Learning Representations from 3D Gaussian Splats
Pith reviewed 2026-06-29 08:36 UTC · model grok-4.3
The pith
Point-based and graph-based models learn distinct representations from 3D Gaussian splats, with Gaussian attributes affecting quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
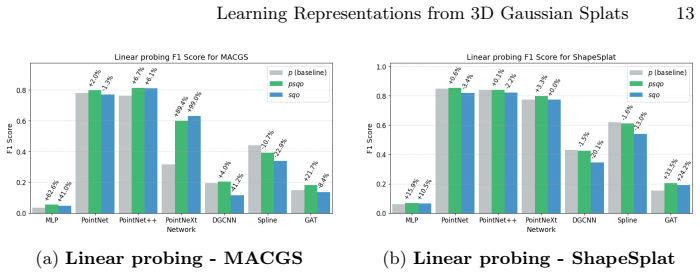
The study shows consistent differences between architectural families in their ability to process 3D Gaussian splat data, and demonstrates that Gaussian-specific attributes such as scale, rotation, and opacity influence the quality of the learned representations when used as input features.
What carries the argument
Comparative evaluation of point-based and graph-based models on Gaussian splat representations, assessed through latent embeddings from classification, probing, and clustering tasks.
If this is right
- Point-based and graph-based models show consistent differences in performance on Gaussian splat data.
- Gaussian-specific attributes impact the quality of learned representations.
- Different architectures are more or less suitable for 3DGS inputs.
- Evaluation through multiple methods like linear probing confirms the differences.
Where Pith is reading between the lines
- New architectures tailored to Gaussian splats could outperform adapted point cloud models.
- The results may apply to other downstream tasks such as 3D object detection using splat representations.
- Larger and more diverse Gaussian splat datasets could strengthen or refine the observed patterns.
Load-bearing premise
The chosen point-based and graph-based models together with the selected datasets are representative enough to draw general conclusions about the suitability of geometry-aware architectures for 3D Gaussian splat representations.
What would settle it
Finding a set of models or datasets where architectural families do not show consistent differences or where Gaussian attributes have no effect on representation quality would falsify the main claims.
Figures
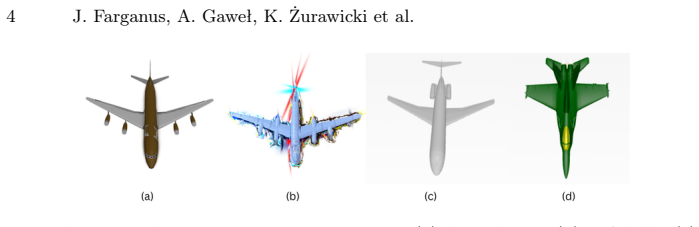
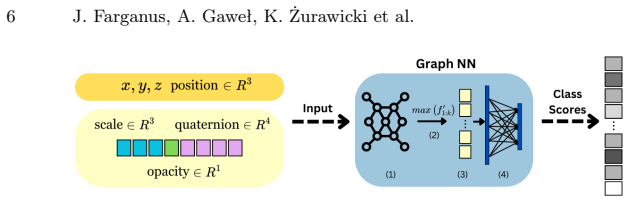
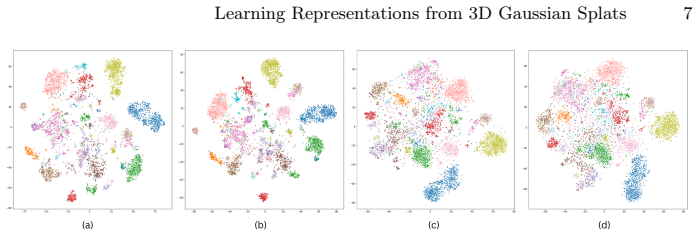
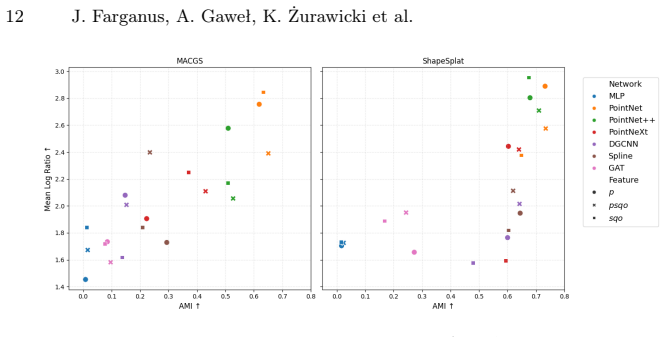
read the original abstract
3D Gaussian Splatting (3DGS) is a recent approach for scene rendering. Although primarily designed for view synthesis, its potential for scene understanding tasks remains underexplored. In this work, we conduct a comparative evaluation of various geometric deep learning architectures for the classification of 3D scenes represented using Gaussian Splatting. We benchmark point-based and graph-based models across both traditional point cloud datasets and dedicated Gaussian Splatting datasets. Scenes are embedded into latent representations, which are evaluated through end-to-end classification, linear probing, and clustering analysis. Our study provides insight into the suitability of different geometry-aware architectures and input feature configurations for learning effective 3D Gaussian Splat representations. The results highlight consistent differences between architectural families and reveal the impact of Gaussian-specific attributes on the quality of representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a comparative benchmark of point-based and graph-based geometric deep learning architectures applied to 3D scene classification where scenes are represented as 3D Gaussian Splats. It evaluates models on both standard point-cloud datasets and dedicated GS datasets, extracting latent representations that are assessed via end-to-end classification, linear probing, and clustering. The central claims are that architectural families exhibit consistent performance differences and that Gaussian-specific attributes improve representation quality.
Significance. If the benchmark selections prove representative, the multi-protocol evaluation supplies practical guidance on architecture and feature choices for downstream 3DGS scene-understanding tasks. The purely empirical design with three complementary protocols (end-to-end, linear probing, clustering) is a methodological strength that allows direct comparison of representation quality across input configurations.
major comments (2)
- [§4] §4 (Experimental Setup): the claim of 'consistent differences between architectural families' rests on a narrow selection of point-based and graph-based models; omission of attention-based or equivariant families means the observed patterns may be artifacts of the chosen subset rather than general properties of geometry-aware architectures on 3DGS inputs.
- [§4.3] §4.3 (Datasets and Results): the impact of Gaussian-specific attributes is demonstrated only on the selected traditional point-cloud and dedicated GS datasets; without explicit justification or ablation showing that these datasets cover diverse scene types, the general conclusion about attribute utility risks being benchmark-specific.
minor comments (2)
- The abstract and introduction would benefit from an explicit enumeration (or table reference) of the exact models and datasets used, to allow readers to assess representativeness immediately.
- Notation for Gaussian attributes (e.g., opacity, scale) should be defined once in a dedicated subsection rather than inline in multiple result paragraphs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our benchmark. We address each major comment below and indicate where revisions will be made to clarify limitations without altering the core empirical findings.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): the claim of 'consistent differences between architectural families' rests on a narrow selection of point-based and graph-based models; omission of attention-based or equivariant families means the observed patterns may be artifacts of the chosen subset rather than general properties of geometry-aware architectures on 3DGS inputs.
Authors: The manuscript explicitly scopes the study to point-based and graph-based families (see abstract and §4), as these are the architectures most directly applicable to 3D Gaussian Splats when treated as attributed point sets or graphs. The reported 'consistent differences between architectural families' refer specifically to performance patterns between these two families across the three evaluation protocols. We agree that attention-based and equivariant models represent important additional families; their omission means the patterns cannot be claimed as fully general across all geometry-aware architectures. In revision we will add a dedicated limitations paragraph in §4 noting this scope and recommending future inclusion of such models (e.g., Point Transformer variants) for broader validation. revision: partial
-
Referee: [§4.3] §4.3 (Datasets and Results): the impact of Gaussian-specific attributes is demonstrated only on the selected traditional point-cloud and dedicated GS datasets; without explicit justification or ablation showing that these datasets cover diverse scene types, the general conclusion about attribute utility risks being benchmark-specific.
Authors: The datasets comprise standard point-cloud benchmarks (ModelNet40, ShapeNet, ScanObjectNN) together with dedicated 3DGS scene datasets chosen because they are the primary publicly available resources that support both point-cloud and Gaussian-splat representations. These span synthetic objects, real indoor scans, and outdoor scenes. We acknowledge that an explicit justification of scene diversity and an accompanying discussion of potential benchmark specificity are currently absent. We will insert a short paragraph in §4.3 that (i) lists the scene categories represented, (ii) references prior usage of these datasets in the 3D vision literature, and (iii) states the limitation that broader scene diversity remains an open question for future work. revision: yes
Circularity Check
No significant circularity: purely empirical benchmarking study
full rationale
This is an empirical benchmarking paper that compares point-based and graph-based architectures on 3D Gaussian Splatting inputs via end-to-end classification, linear probing, and clustering. The abstract and described methodology contain no derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations. All claims derive from direct experimental results on chosen datasets and models, making the work self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Methods15, 399 – 400 (2018), https://api.semanticscholar.org/CorpusID:44115671
Altman, N., Krzywinski, M.: The curse(s) of dimensionality. Nature Methods15, 399 – 400 (2018), https://api.semanticscholar.org/CorpusID:44115671
2018
- [2]
-
[3]
Bronstein, M.M., Bruna, J., Cohen, T., Veličković, P.: Geometric deep learning: Grids, groups, graphs, geodesics, and gauges (2021), https://arxiv.org/abs/2104.13478
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Chen, Y., Liu, J., Zhang, X., Qi, X., Jia, J.: Voxelnext: Fully sparse voxelnet for 3d object detection and tracking. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 21674–21683 (2023)
2023
-
[6]
arXiv preprint arXiv:2410.13421 (2024)
Chopin, J., Dahyot, R.: Performance of gaussian mixture model classifiers on em- bedded feature spaces. arXiv preprint arXiv:2410.13421 (2024)
-
[7]
In: ICLR Workshop on Representation Learning on Graphs and Manifolds (2019)
Fey,M.,Lenssen,J.E.:FastgraphrepresentationlearningwithPyTorchGeometric. In: ICLR Workshop on Representation Learning on Graphs and Manifolds (2019)
2019
-
[8]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Fey, M., Lenssen, J.E., Weichert, F., Müller, H.: Splinecnn: Fast geometric deep learning with continuous b-spline kernels. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 869–877 (2018)
2018
-
[9]
In: Proceedings of the IEEE/CVF international conference on computer vision
Hassani, K., Haley, M.: Unsupervised multi-task feature learning on point clouds. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 8160–8171 (2019)
2019
- [10]
-
[11]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Khan, M., Fazlali, H., Sharma, D., Cao, T., Bai, D., Ren, Y., Liu, B.: Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 8315–8321 (2025). https://doi.org/10.1109/ICRA55743.2025.11127564
-
[12]
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition pp
Landrieu, L., Simonovsky, M.: Large-scale point cloud semantic seg- mentation with superpoint graphs. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition pp. 4558–4567 (2017), https://api.semanticscholar.org/CorpusID:4396837
2018
-
[13]
In: 2025 International Conference on 3D Vision (3DV)
Ma, Q., Li, Y., Ren, B., Sebe, N., Konukoglu, E., Gevers, T., Van Gool, L., Paudel, D.P.: A large-scale dataset of gaussian splats and their self-supervised pretraining. In: 2025 International Conference on 3D Vision (3DV). pp. 145–155. IEEE (2025), https://arxiv.org/abs/2408.10906 Learning Representations from 3D Gaussian Splats 15
-
[14]
World Scientific Annual Review of Artificial Intelligence 1, 2440001 (2023)
Pang, Y., Tay, E.H.F., Yuan, L., Chen, Z.: Masked autoencoders for 3d point cloud self-supervised learning. World Scientific Annual Review of Artificial Intelligence 1, 2440001 (2023)
2023
-
[15]
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation (2017), https://arxiv.org/abs/1612.00593
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space (2017), https://arxiv.org/abs/1706.02413
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Advances in neural information processing systems35, 23192–23204 (2022)
Qian, G., Li, Y., Peng, H., Mai, J., Hammoud, H., Elhoseiny, M., Ghanem, B.: Pointnext: Revisiting pointnet++ with improved training and scaling strategies. Advances in neural information processing systems35, 23192–23204 (2022)
2022
-
[18]
Su, H., Maji, S., Kalogerakis, E., Learned-Miller, E.: Multi-view convolutional neural networks for 3d shape recognition (2015), https://arxiv.org/abs/1505.00880
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
In: International Conference on Learning Representations (2018)
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph attention networks. In: International Conference on Learning Representations (2018)
2018
-
[20]
ACM Transactions on Graphics (tog)38(5), 1–12 (2019)
Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M., Solomon, J.M.: Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (tog)38(5), 1–12 (2019)
2019
- [21]
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., Xiao, J.: 3d shapenets: A deep representation for volumetric shapes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1912–1920 (2015)
1912
- [23]
-
[24]
Xu, Y., Fan, T., Xu, M., Zeng, L., Qiao, Y.: Spidercnn: Deep learning on point sets with parameterized convolutional filters (2018), https://arxiv.org/abs/1803.11527
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Yan, X.: Pointnet/pointnet++ pytorch (2019)
2019
-
[26]
Journal of Student Research10(11 2021)
Yang, Z., Goldsztein, G.: Classification using 3d point cloud and 2d image on abstract objects. Journal of Student Research10(11 2021)
2021
-
[27]
Zhang, H., Wang, C., Tian, S., Lu, B., Zhang, L., Ning, X., Bai, X.: Deep learning- based 3d point cloud classification: A systematic survey and outlook. Displays 79, 102456 (2023). https://doi.org/https://doi.org/10.1016/j.displa.2023.102456, https://www.sciencedirect.com/science/article/pii/S0141938223000896
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
Zhang, R., Zhu, H., Zhao, J., Zhang, Q., Cao, X., Ma, Z.: Mitigating ambiguities in 3d classification with gaussian splatting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2025)
2025
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, R., Zhu, H., Zhao, J., Zhang, Q., Cao, X., Ma, Z.: Mitigating ambiguities in 3d classification with gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27275–27284 (2025)
2025
-
[30]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, H., Jiang, L., Fu, C.W., Jia, J.: Pointweb: Enhancing local neighborhood features for point cloud processing. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5560–5568 (2019)
2019
-
[31]
Zhou, Y., Tuzel, O.: Voxelnet: End-to-end learning for point cloud based 3d object detection (2017), https://arxiv.org/abs/1711.06396
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.