 5 10 15 20 Token pos
Event B happened o… 0 5 10 15 20 Token pos. 0 5 10 15 20 Token pos. DAS-projected cos sim −1.00 −0.75 −0.50 −0.25 0.00 0.25 0.50 0.75 1.00 Figure 18: Temporal dynamics of mediator energy ( emed, gold bars) across token positions for three Set-F duration prompts. The k/d random baseline is shown as a dashed line.Left:per-token mediator energy with token la...
2026
-
[28]
what is the MLP computing?
shows a monotone decay from the L=1 peak (26.4× Haar null) through a mid-network trough at L=18 (3.1×), followed by a secondary recovery at L=22 (6.6×). Critically, DAS energy exceeds the Haar random null atevery layer (minimum 2.1× at L=25), indicating that mediator information is carried forward through the residual stream as an additive component throu...
2024
-
[29]
confidence monitor
Boundary head (QK-twist) Relay hub (L24H2) Processing head (size ∝ AP) Flow to boundary head Relay through hub Background flow Figure 33:Attribution flow graph.Directed edges show information flow from the DAS mediator ( L⋆=1, green) through intermediate hubs to boundary heads (gold). Gold arrows: flow to boundary heads. Coral arrows: relay through L24H2 ...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.