When and How Human Curation Backfires: Preference Alignment under Multi-Model Self-Consuming Loop
Pith reviewed 2026-06-29 07:33 UTC · model grok-4.3
The pith
In multi-model self-consuming loops, human curation on one model can dampen or invert alignment gains for the group and degrade long-term preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
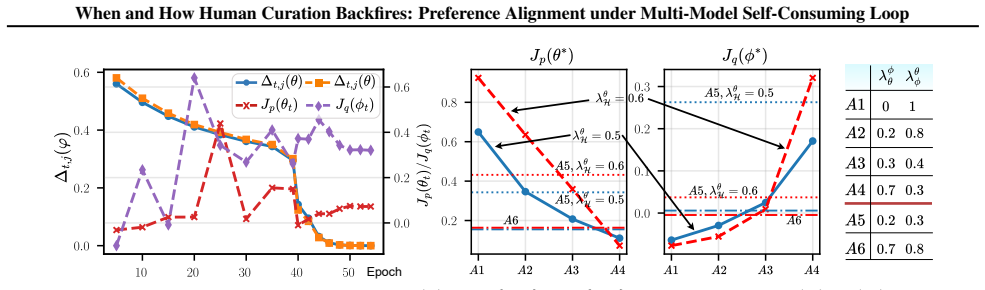
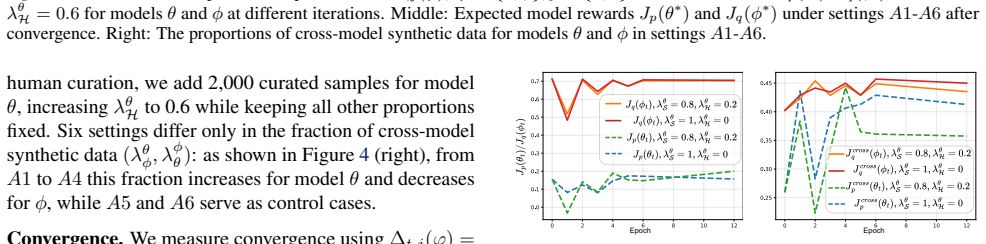
The authors characterize a system of interacting self-consuming models and prove that its fixed points depend on both self-influence and cross-influence matrices; human curation applied to one model alters the joint equilibrium in ways that can lower collective alignment even when each individual curation step is preference-improving.
What carries the argument
The interacting self-consuming dynamical system whose convergence is governed by self-influence and cross-influence terms between models.
If this is right
- Curation applied to one model propagates through cross-influence and can lower the stable alignment level of peer models.
- The sign of the net effect on long-term alignment depends on the strength of cross-model coupling relative to self-influence.
- Systems may converge to equilibria that are less aligned than the starting point despite repeated human interventions.
- Isolated-model analyses of curation no longer bound the multi-model outcome.
Where Pith is reading between the lines
- Developers sharing synthetic data across organizations may need joint curation policies rather than independent ones.
- A practical test could alternate curation between two models in a shared data pool and track whether alignment oscillates or decays.
- The same interaction structure could amplify other unintended signals such as toxicity or demographic skew if those signals cross models.
Load-bearing premise
The mathematical description of how models exchange and retrain on each other's outputs accurately reflects the dynamics of actual multi-model training pipelines.
What would settle it
Train two or more language models in a closed loop where each consumes a mixture of the others' outputs, apply human preference curation only to the first model, and measure whether its alignment score and the group average decline over successive iterations relative to an uncured baseline.
Figures





read the original abstract
Foundation models are increasingly trained on synthetic data generated by prior model iterations rather than exclusively on real data. This self-consuming training paradigm can lead to model collapse, divergence, or bias amplification. Recent work (Ferbach et al., 2024) shows that incorporating human curation into the loop can steer a self-consuming model toward human-aligned behavior, but these analyses focus on a single, isolated model that solely consumes its own outputs. In practice, however, models often interact and train on input-output pairs produced by other models. This paper studies self-consuming training in the multi-model regime. We first formalize a framework for interacting self-consuming models and characterize when the resulting dynamical system converges to a stable point. We then examine how human curation of one model affects its own alignment (self-influence) and how such effects propagate to other models (cross-influence). Unlike isolated settings where human curation always enhances model alignment, we show that cross-model interactions can dampen or even invert this effect, ultimately degrading long-term alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a dynamical system for multiple interacting self-consuming models, characterizes conditions for convergence to stable points, and analyzes self-influence versus cross-influence of human curation on alignment metrics. It claims that cross-model interactions can dampen or invert the alignment benefits of curation that are observed in isolated single-model settings.
Significance. If the interaction operators and alignment evolution equations accurately reflect real training pipelines, the result identifies an important interaction effect that could undermine long-term alignment in multi-model ecosystems. This extends prior single-model analyses and supplies a concrete mechanism (cross-influence) for a previously unexamined failure mode.
major comments (2)
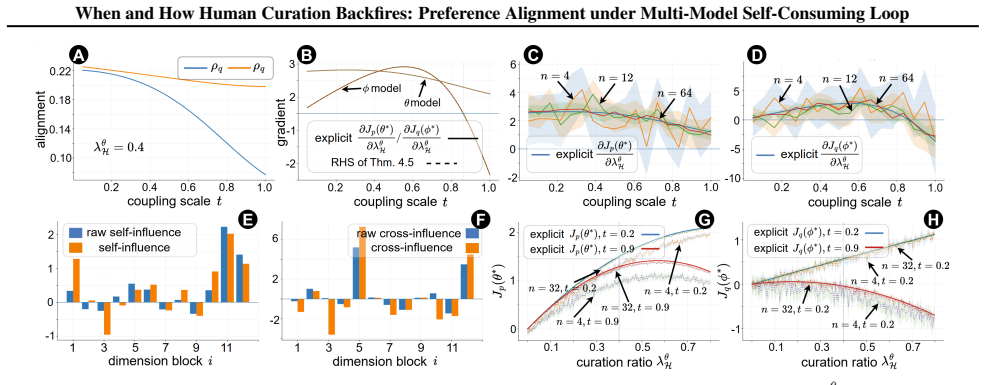
- [§4] §4 (Convergence Characterization): The fixed-point stability analysis depends on the specific form chosen for the cross-model interaction operators. These operators do not incorporate standard pipeline elements such as data filtering, LoRA versus full-parameter updates, or non-stationary preference shifts; altering any of these changes the predicted inversion, making the central claim sensitive to modeling choices that are not justified against real training dynamics.
- [§5] §5 (Influence Propagation): The demonstration that cross-influence can invert self-curation benefits is derived from the chosen alignment-metric evolution equations. Without either empirical validation on actual multi-model runs or a sensitivity analysis to the omitted factors listed above, the inversion result remains an artifact of the abstraction rather than a demonstrated phenomenon.
minor comments (2)
- The abstract cites Ferbach et al. (2024) but the reference list should be verified for completeness and consistency with the in-text citation style.
- [Notation] Notation for self-influence and cross-influence parameters should be introduced once and used uniformly to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below, clarifying the scope of our theoretical framework while acknowledging its limitations.
read point-by-point responses
-
Referee: [§4] §4 (Convergence Characterization): The fixed-point stability analysis depends on the specific form chosen for the cross-model interaction operators. These operators do not incorporate standard pipeline elements such as data filtering, LoRA versus full-parameter updates, or non-stationary preference shifts; altering any of these changes the predicted inversion, making the central claim sensitive to modeling choices that are not justified against real training dynamics.
Authors: We agree that the stability results are derived under a specific parametric form for the interaction operators, chosen to isolate the novel cross-model effects while remaining general enough to encompass both self- and cross-influences. The manuscript does not claim these operators exactly replicate every training pipeline detail; rather, it characterizes conditions under which cross-influence produces inversion even when self-influence is beneficial. We will revise §4 and the discussion to explicitly note that factors such as data filtering or LoRA could alter operator parameters and thus stability thresholds, and to frame the inversion result as a possibility under the modeled dynamics rather than a universal prediction. revision: partial
-
Referee: [§5] §5 (Influence Propagation): The demonstration that cross-influence can invert self-curation benefits is derived from the chosen alignment-metric evolution equations. Without either empirical validation on actual multi-model runs or a sensitivity analysis to the omitted factors listed above, the inversion result remains an artifact of the abstraction rather than a demonstrated phenomenon.
Authors: The inversion is shown mathematically from the evolution equations under the multi-model regime. As a theoretical paper, our contribution is the formal identification of cross-influence as a mechanism that can dampen or reverse single-model curation benefits; we do not present it as an empirically validated phenomenon in deployed systems. We will add a sensitivity analysis in §5 (varying operator coefficients and evolution parameters within plausible ranges) to demonstrate that the inversion persists across a neighborhood of the chosen equations, and we will expand the limitations paragraph to state that full empirical confirmation on real multi-model pipelines lies beyond the current scope. revision: partial
Circularity Check
No significant circularity; framework and claims are self-contained
full rationale
The paper defines a new dynamical system for multi-model self-consuming training, then derives convergence properties and the self/cross-influence effects of human curation directly from the interaction operators and alignment metric evolution in that system. No equations or results are shown to reduce to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The cited single-model result (Ferbach et al. 2024) is treated as external background rather than the source of the multi-model inversion claim. The derivation chain therefore stands on the explicit assumptions of the formalized framework rather than collapsing to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bianchi, F., Suzgun, M., Attanasio, G., R¨ottger, P., Jurafsky, D., Hashimoto, T., and Zou, J
URL https://openreview.net/forum? id=JORAfH2xFd. Bianchi, F., Suzgun, M., Attanasio, G., R¨ottger, P., Jurafsky, D., Hashimoto, T., and Zou, J. Y . Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions. InInternational Con- ference on Learning Representations, volume 2024, pp. 34196–34216, 2024. Bradley, ...
2024
-
[2]
Feng, Y ., Dohmatob, E., Yang, P., Charton, F., and Kempe, J
URL https://openreview.net/forum? id=et5l9qPUhm. Feng, Y ., Dohmatob, E., Yang, P., Charton, F., and Kempe, J. Beyond model collapse: Scaling up with synthe- sized data requires verification. InThe Thirteenth In- ternational Conference on Learning Representations,
-
[3]
Ferbach, D., Bertrand, Q., Bose, A
URL https://openreview.net/forum? id=MQXrTMonT1. Ferbach, D., Bertrand, Q., Bose, A. J., and Gidel, G. Self- consuming generative models with curated data provably optimize human preferences. InAdvances in Neural Information Processing Systems, volume 37, pp. 102531– 102567. Curran Associates, Inc., 2024. Fu, S., Zhang, S., Wang, Y ., Tian, X., and Tao, D...
2024
-
[4]
URL https://openreview.net/forum? id=WttfQGwpES. 10 When and How Human Curation Backfires: Preference Alignment under Multi-Model Self-Consuming Loop Gao, W. and Li, M. Convergence dynamics and stabilization strategies of co-evolving generative models, 2025. URL https://arxiv.org/abs/2503.08117. Gerstgrasser, M., Schaeffer, R., Dey, A., Rafailov, R., Kor-...
-
[5]
Hardt, M., Recht, B., and Singer, Y
URL https://openreview.net/forum? id=5B2K4LRgmz. Hardt, M., Recht, B., and Singer, Y . Train faster, generalize better: Stability of stochastic gradient descent. InInter- national conference on machine learning, pp. 1225–1234. PMLR, 2016. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion proba- bilistic models.Advances in neural information process- in...
-
[6]
findings-emnlp.350/
URL https://aclanthology.org/2023. findings-emnlp.350/. Reuters. Reuters and AI. https://www.reuters. com/info-pages/reuters-and-ai , 2024. Oc- tober 30, 2024. Accessed: 2026-05-16. Ronneberger, O., Fischer, P., and Brox, T. U-net: Convolu- tional networks for biomedical image segmentation. InIn- ternational Conference on Medical image computing and compu...
2023
-
[7]
Zhang et al.Self-Consuming Performative Loop.arXiv:2601.05184, 2025
May 8, 2024. Accessed: 2026-05-16. von Platen, P., Patil, S., Lozhkov, A., Cuenca, P., Lam- bert, N., Rasul, K., Davaadorj, M., Nair, D., Paul, S., Berman, W., Xu, Y ., Liu, S., and Wolf, T. Diffusers: State-of-the-art diffusion models. https://github. com/huggingface/diffusers, 2022. Wang, Y ., Kordi, Y ., Mishra, S., Liu, A., Smith, N. A., Khashabi, D.,...
-
[8]
Wyllie, S., Shumailov, I., and Papernot, N
URL https://openreview.net/forum? id=UWWNxyIT1h. Wyllie, S., Shumailov, I., and Papernot, N. Fairness feed- back loops: training on synthetic data amplifies bias. In Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pp. 2113–2147, 2024. Xie, T. and Zhang, X. Automating data annotation under strategic human agents: Risks...
-
[9]
autophagous
URL https://openreview.net/forum? id=Ut_vApkulkk. 13 When and How Human Curation Backfires: Preference Alignment under Multi-Model Self-Consuming Loop A. Related work Self-consuming Training on Synthetic Data.A rapid growing body of work studies iterative retraining on model-generated data from theoretical or empirical perspectives. The self-consuming tra...
2024
-
[10]
performative prediction
emphases the need for harm-aware fairness evaluation in vision and multimodal models. Moreover, when systems amplify bias, Taori & Hashimoto (2023) formalize data feedback loops in conditional prediction and connect stability to calibration-like properties. Furthermore, extending to multi-model self-consuming systems, Gao & Li (2025) analyze the co-evolvi...
2023
-
[11]
For model θ, we design it to tend towards summarizing the input text and adopt XSum (Narayan et al., 2018) which pairs long news articles with a short single-sentence summary as Rθ
with rankr= 16, α= 32,dropout=0.05. For model θ, we design it to tend towards summarizing the input text and adopt XSum (Narayan et al., 2018) which pairs long news articles with a short single-sentence summary as Rθ. Assume model ϕ prefers to paraphrase the input text, and Rϕ is the paraphrasing data from CoEdIT (Raheja et al., 2023), where the text data...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.