BlockBatch: Multi-Scale Consensus Decoding for Efficient Diffusion Language Model Inference
Pith reviewed 2026-06-29 08:32 UTC · model grok-4.3
The pith
Running multiple block sizes in parallel and merging their KV-cache trajectories speeds up diffusion language model inference by 1.33 times on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
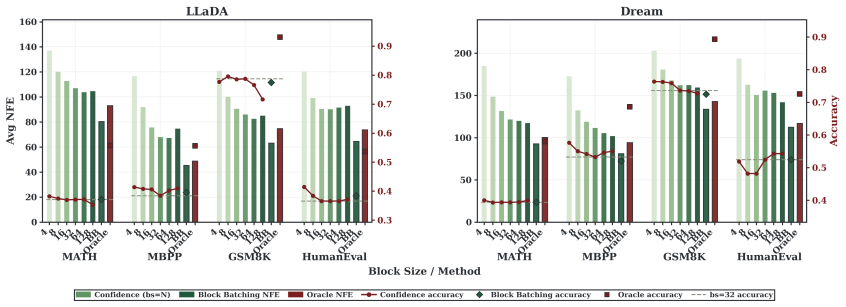
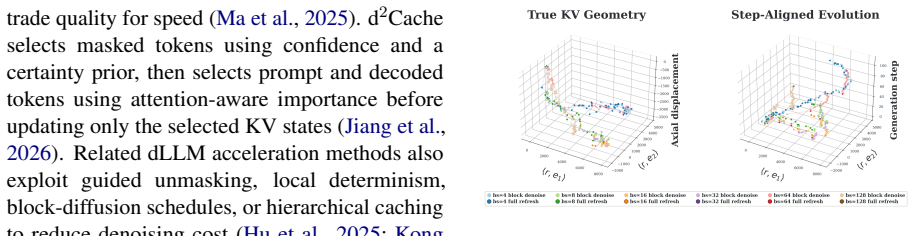
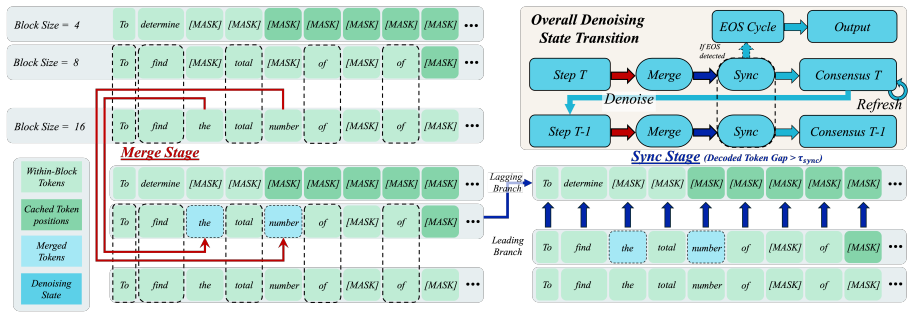
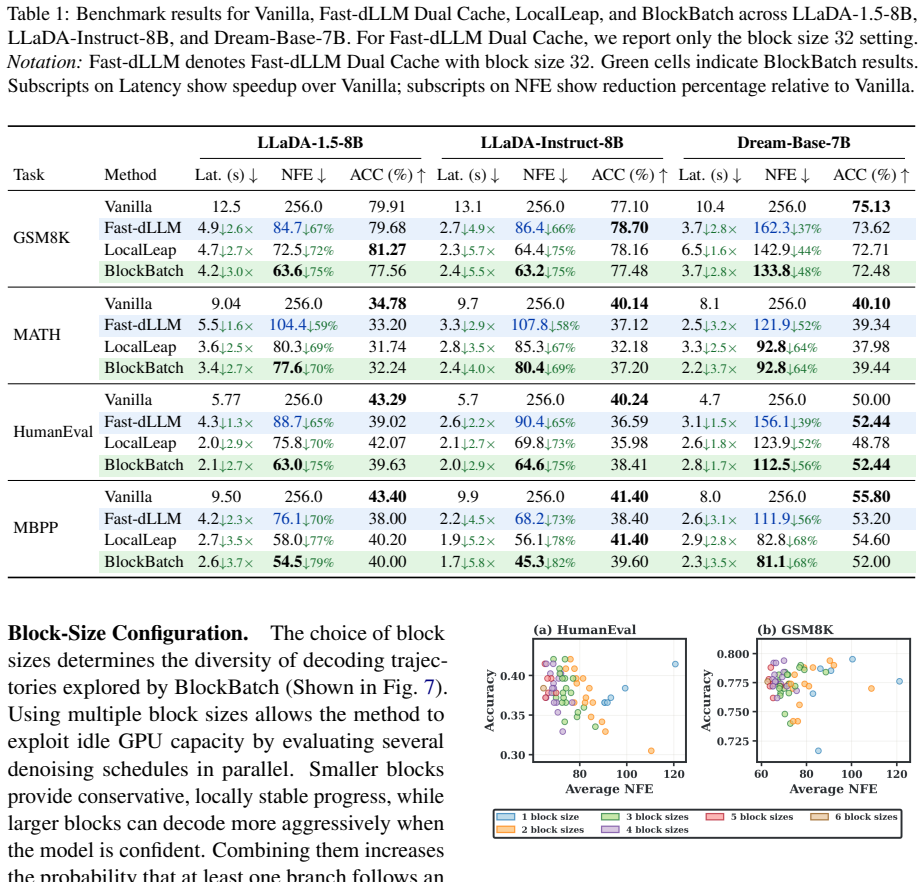
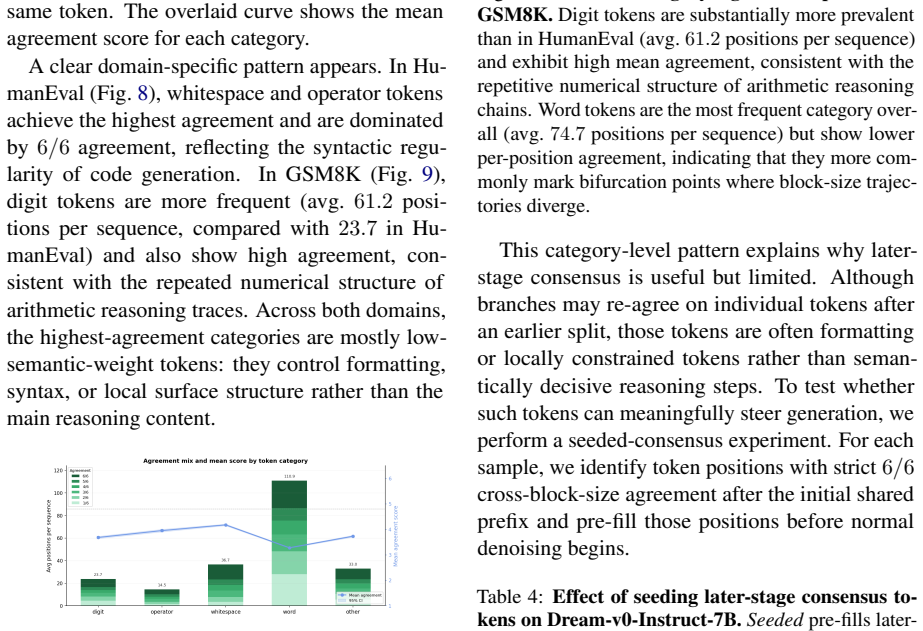
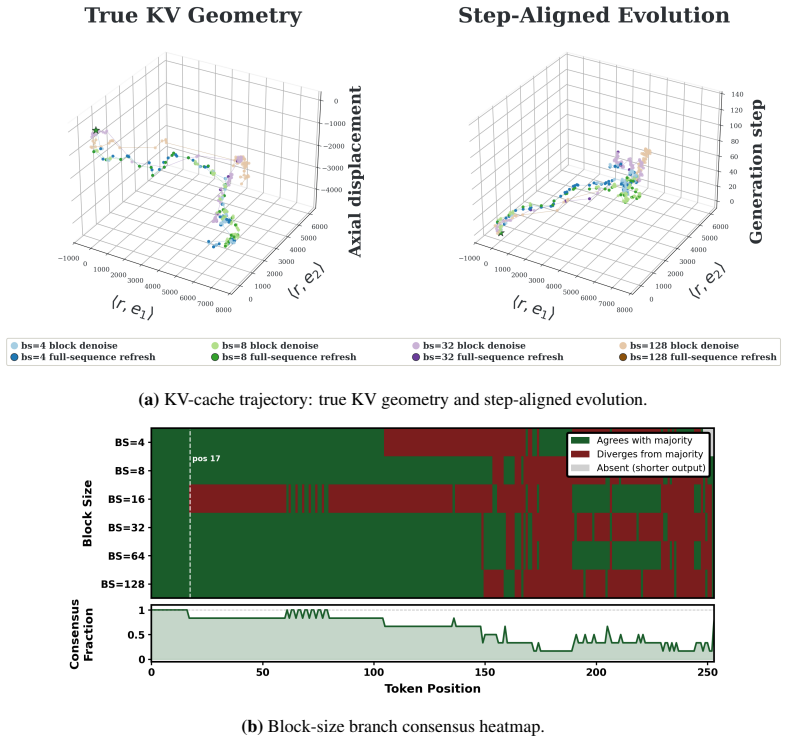
Block size itself acts as a useful branching dimension. Different sizes induce related but non-identical KV-cache trajectories that share an initial prefix, bifurcate at decisive positions, and later agree on syntactically lightweight tokens. BlockBatch therefore executes several block-size branches for the same request inside a single batched forward pass, coordinates them through confidence-gated token merging, leader-based synchronization, and periodic full-sequence refreshes that re-anchor local updates to a globally consistent state. On three representative dLLMs and four datasets the method reduces denoising NFEs by 26.6 percent and achieves a 1.33 times average end-to-end speedup over
What carries the argument
Batched multi-scale branch execution coordinated by confidence-gated token merging, leader synchronization, and periodic full-sequence KV-cache refreshes.
If this is right
- Block size can be exploited as an extra parallel dimension beyond any single fixed choice.
- Shared prefix structure among trajectories from different scales permits safe merging.
- The approach requires no model retraining and works on existing dLLMs.
- Average reductions of 26.6 percent in denoising steps translate directly to measured wall-clock gains.
Where Pith is reading between the lines
- The same trajectory-sharing pattern may appear in other parallel generation schemes, suggesting the merging technique could transfer.
- The refresh interval offers a tunable knob that future work could optimize per model or task.
- If image or audio diffusion models exhibit comparable divergence-then-agreement behavior, the multi-scale idea could apply outside text.
Load-bearing premise
KV-cache trajectories from different block sizes share enough structure that their tokens can be merged without accumulating errors that lower final output quality.
What would settle it
A controlled run on any of the three tested dLLMs where BlockBatch produces lower accuracy or coherence scores than the single best fixed-block baseline on the same four datasets.
Figures





read the original abstract
Diffusion language models (dLLMs) generate text by iteratively denoising multiple token positions in parallel, offering an attractive alternative to strictly autoregressive decoding. In practice, however, block-wise dLLM inference exposes a difficult granularity trade-off: small blocks preserve local conditioning but require many denoising steps, whereas large blocks expose more parallelism but can make premature commitments and accumulate cache error. Existing acceleration methods typically choose a single block size per request, leaving the complementarity among block sizes unused. We show that block size itself is a useful branching dimension. Different block sizes induce related but non-identical KV-cache trajectories: branches often share an initial prefix, bifurcate at semantically decisive positions, and later agree on syntactically lightweight tokens. Motivated by this structure, we propose BlockBatch, a training-free online inference framework that executes multiple block-size branches for the same request inside a batched forward pass. BlockBatch coordinates these branches through confidence-gated token merging, leader-based synchronization, and periodic full-sequence refreshes that re-anchor local block updates to a globally consistent KV state. Across 3 representative dLLMs and 4 datasets, BlockBatch reduces denoising NFEs by 26.6\% on average and achieves a 1.33$\times$ average end-to-end speedup over Fast-dLLM while preserving accuracy. These results identify block-size diversity as a practical and previously underexplored axis for branch-parallel dLLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BlockBatch, a training-free online inference framework for diffusion language models (dLLMs) that treats block size as a branching dimension. It runs multiple block-size branches for the same request inside a single batched forward pass and coordinates them via confidence-gated token merging, leader-based synchronization, and periodic full-sequence refreshes that re-anchor local KV-cache updates. The central claim is that this yields a 26.6% average reduction in denoising NFEs and a 1.33× end-to-end speedup over Fast-dLLM across three representative dLLMs and four datasets while preserving accuracy.
Significance. If the accuracy-preservation result is shown to be robust, the work identifies block-size diversity as a previously underexplored axis for branch-parallel dLLM inference. The training-free character, the observation that branches share prefixes and bifurcate at decisive positions, and the use of existing KV-cache structures are concrete strengths that could translate to practical efficiency gains.
major comments (3)
- [Experiments section (results tables)] Experiments section (results tables): the headline 26.6% NFE reduction and 1.33× speedup are reported only as averages; no per-dataset or per-model breakdowns, standard deviations, or statistical tests are supplied. This directly affects the ability to evaluate whether the central empirical claim holds consistently.
- [§3.2 (confidence-gated token merging)] §3.2 (confidence-gated token merging): the description of how bifurcating KV-cache trajectories are merged lacks any quantitative bound on merge error rate, ablation on the confidence threshold, or analysis of how often semantically decisive positions produce permanent divergence. Because this mechanism is load-bearing for the accuracy-preservation guarantee, the absence of such evidence leaves the weakest assumption unverified.
- [§3.3 (periodic full-sequence refreshes)] §3.3 (periodic full-sequence refreshes): the refresh interval and leader-synchronization policy are presented without ablation studies on refresh frequency or measurements of cache-inconsistency accumulation across denoising steps. These parameters are central to preventing error propagation and therefore require explicit validation.
minor comments (2)
- [Abstract] Abstract: the three dLLMs and four datasets are referred to only generically; naming them would improve immediate readability.
- [§3] Notation in §3: the symbols used for block size, confidence threshold, and refresh period are introduced without a consolidated table; a short notation table would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical support.
read point-by-point responses
-
Referee: Experiments section (results tables): the headline 26.6% NFE reduction and 1.33× speedup are reported only as averages; no per-dataset or per-model breakdowns, standard deviations, or statistical tests are supplied. This directly affects the ability to evaluate whether the central empirical claim holds consistently.
Authors: We agree that aggregate averages alone limit evaluation of consistency. In the revised manuscript we will expand the results tables in Section 4 to include full per-model and per-dataset breakdowns of NFE reduction and end-to-end speedup. We will also report standard deviations across multiple random seeds and add a short note on statistical significance of the observed gains. revision: yes
-
Referee: §3.2 (confidence-gated token merging): the description of how bifurcating KV-cache trajectories are merged lacks any quantitative bound on merge error rate, ablation on the confidence threshold, or analysis of how often semantically decisive positions produce permanent divergence. Because this mechanism is load-bearing for the accuracy-preservation guarantee, the absence of such evidence leaves the weakest assumption unverified.
Authors: We acknowledge the value of additional validation for the merging mechanism. The revised version will add an ablation on the confidence threshold (including its effect on merge frequency, error rate, and final accuracy) together with empirical statistics on merge error rates and the rate of permanent divergence at high-confidence positions. These results will be presented in an expanded §3.2 and a dedicated paragraph in the experiments. revision: yes
-
Referee: §3.3 (periodic full-sequence refreshes): the refresh interval and leader-synchronization policy are presented without ablation studies on refresh frequency or measurements of cache-inconsistency accumulation across denoising steps. These parameters are central to preventing error propagation and therefore require explicit validation.
Authors: We agree that explicit validation of the refresh policy is warranted. The revision will incorporate ablation experiments on refresh interval length and quantitative measurements of cache-inconsistency growth over denoising steps. These will be added to §3.3 and the experimental results to demonstrate robustness of the chosen synchronization strategy. revision: yes
Circularity Check
No circularity; empirical speedups reported as direct experimental outcomes
full rationale
The paper introduces BlockBatch as a training-free framework using confidence-gated merging, synchronization, and refreshes, then reports measured NFE reductions (26.6%) and speedups (1.33×) from experiments on 3 dLLMs and 4 datasets while preserving accuracy. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described method. The central claims rest on external benchmark measurements rather than any reduction to the method's own definitions or prior self-citations. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Continuous Language Diffusion as a Decoder-Interface Problem
Continuous language diffusion works by entering high-margin decoder basins where frozen T5 embeddings recover 93-96% of native decisions and linear readouts reach 97.9% agreement, implying models should be evaluated a...
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374. Ting Chen, Ruixiang Zhang, and Geoffrey Hinton
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Analog bits: Generating discrete data using diffusion models with self-conditioning.Preprint, arXiv:2208.04202. Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou
-
[3]
Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.Preprint, arXiv:2510.06303. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman
-
[4]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Sys- tems. Hengyu Fu, Baihe Huang, Virginia Adams, Charles Wang, Venkat Srinivasan...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Accelerating diffusion language model infer- ence via efficient kv caching and guided diffusion. Preprint, arXiv:2505.21467. Yuchu Jiang, Yue Cai, Xiangzhong Luo, Jiale Fu, Jiarui Wang, Chonghan Liu, and Xu Yang. 2026. d2Cache: Accelerating diffusion-based LLMs via dual adaptive caching. InInternational Conference on Learning Representations. Poster. Fanh...
-
[6]
SnapKV: LLM Knows What You are Looking for Before Generation
Fast inference from transformers via spec- ulative decoding. InProceedings of the 40th Inter- national Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19274–19286. PMLR. Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Fast Transformer Decoding: One Write-Head is All You Need
Simple and effective masked diffusion lan- guage models. InAdvances in Neural Informa- tion Processing Systems, volume 37, pages 130136– 130184. Noam Shazeer. 2019. Fast transformer decod- ing: One write-head is all you need.Preprint, arXiv:1911.02150. Jascha Sohl-Dickstein, Eric A. Weiss, Niru Mah- eswaranathan, and Surya Ganguli. 2015. Deep un- supervis...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. Preprint, arXiv:2508.15487. Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Anh Tuan Luu, and Chen Zhao. 2025. Diffusion vs. autoregressive language models: A text embedding perspective.Preprint, arXiv:2505.15045. Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuan- ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
The corresponding cache correction is ∆(b) full,t =F(x (b) t )−K (b) t
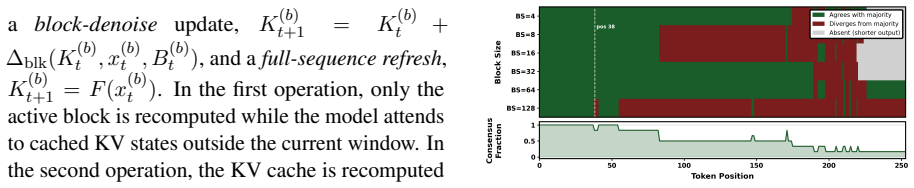
Full-sequence refresh.A full refresh recom- putes the cache from the complete current to- ken state: K(b) t+1 =F(x (b) t ). The corresponding cache correction is ∆(b) full,t =F(x (b) t )−K (b) t
-
[10]
, L}, with |B(b) t |=s b, while reusing cached context out- side the block: K(b) t+1 =K (b) t + ∆(b) blk,t
Block denoise.A block-denoise step up- dates an active blockB(b) t ⊆ {1, . . . , L}, with |B(b) t |=s b, while reusing cached context out- side the block: K(b) t+1 =K (b) t + ∆(b) blk,t. This appendix analyzes how the active block size affects the expected magnitude of the local KV correction. Synchronization and branch selection are policy operations in ...
2025
-
[11]
LocalLeap uses its default script configuration: threshold= 0.9,radius= 4, with relaxed_threshold= 0.75 for LLaDA models and relaxed_threshold= 0.8 for Dream-Base- 7B
BlockBatch uses B={4,8,16,32,64,128} , τsync = 8 , R= 32 , and τmerge = 0.5 . LocalLeap uses its default script configuration: threshold= 0.9,radius= 4, with relaxed_threshold= 0.75 for LLaDA models and relaxed_threshold= 0.8 for Dream-Base- 7B. For Table 2, we ablate the BlockBatch synchro- nization threshold over τsync ∈ {4,8,16,32,64}. All other decodi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.