GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
Pith reviewed 2026-06-29 08:42 UTC · model grok-4.3
The pith
GDSD reframes RL for diffusion language models as normalization-free self-distillation from a closed-form self-teacher.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
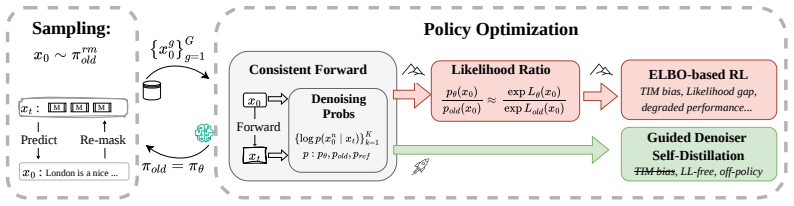
GDSD matches the dLLM's denoiser logits to the teacher's via a normalization-free objective, which reduces RL to likelihood-free self-distillation and thus bypasses the TIM biases. Recent ELBO-based methods emerge as instances of applying different distillation divergences, but with diagnosable pathologies that GDSD avoids.
What carries the argument
Advantage-guided self-teacher obtained from the closed-form optimum of reverse-KL regularized RL, paired with normalization-free logit matching for denoiser distillation.
If this is right
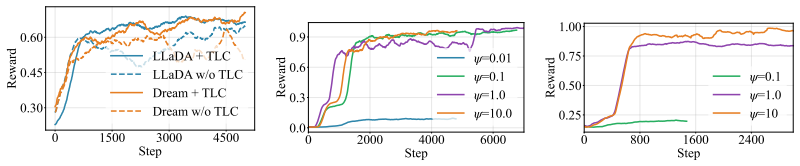
- GDSD produces up to +19.6% higher test accuracy than ELBO-based RL on the reported benchmarks.
- Training reward curves remain more stable under GDSD than under ELBO surrogates.
- ELBO methods appear as special cases of distillation divergences that introduce avoidable pathologies.
- The approach eliminates the need for random masking to estimate likelihood surrogates.
Where Pith is reading between the lines
- The same closed-form teacher construction could be tested on other diffusion or autoregressive models where exact likelihoods remain intractable.
- If the normalization-free matching proves robust, it may simplify reward-aligned fine-tuning pipelines that currently rely on multiple importance-sampling corrections.
- Scaling the self-teacher to larger dLLMs would test whether the closed-form optimum remains computationally tractable at higher parameter counts.
Load-bearing premise
The closed-form optimum of reverse-KL regularized RL supplies an unbiased self-teacher whose logits can be matched directly without new approximation errors.
What would settle it
If GDSD applied to LLaDA-8B or Dream-7B on the same planning/math/coding benchmarks yields no accuracy gain or unstable rewards relative to the best ELBO baseline, the claim that bypassing TIM via self-distillation improves RL would be falsified.
Figures



read the original abstract
Reinforcement learning (RL) can be used to improve the policy (denoiser) of diffusion large language models (dLLMs), while being hindered by the intractability of the policy likelihood. A dominant and efficient family of methods replaces the likelihood in standard RL with its evidence lower bound (ELBO), estimated from randomly masked sequences. Despite being well aligned with pre-training, these approaches introduce bias through training--inference mismatch by using the ELBO as a likelihood surrogate, which can degrade performance. In this work, we propose Guided Denoiser Self-Distillation (GDSD) to directly distill the denoiser of dLLMs from an advantage-guided self-teacher, derived from the closed-form optimum of reverse-KL regularized RL. GDSD matches the dLLM's denoiser logits to the teacher's via a normalization-free objective, which reduces RL to likelihood-free self-distillation and thus bypasses the TIM biases. Recent ELBO-based methods emerge as instances of applying different distillation divergences, but with diagnosable pathologies that GDSD avoids. On planning, math, and coding benchmarks with LLaDA-8B and Dream-7B, GDSD consistently outperforms prior state-of-the-art ELBO-based methods with a more stable training reward dynamics, achieving test-accuracy improvements of up to $+19.6\%$. These results suggest that direct denoiser self-distillation, without relying on an ELBO likelihood surrogate, can provide a more stable and effective RL procedure for dLLMs. Code is available at https://github.com/GaryBall/GDSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard ELBO-based RL for diffusion LLMs introduces training-inference mismatch (TIM) bias, and proposes GDSD as a fix: derive an advantage-guided self-teacher from the closed-form optimum of reverse-KL regularized RL, then perform normalization-free logit matching to reduce RL to likelihood-free self-distillation. This is asserted to bypass TIM biases while recovering prior ELBO methods as special cases with pathologies; experiments on LLaDA-8B and Dream-7B report up to +19.6% gains on planning/math/coding benchmarks with more stable reward dynamics.
Significance. If the closed-form self-teacher is exactly unbiased and the normalization-free matching introduces no new approximation error in the discrete masked setting, the approach would provide a cleaner and more stable RL procedure for dLLMs than ELBO surrogates. The code release supports reproducibility, but the central claim rests on the validity of the reduction, which is not yet verified from the provided abstract-level description.
major comments (2)
- [Derivation of self-teacher (abstract + §3)] The central reduction (abstract and likely §3): the claim that the advantage-guided self-teacher is the exact closed-form optimum of reverse-KL regularized RL, allowing direct normalization-free logit matching to eliminate TIM bias, requires explicit verification that this optimum remains exact and computable without continuous relaxations or implicit normalization in the discrete token/masking schedule of dLLMs. The skeptic's concern that this may reintroduce approximation error is load-bearing for attributing gains to the proposed mechanism rather than other factors.
- [Experiments (§5)] Experimental attribution (likely §5 and tables): the reported +19.6% gains and stable dynamics are presented as evidence that GDSD bypasses ELBO biases, but without ablations isolating the effect of the normalization-free objective versus the self-teacher construction, it is unclear whether the improvements stem from the claimed mechanism or from other implementation choices.
minor comments (2)
- [Abstract] The abstract states that recent ELBO methods 'emerge as instances of applying different distillation divergences' but does not specify which divergences or provide the mapping; this should be made explicit with equations.
- [Notation and preliminaries] Notation for the normalization-free objective and the advantage-guided teacher should be introduced with clear definitions before the main claims, to aid readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Derivation of self-teacher (abstract + §3)] The central reduction (abstract and likely §3): the claim that the advantage-guided self-teacher is the exact closed-form optimum of reverse-KL regularized RL, allowing direct normalization-free logit matching to eliminate TIM bias, requires explicit verification that this optimum remains exact and computable without continuous relaxations or implicit normalization in the discrete token/masking schedule of dLLMs. The skeptic's concern that this may reintroduce approximation error is load-bearing for attributing gains to the proposed mechanism rather than other factors.
Authors: Section 3 derives the advantage-guided self-teacher directly as the closed-form optimum of the reverse-KL regularized objective over the discrete token distribution induced by the dLLM masking schedule. The derivation uses only the exact token probabilities and does not invoke continuous relaxations or implicit normalization; the subsequent normalization-free logit matching is obtained by algebraic rearrangement of this optimum. We can add a short clarifying paragraph in §3 that explicitly states the absence of approximation error in the discrete case. revision: partial
-
Referee: [Experiments (§5)] Experimental attribution (likely §5 and tables): the reported +19.6% gains and stable dynamics are presented as evidence that GDSD bypasses ELBO biases, but without ablations isolating the effect of the normalization-free objective versus the self-teacher construction, it is unclear whether the improvements stem from the claimed mechanism or from other implementation choices.
Authors: We agree that the current experimental section does not contain ablations that isolate the normalization-free objective from the self-teacher construction. We will add these ablations (e.g., variants that retain the self-teacher but revert to a normalized distillation loss) to the revised §5 and tables. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper derives the advantage-guided self-teacher from the closed-form optimum of reverse-KL regularized RL (a standard result in the RL literature) and then reduces the problem to normalization-free logit matching. No load-bearing step is shown to reduce by construction to a fitted parameter, a self-citation chain, or a redefinition of the target quantity. The abstract and claimed mechanism treat the closed-form optimum as an external theoretical input rather than an internal fit or self-referential ansatz. Empirical gains are reported separately from the derivation. This is the common honest case of a self-contained argument against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arel’s sudoku generator
Arel. Arel’s sudoku generator. https://www.ocf.berkeley.edu/~arel/sudoku/main. html, 2025. Accessed: 2025-04-08
2025
-
[2]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models.arXiv preprint arXiv:2503.09573, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Huayu Chen, Cheng Lu, Zhengyi Wang, Hang Su, and Jun Zhu. Score regularized policy optimization through diffusion behavior.arXiv preprint arXiv:2310.07297, 2023
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Shirui Chen, Jiantao Jiao, Lillian J Ratliff, and Banghua Zhu. dultra: Ultra-fast diffusion language models via reinforcement learning.arXiv preprint arXiv:2512.21446, 2025
-
[9]
Safe and stable control via lyapunov- guided diffusion models.arXiv preprint arXiv:2509.25375, 2025
Xiaoyuan Cheng, Xiaohang Tang, and Yiming Yang. Safe and stable control via lyapunov- guided diffusion models.arXiv preprint arXiv:2509.25375, 2025
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[11]
Jaemoo Choi, Yuchen Zhu, Wei Guo, Petr Molodyk, Bo Yuan, Jinbin Bai, Yi Xin, Molei Tao, and Yongxin Chen. Rethinking the design space of reinforcement learning for diffusion models: On 10 the importance of likelihood estimation beyond loss design.arXiv preprint arXiv:2602.04663, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences, 55(1):119–139, 1997
Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of computer and system sciences, 55(1):119–139, 1997
1997
-
[14]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
-
[15]
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639, 2025
-
[16]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[17]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
Zemin Huang, Zhiyang Chen, Zijun Wang, Tiancheng Li, and Guo-Jun Qi. Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models.arXiv preprint arXiv:2505.10446, 2025
-
[20]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Diffusion policy optimization without drifting apart
Haozhe Jiang, Haiwen Feng, Jiantao Jiao, Angjoo Kanazawa, and Nika Haghtalab. Diffusion policy optimization without drifting apart. InICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy
2026
-
[22]
Mercury: Ultra-Fast Language Models Based on Diffusion
Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, Aditya Grover, and V olodymyr Kuleshov. Mercury: Ultra-Fast Language Models Based on Diffusion, 2025. URLhttps://arxiv.org/abs/2506.17298
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR. OpenReview.net, 2024
2024
-
[24]
When speed kills stability: Demystifying RL collapse from the training-inference mismatch, September 2025
Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Zhuo Jiang. When speed kills stability: Demystifying RL collapse from the training-inference mismatch, September 2025. URLhttps://richardli.xyz/rl-collapse
2025
-
[25]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-Like Training: A Critical Perspective.arXiv preprint arXiv:2503.20783, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Contrastive Energy Prediction for Exact Energy-Guided Diffusion Sampling in Offline Reinforcement Learning
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive Energy Prediction for Exact Energy-Guided Diffusion Sampling in Offline Reinforcement Learning. InInternational Conference on Machine Learning, pages 22825–22855. PMLR, 2023
2023
-
[28]
What makes a good diffusion planner for decision making?arXiv preprint arXiv:2503.00535, 2025
Haofei Lu, Dongqi Han, Yifei Shen, and Dongsheng Li. What makes a good diffusion planner for decision making?arXiv preprint arXiv:2503.00535, 2025
-
[29]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
-
[30]
Concrete Score Matching: Generalized Score Matching for Discrete Data.Advances in Neural Information Processing Systems, 35:34532–34545, 2022
Chenlin Meng, Kristy Choi, Jiaming Song, and Stefano Ermon. Concrete Score Matching: Generalized Score Matching for Discrete Data.Advances in Neural Information Processing Systems, 35:34532–34545, 2022
2022
-
[31]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large Language Diffusion Models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Principled rl for diffusion llms emerges from a sequence-level perspective
Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jianwen Xie, Stefano Ermon, Yi Wu, and Chongxuan Li. Principled rl for diffusion llms emerges from a sequence-level perspective. arXiv preprint arXiv:2512.03759, 2025
-
[33]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data, 2025. URLhttps://arxiv.org/abs/2406.03736
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Training Language Models to Follow Instructions with Human Feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training Language Models to Follow Instructions with Human Feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[35]
Tinyzero
Jiayi Pan, Junjie Zhang, Xingyao Wang, Lifan Yuan, Hao Peng, and Alane Suhr. Tinyzero. https://github.com/Jiayi-Pan/TinyZero, 2025. Accessed: 2025-01-24
2025
-
[36]
Simon Park, Abhishek Panigrahi, Yun Cheng, Dingli Yu, Anirudh Goyal, and Sanjeev Arora. Generalizing from simple to hard visual reasoning: Can we mitigate modality imbalance in vlms?arXiv preprint arXiv:2501.02669, 2025
-
[37]
Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788, 2025
Penghui Qi, Zichen Liu, Xiangxin Zhou, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788, 2025
-
[38]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model.Advances in Neural Information Processing Systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model.Advances in Neural Information Processing Systems, 36:53728–53741, 2023
2023
-
[39]
Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[41]
Approximating kl divergence, 2020.URL http://joschu
John Schulman. Approximating kl divergence, 2020.URL http://joschu. net/blog/kl-approx. html, 2020
2020
-
[42]
Trust Region Policy Optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust Region Policy Optimization. InInternational conference on machine learning, pages 1889–
-
[43]
Energy matching based preference learning for diffusion language models
Shiv Shankar. Energy matching based preference learning for diffusion language models. InPro- ceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 4: Student Research Workshop), pages 776–786, 2026
2026
-
[44]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
2024
- [46]
-
[47]
Policy gradient meth- ods for reinforcement learning with function approximation.Advances in neural information processing systems, 12, 1999
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient meth- ods for reinforcement learning with function approximation.Advances in neural information processing systems, 12, 1999
1999
-
[48]
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838, 2025
-
[49]
Rspo: Regularized self-play alignment of large language models.arXiv preprint arXiv:2503.00030, 2025
Xiaohang Tang, Sangwoong Yoon, Seongho Son, Huizhuo Yuan, Quanquan Gu, and Ilija Bogunovic. Rspo: Regularized self-play alignment of large language models.arXiv preprint arXiv:2503.00030, 2025
-
[50]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Gilad Turok, Chris De Sa, and V olodymyr Kuleshov. Duel: Exact likelihood for masked diffusion via deterministic unmasking.arXiv preprint arXiv:2603.01367, 2026
-
[52]
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Chengyu Wang, Paria Rashidinejad, DiJia Su, Song Jiang, Sid Wang, Siyan Zhao, Cai Zhou, Shannon Zejiang Shen, Feiyu Chen, Tommi Jaakkola, et al. Spg: Sandwiched policy gradient for masked diffusion language models.arXiv preprint arXiv:2510.09541, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
d2: Improving Reasoning in Diffusion Language Models via Trajectory Likelihood Estimation
Guanghan Wang, Yair Schiff, Gilad Turok, and V olodymyr Kuleshov. d2: Improved techniques for training reasoning diffusion language models.arXiv preprint arXiv:2509.21474, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutioniz- ing reinforcement learning framework for diffusion large language models.arXiv preprint arXiv:2509.06949, 2025
-
[55]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2208.06193, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
Chenxing Wei, Jiazhen Kang, Hong Wang, Jianqing Zhang, Hao Jiang, Xiaolong Xu, Ningyuan Sun, Ying He, F Richard Yu, Yao Shu, et al. Lfpo: Likelihood-free policy optimization for masked diffusion models.arXiv preprint arXiv:2603.01563, 2026
-
[57]
Self-play preference optimization for language model alignment.arXiv preprint arXiv:2405.00675, 2024
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-play preference optimization for language model alignment.arXiv preprint arXiv:2405.00675, 2024
-
[58]
MMaDA: Multimodal Large Diffusion Language Models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal Large Diffusion Language Models.arXiv preprint arXiv:2505.15809, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Acecoder: Acing coder rl via automated test-case synthesis, 2025
Huaye Zeng, Dongfu Jiang, Haozhe Wang, Ping Nie, Xiaotong Chen, and Wenhu Chen. Acecoder: Acing coder rl via automated test-case synthesis, 2025. URLhttps://arxiv.org/ abs/2502.01718
-
[61]
Shiyuan Zhang, Weitong Zhang, and Quanquan Gu. Energy-Weighted Flow Matching for Offline Reinforcement Learning.arXiv preprint arXiv:2503.04975, 2025
-
[62]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling Reasoning in Dif- fusion Large Language Models via Reinforcement Learning.arXiv preprint arXiv:2504.12216, 2025
-
[63]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Jianyuan Zhong, Kaibo Wang, Ding Ding, Zijin Feng, Haoli Bai, Yang Xiang, Jiacheng Sun, and Qiang Xu. Stabilizing reinforcement learning for diffusion language models.arXiv preprint arXiv:2603.06743, 2026
-
[65]
Banghua Zhu, Hiteshi Sharma, Felipe Vieira Frujeri, Shi Dong, Chenguang Zhu, Michael I Jordan, and Jiantao Jiao. Fine-Tuning Language Models with Advantage-Induced Policy Alignment.arXiv preprint arXiv:2306.02231, 2023
-
[66]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models.arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Yuchen Zhu, Wei Guo, Jaemoo Choi, Petr Molodyk, Bo Yuan, Molei Tao, and Yongxin Chen. Enhancing reasoning for diffusion llms via distribution matching policy optimization.arXiv preprint arXiv:2510.08233, 2025. 14 A Proof A.1 Lemma: Token-level Logit Centralization Lemma A.1.Denote the n-th token of clean completion x0 as x(n) 0 , for any MDM p, we have th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.