KGEdit: Ambiguity-Aware Knowledge Graphs for Training-Free Precise Video Generation and Editing
Pith reviewed 2026-06-29 08:44 UTC · model grok-4.3
The pith
KGEdit builds an ambiguity-aware knowledge graph to convert text prompts into four structured semantic types for precise training-free video editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
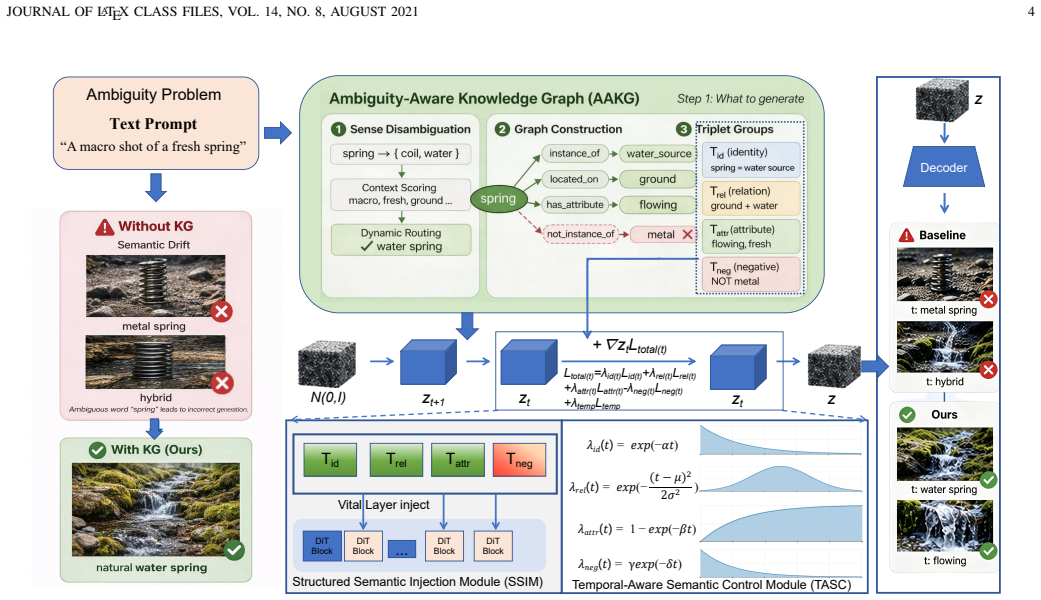
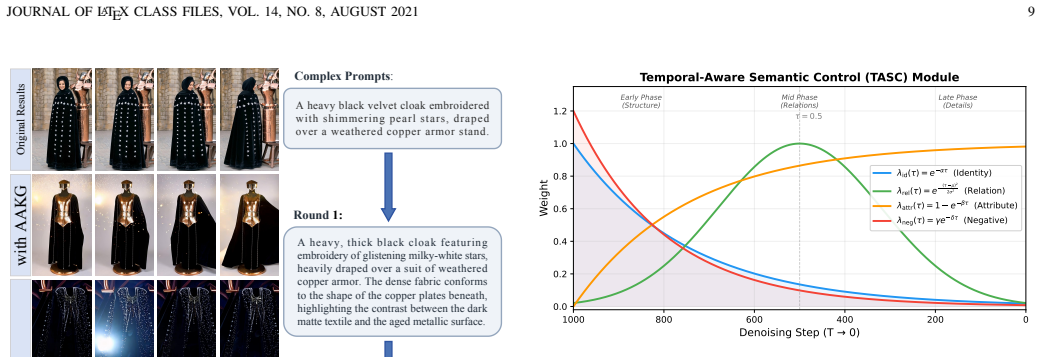
KGEdit constructs an ambiguity-aware knowledge graph that disentangles the input prompt into four structured semantic types: identity, relation, attribute, and negative constraints. A structured semantic injection module then places these signals into key layers of the diffusion Transformer, while a temporal-aware semantic control module dynamically schedules the objectives according to the stage of the denoising process. Experiments show the resulting system delivers higher editing precision, better temporal stability, and greater controllability than prior training-free methods.
What carries the argument
The ambiguity-aware knowledge graph that converts a prompt into the four semantic types (identity, relation, attribute, negative constraints) for targeted injection into the diffusion Transformer.
If this is right
- Enables fine-grained control over which objects, actions, properties, and exclusions appear in each video frame.
- Reduces cross-frame inconsistency by aligning semantic signals to the progressive stages of denoising.
- Supports text-driven video editing at higher efficiency than methods that require model fine-tuning.
- Improves controllability when users issue complex natural-language instructions.
Where Pith is reading between the lines
- The same graph-based disentanglement could be tested on image-only or audio generation pipelines that currently suffer from prompt ambiguity.
- If the four-type breakdown proves reliable, downstream interfaces could expose sliders or checkboxes for each semantic category instead of free text.
- The approach might lower the amount of prompt iteration users need before obtaining acceptable output.
Load-bearing premise
The step that builds the ambiguity-aware knowledge graph can correctly and completely separate any prompt into the four semantic types without errors or missing context.
What would settle it
Apply the method to a collection of prompts that contain overlapping attributes and relations; if the generated videos show the same binding or consistency errors as baseline methods, the central claim does not hold.
Figures




read the original abstract
In recent years, training-free video generation has progressed remarkably. However, when handling complex textual instructions, existing methods still suffer from semantic ambiguity, incorrect concept binding, and cross-frame inconsistency. To address these issues, we propose KGEdit, a structured semantic control framework for text-to-video (T2V) diffusion models. Specifically, we first construct an ambiguity-aware knowledge graph (AAKG) to disentangle and disambiguate the input prompt, converting it into four types of structured semantics: identity, relation, attribute, and negative constraints. We then design a structured semantic injection module (SSIM) to inject these semantic signals into key layers of the diffusion Transformer, enabling fine-grained semantic control. In addition, we introduce a temporal-aware semantic control (TASC) module that dynamically schedules semantic objectives according to the stage-wise characteristics of the denoising process, further improving semantic alignment and temporal consistency. Experiments show that KGEdit outperforms existing methods in editing precision and temporal stability, while offering higher efficiency and controllability in text-driven interaction scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KGEdit, a training-free framework for text-to-video diffusion models that constructs an ambiguity-aware knowledge graph (AAKG) to disentangle input prompts into four structured semantic types (identity, relation, attribute, negative constraints). It introduces a structured semantic injection module (SSIM) to inject these signals into key layers of the diffusion Transformer and a temporal-aware semantic control (TASC) module to dynamically schedule objectives during denoising. The central claim is that this yields superior editing precision, temporal stability, efficiency, and controllability over existing methods in complex text-driven scenarios.
Significance. If the AAKG construction reliably extracts the claimed semantic types without errors and the reported gains are substantiated, the approach could meaningfully advance training-free T2V editing by providing explicit, structured control over semantic binding and temporal consistency. The training-free nature and focus on prompt disambiguation address recognized pain points in the field.
major comments (2)
- [Abstract] Abstract: the claim that 'Experiments show that KGEdit outperforms existing methods in editing precision and temporal stability' is unsupported by any quantitative results, baselines, ablation studies, or implementation details in the provided description; without these, the central performance claims cannot be evaluated.
- [Method (AAKG)] AAKG construction step: the framework's downstream modules (SSIM and TASC) depend entirely on correct disentanglement of arbitrary prompts into identity/relation/attribute/negative constraints, yet no algorithm, LLM prompt template, validation metric (e.g., human agreement), or failure-case analysis is described, leaving the weakest assumption unverified and the attribution of gains unsubstantiated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript to strengthen the presentation of results and method details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments show that KGEdit outperforms existing methods in editing precision and temporal stability' is unsupported by any quantitative results, baselines, ablation studies, or implementation details in the provided description; without these, the central performance claims cannot be evaluated.
Authors: The abstract is a high-level summary; the full manuscript (Section 4) contains the supporting quantitative results, including direct comparisons to baselines on editing precision and temporal stability metrics, ablation studies, and implementation details. The claim is grounded in those experiments. We will revise the abstract to reference specific gains where space permits. revision: partial
-
Referee: [Method (AAKG)] AAKG construction step: the framework's downstream modules (SSIM and TASC) depend entirely on correct disentanglement of arbitrary prompts into identity/relation/attribute/negative constraints, yet no algorithm, LLM prompt template, validation metric (e.g., human agreement), or failure-case analysis is described, leaving the weakest assumption unverified and the attribution of gains unsubstantiated.
Authors: We agree that the AAKG construction requires fuller documentation to allow verification and attribution of gains. The revised version will add the complete algorithm, LLM prompt template, human agreement validation metrics, and failure-case analysis. revision: yes
Circularity Check
No circularity: framework modules are independently specified without reduction to inputs
full rationale
The paper describes KGEdit via three new modules (AAKG construction to produce four semantic types, SSIM for injection into the diffusion Transformer, and TASC for stage-wise scheduling) followed by experimental comparisons. No equations, fitted parameters, self-citations used as load-bearing premises, or derivations that reduce by construction to prior results appear in the abstract or described chain. The performance claims rest on external benchmarks rather than any self-referential renaming or prediction-from-fit step, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Adv. Neural Inf. Process. Syst., vol. 33, pp. 6840–6851, 2020
2020
-
[2]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inICLR, 2021
2021
-
[3]
Pyramidal flow matching for efficient video generative modeling,
Y . Jin, Z. Sun, N. Liet al., “Pyramidal flow matching for efficient video generative modeling,”arXiv preprint arXiv:2410.05954, 2024
-
[4]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inICCV, 2023, pp. 4195–4205
2023
-
[5]
Make-A-Video: Text-to-Video Generation without Text-Video Data
U. Singer, A. Polyak, T. Hayeset al., “Make-a-video: Text-to-video generation without text-video data,”arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Align your latents: High- resolution video synthesis with latent diffusion models,
A. Blattmann, R. Rombach, H. Linget al., “Align your latents: High- resolution video synthesis with latent diffusion models,” inCVPR, 2023, pp. 22 563–22 575
2023
-
[7]
Cogvideox: Text-to-video diffusion models with an expert transformer,
Z. Yang, J. Teng, W. Zhenget al., “Cogvideox: Text-to-video diffusion models with an expert transformer,” inICLR, 2025
2025
-
[8]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhanget al., “Hunyuanvideo: A system- atic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
LTX-Video: Realtime Video Latent Diffusion
Y . HaCohen, N. Chiprut, B. Brazowskiet al., “Ltx-video: Realtime video latent diffusion,”arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Goku: Flow based video generative foundation models,
S. Chen, C. Ge, Y . Zhanget al., “Goku: Flow based video generative foundation models,” inCVPR, 2025, pp. 23 516–23 527
2025
-
[11]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation,
J. Z. Wu, Y . Ge, X. Wanget al., “Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation,” inICCV, 2023, pp. 7623–7633
2023
-
[12]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
S. Zhang, J. Wang, Y . Zhanget al., “I2vgen-xl: High-quality image- to-video synthesis via cascaded diffusion models,”arXiv preprint arXiv:2311.04145, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Videocomposer: Compositional video synthesis with motion controllability,
X. Wang, H. Yuan, S. Zhanget al., “Videocomposer: Compositional video synthesis with motion controllability,” inNeurIPS, 2023
2023
-
[14]
W. Chen, Y . Ji, J. Wuet al., “Control-a-video: Controllable text-to-video diffusion models with motion prior and reward feedback learning,”arXiv preprint arXiv:2305.13840, 2024
-
[15]
Motionctrl: A unified and flexible motion controller for video generation,
Z. Wang, Z. Yuan, X. Wanget al., “Motionctrl: A unified and flexible motion controller for video generation,” inSIGGRAPH, 2024, pp. 1–11
2024
-
[16]
Video-p2p: Video editing with cross-attention control,
S. Liu, Y . Zhang, W. Li, Z. Lin, and J. Jia, “Video-p2p: Video editing with cross-attention control,” inCVPR, 2024, pp. 8599–8608
2024
-
[17]
Fatezero: Fusing attentions for zero-shot text-based video editing,
C. Qi, X. Cun, Y . Zhanget al., “Fatezero: Fusing attentions for zero-shot text-based video editing,” inICCV, 2023, pp. 15 932–15 942
2023
-
[18]
Tokenflow: Consistent diffusion features for consistent video editing,
M. Geyer, O. Bar-Tal, S. Bagon, and T. Dekel, “Tokenflow: Consistent diffusion features for consistent video editing,” inICLR, 2024
2024
-
[19]
FLATTEN: optical FLow- guided ATTENtion for consistent text-to-video editing,
Y . Cong, M. Xu, christian simonet al., “FLATTEN: optical FLow- guided ATTENtion for consistent text-to-video editing,” inICLR, 2024
2024
-
[20]
Fluencyve: Marrying temporal- aware mamba with bypass attention for video editing,
M. Cai, Y . Li, O. Yoshie, and Y . Ieiri, “Fluencyve: Marrying temporal- aware mamba with bypass attention for video editing,”IEEE Trans. Multimedia, pp. 1–12, 2026
2026
-
[21]
Controllable first-frame-guided video editing via mask-aware loRA fine-tuning,
C. Gao, L. Ding, X. Cai, Z. Huang, Z. Wang, and T. Xue, “Controllable first-frame-guided video editing via mask-aware loRA fine-tuning,” in ICLR, 2026
2026
-
[22]
Nova: Sparse control, dense synthesis for pair-free video editing,
T. Pan, J. Dai, C. Yuanet al., “Nova: Sparse control, dense synthesis for pair-free video editing,”arXiv preprint arXiv:2603.02802, 2026
-
[23]
Vace: All-in-one video creation and editing,
Z. Jiang, Z. Han, C. Mao, J. Zhang, Y . Pan, and Y . Liu, “Vace: All-in-one video creation and editing,” inICCV, 2025, pp. 17 191–17 202
2025
-
[24]
VOGUE: Unified understanding, genera- tion, and editing for videos,
C. Wei, Q. Liu, Z. Yeet al., “VOGUE: Unified understanding, genera- tion, and editing for videos,” inICLR, 2026
2026
-
[25]
Text-to-edit: Controllable end-to-end video ad creation via multimodal llms,
D. Cheng, H. Zhan, X. Zhaoet al., “Text-to-edit: Controllable end-to-end video ad creation via multimodal llms,”arXiv preprint arXiv:2501.05884, 2025
-
[26]
Motioncanvas: Cinematic shot design with controllable image-to-video generation,
J. Xing, L. Mai, C. Hamet al., “Motioncanvas: Cinematic shot design with controllable image-to-video generation,” inSIGGRAPH, 2025
2025
-
[27]
Gamefactory: Creating new games with generative interactive videos,
J. Yu, Y . Qin, X. Wang, P. Wan, D. Zhang, and X. Liu, “Gamefactory: Creating new games with generative interactive videos,” inICCV, 2025, pp. 11 590–11 599
2025
-
[28]
Exploring the frontiers of animation video generation in the sora era: Method, dataset and benchmark,
Y . Jiang, B. Xu, S. Yanget al., “Exploring the frontiers of animation video generation in the sora era: Method, dataset and benchmark,” in IJCAI, 2025
2025
-
[29]
Zero-shot video editing using off-the- shelf image diffusion models,
W. Wang, Y . Jiang, K. Xieet al., “Zero-shot video editing using off-the- shelf image diffusion models,”arXiv preprint arXiv:2303.17599, 2023
-
[30]
Anyv2v: A tuning-free framework for any video-to-video editing tasks,
M. Ku, C. Wei, W. Ren, H. Yang, and W. Chen, “Anyv2v: A tuning-free framework for any video-to-video editing tasks,”Trans. Mach. Learn. Res., 2024
2024
-
[31]
Enhancing low-cost video editing with lightweight adaptors and temporal-aware inversion,
Y . He, S. Li, J. Wanget al., “Enhancing low-cost video editing with lightweight adaptors and temporal-aware inversion,” inCPAL, 2026
2026
-
[32]
Controlvideo: Training-free controllable text-to-video generation,
Y . Zhang, Y . Wei, D. Jiang, X. ZHANG, W. Zuo, and Q. Tian, “Controlvideo: Training-free controllable text-to-video generation,” in ICLR, 2024
2024
-
[33]
Freebase: a collaboratively created graph database for structuring human knowl- edge,
K. Bollacker, C. Evans, P. Paritosh, T. Sturge, and J. Taylor, “Freebase: a collaboratively created graph database for structuring human knowl- edge,” inSIGMOD, 2008, pp. 1247–1250
2008
-
[34]
Wikidata: A new platform for collaborative data collec- tion,
D. Vrande ˇci´c, “Wikidata: A new platform for collaborative data collec- tion,” inWWW, 2012, pp. 1063–1064
2012
-
[35]
Translating embeddings for modeling multi-relational data,
A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,”Adv. Neu- ral Inf. Process. Syst., vol. 26, 2013
2013
-
[36]
VBench: Comprehensive benchmark suite for video generative models,
Z. Huang, Y . He, J. Yuet al., “VBench: Comprehensive benchmark suite for video generative models,” inCVPR, 2024
2024
-
[37]
Latte: Latent diffusion transformer for video generation,
X. Ma, Y . Wang, X. Chenet al., “Latte: Latent diffusion transformer for video generation,”Trans. Mach. Learn. Res., 2025
2025
-
[38]
Movie Gen: A Cast of Media Foundation Models
A. Polyak, A. Zohar, A. Brownet al., “Movie gen: A cast of media foundation models,”arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
T. Wan, A. Wang, B. Aiet al., “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Z. Zheng, X. Peng, Y . Louet al., “Open-sora 2.0: Training a commercial-level video generation model in $200 k,”arXiv preprint arXiv:2503.09642, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Vqa-gnn: Reasoning with multimodal knowledge via graph neural networks for visual question answering,
Y . Wang, M. Yasunaga, H. Ren, S. Wada, and J. Leskovec, “Vqa-gnn: Reasoning with multimodal knowledge via graph neural networks for visual question answering,” inICCV, 2023, pp. 21 582–21 592
2023
-
[42]
From pixels to graphs: Open-vocabulary scene graph generation with vision-language models,
R. Li, S. Zhang, D. Lin, K. Chen, and X. He, “From pixels to graphs: Open-vocabulary scene graph generation with vision-language models,” inCVPR, 2024, pp. 28 076–28 086
2024
-
[43]
Aligning vision to language: Annotation- free multimodal knowledge graph construction for enhanced llms rea- soning,
J. Liu, S. Meng, Y . Gaoet al., “Aligning vision to language: Annotation- free multimodal knowledge graph construction for enhanced llms rea- soning,” inICCV, 2025, pp. 981–992
2025
-
[44]
Reasonvqa: A multi-hop reasoning benchmark with structural knowledge for visual question answering,
D. T. Tran, T.-K. Tran, M. Hauswirth, and D. Le Phuoc, “Reasonvqa: A multi-hop reasoning benchmark with structural knowledge for visual question answering,” inICCV, 2025, pp. 18 793–18 803
2025
-
[45]
Prompt-to-prompt image editing with cross-attention control,
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or, “Prompt-to-prompt image editing with cross-attention control,” inThe Eleventh International Conference on Learning Rep- resentations, 2023
2023
-
[46]
Plug-and-play diffusion features for text-driven image-to-image translation,
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel, “Plug-and-play diffusion features for text-driven image-to-image translation,” inCVPR, 2023, pp. 1921–1930
2023
-
[47]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng, “Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing,” inICCV, 2023, pp. 22 560–22 570
2023
-
[48]
Personalize anything for free with diffusion transformer,
H. Feng, Z. Huang, L. Li, and L. Sheng, “Personalize anything for free with diffusion transformer,” inAAAI, vol. 40, no. 5, 2026, pp. 3921– 3929
2026
-
[49]
Stable flow: Vital layers for training-free image editing,
O. Avrahami, O. Patashnik, O. Friedet al., “Stable flow: Vital layers for training-free image editing,” inCVPR, 2025, pp. 7877–7888
2025
-
[50]
Kv-edit: Training-free image editing for precise background preservation,
T. Zhu, S. Zhang, J. Shao, and Y . Tang, “Kv-edit: Training-free image editing for precise background preservation,” inICCV, 2025, pp. 16 607– 16 617
2025
-
[51]
Freecus: Free lunch subject- driven customization in diffusion transformers,
Y . Zhang, Z. Wang, Q. Zhou, and M. Yang, “Freecus: Free lunch subject- driven customization in diffusion transformers,” inICCV, 2025, pp. 15 521–15 531
2025
-
[52]
Ti2v-zero: Zero-shot image condition- ing for text-to-video diffusion models,
H. Ni, B. Egger, S. Lohitet al., “Ti2v-zero: Zero-shot image condition- ing for text-to-video diffusion models,” inCVPR, 2024, pp. 9015–9025
2024
-
[53]
Text2video- zero: Text-to-image diffusion models are zero-shot video generators,
L. Khachatryan, A. Movsisyan, V . Tadevosyanet al., “Text2video- zero: Text-to-image diffusion models are zero-shot video generators,” inICCV, 2023, pp. 15 954–15 964
2023
-
[54]
Large language models are frame-level directors for zero-shot text-to-video generation,
S. Hong, J. Seo, H. Shin, S. Hong, and S. Kim, “Large language models are frame-level directors for zero-shot text-to-video generation,” inICML Workshop, 2023
2023
-
[55]
Free-bloom: Zero-shot text-to-video generator with llm director and ldm animator,
H. Huang, Y . Feng, C. Shi, L. Xu, J. Yu, and S. Yang, “Free-bloom: Zero-shot text-to-video generator with llm director and ldm animator,” Adv. Neural Inf. Process. Syst., vol. 36, pp. 26 135–26 158, 2023
2023
-
[56]
Eidt-v: Exploiting intersec- tions in diffusion trajectories for model-agnostic, zero-shot, training-free text-to-video generation,
D. Jagpal, X. Chen, and V . P. Namboodiri, “Eidt-v: Exploiting intersec- tions in diffusion trajectories for model-agnostic, zero-shot, training-free text-to-video generation,” inCVPR, 2025, pp. 18 219–18 228
2025
-
[57]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inCVPR, 2022, pp. 10 684–10 695
2022
-
[58]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/ forum?id=PxTIG12RRHS
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.