Quotient DAGs for Off-Policy Evaluation:Forward-Flow Importance Sampling and Exact Slate Propensities
Pith reviewed 2026-06-29 08:58 UTC · model grok-4.3
The pith
Quotient DAGs merge equivalent histories to compute exact unordered slate propensities without factorial sums.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For slate recommendation under a set-sufficient next-item interface, the quotient-DAG view yields Forward-DP, a subset-DAG dynamic program that computes exact unordered propensities without factorial enumeration by using target-to-behavior forward-flow ratios on the merged graph.
What carries the argument
Quotient-DAG that merges histories equivalent for evaluation and assigns weights using forward-flow importance sampling ratios on the merged graph.
If this is right
- The resulting propensity primitive enables practical propensity-based evaluation for context-dependent autoregressive slate loggers.
- Exact unordered slate propensities can be obtained without summing over all generation orders.
- Forward-flow ratios on the merged graph supply the correct importance weights once equivalent histories are identified.
Where Pith is reading between the lines
- The same merging step could reduce variance in importance-sampling estimates whenever the evaluation metric is invariant to order.
- Quotient constructions of this form may extend to other sequential processes in which only the set of chosen actions affects the outcome.
- The approach offers a template for handling symmetries between logging and evaluation policies in off-policy settings.
Load-bearing premise
The reward and downstream estimator depend only on the unordered slate and the next-item interface is set-sufficient.
What would settle it
Compute the Forward-DP propensity for a small slate and verify that it equals the direct sum of the behavior-policy probabilities over every possible ordering of that slate.
Figures

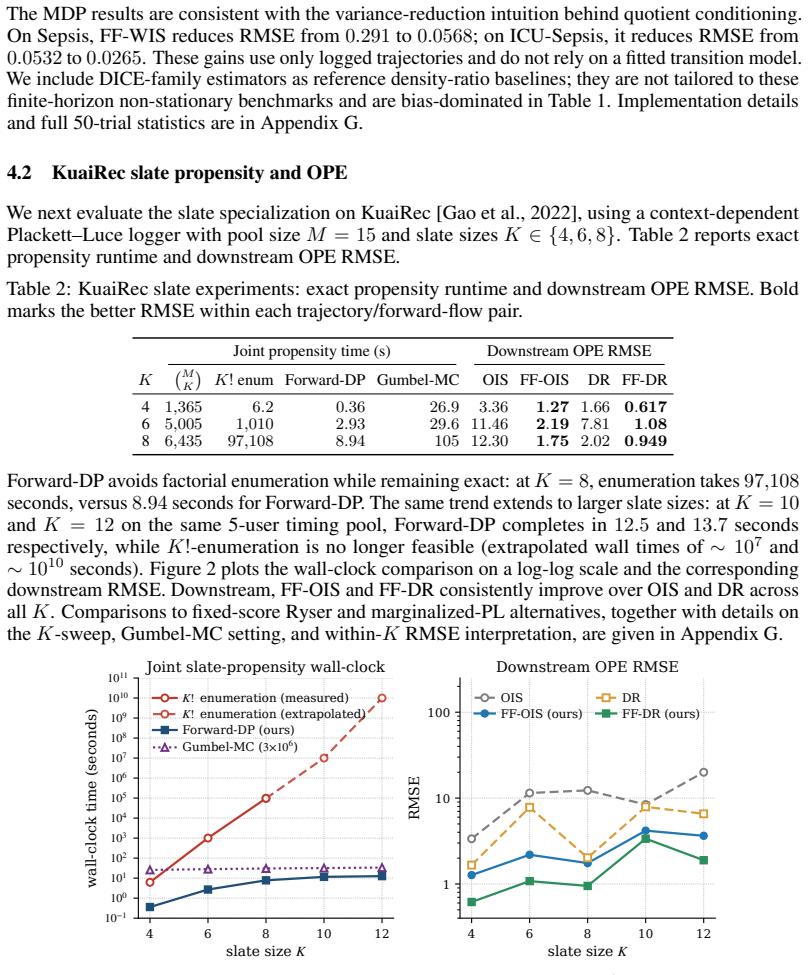

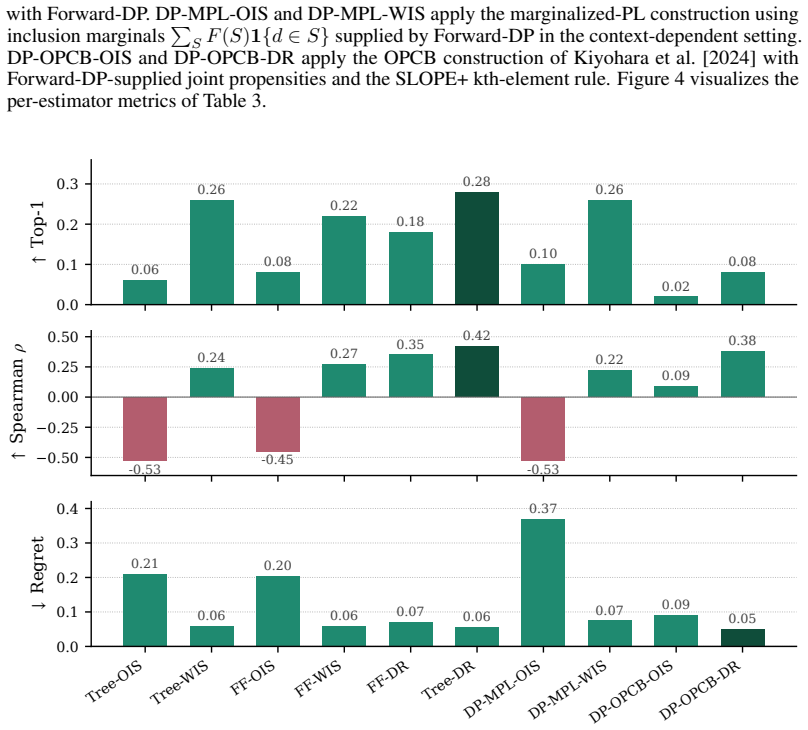
read the original abstract
Off-policy evaluation estimates how a target policy would perform using data collected by a different behavior policy, which is crucial when online testing is costly or risky, such as in recommendation or healthcare. Standard importance sampling reweights each logged trajectory, but it can treat details of the generation process as meaningful even when the evaluation target ignores them: for example, an autoregressive slate recommender may generate an ordered sequence of items while the reward and downstream estimator depend only on the unordered slate. This creates nuisance variance and a computational gap, since exact unordered slate propensities require summing over all generation orders. We introduce a quotient-DAG view that merges histories equivalent for evaluation and assigns weights using target-to-behavior forward-flow ratios on the merged graph. For slate recommendation under a set-sufficient next-item interface, this yields Forward-DP, a subset-DAG dynamic program that computes exact unordered propensities without factorial enumeration. The resulting propensity primitive enables practical propensity-based evaluation and model selection for context-dependent autoregressive slate loggers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a quotient-DAG representation of the slate generation process that merges histories equivalent under the evaluation metric (unordered slate). It defines forward-flow importance sampling ratios on this merged graph and, for set-sufficient next-item interfaces, derives Forward-DP: a subset-DAG dynamic program that computes exact unordered slate propensities without enumerating permutations. The resulting propensity estimator is intended to support lower-variance off-policy evaluation and model selection when the reward and downstream estimator depend only on the unordered slate.
Significance. If the derivation holds, the method supplies an exact, computationally tractable propensity primitive for a practically relevant class of autoregressive slate loggers. This directly addresses the factorial blow-up that currently prevents exact importance sampling in ordered slate generation, and the graph-theoretic reduction may generalize to other sequential settings where only a quotient of the trajectory matters. The explicit statement of the set-sufficiency and unordered-reward assumptions makes the scope of the claim clear.
minor comments (2)
- The abstract and introduction repeatedly use the term 'set-sufficient next-item interface' without a formal definition or reference to the precise interface condition used in the Forward-DP construction; a short paragraph or boxed definition early in §2 would improve readability.
- Notation for the forward-flow ratio (target-to-behavior) is introduced in the abstract but not contrasted with the conventional backward importance weight; a one-line comparison in the related-work section would help readers situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive summary, and significance assessment of the quotient-DAG approach. The recommendation of minor revision is noted. No specific major comments were raised in the report, so we provide no point-by-point responses below.
Circularity Check
No significant circularity; new graph reduction applied to explicit modeling assumptions
full rationale
The paper introduces quotient DAGs and forward-flow ratios as a new construction for off-policy evaluation on slates where rewards depend only on unordered sets. Forward-DP is presented as a dynamic program on the resulting subset-DAG that avoids factorial enumeration. No derivation step reduces by construction to a fitted parameter, self-definition, or load-bearing self-citation; the set-sufficiency condition and unordered-slate reward dependence are stated as explicit modeling choices rather than derived outputs. The central claim is a computational reduction whose correctness is independent of any internal fit or renaming of known results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The reward and downstream estimator depend only on the unordered slate
- domain assumption Set-sufficient next-item interface
invented entities (3)
-
Quotient DAG
no independent evidence
-
Forward-DP
no independent evidence
-
forward-flow ratios
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Miroslav Dudík, John Langford, and Lihong Li
arXiv:2205.08084. Miroslav Dudík, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. In Lise Getoor and Tobias Scheffer, editors,Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, USA, June 28 - July 2, 2011, pages 1097–1104. Omnipress,
-
[2]
KuaiRec: A fully-observed dataset and insights for evaluating recom- mender systems
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. KuaiRec: A fully-observed dataset and insights for evaluating recom- mender systems. In Mohammad Al Hasan and Li Xiong, editors,Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, O...
2022
-
[3]
doi: 10.1145/3511808.3557220. Ge Gao, Jonathan D. Chang, Claire Cardie, Kianté Brantley, and Thorsten Joachims. Policy-gradient training of language models for ranking.CoRR, abs/2310.04407,
-
[5]
doi: 10.1145/3523227.3546767. Nan Jiang and Lihong Li. Doubly robust off-policy value evaluation for reinforcement learning. In Maria-Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of the 33rd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, JMLR Workshop and Conference Proceedings, pages 652...
-
[6]
Wang-Cheng Kang and Julian J. McAuley. Self-attentive sequential recommendation. InIEEE International Conference on Data Mining, ICDM 2018, Singapore, November 17-20, 2018, pages 197–206. IEEE Computer Society,
2018
-
[7]
doi: 10.1109/ICDM.2018.00035. SASRec. Haruka Kiyohara, Masatoshi Uehara, Yusuke Narita, Nobuyuki Shimizu, Yasuo Yamamoto, and Yuta Saito. Off-policy evaluation of ranking policies under diverse user behavior. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2023, Long Beach, CA, USA, August 6-10, 2023, pages 1154...
-
[8]
doi: 10.1145/3580305. 3599447. AIPS estimator. Haruka Kiyohara, Masahiro Nomura, and Yuta Saito. Off-policy evaluation of slate bandit policies via optimizing abstraction. In Tat-Seng Chua, Chong-Wah Ngo, Ravi Kumar, Hady W. Lauw, and Roy Ka-Wei Lee, editors,Proceedings of the ACM on Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, pages 3150–3161. ACM,
-
[9]
doi: 10.1145/3589334.3645343. OPCB estimator. Matthieu Komorowski, Leo A. Celi, Omar Badawi, Anthony C. Gordon, and A. Aldo Faisal. The Artificial Intelligence Clinician learns optimal treatment strategies for sepsis in intensive care. Nature Medicine, 24(11):1716–1720,
-
[10]
Wouter Kool, Herke van Hoof, and Max Welling
doi: 10.1038/s41591-018-0213-5. Wouter Kool, Herke van Hoof, and Max Welling. Stochastic beams and where to find them: The Gumbel-top-k trick for sampling sequences without replacement. InProceedings of the 36th International Conference on Machine Learning (ICML),
-
[11]
Understanding the curse of horizon in off- policy evaluation via conditional importance sampling
10 Yao Liu, Pierre-Luc Bacon, and Emma Brunskill. Understanding the curse of horizon in off- policy evaluation via conditional importance sampling. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Proceedings of Machine Learning Research, pages 6184–6193. PMLR,
2020
-
[12]
Chi, and Qiaozhu Mei
Jiaqi Ma, Xinyang Yi, Weijing Tang, Zhe Zhao, Lichan Hong, Ed H. Chi, and Qiaozhu Mei. Learning- to-rank with partitioned preference: Fast estimation for the Plackett-Luce model. In Arindam Banerjee and Kenji Fukumizu, editors,The 24th International Conference on Artificial Intelligence and Statistics, AISTATS 2021, April 13-15, 2021, Virtual Event, Proce...
2021
-
[13]
Ashique Rupam Mahmood, Hado van Hasselt, and Richard S. Sutton. Weighted importance sampling for off-policy learning with linear function approximation. In Zoubin Ghahramani, Max Welling, Corinna Cortes, Neil D. Lawrence, and Kilian Q. Weinberger, editors,Advances in Neural Infor- mation Processing Systems 27: Annual Conference on Neural Information Proce...
2014
-
[14]
Concept-driven off policy evaluation.CoRR, abs/2411.19395,
Ritam Majumdar, Jack Teversham, and Sonali Parbhoo. Concept-driven off policy evaluation.CoRR, abs/2411.19395,
-
[16]
Michael Oberst and David A. Sontag. Counterfactual off-policy evaluation with Gumbel-max structural causal models. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Proceedings of Machine Learning Research, pages 4881–4890. PMLR,
2019
-
[17]
Pavse and Josiah P
Brahma S. Pavse and Josiah P. Hanna. Scaling marginalized importance sampling to high-dimensional state-spaces via state abstraction. In Brian Williams, Yiling Chen, and Jennifer Neville, editors, Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Washington, DC, USA, February 7-14, 2023, pages 9417–9425. AAAI Press,
2023
-
[18]
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
doi: 10.1609/aaai.v37i8.26128. Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. RankZephyr: Effective and robust zero-shot listwise reranking is a breeze!CoRR, abs/2312.02724,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v37i8.26128
-
[19]
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
doi: 10.48550/ARXIV . 2312.02724. Doina Precup, Richard S. Sutton, and Satinder Singh. Eligibility traces for off-policy policy evaluation. In Pat Langley, editor,Proceedings of the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford University, Stanford, CA, USA, June 29 - July 2, 2000, pages 759–766. Morgan Kaufmann,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2000
-
[20]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Mahesh Sathiamoorthy. Recommender systems with generative retrieval. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in N...
2023
-
[21]
Mark Rowland, Anna Harutyunyan, Hado van Hasselt, Diana Borsa, Tom Schaul, Rémi Munos, and Will Dabney
TIGER. Mark Rowland, Anna Harutyunyan, Hado van Hasselt, Diana Borsa, Tom Schaul, Rémi Munos, and Will Dabney. Conditional importance sampling for off-policy learning. In Silvia Chiappa and Roberto Calandra, editors,The 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020, 26-28 August 2020, Online [Palermo, Sicily, Italy]...
2020
-
[22]
Effective off-policy evaluation and learning in contextual combinatorial bandits
11 Tatsuhiro Shimizu, Koichi Tanaka, Ren Kishimoto, Haruka Kiyohara, Masahiro Nomura, and Yuta Saito. Effective off-policy evaluation and learning in contextual combinatorial bandits. In Tommaso Di Noia, Pasquale Lops, Thorsten Joachims, Katrien Verbert, Pablo Castells, Zhenhua Dong, and Ben London, editors,Proceedings of the 18th ACM Conference on Recomm...
2024
-
[23]
doi: 10.1145/3640457.3688099. Slate-OPE via abstraction. Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Wenwu Zhu, Dacheng Tao, Xueqi Cheng, Peng Cui, Elke A. Rundensteiner, David Carmel, Qi He, and Jeffrey Xu Yu, editors,Proce...
-
[24]
doi: 10.1145/3357384.3357895. Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. Is ChatGPT good at search? investigating large language models as re-ranking agents. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proc...
-
[25]
doi: 10.18653/v1/2023.emnlp-main.923. Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miroslav Dudík, John Langford, Damien Jose, and Imed Zitouni. Off-policy evaluation for slate recommendation. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural I...
-
[26]
Thomas and Emma Brunskill
Philip S. Thomas and Emma Brunskill. Data-efficient off-policy policy evaluation for reinforcement learning. In Maria-Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of the 33rd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, JMLR Workshop and Conference Proceedings, pages 2139–2148. JMLR.org,
2016
-
[27]
Minimax weight and q-function learning for off-policy evaluation
Masatoshi Uehara, Jiawei Huang, and Nan Jiang. Minimax weight and q-function learning for off-policy evaluation. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, Proceedings of Machine Learning Research, pages 9659–9668. PMLR,
2020
-
[28]
Control variates for slate off-policy evaluation
Nikos Vlassis, Ashok Chandrashekar, Fernando Amat Gil, and Nathan Kallus. Control variates for slate off-policy evaluation. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Ne...
2021
-
[29]
Towards optimal off-policy evaluation for reinforce- ment learning with marginalized importance sampling
Tengyang Xie, Yifei Ma, and Yu-Xiang Wang. Towards optimal off-policy evaluation for reinforce- ment learning with marginalized importance sampling. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché Buc, Emily B. Fox, and Roman Garnett, editors,Advances in Neural Information Processing Systems 32: Annual Conference on Neural Inform...
2019
-
[30]
GenDICE: Generalized offline estimation of stationary values
Ruiyi Zhang, Bo Dai, Lihong Li, and Dale Schuurmans. GenDICE: Generalized offline estimation of stationary values. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30,
2020
-
[31]
The target policy is π= softmax(Q ∗) at temperature 0.1, and the behavior policy is β=ϵ -greedy(Q∗) at ϵ= 0.3
is a stochastic MDP with 720 ground states, 8 actions, horizon H= 5 , and terminal rewards {+1,0,−1} for discharge, non- terminal, and death respectively. The target policy is π= softmax(Q ∗) at temperature 0.1, and the behavior policy is β=ϵ -greedy(Q∗) at ϵ= 0.3 . The ground-truth value is V(π) =−0.2683 . The learned-abstraction baselines in Table 1 are...
2023
-
[32]
and trained for 20,000 steps (DualDICE) or 15,000 steps (GenDICE) with Adam, batch size 2048, and gradient clipping at norm
2048
-
[33]
converged
DualDICE uses the primal form (ζ(s, a) =∂f(bellman) for f(x) =x 2/2); GenDICE uses the saddle-point form with τ≥0 via softplus, learning rates (ητ , ηf) = (10−4,10 −3), normalization penalty λ= 10 , and chi-square penalty α= 1 . Each estimator is run for 50 trials with seeds {43, . . . ,92}. The reported Table 1 entries are bias, std, and RMSE relative to...
2018
-
[34]
The left panel compares exact enumeration over all K! generation orders, Forward-DP, and a Gumbel-top- K Monte Carlo estimator [Kool et al., 2019]
KuaiRec scaling details for Figure 2.Figure 2 evaluates how slate size K affects both joint- propensity computation and downstream OPE. The left panel compares exact enumeration over all K! generation orders, Forward-DP, and a Gumbel-top- K Monte Carlo estimator [Kool et al., 2019]. Direct K!-enumeration is measured up to K= 8 and extrapolated for K >8 , ...
2019
-
[35]
Lower than 1.00 indicates lower RMSE than the denominator
Table 5: Within-K RMSE ratios on KuaiRec (M= 15 , nusers = 300, ntrials = 200). Lower than 1.00 indicates lower RMSE than the denominator. Ratios should be compared within the same K, not across differentK. KFF-OIS / OIS DR / OIS FF-DR / OIS FF-DR / DR 40.378 0.494 0.184 0.372 60.191 0.682 0.094 0.138 80.142 0.164 0.077 0.470 100.497 0.941 0.401 0.426 120...
2019
-
[36]
Full proofs appear in Appendix A (§A.1, §A.3, §A.4, §A.6)
state their assumptions in the proposition body. Full proofs appear in Appendix A (§A.1, §A.3, §A.4, §A.6). The variance gap derivation specialized to slate OPE is in §A.5. Guidelines: • The answer [N/A] means that the paper does not include theoretical results. • All the theorems, formulas, and proofs in the paper should be numbered and cross- referenced...
2019
-
[37]
Guidelines: • The answer [N/A] means that the paper does not include experiments
The Qwen2.5-3B logit cache for the cross-architecture run is the only GPU-dependent step and is amortized once per user. Guidelines: • The answer [N/A] means that the paper does not include experiments. • The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage. • The pape...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.