FPLIER: Federated Pathway-Level Information Extractor
Pith reviewed 2026-06-28 23:59 UTC · model grok-4.3
The pith
FPLIER produces PLIER training updates algebraically identical to centralized pooling while keeping expression data local to each site.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
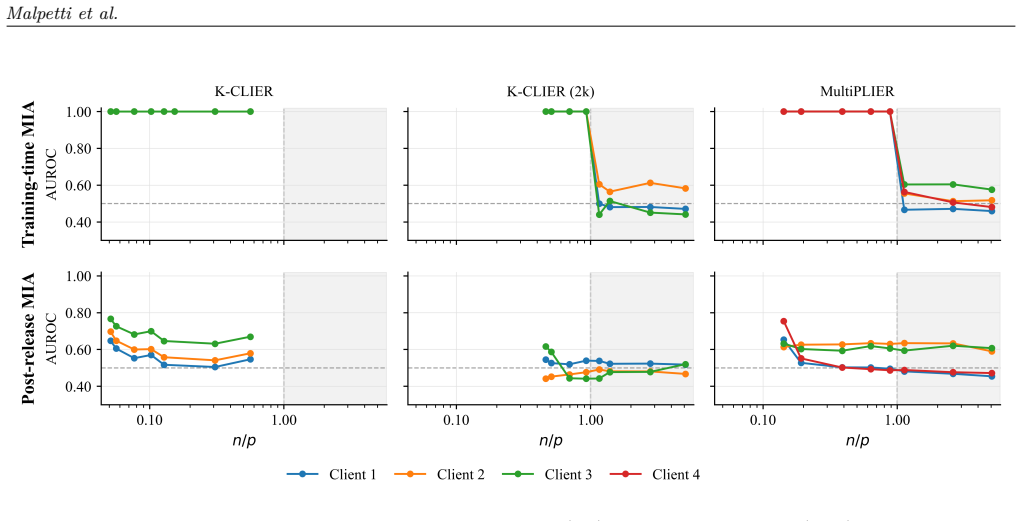
Through secure aggregation, FPLIER produces training updates algebraically equivalent to those of a centralized pooled-data approach while keeping expression data local. Evaluation across simulated consortia from the K-CLIER and MultiPLIER studies shows stable convergence. Privacy risk is governed by the rank of the training expression matrix; incorporating public data or reducing dimensionality increases this rank and moves the system toward a full-rank regime in which training and non-training samples become indistinguishable to the attacker.
What carries the argument
Secure aggregation protocol that enforces algebraic equivalence between federated and centralized PLIER updates.
If this is right
- Data holders can jointly train pathway-aware models without moving raw expression matrices.
- Adding public datasets increases matrix rank and thereby reduces membership inference risk.
- Dimensionality reduction steps can be applied to push the system toward the full-rank privacy regime.
- The same secure-aggregation approach yields stable results across the two tested consortia structures.
Where Pith is reading between the lines
- The same secure-aggregation wrapper could be applied to other gene-set factorization methods that rely on large compendia.
- Consortia might deliberately design data collection to maximize effective rank as a privacy control.
- The rank dependence points to a possible general lever for privacy in matrix-factorization models beyond PLIER.
Load-bearing premise
Secure aggregation can be realized in practice without leakage beyond the analyzed intermediate statistics and the federated updates remain numerically stable.
What would settle it
A membership inference attack that identifies training samples with accuracy significantly above chance on a full-rank expression matrix, or observed numerical divergence between federated and centralized runs on real multi-site data.
Figures

read the original abstract
In transcriptomics, gene-set-aware factorization methods such as the Pathway Level Information Extractor (PLIER) are most effective when trained on large, heterogeneous expression compendia. Yet, many clinically relevant cohorts cannot be pooled into a single dataset due to privacy and governance constraints. We present FPLIER, a federated extension of PLIER that enables distributed training across multiple data holders while incorporating publicly available datasets. Through secure aggregation, FPLIER produces training updates algebraically equivalent to those of a centralized pooled-data approach while keeping expression data local. We evaluate FPLIER across multiple scenarios in two simulated consortia (from the K-CLIER and MultiPLIER studies) and demonstrate stable convergence. We further conduct a systematic analysis of membership inference attacks targeting both intermediate training statistics and the released model. Our results show that privacy risk is governed by the rank of the training expression matrix. Incorporating public data or reducing data dimensionality increases this rank, moving the system toward a full-rank regime in which training and non-training samples become indistinguishable to the attacker, and membership-inference performance approaches random guessing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FPLIER, a federated extension of the PLIER gene-set-aware factorization method for transcriptomics. It claims that secure aggregation enables training updates that are algebraically equivalent to those from centralized pooled-data training while keeping expression data local to each site; evaluates the method on simulated consortia derived from the K-CLIER and MultiPLIER studies, reporting stable convergence; and conducts a membership-inference analysis showing that privacy risk is governed by the rank of the training expression matrix, with incorporation of public data or dimensionality reduction increasing rank and driving attack performance toward random guessing.
Significance. If the algebraic equivalence and rank-governed privacy result are substantiated, the work would enable privacy-preserving collaborative training of pathway-level models on distributed clinical cohorts that cannot be pooled, a practically important capability in transcriptomics. The use of simulated multi-site consortia and systematic membership-inference evaluation provides a concrete starting point for privacy analysis in federated bioinformatics methods.
major comments (3)
- [Abstract] Abstract: the central claim that FPLIER produces training updates 'algebraically equivalent' to centralized PLIER via secure aggregation is asserted without any derivation, equations, or proof sketch showing how the PLIER objective or updates are preserved under aggregation.
- [Abstract] Abstract: the membership-inference analysis concludes that 'privacy risk is governed by the rank of the training expression matrix' and that performance 'approaches random guessing' in the full-rank regime, yet reports no quantitative attack metrics (AUC, success rate, etc.), no description of the attack implementation, and no comparison across rank regimes.
- [Abstract] Abstract: evaluation is limited to the statement of 'stable convergence' on simulated data from two consortia, with no quantitative convergence metrics, no direct comparison of final model parameters or reconstruction error against a centralized baseline, and no implementation details on the secure-aggregation protocol or numerical stability.
Simulated Author's Rebuttal
We thank the referee for the constructive review. The comments correctly note that the abstract is highly condensed and would benefit from additional detail to support its claims. We address each point below, with revisions to the abstract and cross-references to the full derivations and results already present in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that FPLIER produces training updates 'algebraically equivalent' to centralized PLIER via secure aggregation is asserted without any derivation, equations, or proof sketch showing how the PLIER objective or updates are preserved under aggregation.
Authors: The abstract summarizes the result; the full algebraic derivation appears in Methods Section 3.2, where we demonstrate that secure aggregation of the PLIER gradient updates (which are linear in the data matrix) yields exactly the same parameter updates as the centralized objective. We will revise the abstract to include a one-sentence reference to this equivalence and the relevant methods section. revision: yes
-
Referee: [Abstract] Abstract: the membership-inference analysis concludes that 'privacy risk is governed by the rank of the training expression matrix' and that performance 'approaches random guessing' in the full-rank regime, yet reports no quantitative attack metrics (AUC, success rate, etc.), no description of the attack implementation, and no comparison across rank regimes.
Authors: Quantitative attack metrics (AUC values across rank regimes), attack implementation details, and comparisons are reported in Results Section 4.3 and Figure 5. The abstract condenses the governing relationship; we will add example AUC figures (e.g., approaching 0.5 in the full-rank case) to the abstract to make the claim self-contained. revision: yes
-
Referee: [Abstract] Abstract: evaluation is limited to the statement of 'stable convergence' on simulated data from two consortia, with no quantitative convergence metrics, no direct comparison of final model parameters or reconstruction error against a centralized baseline, and no implementation details on the secure-aggregation protocol or numerical stability.
Authors: Quantitative convergence metrics, parameter and reconstruction-error comparisons to the centralized baseline, and secure-aggregation implementation details (including numerical stability via fixed-point arithmetic) are provided in Section 4.2, Table 1, and Figure 3. We will revise the abstract to reference these key quantitative results and the methods section. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's derivation chain consists of applying standard secure aggregation to PLIER updates to achieve algebraic equivalence with centralized training (a direct property of the external primitive) and analyzing privacy via the rank of the expression matrix (a standard linear-algebra fact). No equations, fitted parameters, or self-citations are presented that reduce these claims to definitions or prior fits within the paper; the equivalence and rank-based indistinguishability follow from the cited external mechanisms without internal reduction. The evaluation on simulated consortia is empirical and does not rely on self-referential predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Secure aggregation can be implemented to deliver updates algebraically identical to centralized training without extra leakage.
Reference graph
Works this paper leans on
-
[1]
RNA-Seq: a revolutionary tool for transcriptomics
Z. Wang, M. Gerstein, and M. Snyder. “RNA-Seq: a revolutionary tool for transcriptomics”. In:Nature reviews genetics10.1 (2009), pp. 57–63
2009
-
[2]
Single-cell transcriptomics to explore the immune system in health and dis- ease
M. J. Stubbington, O. Rozenblatt-Rosen, A. Regev, and S. A. Teichmann. “Single-cell transcriptomics to explore the immune system in health and dis- ease”. In:Science358.6359 (2017), pp. 58–63
2017
-
[3]
The properties of high-dimensional data spaces: implications for exploring gene and protein expression data
R. Clarke, H. W. Ressom, A. Wang, J. Xuan, M. C. Liu, E. A. Gehan, and Y. Wang. “The properties of high-dimensional data spaces: implications for exploring gene and protein expression data”. In: Nature reviews cancer8.1 (2008), pp. 37–49
2008
-
[4]
Systematic RNA in- terference reveals that oncogenic KRAS-driven can- cers require TBK1
D. A. Barbie, P. Tamayo, J. S. Boehm, S. Y. Kim, S. E. Moody, I. F. Dunn, A. C. Schinzel, P. Sandy, E. Meylan, C. Scholl, et al. “Systematic RNA in- terference reveals that oncogenic KRAS-driven can- cers require TBK1”. In:Nature462.7269 (2009), pp. 108–112
2009
-
[5]
GSVA: gene set variation analysis for microarray and RNA- seq data
S.Hänzelmann,R.Castelo,andJ.Guinney.“GSVA: gene set variation analysis for microarray and RNA- seq data”. In:BMC bioinformatics14 (2013), pp. 1– 15
2013
-
[6]
Pathway-level information extractor (PLIER) for gene expression data
W. Mao, E. Zaslavsky, B. M. Hartmann, S. C. Seal- fon, and M. Chikina. “Pathway-level information extractor (PLIER) for gene expression data”. In: Nature methods16.7 (2019), pp. 607–610
2019
-
[7]
Multi- PLIER: a transfer learning framework for transcrip- tomics reveals systemic features of rare disease
J. N. Taroni, P. C. Grayson, Q. Hu, S. Eddy, M. Kretzler, P. A. Merkel, and C. S. Greene. “Multi- PLIER: a transfer learning framework for transcrip- tomics reveals systemic features of rare disease”. In: Cell systems8.5 (2019), pp. 380–394
2019
-
[8]
Reproducible RNA-seq analysis using recount2
L. Collado-Torres, A. Nellore, K. Kammers, S. E. Ellis, M. A. Taub, K. D. Hansen, A. E. Jaffe, B. Langmead, and J. T. Leek. “Reproducible RNA-seq analysis using recount2”. In:Nature biotechnology 35.4 (2017), pp. 319–321
2017
-
[9]
The cancer genome atlas pan-cancer analysis project
J. N. Weinstein, E. A. Collisson, G. B. Mills, K. R. Shaw, B. A. Ozenberger, K. Ellrott, I. Shmulevich, C. Sander, and J. M. Stuart. “The cancer genome atlas pan-cancer analysis project”. In:Nature ge- netics45.10 (2013), pp. 1113–1120
2013
-
[10]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Arcas. “Communication-efficient learning of deep networks from decentralized data. arXiv”. In:arXiv preprint arXiv:1602.05629 (2016)
-
[11]
Technical and legal aspects of federated learning in bioinformatics: applications, challenges and opportunities
D. Malpetti, M. Scutari, F. Gualdi, J. Van Setten, S. W. van der Laan, S. Haitjema, A. Lee, I. Her- ing, and F. Mangili. “Technical and legal aspects of federated learning in bioinformatics: applications, challenges and opportunities”. In:Frontiers in Dig- ital Health7 (2025), p. 1644291
2025
-
[12]
Protocol for interpretable and context- specific single-cell-informed deconvolution of bulk RNA-seq data
D. Malpetti, F. Mangili, M. Bolis, A. Rinaldi, D. Legouis, L. Ruinelli, P. Cippà, and L. Azz- imonti. “Protocol for interpretable and context- specific single-cell-informed deconvolution of bulk RNA-seq data”. In:STAR protocols6.1 (2025), p. 103670
2025
-
[13]
A transfer learning frame- work to elucidate the clinical relevance of altered proximal tubule cell states in kidney disease
D. Legouis, A. Rinaldi, D. Malpetti, G. Arnoux, T. Verissimo, A. Faivre, F. Mangili, A. Rinaldi, L. Ruinelli, J. Pugin, et al. “A transfer learning frame- work to elucidate the clinical relevance of altered proximal tubule cell states in kidney disease”. In: Iscience27.3 (2024). 10 Malpetti et al
2024
-
[14]
MousiPLIER: A Mouse Pathway-Level Information Extractor Model
S. Zhang, B. J. Heil, W. Mao, M. Chikina, C. S. Greene, and E. A. Heller. “MousiPLIER: A Mouse Pathway-Level Information Extractor Model”. In: eneuro11.6 (2024)
2024
-
[15]
Patient privacy in AI-driven omics methods
J. Zhou, C. Huang, and X. Gao. “Patient privacy in AI-driven omics methods”. In:Trends in Genetics 40.5 (2024), pp. 383–386
2024
-
[16]
Secure single-server aggregation with (poly) logarithmic overhead
J. H. Bell, K. A. Bonawitz, A. Gascón, T. Lepoint, and M. Raykova. “Secure single-server aggregation with (poly) logarithmic overhead”. In:Proceedings of the 2020 ACM SIGSAC conference on computer and communications security. 2020, pp. 1253–1269
2020
-
[17]
Secure aggregation for federated learning in flower
K. H. Li, P. P. B. de Gusmão, D. J. Beutel, and N. D. Lane. “Secure aggregation for federated learning in flower”. In:Proceedings of the 2nd ACM Interna- tional Workshop on Distributed Machine Learning. 2021, pp. 8–14
2021
-
[18]
The algorithmic founda- tions of differential privacy
C. Dwork and A. Roth. “The algorithmic founda- tions of differential privacy”. In:Foundations and trends in theoretical computer science9.3-4 (2014), pp. 211–487
2014
-
[19]
Genome-wide association studies
E. Uffelmann, Q. Q. Huang, N. S. Munung, J. De Vries, Y. Okada, A. R. Martin, H. C. Martin, T. Lappalainen, and D. Posthuma. “Genome-wide association studies”. In:Nature Reviews Methods Primers1.1 (2021), p. 59
2021
-
[20]
Federated learning algo- rithms for generalized mixed-effects model (GLMM) on horizontally partitioned data from distributed sources
W. Li, J. Tong, M. M. Anjum, N. Mohammed, Y. Chen, and X. Jiang. “Federated learning algo- rithms for generalized mixed-effects model (GLMM) on horizontally partitioned data from distributed sources”. In:BMC Medical Informatics and Deci- sion Making22.1 (2022), p. 269
2022
-
[21]
Privacy-preserving federated neural network learning for disease- associated cell classification
S. Sav, J.-P. Bossuat, J. R. Troncoso-Pastoriza, M. Claassen, and J.-P. Hubaux. “Privacy-preserving federated neural network learning for disease- associated cell classification”. In:Patterns3.5 (2022)
2022
-
[22]
scFed: federated learning for cell type classification with scRNA-seq
S. Wang, B. Shen, L. Guo, M. Shang, J. Liu, Q. Sun, and B. Shen. “scFed: federated learning for cell type classification with scRNA-seq”. In:Briefings in Bioinformatics25.1 (2024), bbad507
2024
-
[23]
Flimma: a federated and privacy-aware tool for differential gene expression analysis
O. Zolotareva, R. Nasirigerdeh, J. Matschinske, R. Torkzadehmahani,M.Bakhtiari,T.Frisch,J.Späth, D. B. Blumenthal, A. Abbasinejad, P. Tieri, et al. “Flimma: a federated and privacy-aware tool for differential gene expression analysis”. In:Genome biology22.1 (2021), p. 338
2021
-
[24]
Federated deep learning enables cancer subtyping by proteomics
Z. Cai, E. L. Boys, Z. Noor, A. T. Aref, D. Xavier, N. Lucas, S. G. Williams, J. M. Koh, R. C. Poulos, Y. Wu, et al. “Federated deep learning enables cancer subtyping by proteomics”. In:Cancer Discovery 15.9 (2025), pp. 1803–1818
2025
-
[25]
Flower: A Friendly Federated Learning Research Framework
D. J. Beutel, T. Topal, A. Mathur, X. Qiu, J. Fernandez-Marques, Y. Gao, L. Sani, K. H. Li, T. Parcollet, P. P. B. de GusmÃG, o, et al. “Flower: A friendly federated learning research framework”. In:arXiv preprint arXiv:2007.14390(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[26]
Comparative analy- sis of open-source federated learning frameworks-a literature-based survey and review
P. Riedel, L. Schick, R. von Schwerin, M. Reichert, D. Schaudt, and A. Hafner. “Comparative analy- sis of open-source federated learning frameworks-a literature-based survey and review”. In:Interna- tional Journal of Machine Learning and Cybernetics 15.11 (2024), pp. 5257–5278
2024
-
[27]
Membership inference attack against princi- pal component analysis
O. Zari, J. Parra-Arnau, A. Ünsal, T. Strufe, and M. Önen. “Membership inference attack against princi- pal component analysis”. In:International Confer- ence on Privacy in Statistical Databases. Springer. 2022, pp. 269–282
2022
-
[28]
The reactome pathway knowledgebase
A. Fabregat, S. Jupe, L. Matthews, K. Sidiropoulos, M. Gillespie, P. Garapati, R. Haw, B. Jassal, F. Korninger, B. May, et al. “The reactome pathway knowledgebase”. In:Nucleic acids research46.D1 (2018), pp. D649–D655
2018
-
[29]
Bayesian method to predict individual SNP genotypes from gene expression data
E. E. Schadt, S. Woo, and K. Hao. “Bayesian method to predict individual SNP genotypes from gene expression data”. In:Nature genetics44.5 (2012), pp. 603–608
2012
-
[30]
A decade of research on genetic privacy: the findings of the GetPreCiSe Center at Vanderbilt University
C. Slobogin, K. Tellis, E. W. Clayton, J. Clayton, A. Eilmus, and B. A. Malin. “A decade of research on genetic privacy: the findings of the GetPreCiSe Center at Vanderbilt University”. In:Frontiers in Genetics16 (2025), p. 1629386
2025
-
[31]
Federated horizon- tally partitioned principal component analysis for biomedical applications
A. Hartebrodt and R. Röttger. “Federated horizon- tally partitioned principal component analysis for biomedical applications”. In:Bioinformatics Ad- vances2.1 (2022), vbac026
2022
-
[32]
G. H. Golub and C. F. Van Loan.Matrix compu- tations (3rd ed.)USA: Johns Hopkins University Press, 1996.isbn: 0801854148
1996
-
[33]
Find- ing structure with randomness: Probabilistic algo- rithms for constructing approximate matrix decom- positions
N. Halko, P.-G. Martinsson, and J. A. Tropp. “Find- ing structure with randomness: Probabilistic algo- rithms for constructing approximate matrix decom- positions”. In:SIAM review53.2 (2011), pp. 217– 288
2011
-
[34]
Practical secure aggregation for privacy- preserving machine learning
K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth. “Practical secure aggregation for privacy- preserving machine learning”. In:proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017, pp. 1175–1191. 11 Malpetti et al. A. Standard PLIER training For completeness, ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.