LiteCoder-Terminal: Scaling Long-Horizon Terminal Environments for Learning Language Agents
Pith reviewed 2026-06-29 07:25 UTC · model grok-4.3
The pith
Fully synthetic executable terminal environments generated from domain specifications offer scalable verifiable training for language agents on complex command-line tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
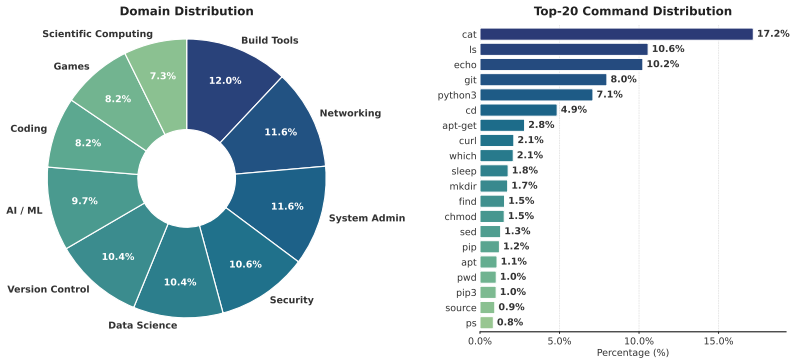
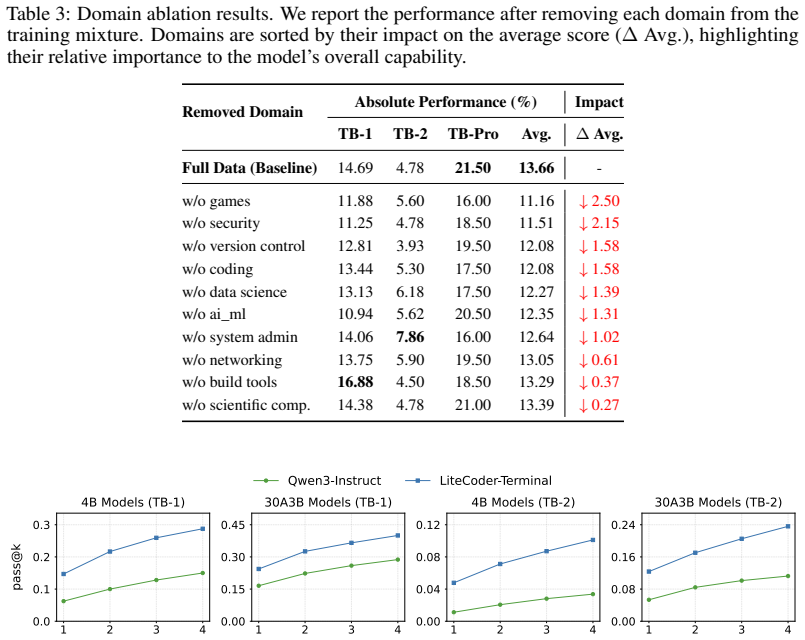
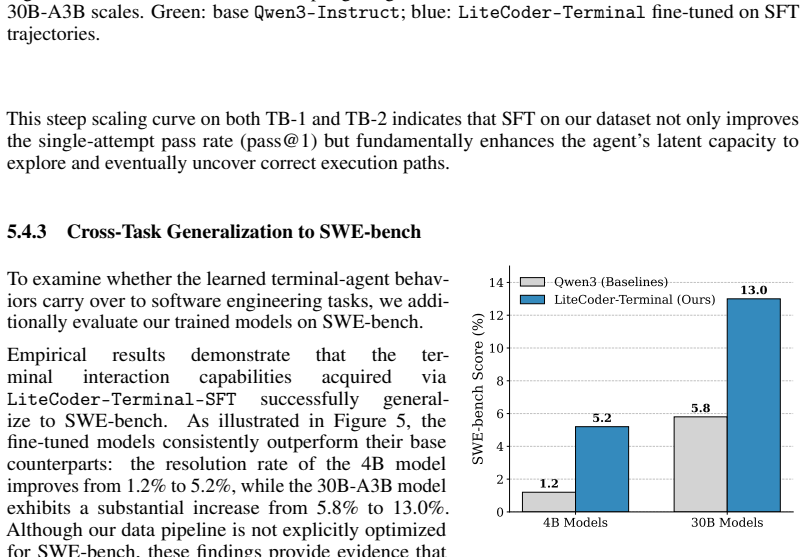
A synthesis pipeline autonomously generates executable terminal training environments from domain specifications, producing LiteCoder-Terminal-SFT with 11,255 trajectories and LiteCoder-Terminal-RL with 602 environments; supervised fine-tuning and DMPO on Qwen models then yield pass@1 scores of 29.06 percent, 18.54 percent, and 34.00 percent on Terminal Bench 1.0, 2.0, and Pro.
What carries the argument
LiteCoder-Terminal-Gen, the zero-dependency pipeline that generates executable and verifiable terminal environments directly from domain specifications.
If this is right
- Supervised fine-tuning on the generated SFT trajectories raises pass@1 rates on Terminal Bench benchmarks relative to base models.
- Direct Multi-turn Preference Optimization on the RL environments produces further measurable gains.
- The method removes dependence on scraped repositories while increasing domain controllability and targeting of specific capability gaps.
Where Pith is reading between the lines
- The same synthesis approach could be applied to other long-horizon interactive domains such as web browsers or code interpreters.
- Verifiable synthetic trajectories may support iterative self-improvement loops that scale beyond fixed benchmarks.
Load-bearing premise
Environments produced from domain specifications remain executable, verifiable, and representative of real terminal dynamics without introducing non-real artifacts or coverage gaps.
What would settle it
A controlled experiment in which agents trained only on the synthetic environments are evaluated on unmodified real-world terminals outside the ten specified domains and exhibit systematic failure rates.
Figures

read the original abstract
Mastering terminal environments requires language agents capable of multi-step planning, feedback-grounded execution, and dynamic state adaptation. However, training such agents is currently bottlenecked by a reliance on scraped external repositories, which limits domain diversity, environment controllability, and the targeting of specific capability deficits. We introduce LiteCoder-Terminal-Gen, a zero-dependency synthesis pipeline that autonomously generates executable and verifiable terminal training environments directly from domain specifications. Using this framework, we construct two large-scale resources: LiteCoder-Terminal-SFT, comprising 11,255 expert trajectories across 10 domains, and LiteCoder-Terminal-RL, featuring 602 verifiable environments for trajectory-level preference optimization. Supervised fine-tuning of Qwen-family models on our SFT dataset yields agents that significantly outperform their base counterparts. Notably, our 32B variant achieves 29.06%, 18.54%, and 34.00% pass@1 on Terminal Bench 1.0, 2.0, and Pro, respectively. Furthermore, applying Direct Multi-turn Preference Optimization (DMPO) on our RL environments yields additional performance gains. These results systematically demonstrate that fully synthetic, executable environments offer a scalable and verifiable supervision signal for mastering complex, real-world command-line workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LiteCoder-Terminal-Gen, a zero-dependency synthesis pipeline that generates executable terminal environments directly from domain specifications. It produces two resources: LiteCoder-Terminal-SFT (11,255 expert trajectories across 10 domains) and LiteCoder-Terminal-RL (602 verifiable environments). Supervised fine-tuning of Qwen-family models on the SFT data yields agents with pass@1 scores of 29.06%, 18.54%, and 34.00% on Terminal Bench 1.0, 2.0, and Pro (32B variant), with further gains from Direct Multi-turn Preference Optimization (DMPO) on the RL environments. The central claim is that fully synthetic, executable environments provide a scalable and verifiable supervision signal for long-horizon terminal agents.
Significance. If the generated environments accurately reproduce real terminal state transitions and error distributions, the approach could remove a major data bottleneck for training language agents on complex, multi-step command-line tasks by supplying controllable, diverse, and automatically verifiable trajectories at scale. The reported dataset sizes and benchmark gains constitute concrete empirical evidence that synthetic data can drive measurable improvements; the public release of these resources would be a clear asset for the community.
major comments (2)
- [Abstract] Abstract: The abstract states specific performance numbers (29.06% pass@1 etc.) and dataset sizes but supplies no description of the generation algorithm, verification procedure, benchmark protocol, or controls. This absence directly prevents evaluation of whether the environments are executable and representative, which is load-bearing for the claim that they constitute a 'verifiable supervision signal'.
- [Abstract] Abstract / Results: No quantitative comparison (command-frequency histograms, state-transition matrices, or error-type distributions) is reported between LiteCoder-Terminal-SFT trajectories and any real-world scraped corpus. Without such evidence, the 29–34% pass@1 gains do not establish that the synthetic data captures the failure modes required for transfer to actual command-line workflows.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states specific performance numbers (29.06% pass@1 etc.) and dataset sizes but supplies no description of the generation algorithm, verification procedure, benchmark protocol, or controls. This absence directly prevents evaluation of whether the environments are executable and representative, which is load-bearing for the claim that they constitute a 'verifiable supervision signal'.
Authors: We agree that the abstract could benefit from additional methodological context to support the central claims. In the revised version, we will expand the abstract to include a concise description of the LiteCoder-Terminal-Gen synthesis pipeline, the verification procedure for executability, the benchmark protocol, and key controls used. revision: yes
-
Referee: [Abstract] Abstract / Results: No quantitative comparison (command-frequency histograms, state-transition matrices, or error-type distributions) is reported between LiteCoder-Terminal-SFT trajectories and any real-world scraped corpus. Without such evidence, the 29–34% pass@1 gains do not establish that the synthetic data captures the failure modes required for transfer to actual command-line workflows.
Authors: The manuscript prioritizes the development of a fully synthetic pipeline to overcome limitations of scraped data, such as lack of controllability and verifiability. While we do not report direct quantitative comparisons to scraped corpora, the environments are designed to be executable and the performance on Terminal Bench (which reflects real-world terminal tasks) provides evidence of relevance. We do not believe such comparisons are necessary to support our claims and will not add them. revision: no
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The paper presents an empirical pipeline: a synthesis method generates synthetic terminal environments from domain specs, produces SFT and RL datasets, trains models, and reports pass@1 gains on external Terminal Bench suites. No equations, fitted parameters, or self-citations are invoked to derive the central claim; the reported improvements are framed as measured outcomes of training rather than tautological restatements of the generation process. The absence of any load-bearing self-definition, uniqueness theorem, or renamed input makes the chain non-circular by the stated criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain specifications can be used to generate executable and verifiable terminal environments in a zero-dependency manner.
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
2023
-
[3]
Claude code: A command-line tool for agentic coding with claude, 2025
Anthropic. Claude code: A command-line tool for agentic coding with claude, 2025. URL https://github.com/anthropics/claude-code. Accessed: 2026-02-03
2025
-
[4]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[5]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[8]
Yukang Feng, Jianwen Sun, Zelai Yang, Jiaxin Ai, Chuanhao Li, Zizhen Li, Fanrui Zhang, Kang He, Rui Ma, Jifan Lin, et al. Longcli-bench: A preliminary benchmark and study for long- horizon agentic programming in command-line interfaces.arXiv preprint arXiv:2602.14337, 2026
-
[9]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193, 2026
Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and Wei Ping. On data engineering for scaling llm terminal capabilities.arXiv preprint arXiv:2602.21193, 2026
-
[13]
Kaijie Zhu, Yuzhou Nie, Yijiang Li, Yiming Huang, Jialian Wu, Jiang Liu, Ximeng Sun, Zhenfei Yin, Lun Wang, Zicheng Liu, et al. Termigen: High-fidelity environment and robust trajectory synthesis for terminal agents.arXiv preprint arXiv:2602.07274, 2026
-
[14]
Large-scale terminal agentic trajectory generation from dockerized environments, 2026
Siwei Wu, Yizhi Li, Yuyang Song, Wei Zhang, Yang Wang, Riza Batista-Navarro, Xian Yang, Mingjie Tang, Bryan Dai, Jian Yang, and Chenghua Lin. Large-scale terminal agentic trajectory generation from dockerized environments, 2026. URLhttps://arxiv.org/abs/ 2602.01244
-
[15]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[18]
Yuxuan Cai, Lu Chen, Qiaoling Chen, Yuyang Ding, Liwen Fan, Wenjie Fu, Yufei Gao, Honglin Guo, Pinxue Guo, Zhenhua Han, et al. Nex-n1: Agentic models trained via a unified ecosystem for large-scale environment construction.arXiv preprint arXiv:2512.04987, 2025
-
[19]
OpenThoughts-Agent
OpenThoughts-Agent Team. OpenThoughts-Agent. https://www.open-thoughts.ai/blog/agent, December 2025
2025
-
[20]
Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing. InInternational Conference on Learning Representations, volume 2025, pages 76346–76382, 2025
2025
-
[21]
Harbor Framework, November 2025
Alex Shaw. Harbor Framework, November 2025. URL https://github.com/ laude-institute/harbor
2025
-
[22]
Minimax m2 & agent: Ingenious in simplicity
MiniMax. Minimax m2 & agent: Ingenious in simplicity. https://www.minimax.io/news/ minimax-m2, October 2025. Official model announcement. Accessed: 2026-05-21
2025
-
[23]
Minimax m2.1: Significantly enhanced multi-language programming, built for real- world complex tasks
MiniMax. Minimax m2.1: Significantly enhanced multi-language programming, built for real- world complex tasks. https://www.minimax.io/news/minimax-m21, December 2025. Official model announcement. Accessed: 2026-05-21
2025
-
[24]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[26]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Direct multi-turn preference optimization for language agents
Wentao Shi, Mengqi Yuan, Junkang Wu, Qifan Wang, and Fuli Feng. Direct multi-turn preference optimization for language agents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2312–2324, 2024. 11
2024
-
[28]
Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, et al. Let it flow: Agentic crafting on rock and roll, building the rome model within an open agentic learning ecosystem.arXiv preprint arXiv:2512.24873, 2025
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024. A Domain-to-Task Generation Prompt Below is an example of the domain-specific system prompt used in the Magpie-style active sampling stage (Section 3). This pr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Write a GPT-4 level LLM from scratch in C++
Extreme Complexity / Hallucination:Tasks that are wildly unrealistic or require massive engi- neering teams. 12 • Example: “Write a GPT-4 level LLM from scratch in C++.” • Example: “Create a full operating system kernel overnight.” 2.Vague / Ambiguous:Instructions with no clear success criteria
-
[32]
feasible
Unavailable Resources:Tasks that depend on missing hardware (GPUs, physical peripherals) or require external authentication. 4.Any other tasks that you deem unreasonable or impractical based on your expert judgment. You must respond in strict JSON format: { “feasible”: boolean, “reason”: “Explanation of why it is accepted or rejected.”, “difficulty”: “Eas...
-
[33]
Analyze the taskto understand: high-level goal and requirements; programming language and tools needed; expected inputs and outputs; how to make it more testable
-
[34]
Transform it into testable formatwith specific constraints: clear implementation require- ments (functions, classes, specific input/output specifications with concrete file paths, e.g., /app/input.json); data structure handling requirements; technical stack specifications; output format requirements (JSON structure, CSV format, etc.)
-
[35]
Important:Use /app as the working directory
Structure instruction.mdclearly: brief task description (1–2 sentences); technical requirements (language, input and output files); input/output specifications with examples; data format specifica- tions (with precise details); edge cases and error handling (if applicable). Important:Use /app as the working directory. Make requirements specific and testab...
-
[36]
Createenvironment/ directory structure:environment/[data files] — any input test data files mentioned ininstruction.md;environment/Dockerfile — container environment based on the base image template
-
[37]
After the base setup, add task-specific configuration: setWORKDIR,COPYtest data files to their required locations
Dockerfile requirements: Start with a fixed base image configuration (Ubuntu 24.04 with tmux, asciinema, uv, Python 3.13, OpenHands, and Claude Code pre-installed). After the base setup, add task-specific configuration: setWORKDIR,COPYtest data files to their required locations
-
[38]
Files should be small but representative
Test data files: Create realistic sample data files mentioned ininstruction.md. Files should be small but representative. Match exact specifications frominstruction.md. Important:Do NOT install any additional packages; rely solely on the base image configuration. 13 Solution Generation You are an expert programmer who creates reference solutions for bench...
-
[39]
If any of these pass, the assertion is too weak
Attack:Simulate a lazy agent that emits an empty file, incorrect data, or a hardcoded dummy payload. If any of these pass, the assertion is too weak
-
[40]
If the assertion false-rejects, it is over-specified
Refine:Simulate an expert agent that uses a different implementation approach but produces correct results. If the assertion false-rejects, it is over-specified. 4.Finalize:Write the robust version based on the preceding attack and refinement steps. Config Derivation You are an expert at creating Harbor benchmark task configurations. I have a complete tas...
-
[41]
Analyze the complete taskto determine: task difficulty (easy/medium/hard based on solution complexity); task category; appropriate technology tags (3–5 tags); time estimates for experts and juniors; resource requirements (CPU, memory, storage)
-
[42]
Examine all generated files: instruction.md, environment/Dockerfile, solution/solve.sh, andtests/
-
[43]
Guidelines:Resource allocation ranges from basic tasks (1 CPU, 2048 MB) to ML/build tasks (2–4 CPUs, 4096–8192 MB)
Createtask.toml declaring verifier, agent, and build timeouts, CPU, memory, and storage quotas. Guidelines:Resource allocation ranges from basic tasks (1 CPU, 2048 MB) to ML/build tasks (2–4 CPUs, 4096–8192 MB). Verifier timeout ranges from 360s (simple) to 900s (complex builds). Agent timeout ranges from 1800s (simple) to 3600s (complex). Previous agent ...
2048
-
[44]
soft loop
Adaptability.Analyze if the agent gets stuck in loops or fails to pivot strategies. • Mechanical Loop:Repeating the exact same command after encountering an error. This is the lowest level of failure. • Rigid Strategy:Although parameters (like syntax) are slightly modified after an error, the logical path to solve the problem remains unchanged (e.g., cons...
-
[45]
Task completed
Groundedness.Analyze if the agent fails to be reality-aligned. • Ignoring Feedback:The tool returns an error, but the agent claims “Task completed” in the next step. •Hallucinated Success:Assuming a file exists or a state is achieved without tool verification. • Context Drift:Forgetting that a certain method was already attempted and failed in previous steps
-
[46]
cannot be completed
Persistence.Analyze if the agent gives up on the task prematurely when facing obstacles. • Premature Surrender:Concluding the task is impossible or “cannot be completed” immediately after encountering an environmental limitation (e.g., missing compiler, command not found) without attempting reasonable alternatives or workarounds (e.g., checking for other ...
-
[47]
I cannot assist with this,
Refusal & Stoppage.Analyze if the agent explicitly refuses to proceed with the task. • Explicit Refusal:The agent states it cannot or will not fulfill the request (e.g., “I cannot assist with this,” “I am unable to generate this content”). Important:Strictly ignore all JSON formatting-related deviations. Examples include incorrect field ordering (since JS...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.