Do Physics Foundation Models Learn Generalizable Physics? A Bias-Aware Benchmark Across Physical Regimes and Distribution Shifts
Pith reviewed 2026-07-04 00:37 UTC · model grok-4.3
The pith
Physics foundation models perform as conditional generalists whose success depends on regime, temporal scale, and initial conditions rather than as universal predictors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current physics foundation models behave as conditional rather than universal generalists: their generality depends on the physical regime, temporal scale, initial-condition setting, pretraining, model size, and architecture. Improving the training data distribution only partially mitigates this limitation. Pretraining and scaling are also unable to reliably remove their ability biases.
What carries the argument
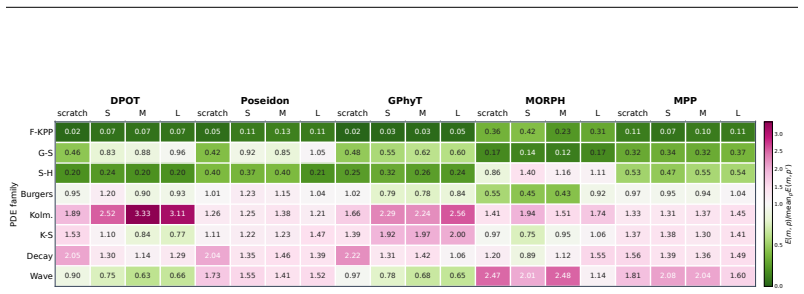
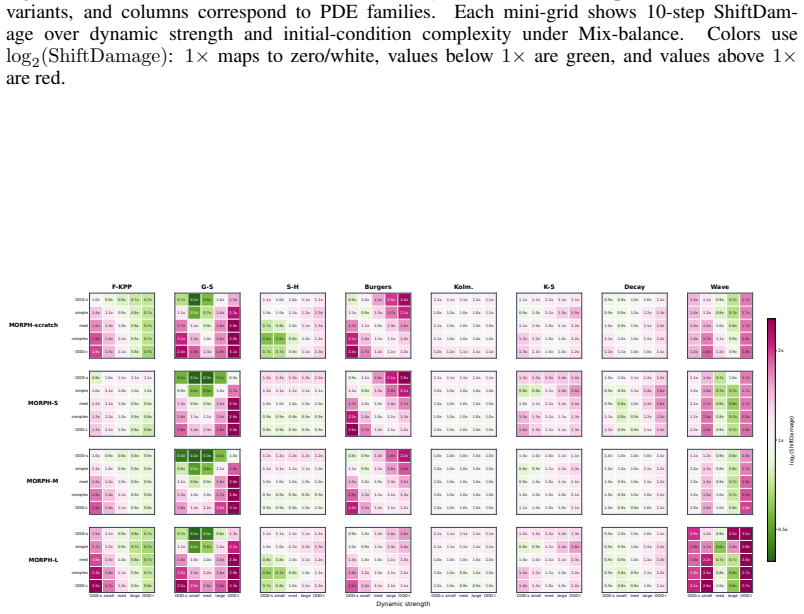
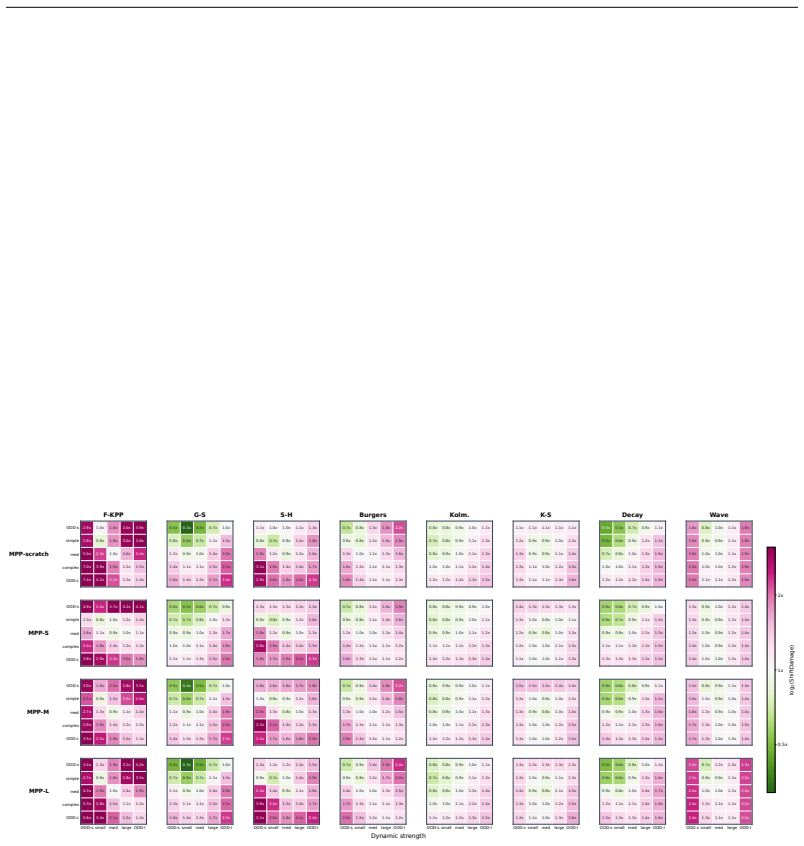
The benchmark of eight physical dynamics, three training-data mixtures, and twenty-five test regimes induced by dynamic-scale and initial-condition complexity shifts that produces sixty thousand measurements across model variants.
Load-bearing premise
The twenty-five test regimes induced by dynamic-scale and initial-condition complexity shifts sufficiently represent the distribution shifts that matter for real-world use.
What would settle it
A single physics foundation model that maintains high accuracy across all twenty-five regimes irrespective of pretraining, size, or architecture would falsify the conditional-generality claim.
Figures

























read the original abstract
Recent physics foundation models claim general spatiotemporal forecasting ability, yet their evaluations often collapse performance into a single average score under a fixed training distribution. This makes it difficult to determine whether a model has learned generalizable physical dynamics or only performs well under particular settings. We construct a benchmark with 8 physical dynamics, 3 training-data mixtures, and 25 test regimes induced by dynamic-scale and initial-condition complexity shifts, covering in-distribution, distribution-shift, and out-of-distribution settings. We evaluate five physics foundation model architectures and four model variants per architecture (scratch and three pretrained sizes), resulting in 60,000 measurements. Our results show that current physics foundation models behave as conditional rather than universal generalists: their generality depends on the physical regime, temporal scale, initial-condition setting, pretraining, model size, and architecture. Improving the training data distribution only partially mitigates this limitation. Pretraining and scaling are also unable to reliably remove their ability biases. We argue that improving physics foundation models requires moving beyond scaling models or expanding data, toward learning mechanisms that better capture transferable physical knowledge across regimes, temporal scales, and distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
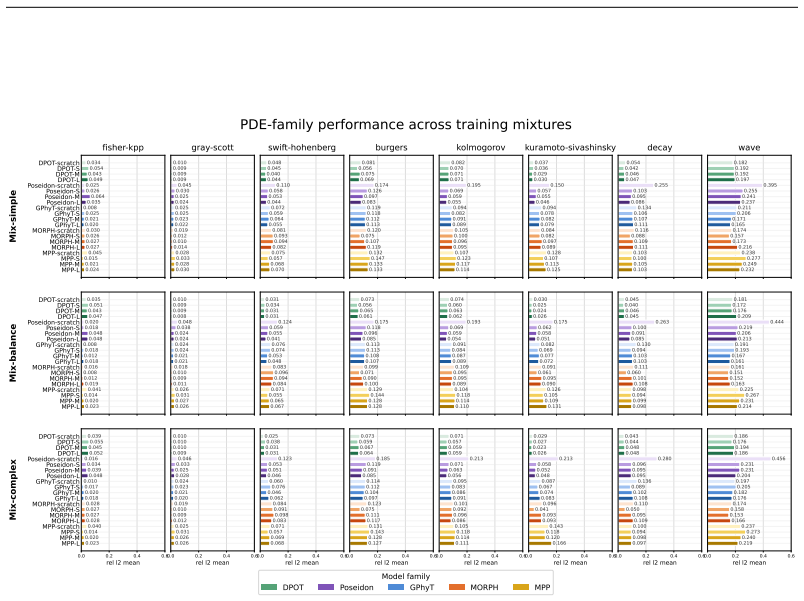
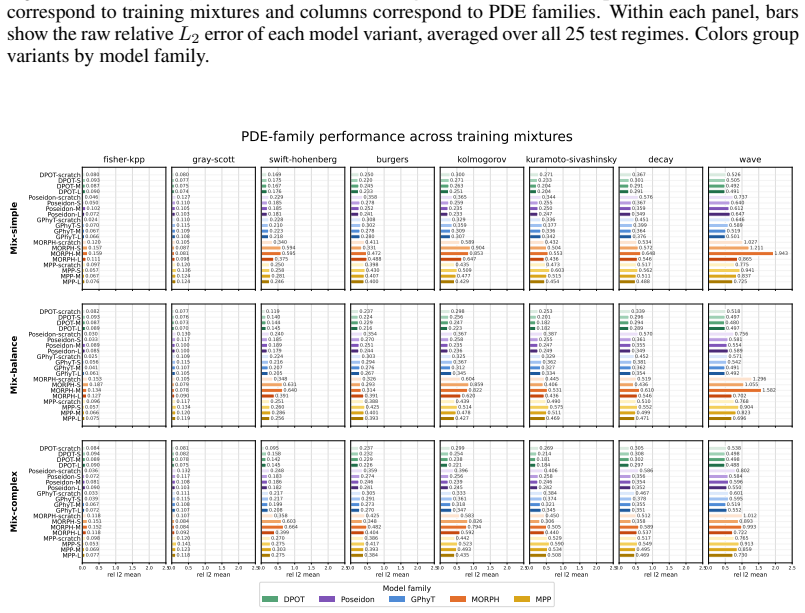
Summary. The paper constructs a benchmark with 8 physical dynamics, 3 training-data mixtures, and 25 test regimes induced by dynamic-scale and initial-condition complexity shifts. It evaluates five physics foundation model architectures (plus four variants each: scratch and three pretrained sizes) across in-distribution, distribution-shift, and out-of-distribution settings, yielding 60,000 measurements. The central claim is that current physics foundation models behave as conditional rather than universal generalists: performance depends on regime, temporal scale, initial conditions, pretraining, model size, and architecture, with data-distribution improvements, pretraining, and scaling only partially mitigating ability biases.
Significance. If the chosen regimes capture meaningful distribution shifts, the large-scale empirical results (60,000 measurements across multiple architectures and settings) would be significant for the field, as they provide concrete evidence that scaling and pretraining alone do not produce universal physical generalization and point toward the need for mechanisms that better capture transferable physical knowledge. The breadth of the evaluation across 8 dynamics and explicit regime construction is a methodological strength.
major comments (3)
- [§3] §3 (Benchmark Construction): The 25 test regimes are generated solely by varying dynamic scale and initial-condition complexity within the 8 dynamics; the manuscript provides no explicit parameter ranges, complexity metrics, or justification showing these axes sample the distribution shifts that arise in applications (e.g., boundary-condition changes, external forcing, or material-parameter variation). This choice is load-bearing for the claim that models are 'conditional rather than universal generalists.'
- [§4.2–4.3] §4.2–4.3 (Experimental Results): The paper reports performance variation across the 25 regimes but does not include statistical significance tests, confidence intervals, or variance estimates on the differences; without these, it is unclear whether the observed conditional behavior is robust or could be explained by measurement noise in the 60,000 evaluations.
- [§5] §5 (Discussion of Mitigation): The claim that 'improving the training data distribution only partially mitigates this limitation' rests on comparisons across only three mixtures; the manuscript does not quantify 'partial' (e.g., via effect-size metrics) or ablate which aspects of the mixtures drive the observed changes, weakening support for this part of the central conclusion.
minor comments (2)
- The abstract states '60,000 measurements' but the main text should explicitly derive this number (e.g., architectures × variants × regimes × metrics) for reproducibility.
- [§3.1] Notation for the three training mixtures and the exact definition of 'dynamic-scale' versus 'initial-condition complexity' shifts should be introduced earlier and used consistently in figures and tables.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation and strengthen the empirical claims. We address each major comment below and outline the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The 25 test regimes are generated solely by varying dynamic scale and initial-condition complexity within the 8 dynamics; the manuscript provides no explicit parameter ranges, complexity metrics, or justification showing these axes sample the distribution shifts that arise in applications (e.g., boundary-condition changes, external forcing, or material-parameter variation). This choice is load-bearing for the claim that models are 'conditional rather than universal generalists.'
Authors: We agree that explicit details are needed. The 25 regimes are generated by applying multiplicative scale factors (0.1×–10×) to key dynamic parameters (e.g., viscosity, forcing amplitude) and by modulating initial-condition complexity through added Gaussian noise at multiple spatial scales. In the revised manuscript we will add an appendix table listing the exact parameter values and complexity metrics for every regime, together with a short justification paragraph linking these choices to standard distribution-shift scenarios in the literature (e.g., Reynolds-number variation and multi-scale initial turbulence). We will also explicitly note that boundary-condition and material-parameter shifts lie outside the current benchmark scope because they would require reformulating the underlying dynamics; this limitation will be stated clearly. revision: partial
-
Referee: [§4.2–4.3] §4.2–4.3 (Experimental Results): The paper reports performance variation across the 25 regimes but does not include statistical significance tests, confidence intervals, or variance estimates on the differences; without these, it is unclear whether the observed conditional behavior is robust or could be explained by measurement noise in the 60,000 evaluations.
Authors: We concur that statistical quantification is required. The 60,000 measurements comprise multiple independent evaluations per (model, regime) pair arising from different random seeds and the four model variants. In the revision we will report 95 % bootstrap confidence intervals for all key performance deltas across regimes and will add a short methods paragraph describing the resampling procedure. These additions will allow readers to judge whether the reported conditional behavior exceeds measurement variability. revision: yes
-
Referee: [§5] §5 (Discussion of Mitigation): The claim that 'improving the training data distribution only partially mitigates this limitation' rests on comparisons across only three mixtures; the manuscript does not quantify 'partial' (e.g., via effect-size metrics) or ablate which aspects of the mixtures drive the observed changes, weakening support for this part of the central conclusion.
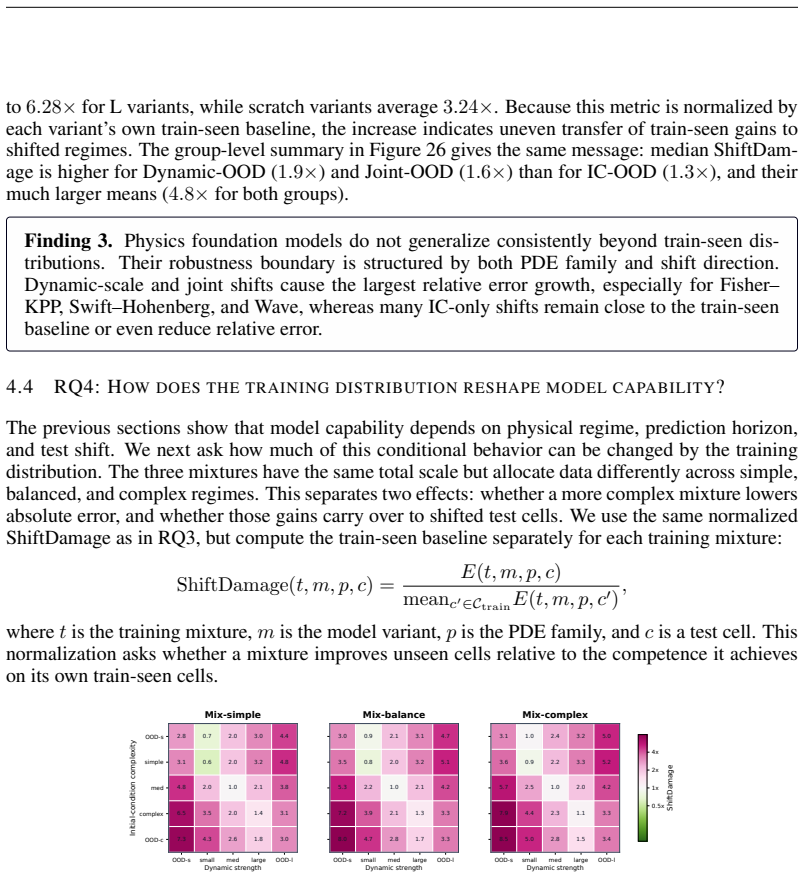
Authors: The three mixtures were designed to span qualitatively different data distributions (balanced, regime-skewed, complexity-skewed). To quantify the mitigation we will insert effect-size statistics (Cohen’s d and relative percentage change) for the performance shifts between mixtures in the revised §5. We will also expand the text to describe which mixture components most influence particular regimes. A exhaustive component-wise ablation would require new training runs beyond the present study; we will therefore characterize the current comparison as an initial exploration while still providing the requested quantitative support for the “partial” qualifier. revision: partial
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper constructs 8 dynamics, 3 training mixtures, and 25 test regimes via dynamic-scale and initial-condition shifts, then reports 60,000 direct performance measurements across architectures, sizes, and pretraining variants. No equations, derivations, parameter fitting, or predictions appear; results are raw empirical evaluations on the constructed regimes. No self-citation load-bearing steps or ansatz smuggling are present. The central claim follows immediately from the observed variation across regimes without any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- selection of 8 dynamics and 25 regimes
axioms (1)
- domain assumption The chosen shifts represent meaningful distribution shifts for physical systems.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.