On subspace-constrained preconditioning for randomized iterative methods
Pith reviewed 2026-06-29 06:19 UTC · model grok-4.3
The pith
A QR-like factorization allows subspace-constrained preconditioning to reduce randomized linear solvers to smaller systems with linear convergence in expectation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The subspace-constrained preconditioning framework, realized through an implicit QR-like factorization, transforms the original linear system into block-orthogonal form. This step reduces the task to solving a smaller linear system with improved singular value properties from a suitable starting vector. The resulting algorithmic structure converges linearly in expectation while remaining computationally efficient by not constructing preconditioners explicitly.
What carries the argument
The QR-like factorization that produces a block-orthogonal equivalent system, enabling reduction to a smaller problem with favorable singular values.
If this is right
- The technique eliminates the need for full-rank assumptions required in previous subspace preconditioning work.
- Implementation stays implicit, sidestepping the high cost of forming a complete preconditioned system.
- Orthogonal search directions constructed from stochastic gradients support accelerated variants of the method.
- Linear convergence holds in expectation under the stated conditions.
Where Pith is reading between the lines
- The reduction to smaller systems may extend naturally to other classes of iterative solvers beyond randomized ones.
- Choosing the initial point to achieve the favorable singular value distribution could be explored through adaptive strategies in practice.
- The implicit nature suggests the approach scales well to very large sparse systems where explicit matrices are impractical.
Load-bearing premise
The reformulation reduces the problem to solving a smaller linear system with a favorable singular value distribution, provided an appropriate initial point is employed.
What would settle it
Running the method on a test linear system with a chosen initial point and checking whether the expected residual or error decreases at a constant linear rate per iteration; failure to observe this rate would challenge the convergence claim.
Figures

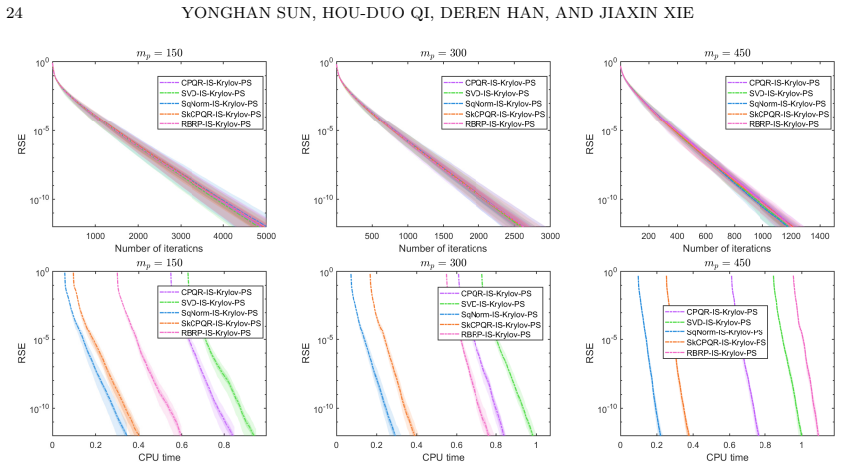
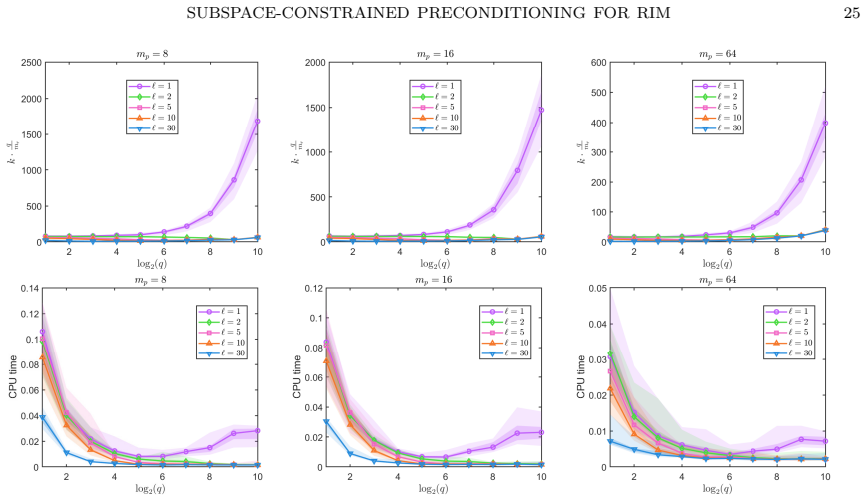
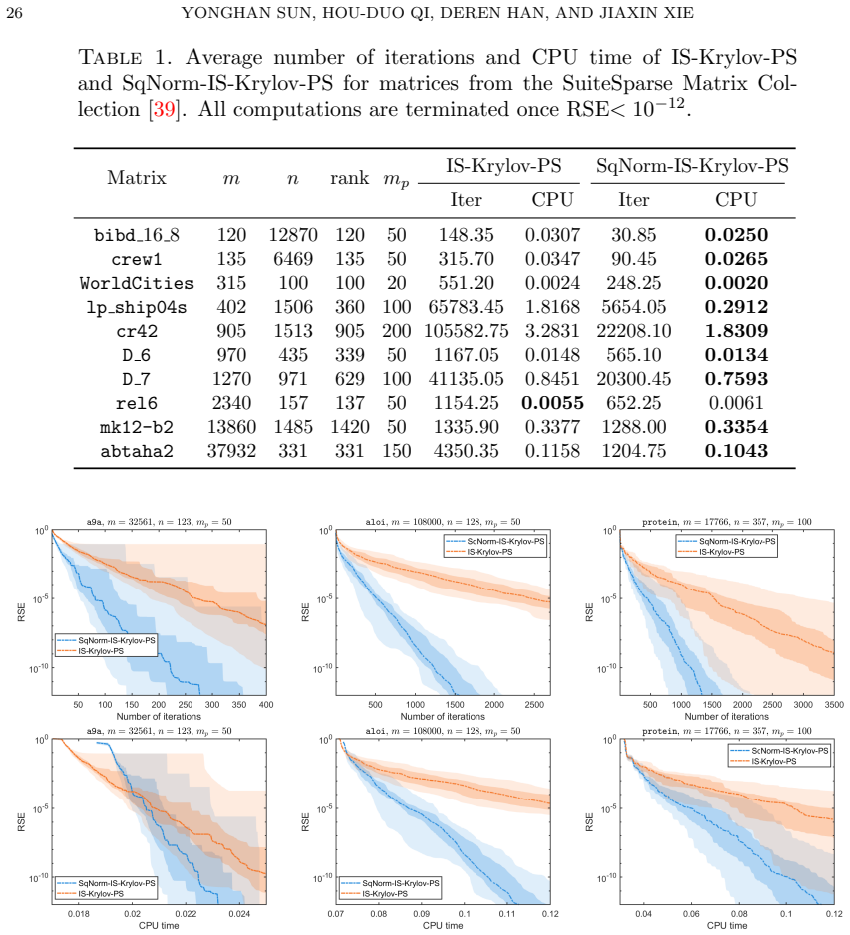

read the original abstract
In this paper, we further investigate and refine the subspace-constrained preconditioning technique to enhance the theoretical and numerical convergence properties of randomized iterative methods for solving linear systems. In particular, we design a QR-like factorization that transforms the original linear system into an equivalent block-orthogonal form, thus avoiding the full-rank assumptions adopted in existing work. Moreover, this reformulation reduces the problem to solving a smaller linear system with a favorable singular value distribution, provided an appropriate initial point is employed. The proposed framework can be implemented implicitly within the iteration and does not require explicitly constructing either a preconditioner matrix or a preconditioned linear system, which eliminates the prohibitive cost of forming a fully preconditioned system. Furthermore, we construct orthogonalized search directions from stochastic gradients and develop accelerated variants of the framework. We prove that the proposed algorithmic framework converges linearly in expectation. Numerical experiments demonstrate the benefits of the proposed preconditioning strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a subspace-constrained preconditioning framework for randomized iterative methods solving linear systems. It introduces a QR-like factorization that converts the system to an equivalent block-orthogonal form without requiring full-rank assumptions, reduces the problem to a smaller linear system whose singular values are claimed to be favorable (provided an appropriate initial point), implements the approach implicitly without forming explicit preconditioners, constructs orthogonalized search directions from stochastic gradients, develops accelerated variants, proves linear convergence in expectation, and reports numerical benefits.
Significance. If the linear convergence holds without restrictive conditions on the initial point, the work would strengthen the theoretical foundation for randomized solvers by providing an implicit preconditioning strategy that avoids full-rank assumptions and expensive matrix constructions. The combination of the factorization reformulation, implicit implementation, and accelerated variants could improve practical efficiency for large-scale systems.
major comments (2)
- [Abstract / reformulation section] Abstract and the reformulation section: the reduction to a smaller linear system with favorable singular value distribution is stated to hold only 'provided an appropriate initial point is employed.' This condition appears load-bearing for both the spectral claim and the subsequent linear convergence proof; the manuscript must either supply a general, constructive procedure for obtaining such an initial point that works for arbitrary instances or clarify that the guarantee is conditional on a specially chosen start.
- [Convergence theorem] Convergence theorem (presumably §4 or the main theorem): the proof of linear convergence in expectation must be checked against whether it relies on the same initial-point condition used for the singular-value benefit. If the theorem statement does not explicitly restrict the initial vector, the derivation should be examined for an implicit assumption that would invalidate the result for generic starts.
minor comments (2)
- [Reformulation section] Clarify the precise relationship between the block-orthogonal form obtained by the QR-like factorization and the original system; an explicit statement of equivalence (including any rank or consistency conditions) would aid readability.
- [Implementation section] The description of the implicit implementation should include a short pseudocode or algorithmic outline showing how the factorization step is folded into the iteration without explicit matrix construction.
Simulated Author's Rebuttal
We thank the referee for the careful reading and valuable comments on our manuscript. We address the two major comments point by point below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / reformulation section] Abstract and the reformulation section: the reduction to a smaller linear system with favorable singular value distribution is stated to hold only 'provided an appropriate initial point is employed.' This condition appears load-bearing for both the spectral claim and the subsequent linear convergence proof; the manuscript must either supply a general, constructive procedure for obtaining such an initial point that works for arbitrary instances or clarify that the guarantee is conditional on a specially chosen start.
Authors: We agree that the dependence on an appropriate initial point for the favorable singular-value claim should be stated more explicitly. In the revised manuscript we will (i) retain the existing phrasing in the abstract but add a dedicated remark in the reformulation section that the spectral benefit is conditional, and (ii) supply a constructive, easily implementable procedure: the initial vector is taken as the orthogonal projection of an arbitrary starting guess onto the column space of the sketching matrix (or, equivalently, the solution of a small least-squares problem whose size is independent of the original dimension). This choice is always feasible and can be computed implicitly within the same iteration framework. We will also update the abstract to reference this procedure. revision: yes
-
Referee: [Convergence theorem] Convergence theorem (presumably §4 or the main theorem): the proof of linear convergence in expectation must be checked against whether it relies on the same initial-point condition used for the singular-value benefit. If the theorem statement does not explicitly restrict the initial vector, the derivation should be examined for an implicit assumption that would invalidate the result for generic starts.
Authors: We have re-examined the proof of the main convergence theorem. The linear rate is derived under the same block-orthogonal reformulation that yields the favorable singular values; consequently the analysis does rely on the initial vector satisfying the condition used for the spectral claim. The current theorem statement does not make this restriction explicit. In the revision we will add the precise assumption on the initial vector to the theorem statement and to the statement of the main result, and we will insert a short paragraph immediately after the theorem that recalls why the chosen initialization satisfies the hypothesis. No other changes to the proof are required. revision: yes
Circularity Check
No circularity: convergence proof is independent of fitted inputs or self-referential definitions
full rationale
The paper derives linear convergence in expectation for the subspace-constrained framework via reformulation to an equivalent block-orthogonal system (via QR-like factorization) followed by standard analysis of randomized iterative methods on the reduced system. The 'appropriate initial point' is an explicit modeling assumption stated in the abstract, not a hidden fit or self-definition. No equations reduce a claimed prediction to a fitted parameter by construction, and no load-bearing step relies on a self-citation chain that itself lacks external verification. The approach builds on prior randomized methods but adds an explicit factorization step whose spectral benefit is analyzed directly rather than assumed via renaming or smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A QR-like factorization exists that transforms the linear system into an equivalent block-orthogonal form without requiring full rank.
Reference graph
Works this paper leans on
- [1]
-
[2]
K. B. Athreya and S. N. Lahiri.Measure theory and probability theory. Springer, New York, 2006
2006
-
[3]
Avron, P
H. Avron, P. Maymounkov, and S. Toledo. Blendenpik: supercharging LAPACK’s least-squares solver. SIAM J. Sci. Comput., 32(3):1217–1236, 2010
2010
-
[4]
M. Benzi. Preconditioning techniques for large linear systems: a survey.J. Comput. Phys., 182(2):418– 477, 2002
2002
-
[5]
Chang and C.-J
C.-C. Chang and C.-J. Lin. LIBSVM: a library for support vector machines.ACM Trans. Intell. Syst. Technol., 2(3):1–27, 2011
2011
-
[6]
Y. Chen, E. N. Epperly, J. A. Tropp, and R. J. Webber. Randomly pivoted Cholesky: practical ap- proximation of a kernel matrix with few entry evaluations.Comm. Pure Appl. Math., 78(5):995–1041, 2025
2025
-
[7]
Cortinovis and D
A. Cortinovis and D. Kressner. Adaptive randomized pivoting for column subset selection, DEIM, and low-rank approximation.SIAM J. Matrix Anal. Appl., 47(1):25–47, 2026
2026
-
[8]
E. J. Craig. The n-step iteration procedures.J. Math. Phys., 34(1-4):64–73, 1955
1955
-
[9]
J. W. Demmel. The probability that a numerical analysis problem is difficult.Math. Comp., 50(182):449– 480, 1988
1988
-
[10]
Derezi´ nski and M
M. Derezi´ nski and M. W. Mahoney. Recent and upcoming developments in randomized numerical linear algebra for machine learning. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6470–6479, 2024
2024
-
[11]
Derezi´ nski and J
M. Derezi´ nski and J. Yang. Solving dense linear systems faster than via preconditioning. InProceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 1118–1129, 2024
2024
-
[12]
Deshpande, L
A. Deshpande, L. Rademacher, S. S. Vempala, and G. Wang. Matrix approximation and projective clustering via volume sampling.Theory Comput., 2(1):225–247, 2006
2006
-
[13]
Y. Dong, C. Chen, P.-G. Martinsson, and K. Pearce. Robust blockwise random pivoting: fast and accurate adaptive interpolative decomposition.SIAM J. Matrix Anal. Appl., 46(3):1791–1815, 2025
2025
-
[14]
Dong and P.-G
Y. Dong and P.-G. Martinsson. Simpler is better: a comparative study of randomized pivoting algo- rithms for CUR and interpolative decompositions.Adv. Comput. Math., 49(4):66, 2023
2023
-
[15]
J. A. Duersch and M. Gu. Randomized QR with column pivoting.SIAM J. Sci. Comput., 39(4):C263– C291, 2017
2017
-
[16]
J. A. Duersch and M. Gu. Randomized projection for rank-revealing matrix factorizations and low-rank approximations.SIAM Rev., 62(3):661–682, 2020
2020
-
[17]
Eckart and G
C. Eckart and G. Young. The approximation of one matrix by another of lower rank.Psychometrika, 1(3):211–218, 1936. SUBSPACE-CONSTRAINED PRECONDITIONING FOR RIM 29
1936
-
[18]
Ehrig and P
R. Ehrig and P. Deuflhard. GMERR—an error-minimizing variant of GMRES. Technical Report SC- 97-63, ZIB, 1997
1997
-
[19]
E. N. Epperly. Adaptive randomized pivoting and volume sampling.arXiv preprint arXiv:2510.02513, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
E. N. Epperly, M. Meier, and Y. Nakatsukasa. Fast randomized least-squares solvers can be just as accurate and stable as classical direct solvers.Commun. Pure Appl. Math., 79(2):293–339, 2026
2026
-
[21]
Fletcher.Practical methods of optimization
R. Fletcher.Practical methods of optimization. John Wiley & Sons, Chichester, 2013
2013
-
[22]
Frieze, R
A. Frieze, R. Kannan, and S. Vempala. Fast Monte-Carlo algorithms for finding low-rank approxima- tions.J. ACM, 51(6):1025–1041, 2004
2004
-
[23]
S. Garg, A. S. Berahas, and M. Derezi´ nski. Second-order information promotes mini-batch robustness in variance-reduced gradients.J. Mach. Learn. Res., 26(306):1–49, 2025
2025
-
[24]
G. Garrigos and R. M. Gower. Handbook of convergence theorems for (stochastic) gradient methods. arXiv preprint arXiv:2301.11235, 2023
-
[25]
A. Gaul, M. H. Gutknecht, J. Liesen, and R. Nabben. A framework for deflated and augmented Krylov subspace methods.SIAM J. Matrix Anal. Appl., 34(2):495–518, 2013
2013
-
[26]
G. H. Golub and C. F. Van Loan.Matrix computations. Johns Hopkins University Press, Baltimore, 2013
2013
-
[27]
Goswami and B
A. Goswami and B. V. Rao.Measure theory for analysis and probability. Springer, Singapore, 2025
2025
-
[28]
R. M. Gower, N. Loizou, X. Qian, A. Sailanbayev, E. Shulgin, and P. Richt´ arik. SGD: general analysis and improved rates. InProceedings of the 36th International Conference on Machine Learning, pages 5200–5209, 2019
2019
-
[29]
R. M. Gower and P. Richt´ arik. Randomized iterative methods for linear systems.SIAM J. Matrix Anal. Appl., 36(4):1660–1690, 2015
2015
- [30]
-
[31]
Halko, P.-G
N. Halko, P.-G. Martinsson, and J. A. Tropp. Finding structure with randomness: probabilistic algo- rithms for constructing approximate matrix decompositions.SIAM Rev., 53(2):217–288, 2011
2011
-
[32]
D. Han, Y. Su, and J. Xie. Randomized Douglas–Rachford methods for linear systems: improved accuracy and efficiency.SIAM J. Optim., 34(1):1045–1070, 2024
2024
-
[33]
Han and J
D. Han and J. Xie. On pseudoinverse-free randomized methods for linear systems: unified framework and acceleration.Optim. Methods Softw., 41(1):82–117, 2026
2026
-
[34]
I. C. Ipsen and A. K. Saibaba. Many (most?) column subset selection criteria are NP hard.arXiv preprint arXiv:2511.02740, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Kaczmarz
S. Kaczmarz. Angen¨ aherte aufl¨ osung von systemen linearer glei-chungen.Bull. Int. Acad. Pol. Sic. Let., Cl. Sci. Math. Nat., pages 355–357, 1937
1937
- [36]
-
[37]
C. T. Kelley.Iterative methods for linear and nonlinear equations. SIAM, Philadelphia, 1995
1995
-
[38]
D. P. Kingma and J. Ba. Adam: a method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[39]
S. P. Kolodziej, M. Aznaveh, M. Bullock, J. David, T. A. Davis, M. Henderson, Y. Hu, and R. Sand- strom. The SuiteSparse matrix collection website interface.J. Open Source Softw., 4(35):1244, 2019
2019
- [40]
-
[41]
X.-L. Li. Preconditioned stochastic gradient descent.IEEE Trans. Neural Netw. Learn. Syst., 29(5):1454–1466, 2017
2017
-
[42]
Liu and S
J. Liu and S. Wright. An accelerated randomized Kaczmarz algorithm.Math. Comp., 85(297):153–178, 2016
2016
-
[43]
Loizou and P
N. Loizou and P. Richt´ arik. Momentum and stochastic momentum for stochastic gradient, Newton, proximal point and subspace descent methods.Comput. Optim. Appl., 77(3):653–710, 2020
2020
-
[44]
Lok and E
J. Lok and E. Rebrova. A subspace constrained randomized Kaczmarz method for structure or external knowledge exploitation.Linear Algebra Appl., 698:220–260, 2024. 30 YONGHAN SUN, HOU-DUO QI, DEREN HAN, AND JIAXIN XIE
2024
- [45]
-
[46]
D. A. Lorenz and M. Winkler. Minimal error momentum Bregman-Kaczmarz.Linear Algebra Appl., 709:416–448, 2025
2025
-
[47]
Ma and D
A. Ma and D. Needell. Stochastic gradient descent for linear systems with missing data.Numer. Math. Theory Methods Appl., 12(1):1–20, 2019
2019
-
[48]
J. Martens and R. Grosse. Optimizing neural networks with Kronecker-factored approximate curvature. arXiv preprint arXiv:1503.05671, 2015
-
[49]
Martinsson and J
P.-G. Martinsson and J. A. Tropp. Randomized numerical linear algebra: foundations and algorithms. Acta Numer., 29:403–572, 2020
2020
-
[50]
Meier, Y
M. Meier, Y. Nakatsukasa, A. Townsend, and M. Webb. Are sketch-and-precondition least squares solvers numerically stable?SIAM J. Matrix Anal. Appl., 45(2):905–929, 2024
2024
-
[51]
X. Meng, M. A. Saunders, and M. W. Mahoney. LSRN: a parallel iterative solver for strongly over- or underdetermined systems.SIAM J. Sci. Comput., 36(2):C95–C118, 2014
2014
-
[52]
Spectrum Approximation Beyond Fast Matrix Multiplication: Algorithms and Hardness
C. Musco, P. Netrapalli, A. Sidford, S. Ubaru, and D. P. Woodruff. Spectrum approximation beyond fast matrix multiplication: algorithms and hardness.arXiv preprint arXiv:1704.04163, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
I. Necoara. Faster randomized block Kaczmarz algorithms.SIAM J. Matrix Anal. Appl., 40(4):1425– 1452, 2019
2019
-
[54]
Needell, N
D. Needell, N. Srebro, and R. Ward. Stochastic gradient descent, weighted sampling, and the randomized Kaczmarz algorithm.Math. Program., 155:549–573, 2016
2016
-
[55]
Needell and J
D. Needell and J. A. Tropp. Paved with good intentions: analysis of a randomized block Kaczmarz method.Linear Algebra Appl., 441:199–221, 2014
2014
-
[56]
Nemirovski, A
A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro. Robust stochastic approximation approach to stochastic programming.SIAM J. Optim., 19(4):1574–1609, 2009
2009
-
[57]
Pearce, C
K. Pearce, C. Chen, Y. Dong, and P.-G. Martinsson. Adaptive parallelizable algorithms for interpolative decompositions via partially pivoted LU.Numer. Linear Algebra Appl., 32(1):e70002, 2025
2025
- [58]
-
[59]
S. J. Reddi, S. Kale, and S. Kumar. On the convergence of Adam and beyond.arXiv preprint arXiv:1904.09237, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[60]
J. Rieger. Generalized Gearhart–Koshy acceleration for the Kaczmarz method.Math. Comp., 92:1251– 1272, 2023
2023
-
[61]
Robbins and S
H. Robbins and S. Monro. A stochastic approximation method.Ann. Math. Statist., 22:400–407, 1951
1951
-
[62]
Saad.Iterative methods for sparse linear systems
Y. Saad.Iterative methods for sparse linear systems. SIAM, Philadelphia, 2003
2003
-
[63]
Saad and M
Y. Saad and M. H. Schultz. GMRES: a generalized minimal residual algorithm for solving nonsymmetric linear systems.SIAM J. Sci. Stat. Comput., 7(3):856–869, 1986
1986
-
[64]
Sch¨ opfer and D
F. Sch¨ opfer and D. A. Lorenz. Linear convergence of the randomized sparse Kaczmarz method.Math. Program., 173(1):509–536, 2019
2019
-
[65]
N. N. Schraudolph. Fast curvature matrix-vector products for second-order gradient descent.Neural Comput., 14(7):1723–1738, 2002
2002
-
[66]
A. J. Scott and G. P. Styan. On a separation theorem for generalized eigenvalues and a problem in the analysis of sample surveys.Linear Algebra Appl., 70:209–224, 1985
1985
-
[67]
Scott and M
J. Scott and M. T˚ uma. Sparse linear least-squares problems.Acta Numer., 34:891–1010, 2025
2025
-
[68]
Design Criteria for SGD Preconditioners: Local Conditioning, Noise Floors, and Basin Stability
M. Scott, T. Xu, Z. Tang, A. Pichette-Emmons, Q. Ye, Y. Saad, and Y. Xi. Designing preconditioners for SGD: local conditioning, noise floors, and basin stability.arXiv preprint arXiv:2511.19716, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
J. R. Shewchuk. An introduction to the conjugate gradient method without the agonizing pain. Technical Report CMU-CS-94-125, Carnegie Mellon University, Pittsburgh, PA, 1994
1994
-
[70]
Strohmer and R
T. Strohmer and R. Vershynin. A randomized Kaczmarz algorithm with exponential convergence.J. Fourier Anal. Appl., 15(2):262–278, 2009
2009
-
[71]
Y. Su, D. Han, Y. Zeng, and J. Xie. On greedy multi-step inertial randomized Kaczmarz method for solving linear systems.Calcolo, 61(4):68, 2024. SUBSPACE-CONSTRAINED PRECONDITIONING FOR RIM 31
2024
- [72]
-
[73]
Y. Wang, Y. Sun, D. Han, and J. Xie. Linear convergence of Gearhart–Koshy accelerated Kaczmarz methods for tensor linear systems.arXiv preprint arXiv:2604.05816, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[74]
R. Weiss. Error-minimizing Krylov subspace methods.SIAM J. Sci. Comput., 15(3):511–527, 1994
1994
-
[75]
R. Weiss. A theoretical overview of Krylov subspace methods.Appl. Numer. Math., 19(3):207–233, 1995
1995
- [76]
-
[77]
Xie, H.-D
J. Xie, H.-D. Qi, and D. Han. Randomized iterative methods for generalized absolute value equations: solvability and error bounds.SIAM J. Optim., 35(3):1731–1760, 2025
2025
-
[78]
Xie and Z
J. Xie and Z. Xu. Subset selection for matrices with fixed blocks.Israel J. Math., 245(1):1–26, 2021
2021
- [79]
-
[80]
Randomized conjugate gradient least squares
Y. Zeng, J.-F. Cai, D. Han, and J. Xie. Randomized conjugate gradient least squares.arXiv preprint arXiv:2605.25034, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.