Scalable AI-Driven Analytics for User Engagement and Stance Detection on Social Media
Pith reviewed 2026-06-29 00:26 UTC · model grok-4.3
The pith
Conspiracy videos draw up to 70 percent of total user engagement in their first week after upload.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A scalable service framework combining data ingestion, topic modelling, sentiment analysis, and stance detection processes over 7 million comments from nearly 50,000 conspiracy-related YouTube videos. The analysis shows conspiracy content attracts up to 70 percent of total user engagement within the first week and that a majority of users express favourable positions toward the narratives, with a small set of highly active users driving disproportionate engagement across channels.
What carries the argument
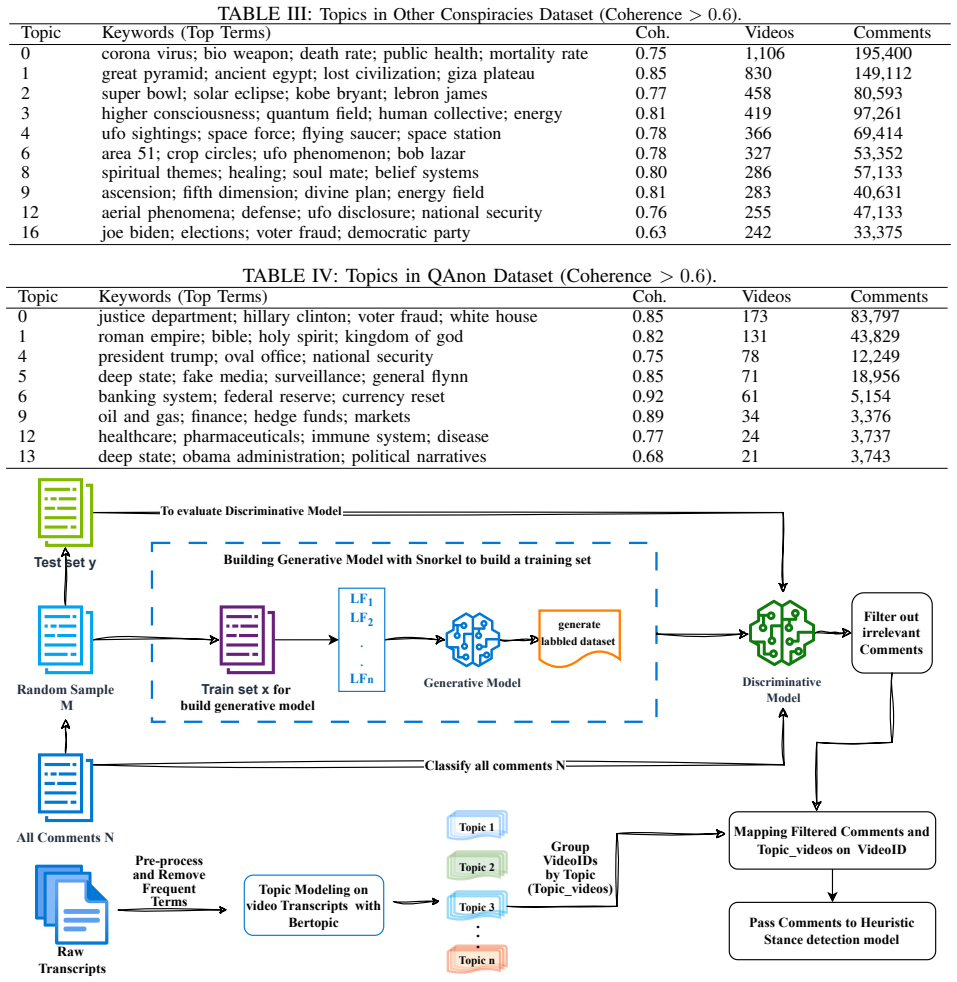
The modular pipeline that chains data ingestion, filtering, topic modelling, sentiment analysis, and stance detection to operate on large real-world comment sets.
Load-bearing premise
The stance detection and sentiment models correctly classify user positions on conspiracy comments even though no accuracy metrics or validation results are supplied.
What would settle it
Label a random sample of the 7 million comments for stance and sentiment by hand, then measure how often the pipeline's classifications match those labels.
Figures





read the original abstract
Social media platforms have become a major vector for the large-scale dissemination of misinformation and conspiracy content, posing significant risks to public trust, health, and societal stability. While prior work has primarily focused on analysing such content from a behavioural or content-centric perspective, there is a lack of scalable, service-oriented solutions that enable continuous monitoring and analysis of user engagement at platform scale. In this paper, we present a scalable AI-driven service framework for analysing user engagement and stance on social media content. Our system integrates data ingestion, filtering, topic modelling, sentiment analysis, and stance detection into a modular pipeline that can operate on large-scale, real-world datasets. We implement and evaluate our framework on a dataset comprising over 7 million user comments collected from nearly 50,000 YouTube videos associated with conspiracy narratives. Our analysis reveals that conspiracy content attracts up to 70% of total user engagement within the first week of publication, indicating strong early amplification dynamics. Furthermore, we identify a subset of highly active users who exhibit disproportionately high engagement across multiple videos and channels. Stance analysis shows that a majority of users express favourable positions toward conspiracy narratives, highlighting the role of user communities in reinforcing such content. The proposed framework demonstrates the feasibility of deploying scalable, service-oriented analytics for real-time monitoring of user engagement and behavioural patterns. These findings demonstrate the effectiveness of our framework in capturing large-scale engagement dynamics and highlight the importance of early-stage detection and service-based monitoring for mitigating the spread of harmful content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a modular, service-oriented AI pipeline that combines data ingestion, filtering, topic modelling, sentiment analysis, and stance detection to monitor user engagement with conspiracy-related YouTube content at scale. Evaluated on a corpus of >7 million comments from ~50k videos, the work reports that conspiracy content captures up to 70% of total engagement within the first week and that a majority of users adopt favourable stances toward such narratives, while also identifying a small set of highly active users.
Significance. A validated, production-ready framework for continuous, large-scale stance and engagement monitoring would be a useful contribution to computational social science and platform-governance research. The dataset size and the emphasis on early amplification are strengths; however, the absence of any reported model validation, baselines, or uncertainty estimates for the core AI components substantially reduces the reliability of the headline quantitative claims.
major comments (3)
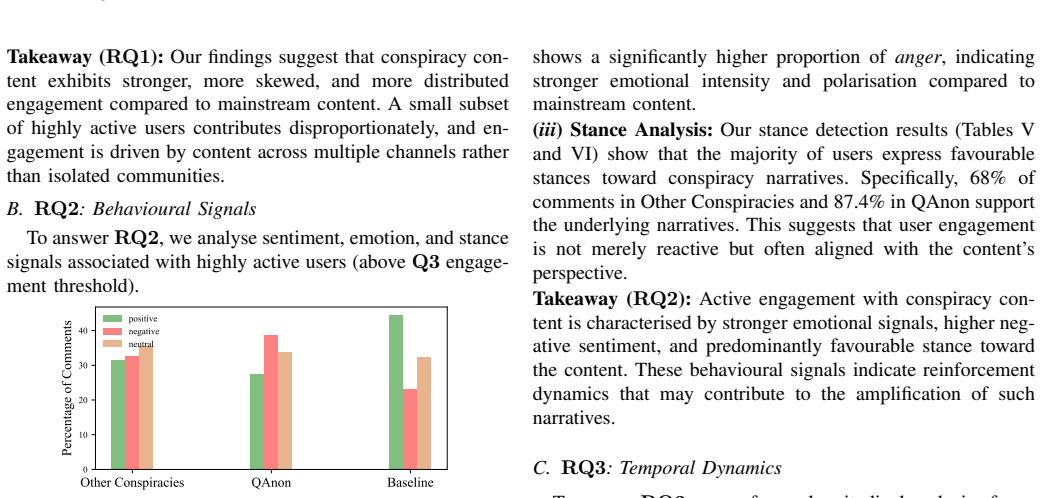
- [Abstract and §4] Abstract and §4 (Stance Detection): The central claim that 'a majority of users express favourable positions toward conspiracy narratives' is produced by an unvalidated stance-detection module. No accuracy, F1, confusion matrix, inter-annotator agreement, or held-out test-set results are supplied for either the stance classifier or the upstream sentiment analysis. Without these metrics the majority conclusion cannot be assessed and is load-bearing for the paper's main empirical contribution.
- [§3 and §5] §3 and §5 (Engagement Analysis): The reported 'up to 70% of total user engagement within the first week' is presented without baseline comparisons, temporal controls, or error bars. It is therefore impossible to determine whether this figure exceeds what would be expected under a null model of random or popularity-driven engagement.
- [§4] §4 (Pipeline Evaluation): The manuscript asserts that the framework 'can operate on large-scale, real-world datasets' and demonstrates 'feasibility of deploying scalable, service-oriented analytics,' yet provides no throughput, latency, or resource-utilization measurements for the end-to-end pipeline on the 7 M comment corpus.
minor comments (2)
- [Abstract] The abstract states quantitative findings without any accompanying validation statistics; this should be flagged as a limitation even in the abstract.
- [§3] Notation for engagement ratios and stance polarity scores is introduced without explicit definitions or references to the precise formulas used.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to improve the manuscript's rigor and transparency.
read point-by-point responses
-
Referee: [Abstract and §4] The central claim that 'a majority of users express favourable positions toward conspiracy narratives' is produced by an unvalidated stance-detection module. No accuracy, F1, confusion matrix, inter-annotator agreement, or held-out test-set results are supplied for either the stance classifier or the upstream sentiment analysis. Without these metrics the majority conclusion cannot be assessed and is load-bearing for the paper's main empirical contribution.
Authors: We agree that the absence of validation metrics for the stance detection and sentiment components limits the assessability of the majority stance claim. The manuscript applies standard off-the-shelf NLP models without reporting dataset-specific performance. In revision we will add a new evaluation subsection in §4 that reports accuracy, macro-F1, a confusion matrix, and inter-annotator agreement on a manually labelled held-out test set of 500 comments. This will directly support the empirical contribution. revision: yes
-
Referee: [§3 and §5] The reported 'up to 70% of total user engagement within the first week' is presented without baseline comparisons, temporal controls, or error bars. It is therefore impossible to determine whether this figure exceeds what would be expected under a null model of random or popularity-driven engagement.
Authors: The 70 % figure is an observational statistic computed from the temporal distribution of comment volumes in the collected corpus. We acknowledge the lack of statistical controls. The revised manuscript will add, in §§3 and 5, a simple null-model baseline (random reassignment of engagement volumes) together with bootstrap-derived 95 % confidence intervals around the weekly engagement percentages to allow readers to judge whether the observed early amplification is distinguishable from chance. revision: yes
-
Referee: [§4] The manuscript asserts that the framework 'can operate on large-scale, real-world datasets' and demonstrates 'feasibility of deploying scalable, service-oriented analytics,' yet provides no throughput, latency, or resource-utilization measurements for the end-to-end pipeline on the 7 M comment corpus.
Authors: We concur that quantitative pipeline benchmarks are required to substantiate the scalability claims. The revised version will include, in §4, end-to-end measurements (comments processed per second, average latency per comment, peak CPU and memory usage) obtained while ingesting and analysing the full 7-million-comment corpus on a standard cloud VM configuration. These metrics will be presented alongside the existing qualitative feasibility discussion. revision: yes
Circularity Check
No circularity: empirical pipeline outputs are direct data counts and model applications, not self-defined quantities.
full rationale
The paper describes a modular data-processing pipeline (ingestion, filtering, topic modelling, sentiment, stance detection) applied to a collected dataset of 7M comments. Reported figures such as the 70% early engagement and majority favourable stance are presented as analysis results from this pipeline. No equations, parameter-fitting steps, or derivations appear in the abstract or described framework. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The stance-detection component is unvalidated in the provided text, but this is a validation gap rather than a circular reduction of the output to its own definition. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Top websites ranking 2023,
“Top websites ranking 2023,” Sep 2023, [Accessed 12-10-2023]. [Online]. Available: https://www.similarweb.com/top-websites/
2023
-
[2]
32 youtube statistics 2024: Key insights & trends you need to know,
N. Dunn, “32 youtube statistics 2024: Key insights & trends you need to know,” 2024, [Accessed 14-10-2024]. [Online]. Available: https://www.charleagency.com/articles/youtube-statistics/
2024
-
[3]
Conspiracy theories as barriers to controlling the spread of covid-19 in the u.s
D. Romer and K. H. Jamieson, “Conspiracy theories as barriers to controlling the spread of covid-19 in the u.s.”Social Science & Medicine, vol. 263, p. 113356, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S027795362030575X
2020
-
[4]
Qanon: The networks of misinformation and conspiracy theories on social media,
S. Dastgeer and R. Thapaliya, “Qanon: The networks of misinformation and conspiracy theories on social media,” inThe Emerald Handbook of Computer-Mediated Communication and Social Media. Emerald Publishing Limited, 2022, pp. 251–268
2022
-
[5]
Managing harmful conspiracy theories on YouTube - blog.youtube,
Google, “Managing harmful conspiracy theories on YouTube - blog.youtube,” [15-OCT-2020], [Accessed 14-10- 2024]. [Online]. Available: https://blog.youtube/news-and-events/ harmful-conspiracy-theories-youtube/
2020
-
[6]
Continuing our work to improve recommendations on youtube — blog.youtube,
YouTube, “Continuing our work to improve recommendations on youtube — blog.youtube,” [25-01-2019], [Accessed 15- 10-2024]. [Online]. Available: https://blog.youtube/news-and-events/ continuing-our-work-to-improve/
2019
-
[7]
Trends in the diffusion of misinformation on social media,
H. Allcott, M. Gentzkow, and C. Yu, “Trends in the diffusion of misinformation on social media,”Research & Politics, vol. 6, no. 2, p. 2053168019848554, 2019
2019
-
[8]
A longitudinal analysis of youtube’s promotion of conspiracy videos,
M. Faddoul, G. Chaslot, and H. Farid, “A longitudinal analysis of youtube’s promotion of conspiracy videos,” 3 2020. [Online]. Available: http://arxiv.org/abs/2003.03318
arXiv 2020
-
[9]
Conspiracy beliefs, misinformation, social media platforms, and protest participation,
S. Boulianne and S. Lee, “Conspiracy beliefs, misinformation, social media platforms, and protest participation,”Media and Communication, vol. 10, pp. 30–41, 2022
2022
-
[10]
Conspiracy brokers: Under- standing the monetization of youtube conspiracy theories
C. Ballard, I. Goldstein, P. Mehta, G. Smothers, K. Take, V . Zhong, R. Greenstadt, T. Lauinger, and D. McCoy, “Conspiracy brokers: Under- standing the monetization of youtube conspiracy theories.” Association for Computing Machinery, Inc, 4 2022, pp. 2707–2718
2022
-
[11]
Science vs conspiracy: Collective narratives in the age of misinformation,
A. Bessi, M. Coletto, G. A. Davidescu, A. Scala, G. Caldarelli, and W. Quattrociocchi, “Science vs conspiracy: Collective narratives in the age of misinformation,”PloS one, vol. 10, no. 2, p. e0118093, 2015
2015
-
[12]
The spreading of misinformation online,
M. Del Vicario, A. Bessi, F. Zollo, F. Petroni, A. Scala, G. Caldarelli, H. E. Stanley, and W. Quattrociocchi, “The spreading of misinformation online,”Proceedings of the national academy of Sciences, vol. 113, no. 3, pp. 554–559, 2016
2016
-
[13]
Users polarization on facebook and youtube,
A. Bessi, F. Zollo, M. D. Vicario, M. Puliga, A. Scala, G. Caldarelli, B. Uzzi, and W. Quattrociocchi, “Users polarization on facebook and youtube,”PLoS ONE, vol. 11, 8 2016
2016
-
[14]
Conspiracy vs science: a large-scale analysis of online discussion cascades,
Y . Zhang, L. Wang, J. J. Zhu, and X. Wang, “Conspiracy vs science: a large-scale analysis of online discussion cascades,”World wide web, vol. 24, pp. 585–606, 2021
2021
-
[15]
Conspiracy in the time of corona: automatic detection of emerging covid-19 conspiracy theories in social media and the news,
S. Shahsavari, P. Holur, T. Wang, T. R. Tangherlini, and V . Roychowd- hury, “Conspiracy in the time of corona: automatic detection of emerging covid-19 conspiracy theories in social media and the news,”Journal of computational social science, vol. 3, no. 2, pp. 279–317, 2020
2020
-
[16]
Conspiracy theories and social media platforms,
M. Cinelli, G. Etta, M. Avalle, A. Quattrociocchi, N. Di Marco, C. Valensise, A. Galeazzi, and W. Quattrociocchi, “Conspiracy theories and social media platforms,”Current Opinion in Psychology, p. 101407, 2022
2022
-
[17]
Analyzing disinformation and crowd manipulation tactics on youtube,
M. N. Hussain, S. Tokdemir, N. Agarwal, and S. Al-Khateeb, “Analyzing disinformation and crowd manipulation tactics on youtube,” in2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). IEEE, 2018, pp. 1092–1095
2018
-
[18]
Caught in a networked collusion? homogeneity in conspiracy-related discussion net- works on youtube,
D. R ¨ochert, G. Neubaum, B. Ross, and S. Stieglitz, “Caught in a networked collusion? homogeneity in conspiracy-related discussion net- works on youtube,”Information Systems, vol. 103, p. 101866, 2022
2022
-
[19]
Antisemitic conspiracy fantasy in the age of digital media: Three ‘conspiracy theorists’ and their youtube audiences,
D. Allington, B. L. Buarque, and D. B. Flores, “Antisemitic conspiracy fantasy in the age of digital media: Three ‘conspiracy theorists’ and their youtube audiences,”Language and Literature, vol. 30, pp. 78–102, 2 2021
2021
-
[20]
Where conspiracy theories flourish: A study of youtube comments and bill gates conspiracy theories,
L. Ha, T. Graham, and J. Gray, “Where conspiracy theories flourish: A study of youtube comments and bill gates conspiracy theories,”Harvard Kennedy School Misinformation Review, 10 2022
2022
-
[21]
Google for developers — add youtube functionality to your app,
“Google for developers — add youtube functionality to your app,” Oct 2023, [Accessed: 03-03-2024]. [Online]. Available: https: //developers.google.com/youtube/v3
2023
-
[22]
youtube-transcript-api — pypi,
“youtube-transcript-api — pypi,” Oct 2024. [Online]. Available: https://pypi.org/project/youtube-transcript-api/
2024
-
[23]
Snorkel: Rapid training data creation with weak supervision,
A. Ratner, S. H. Bach, H. Ehrenberg, J. Fries, S. Wu, and C. R ´e, “Snorkel: Rapid training data creation with weak supervision,” in Proceedings of the VLDB Endowment. International Conference on V ery Large Data Bases, vol. 11, no. 3. NIH Public Access, 2017, p. 269
2017
-
[24]
P. O. Perry,corpus: Text Corpus Analysis, 2017, r package version 0.10.0. [Online]. Available: http://corpustext.com
2017
-
[25]
Bertopic: Neural topic modeling with a class-based tf-idf procedure,
M. Grootendorst, “Bertopic: Neural topic modeling with a class-based tf-idf procedure,”arXiv preprint arXiv:2203.05794, 2022
Pith/arXiv arXiv 2022
-
[26]
Umap: Uniform manifold approximation and projection for dimension reduction,
L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018
Pith/arXiv arXiv 2018
-
[27]
hdbscan: Hierarchical density based clustering
L. McInnes, J. Healy, and S. Astels, “hdbscan: Hierarchical density based clustering.”J. Open Source Softw., vol. 2, no. 11, p. 205, 2017
2017
-
[28]
Scikit-learn: Machine learning in Python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vander- plas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duch- esnay, “Scikit-learn: Machine learning in Python,”Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011
2011
-
[29]
Nltk: The natural language toolkit,
E. Loper and S. Bird, “Nltk: The natural language toolkit,”arXiv preprint cs/0205028, 2002
Pith/arXiv arXiv 2002
-
[30]
Software Framework for Topic Modelling with Large Corpora,
R. ˇReh˚uˇrek and P. Sojka, “Software Framework for Topic Modelling with Large Corpora,” inProceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Valletta, Malta: ELRA, May 2010, pp. 45–50, http://is.muni.cz/publication/884893/en
2010
-
[31]
Semeval-2018 Task 1: Affect in tweets,
S. M. Mohammad, F. Bravo-Marquez, M. Salameh, and S. Kiritchenko, “Semeval-2018 Task 1: Affect in tweets,” inProceedings of Interna- tional Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 2018
2018
-
[32]
Replicable semi-supervised approaches to state-of-the-art stance detection of tweets,
M. Reveilhac and G. Schneider, “Replicable semi-supervised approaches to state-of-the-art stance detection of tweets,”Information Processing and Management, vol. 60, no. 2, p. 103199, 2023
2023
-
[33]
On a test of whether one of two random variables is stochastically larger than the other,
H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,”The Annals of Mathematical Statistics, vol. 18, no. 1, pp. 50–60, 1947
1947
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.