MINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
Pith reviewed 2026-06-29 07:12 UTC · model grok-4.3
The pith
Mindgames provides four game environments that test LLM agents on belief attribution, opponent modeling, cooperative inference, and sustained deception while exposing brittle rule adherence and error confounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
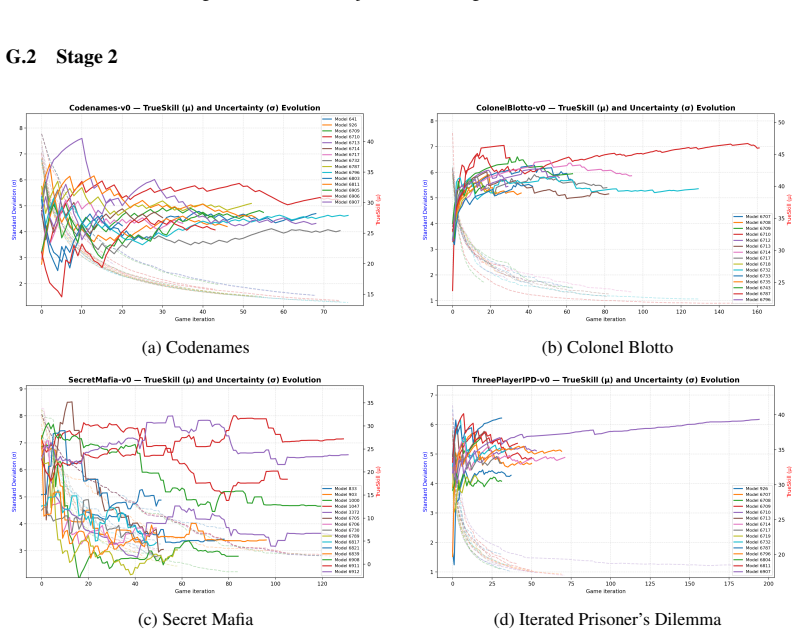
Mindgames operationalizes complementary reasoning demands relevant to theory of mind through Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia, using a unified interface, TrueSkill ratings, and full trajectory logging. Analysis of the competition cycle surfaces agent-level limitations such as brittle rule adherence and reliance on structural scaffolding, along with evaluation-level issues including differing leaderboard validity across games and a pronounced error-survival confound in Secret Mafia.
What carries the argument
The four-game arena with TrueSkill-based rating and error-attribution lens that scores agents on belief attribution under hidden information, opponent modeling through repeated interaction, cooperative inference under knowledge asymmetries, and sustained deception.
If this is right
- Brittle rule adherence remains a major bottleneck for current LLM agents in multi-agent settings.
- Top systems repeatedly depend on explicit structural scaffolding to succeed.
- Leaderboard validity differs sharply across the four environments.
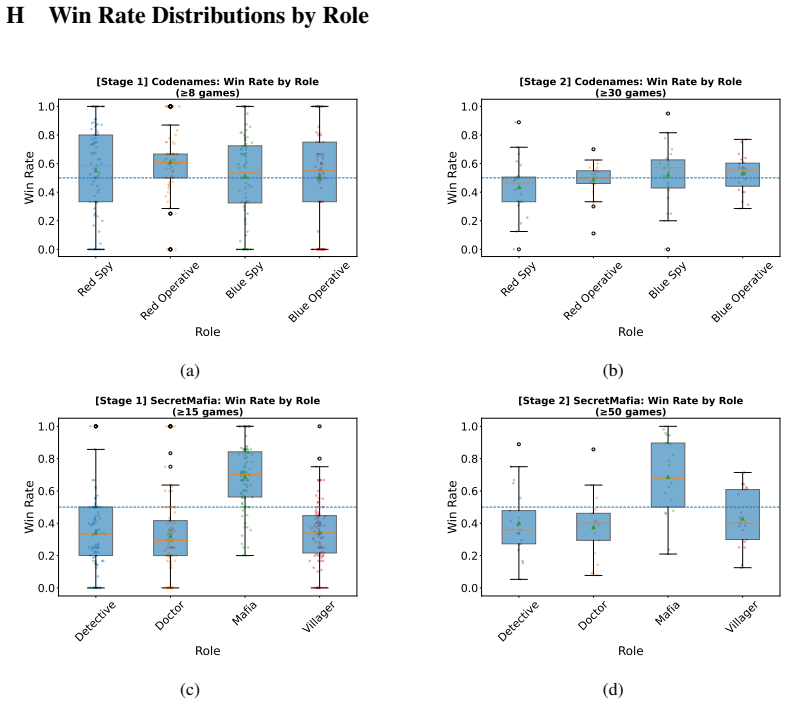
- Failure-heavy games can reward robustness to opponent errors as much as strategic ability.
- The released dataset of 29,571 games and the MG-Ref offline protocol enable consistent scoring of new agents against a frozen reference pool.
Where Pith is reading between the lines
- Developers may need training methods that build intrinsic rule following rather than reliance on external prompts.
- The error-survival pattern observed in one game could appear in other dynamic, failure-prone evaluation setups.
- Extending the arena with additional games could test further reasoning demands not covered by the current four.
- Real-world multi-agent deployments of LLMs may face similar confounds when opponents or teammates make mistakes.
Load-bearing premise
The four chosen games together with TrueSkill ratings and error-attribution analysis supply a valid, non-confounded measure of the targeted social and strategic reasoning skills.
What would settle it
Demonstrating that top agents reach high performance without explicit scaffolding or that Secret Mafia shows no measurable error-survival advantage would undermine the reported limitations and confounds.
Figures









read the original abstract
Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mindgames, a multi-game arena built on TextArena for evaluating social and strategic reasoning in multi-agent LLMs. It operationalizes theory-of-mind-relevant demands via four environments (Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, Secret Mafia), reports results from a 2025 competition with 944 agents from 76 teams, identifies agent-level and evaluation-level limitations including brittle rule adherence and an error-survival confound, and releases a dataset of 29,571 games plus the MG-Ref deterministic offline tournament protocol.
Significance. If the evaluation design is shown to isolate the targeted reasoning skills, the work supplies a useful open platform, large trajectory dataset, and reference protocol that could support reproducible progress on multi-agent LLM benchmarks beyond static vignettes. The explicit surfacing of evaluation confounds and the competition-scale data are concrete strengths for the field.
major comments (2)
- [Abstract] Abstract: the central claim that the four games plus TrueSkill rating and error-attribution lens supply a non-confounded measure of distinct ToM-relevant skills (belief attribution, opponent modeling, cooperative inference, sustained deception) is load-bearing, yet the abstract itself states that 'failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound'. It is unclear whether the rating system includes documented adjustments for variable player counts, team structure, or high-variance LLM play, or whether the error-attribution procedure prevents rather than post-hoc labels this confound.
- [Abstract] Abstract (analysis of leaderboard validity): the claim that top-performing systems rely on explicit structural scaffolding and that leaderboard validity differs sharply across environments rests on the separation of strategic ability from rule-following robustness; without explicit validation that the TrueSkill application and error lens achieve this separation, the surfaced limitations and agent rankings cannot be fully interpreted as measures of the intended reasoning demands.
minor comments (1)
- [Abstract] The abstract contains a minor notation inconsistency with double backticks around 'theory of mind'; standard LaTeX or single quotes would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below, clarifying that the manuscript does not assert a fully non-confounded isolation of skills but instead describes the operationalization alongside explicitly surfaced limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the four games plus TrueSkill rating and error-attribution lens supply a non-confounded measure of distinct ToM-relevant skills (belief attribution, opponent modeling, cooperative inference, sustained deception) is load-bearing, yet the abstract itself states that 'failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound'. It is unclear whether the rating system includes documented adjustments for variable player counts, team structure, or high-variance LLM play, or whether the error-attribution procedure prevents rather than post-hoc labels this confound.
Authors: The abstract does not advance a claim of supplying a non-confounded measure of the listed skills. It states that the four environments operationalize complementary ToM-relevant demands and then explicitly identifies the error-survival confound as an evaluation-level limitation observed in this cycle. TrueSkill is applied to observed outcomes without further documented adjustments for player counts, team structure, or LLM variance beyond the system's standard multi-player handling. The error-attribution procedure is a post-hoc labeling tool used to quantify and surface the confound, not to eliminate it. We will revise the abstract for added precision on this distinction. revision: partial
-
Referee: [Abstract] Abstract (analysis of leaderboard validity): the claim that top-performing systems rely on explicit structural scaffolding and that leaderboard validity differs sharply across environments rests on the separation of strategic ability from rule-following robustness; without explicit validation that the TrueSkill application and error lens achieve this separation, the surfaced limitations and agent rankings cannot be fully interpreted as measures of the intended reasoning demands.
Authors: The statements on structural scaffolding and differing leaderboard validity are empirical observations drawn from the 29k-game dataset after applying the error-attribution lens to separate rule violations from strategic actions. The manuscript presents these patterns and the resulting limitations without claiming that the lens or TrueSkill provides a formally validated separation of the targeted skills. A dedicated validation study would strengthen interpretation but is outside the scope of the current competition analysis. revision: no
Circularity Check
No circularity: empirical competition data with no derivation or fitted predictions
full rationale
The paper describes an empirical evaluation platform using four established games (Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, Secret Mafia), TrueSkill ratings, and a released dataset of 29,571 games. No mathematical derivations, equations, or parameter-fitting steps are present that could reduce claims to self-referential inputs. Analysis of agent limitations and error confounds is drawn directly from competition observations rather than constructed equivalences or self-citations. The central claims rest on external game rules and observed trajectories, making the work self-contained against benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four games operationalize belief attribution under hidden information, opponent modeling, cooperative inference under knowledge asymmetries, and sustained deception.
Reference graph
Works this paper leans on
-
[1]
Does the chimpanzee have a theory of mind?Behavioral and brain sciences, 1(4):515–526, 1978
David Premack and Guy Woodruff. Does the chimpanzee have a theory of mind?Behavioral and brain sciences, 1(4):515–526, 1978
1978
-
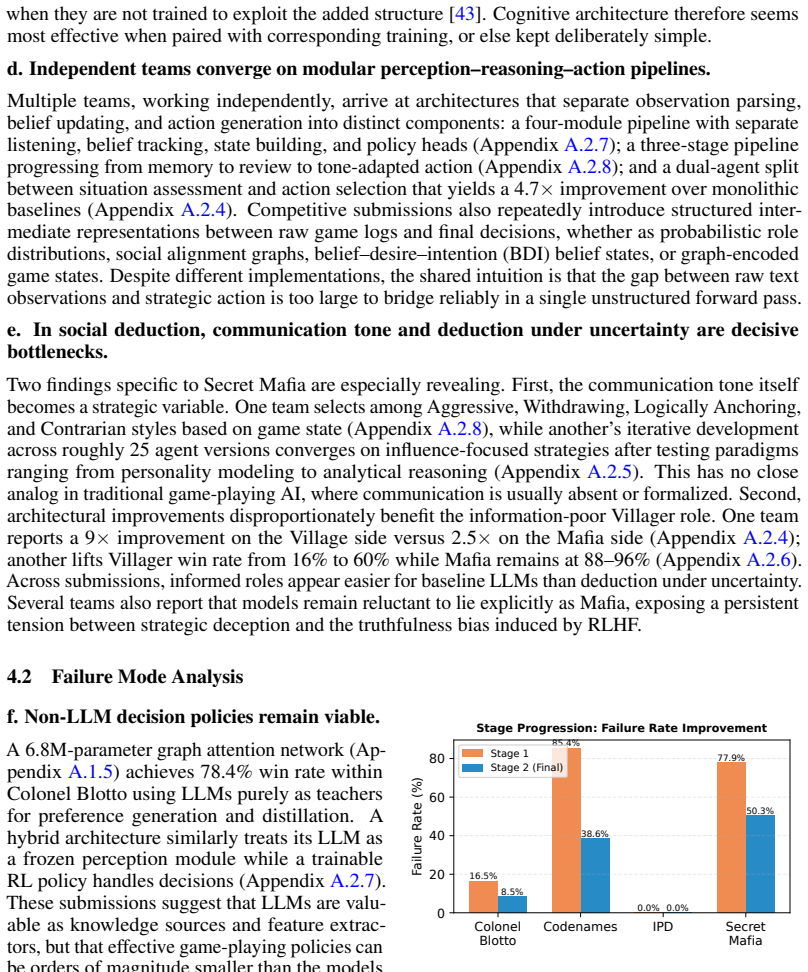
[2]
Tomer Ullman. Large language models fail on trivial alterations to theory-of-mind tasks.arXiv preprint arXiv:2302.08399, 2023
-
[3]
Weisz, and Murray Campbell
Matthew Riemer, Zahra Ashktorab, Djallel Bouneffouf, Payel Das, Miao Liu, Justin D. Weisz, and Murray Campbell. Position: Theory of mind benchmarks are broken for large language models, 2025. ICML 2025
2025
-
[4]
Fantom: A benchmark for stress-testing machine theory of mind in interactions
Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. Fantom: A benchmark for stress-testing machine theory of mind in interactions. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413, 2023
2023
-
[5]
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, and Michael R. Lyu. How far are we on the decision-making of LLMs? evaluating LLMs’ gaming ability in multi-agent environments. In International Conference on Learning Representations, 2025
2025
-
[6]
Large language models miss the multi-agent mark
Emanuele La Malfa, Gabriele La Malfa, Samuele Marro, Jie M Zhang, Elizabeth Black, Michael Luck, Philip Torr, and Michael Wooldridge. Large language models miss the multi-agent mark. arXiv preprint arXiv:2505.21298, 2025
-
[7]
Theory of mind for multi-agent collaboration via large language models
Huao Li, Yu Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Charles Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 180–192, Singapore, December 20
2023
-
[8]
doi: 10.18653/v1/2023.emnlp-main.13
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.13. URL https://aclanthology.org/2023.emnlp-main.13/
-
[9]
Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. Language agents with reinforcement learning for strategic play in the werewolf game.arXiv preprint arXiv:2310.18940, 2023
-
[10]
Playing repeated games with large language models.Nature Human Behaviour, 9(7):1380–1390, 2025
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. Playing repeated games with large language models.Nature Human Behaviour, 9(7):1380–1390, 2025
2025
-
[11]
lmgame-bench: How good are llms at playing games? arXiv preprint arXiv:2505.15146, 2025
Lanxiang Hu, Mingjia Huo, Yuxuan Zhang, Haoyang Yu, Eric P Xing, Ion Stoica, Tajana Rosing, Haojian Jin, and Hao Zhang. lmgame-bench: How good are llms at playing games? arXiv preprint arXiv:2505.15146, 2025
-
[12]
Haoran Sun, Yusen Wu, Peng Wang, Wei Chen, Yukun Cheng, Xiaotie Deng, and Xu Chu. Game theory meets large language models: A systematic survey with taxonomy and new frontiers.arXiv preprint arXiv:2502.09053, 2025
-
[13]
Autonomous agents modelling other agents: A compre- hensive survey and open problems.Artificial Intelligence, 258:66–95, 2018
Stefano V Albrecht and Peter Stone. Autonomous agents modelling other agents: A compre- hensive survey and open problems.Artificial Intelligence, 258:66–95, 2018
2018
-
[14]
PhD thesis, Carnegie Mellon University, 2025
Ini Oguntola.Theory of Mind in Multi-Agent Systems. PhD thesis, Carnegie Mellon University, 2025
2025
-
[15]
Multiagentbench: Evaluating the collaboration and competition of llm agents
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Daisy Zhe Wang, Zhenhailong Wang, Cheng Qian, Robert Tang, Heng Ji, et al. Multiagentbench: Evaluating the collaboration and competition of llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, 2025
2025
-
[16]
Zirui Song, Yuan Huang, Junchang Liu, Haozhe Luo, Chenxi Wang, Lang Gao, Zixiang Xu, Mingfei Han, Xiaojun Chang, and Xiuying Chen. Beyond survival: Evaluating llms in social deduction games with human-aligned strategies.arXiv preprint arXiv:2510.11389, 2025
- [17]
-
[18]
Trueskill™: a bayesian skill rating system
Ralf Herbrich, Tom Minka, and Thore Graepel. Trueskill™: a bayesian skill rating system. Advances in neural information processing systems, 19, 2006
2006
-
[19]
Avalonbench: Evaluating llms playing the game of avalon.arXiv preprint arXiv:2310.05036, 2023
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu. Avalonbench: Evaluating llms playing the game of avalon.arXiv preprint arXiv:2310.05036, 2023
-
[20]
Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations.Advances in Neural Information Processing Systems, 37:28219–28253, 2024
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, and Kaidi Xu. Gtbench: Uncovering the strategic reasoning capabilities of llms via game-theoretic evaluations.Advances in Neural Information Processing Systems, 37:28219–28253, 2024
2024
-
[21]
Jianzhu Yao, Kevin Wang, Ryan Hsieh, Haisu Zhou, Tianqing Zou, Zerui Cheng, Zhangyang Wang, and Pramod Viswanath. Spin-bench: How well do llms plan strategically and reason socially?arXiv preprint arXiv:2503.12349, 2025
-
[22]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis- Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, et al. Sotopia: Interactive evaluation for social intelligence in language agents.arXiv preprint arXiv:2310.11667, 2023
-
[23]
Tombench: Benchmarking theory of mind in large language models
Zhuang Chen, Jincenzi Wu, Jinfeng Zhou, Bosi Wen, Guanqun Bi, Gongyao Jiang, Yaru Cao, Mengting Hu, Yunghwei Lai, Zexuan Xiong, et al. Tombench: Benchmarking theory of mind in large language models. InProceedings of ACL, pages 15959–15983, 2024
2024
-
[24]
Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, and Naihao Deng. Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models. In Findings of EMNLP, pages 10691–10706, 2023. 21
2023
-
[25]
Understanding social reasoning in language models with language models.Advances in Neural Information Processing Systems, 36:13518–13529, 2023
Kanishk Gandhi, Jan-Philipp Fränken, Tobias Gerstenberg, and Noah Goodman. Understanding social reasoning in language models with language models.Advances in Neural Information Processing Systems, 36:13518–13529, 2023
2023
-
[26]
Opentom: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models
Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Yulan He. Opentom: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models. In Proceedings of ACL, pages 8593–8623, 2024
2024
-
[27]
Theory of mind: Mechanisms, methods, and new directions
Lindsey J Byom and Bilge Mutlu. Theory of mind: Mechanisms, methods, and new directions. Frontiers in human neuroscience, 7:413, 2013
2013
-
[28]
Suma Bailis, Jane Friedhoff, and Feiyang Chen. Werewolf arena: A case study in llm evaluation via social deduction.arXiv preprint arXiv:2407.13943, 2024
-
[29]
Hidden in plain text: Measuring llm deception quality against human baselines using social deduction games
Christopher Kao, Vanshika Vats, and James Davis. Hidden in plain text: Measuring llm deception quality against human baselines using social deduction games. In2025 IEEE International Conference on Agentic AI (ICA), pages 110–115. IEEE, 2025
2025
-
[30]
Fine-grained and thematic evalua- tion of llms in social deduction game.IEEE Access, 2025
Byungjun Kim, Dayeon Seo, Minju Kim, and Bugeun Kim. Fine-grained and thematic evalua- tion of llms in social deduction game.IEEE Access, 2025
2025
-
[31]
Codenames as a benchmark for large language models.IEEE Transactions on Games, 2025
Matthew Stephenson, Matthew Sidji, and Benoît Ronval. Codenames as a benchmark for large language models.IEEE Transactions on Games, 2025
2025
-
[32]
The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
Nolan Bard, Jakob N Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, et al. The hanabi challenge: A new frontier for ai research.Artificial Intelligence, 280:103216, 2020
2020
-
[33]
Human-level play in the game of diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022
Meta Fundamental AI Research Diplomacy Team (FAIR)†, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, et al. Human-level play in the game of diplomacy by combining language models with strategic reasoning.Science, 378(6624):1067–1074, 2022
2022
-
[34]
Richelieu: Self-evolving llm-based agents for ai diplomacy.Advances in Neural Information Processing Systems, 37: 123471–123497, 2024
Zhenyu Guan, Xiangyu Kong, Fangwei Zhong, and Yizhou Wang. Richelieu: Self-evolving llm-based agents for ai diplomacy.Advances in Neural Information Processing Systems, 37: 123471–123497, 2024
2024
-
[35]
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, and Arjun Yadav. Gamebench: Evaluating strategic reasoning abilities of llm agents.arXiv preprint arXiv:2406.06613, 2024
-
[36]
Game of thoughts: Iterative reasoning in game-theoretic domains with large language models
Benjamin Kempinski, Ian Gemp, Kate Larson, Marc Lanctot, Yoram Bachrach, and Tal Kach- man. Game of thoughts: Iterative reasoning in game-theoretic domains with large language models. AAMAS ’25, page 1088–1097, Richland, SC, 2025. International Foundation for Autonomous Agents and Multiagent Systems. ISBN 9798400714269
2025
-
[37]
Chandler Smith, Marwa Abdulhai, Manfred Diaz, Marko Tesic, Rakshit S Trivedi, Alexan- der Sasha Vezhnevets, Lewis Hammond, Jesse Clifton, Minsuk Chang, Edgar A Duéñez- Guzmán, et al. Evaluating generalization capabilities of llm-based agents in mixed-motive scenarios using concordia.arXiv preprint arXiv:2512.03318, 2025
-
[38]
https://www.mafiabench
MafiaBench: LLM social deduction via Mafia tournaments. https://www.mafiabench. org/, 2024
2024
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
The colonel blotto game.Economic Theory, 29(1):1–24, 2006
Brian Roberson. The colonel blotto game.Economic Theory, 29(1):1–24, 2006
2006
-
[41]
Evolution of strategies in the three-person iterated prisoner’s dilemma game.Journal of theoretical biology, 195(1):53–67, 1998
Masanao Matsushima and Takashi Ikegami. Evolution of strategies in the three-person iterated prisoner’s dilemma game.Journal of theoretical biology, 195(1):53–67, 1998. 22
1998
-
[42]
Mark Braverman, Omid Etesami, and Elchanan Mossel. Mafia: A theoretical study of players and coalitions in a partial information environment.The Annals of Applied Probability, 18(3): 825–846, 2008. doi: 10.1214/07-AAP456
-
[43]
Gpt-5 system card, 2025
OpenAI. Gpt-5 system card, 2025. URL https://openai.com/research/ gpt-5-system-card
2025
-
[44]
Yunfei Xie, Kevin Wang, Bobby Cheng, Jianzhu Yao, Zhizhou Sha, Alexander Duffy, Yihan Xi, Hongyuan Mei, Cheston Tan, Chen Wei, et al. Memo: Memory-augmented model context optimization for robust multi-turn multi-agent llm games.arXiv preprint arXiv:2603.09022, 2026
-
[45]
Long-context llms struggle with long in-context learning.arXiv preprint arXiv:2404.02060, 2024
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, and Wenhu Chen. Long-context llms struggle with long in-context learning.arXiv preprint arXiv:2404.02060, 2024
-
[46]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[47]
text-embedding-3-small, 2025
OpenAI. text-embedding-3-small, 2025. URL https://platform.openai.com/docs/ models/text-embedding-3-small
2025
-
[48]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 23 Project Contributors Core Contributors.Kevin Wang, Anna Thöni, Benjamin Kempinski, Bobby Cheng, Jianzhu Yao Core Advisors.Atlas Wang...
2018
-
[49]
Episodes are terminated with typed failure metadata when violations occur, enabling downstream attribution of responsibility
Action Validator: Enforces reasoning-template compliance, action-format constraints, and game-rule validity during gameplay. Episodes are terminated with typed failure metadata when violations occur, enabling downstream attribution of responsibility
-
[50]
Players Builder: Reconstructs outcomes after episode termination and computes granular episode-level rewards beyond binary win/loss (e.g., normalizing by fraction of rounds won in Colonel Blotto rather than match outcome alone), including responsibility attribution for premature termination
-
[51]
Crucially, error steps themselves remain eligible and receive penalty rewards to teach format compliance; only steps with no outcome to learn from are excluded
Steps Filter: Excludes training steps that lack observable outcomes — for instance, a valid Codenames clue whose operative produced a parsing failure has no guesses to evaluate and is therefore gated. Crucially, error steps themselves remain eligible and receive penalty rewards to teach format compliance; only steps with no outcome to learn from are excluded
-
[52]
Reward Assigner: Performs environment-specific backward attribution so that logically coupled actions share credit or blame based on realized outcomes. Per-step rewards are additionally modulated by episode outcome: actions in winning games receive full credit regardless of intermediate results, while the same actions in losing games receive reduced credi...
-
[53]
Guided Generation: Uses Pydantic-based constrained decoding to enforce structured output with a dedicated reasoning field, ensuring outputs conform to game-specific schemas
-
[54]
ReAct framework: The model generates self-authored code blocks within its reasoning traces, executing them inline for computation and verification
-
[55]
Zero-heuristic design principleA deliberate design choice: the system uses no hardcoded lookup tables, decision trees, or game-specific heuristics
PAL (Program-Aided Language): Deterministic computation is offloaded to Python execution, avoiding the numerical errors inherent in token-level arithmetic. Zero-heuristic design principleA deliberate design choice: the system uses no hardcoded lookup tables, decision trees, or game-specific heuristics. All strategic decisions emerge from code generation a...
-
[56]
Graph PPO training: Clipped PPO ( ϵ= 0.2 , γ= 0.99 , λ= 0.95 ) with auxiliary exploration and counterfactual updates
-
[57]
Meta learning: A bi-level update where a fast inner loop adapts FiLM parameters for 1–2 gradient steps to recent opponent behavior, while an outer loop optimizes for rapid adaptation
-
[58]
Each candidate is evaluated via 4 stochastic rollouts, producing approximately 2,300 preference pairs
Preference generation: Two teacher LLMs (Qwen 2.5-Instruct and Llama 3-Instruct) propose candidate actions. Each candidate is evaluated via 4 stochastic rollouts, producing approximately 2,300 preference pairs
-
[59]
Teacher alignment: Supervised fine-tuning on chosen actions followed by direct preference optimization (DPO) on preference pairs to align a teacher model
-
[60]
The graph policy is trained by cross-entropy imitation, then continues PPO training to stabilize performance
Policy distillation: The aligned teacher generates state-to-action labels for 2,000 sampled states. The graph policy is trained by cross-entropy imitation, then continues PPO training to stabilize performance. ResultsOn Colonel Blotto, the full curriculum attains a 78.40% win rate (95% CI: [77.36, 79.44]) over 1,000 games. PPO alone achieves 58.4% with a ...
-
[61]
Role-specific behavioral instructions guide strategy (e.g., Mafia agents are instructed to mislead without implicating teammates)
Hard Constraints: Prohibits identity leakage, repetition, and requires new reasoning each turn. Role-specific behavioral instructions guide strategy (e.g., Mafia agents are instructed to mislead without implicating teammates). 2.Game Message: Current game state and available actions
-
[62]
Win rates by configuration: Base 21.7% → +Prompt Refinement 25.0% → +Memory/Deduc- tion 16.7% → +SFT 45.0%
Observation: Filtered observation containing only system messages and player statements 4.Past Public Statements: The agent’s own previous public messages (for consistency) 5.Talk: Space for generating the current response Stage 2: Memory and deduction layer • Observation preprocessing: Regular expressions extract system-level information and player messa...
-
[63]
Key failure: Mafia agents frequently leak role information into public responses
Basic agent: A single LLM call generates the response directly. Key failure: Mafia agents frequently leak role information into public responses
-
[64]
An external harness extracts only the public action portion, architecturally preventing information leakage
Thinking agent: The model generates a private reasoning block enclosed in <outloud> XML tags, containing role-aware strategic analysis. An external harness extracts only the public action portion, architecturally preventing information leakage
-
[65]
Key finding: memory without fine-tuning hurtsCounterintuitively, the Remembering agent performedworsethan the Thinking agent
Remembering agent: Extends the Thinking agent with a <remembering> XML block for cross-turn knowledge persistence, where the LLM decides what to retain or discard. Key finding: memory without fine-tuning hurtsCounterintuitively, the Remembering agent performedworsethan the Thinking agent. Without fine-tuning, the 8B-parameter model could not reliably expl...
-
[66]
build coalition against Player 3
Strategy formulation: High-level objective selection (e.g., “build coalition against Player 3” or “deflect suspicion from teammate”) 2.Tactic selection: Specific action and dialogue that implements the chosen strategy Results across prompt configurationsThree configurations reveal the impact of the multi-agent decomposition: •Minimal prompts: 15.0% win ra...
-
[67]
Handles perspective-taking, social simulation, and theory of mind
Imaginative Thinking(inspired by the Default Mode Network): Generates hypotheses about what players might do, feel, or plan. Handles perspective-taking, social simulation, and theory of mind
-
[68]
Performs hypothesis verification, strategic planning, and vote optimization
Logical Thinking(inspired by the Task-Positive Network): Tests imaginative hypotheses against behavioral evidence. Performs hypothesis verification, strategic planning, and vote optimization
-
[69]
Inspired by neuroscience research on humor and surprise processing, this mode flags inconsistencies as potential deception cues
Deception Detection Thinking: Identifies expectation-violations, where a player’s state- ments or actions diverge from their predicted behavior pattern. Inspired by neuroscience research on humor and surprise processing, this mode flags inconsistencies as potential deception cues. Evolutionary developmentThe team tested approximately 25 agent versions, ev...
-
[70]
Global System Prompt: Game rules, mechanics, and a JSON reply protocol that separates reasoning from public action
-
[71]
Role-Specific Strategy Guidance: Goals and decision criteria tailored to the assigned role (not scripts, but principles) 3.Dynamic Game Context: Compact state snapshot from the State Analyzer BDI reasoning scaffold •Beliefs: Role probability estimates for each player, updated from behavioral evidence •Desires: Current strategic goals derived from role and...
-
[72]
Run self-play game batches
-
[73]
Perform role-level post-hoc analysis of wins and losses
-
[74]
as Villager, vote with the majority in early rounds to build credibility
Extract recurring heuristics from winning games (e.g., “as Villager, vote with the majority in early rounds to build credibility”)
-
[75]
Filter conflicting heuristics
-
[76]
less coupling can yield more robustness
Integrate surviving heuristics into role-specific strategy guidance ResultsProgressive ablation shows cumulative gains: ReAct baseline 52% → +Structured obser- vation 62% → +BDI reasoning 70% → +Self-improvement 78%. The largest gains accrue on the information-poor Villager side (16% → 60%), while Mafia performance remains consistently high (88–96%) acros...
-
[77]
This internal review is not shown to other players
Reviewer Agent: Takes the current game observation state (chat log, player status, game phase) and generates a detailed chain-of-thought review containing logical deductions, 32 contradiction detection, and a probability assessment of each player’s role. This internal review is not shown to other players
-
[78]
A perfectly logical deduction, if delivered in a dry, robotic, or socially inappropriate manner, will fail to persuade
Action Agent: Takes the original observation state and the Reviewer’s detailed analysis to formulate the final natural-language action (a statement, an accusation, or a vote). This separation ensures the final output is grounded in deep, structured analysis. Memory Module: Social Alignment GraphIntroduced in Revac2_1, the Memory Module overcomes short-ter...
-
[79]
[Trust and cooperation will benefit us all in the long run.]
-
[80]
Let’s try for cooperation early and see how the others react
[Okay, I agree with Player 0. Let’s try for cooperation early and see how the others react. My goal is to maximize my score while also trying to learn about the other players.] Action:[Player 2] [I agree with the plan to cooperate early...] Figure 10: Starting observation for Player 2 in Three-Player IPD. 34 Action space.The environment supports both comm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.