MoSSP: A Momentum-Based Single-Loop Stochastic Penalty Method for Nonconvex Constrained DC-Regularized Optimization
Pith reviewed 2026-06-29 06:00 UTC · model grok-4.3
The pith
MoSSP finds stochastic ε-KKT points for nonconvex constrained DC-regularized problems with O(ε^{-3}) oracle complexity via single-loop momentum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop MoSSP, a Momentum-based Single-loop Stochastic Penalty method for such problems with provable complexity guarantees. The key idea is to apply a single stochastic proximal-gradient step to the Moreau envelope of the penalty plus the convex DC part, with the concave part's proximal mapping computed in parallel. We derive two algorithm variants: a Polyak-momentum version with O(ε^{-4}) oracle complexity for finding stochastic ε-KKT points, and an improved O(ε^{-3}) version incorporating recursive momentum.
What carries the argument
Single stochastic proximal-gradient step on the Moreau envelope of the penalty plus convex DC part, executed in parallel with the concave proximal mapping and accelerated by Polyak or recursive momentum.
If this is right
- The method supplies the first single-loop stochastic algorithms with explicit complexity for nonconvex constrained DC-regularized problems.
- Recursive momentum improves the exponent from 4 to 3 without leaving the single-loop framework.
- The approach applies when the feasible set is nonconvex and the concave DC component is nonsmooth.
- Experimental results on benchmark instances confirm practical performance consistent with the derived bounds.
Where Pith is reading between the lines
- The same momentum-plus-Moreau-envelope construction may transfer to other nonsmooth penalty terms whose proximal maps remain tractable.
- Recursive momentum could be combined with variance-reduction techniques to target even lower complexity in finite-sum settings.
- If proximal mappings must be approximated by inner loops, the overall complexity would degrade by the inner-loop cost factor.
- The framework suggests a template for designing single-loop methods for bilevel problems whose lower level admits a DC representation.
Load-bearing premise
Proximal mappings for the penalty and DC parts can be evaluated or approximated in time that preserves the single-loop structure.
What would settle it
A concrete instance in which the proximal mappings require iterative inner solvers whose total cost exceeds the claimed outer-loop oracle bound while still reaching ε-KKT accuracy.
Figures

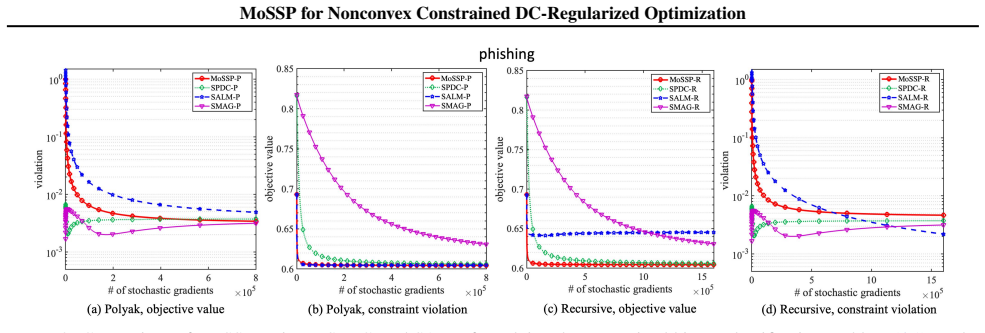
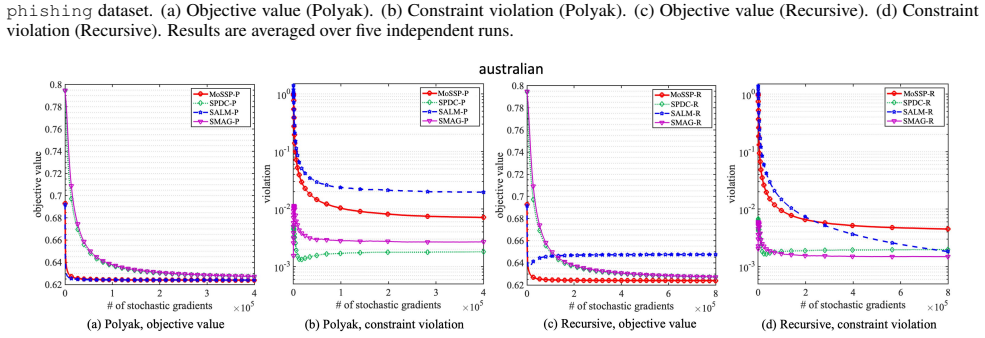
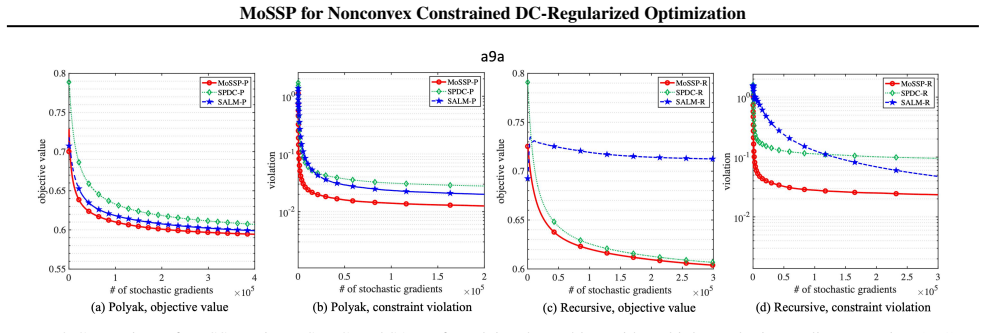
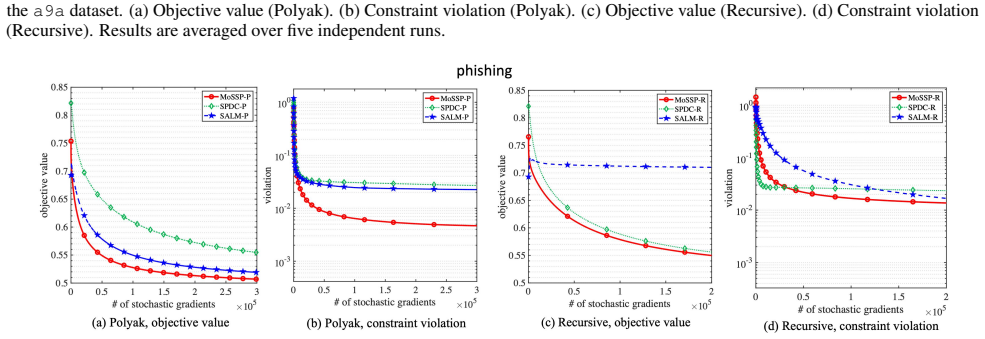
read the original abstract
In this paper, we study a structured class of nonconvex constrained stochastic problems with difference-of-convex (DC) regularization, where the feasible set is possibly nonconvex and the concave part of the DC regularizer is allowed to be nonsmooth. The fundamental challenge lies in maintaining feasibility for nonconvex constraints while achieving favorable oracle complexity. Although single-loop algorithms efficiently solve unconstrained DC optimization problems, their potential for constrained optimization with DC structure remains largely unexplored. To address this gap, we develop MoSSP, a Momentum-based Single-loop Stochastic Penalty method for such problems with provable complexity guarantees. The key idea is to apply a single stochastic proximal-gradient step to the Moreau envelope of the penalty plus the convex DC part, with the concave part's proximal mapping computed in parallel. We derive two algorithm variants: a Polyak-momentum version with $O(\varepsilon^{-4})$ oracle complexity for finding stochastic $\varepsilon$-KKT points, and an improved $O(\varepsilon^{-3})$ version incorporating recursive momentum. Experimental results demonstrate the effectiveness of the proposed algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoSSP, a momentum-based single-loop stochastic penalty method for nonconvex constrained stochastic optimization problems with DC regularization (where the feasible set may be nonconvex and the concave DC part may be nonsmooth). It introduces two variants—a Polyak-momentum version and a recursive-momentum version—claiming O(ε^{-4}) and O(ε^{-3}) oracle complexities, respectively, for finding stochastic ε-KKT points via a single stochastic proximal-gradient step on the Moreau envelope of the penalty plus convex DC part, with parallel computation of the concave prox.
Significance. If the stated oracle complexities hold under verifiable assumptions, the work would fill a gap by extending single-loop stochastic methods with momentum to constrained DC-regularized problems, which arise in applications such as sparse optimization and machine learning. The experimental results provide supporting evidence of practical effectiveness, though the primary contribution is the claimed theoretical guarantees.
major comments (1)
- [Abstract and §3] Abstract and §3 (algorithm description): The single-loop structure and the O(ε^{-4})/O(ε^{-3}) oracle complexity claims rest on the assumption that the proximal mapping of the penalty term (for possibly nonconvex constraints) can be evaluated exactly or to sufficient accuracy at unit cost in parallel with the stochastic gradient step. For nonconvex feasible sets the natural penalty is often the indicator function, whose prox is a nonconvex projection that is NP-hard in general; without an explicit smooth penalty surrogate whose prox is cheap or an inner-loop budget in the complexity count, this assumption is load-bearing and undermines both the single-loop property and the stated bounds.
minor comments (1)
- [Abstract] The abstract states 'provable complexity guarantees' but does not list the precise assumptions (smoothness, Lipschitz constants, bounded variance) under which the bounds are derived; these should be stated explicitly in the introduction or theorem statements.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the constructive comment on the assumptions underlying our method. We address the point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (algorithm description): The single-loop structure and the O(ε^{-4})/O(ε^{-3}) oracle complexity claims rest on the assumption that the proximal mapping of the penalty term (for possibly nonconvex constraints) can be evaluated exactly or to sufficient accuracy at unit cost in parallel with the stochastic gradient step. For nonconvex feasible sets the natural penalty is often the indicator function, whose prox is a nonconvex projection that is NP-hard in general; without an explicit smooth penalty surrogate whose prox is cheap or an inner-loop budget in the complexity count, this assumption is load-bearing and undermines both the single-loop property and the stated bounds.
Authors: We agree that the single-loop property and the stated oracle complexities presuppose that the proximal mapping of the chosen penalty term can be evaluated exactly (or to sufficient accuracy) at unit cost. The manuscript develops the method for the class of problems in which such a penalty is employed—for instance, when the constraints admit an efficient (possibly nonconvex) projection or when a smooth penalty surrogate with a closed-form prox is used. In settings where the natural penalty is the indicator of a nonconvex set whose projection is NP-hard, an inner iterative solver would indeed be required and would need to be budgeted in the complexity analysis, altering both the single-loop claim and the bounds. We will revise the abstract and Section 3 to state this assumption explicitly, to delineate the settings in which the proximal mapping remains tractable, and to note the consequences when it does not. This clarification does not change the technical results but improves the precision of the claims. revision: yes
Circularity Check
No circularity detected in derivation
full rationale
The paper presents MoSSP as a newly constructed single-loop algorithm applying stochastic proximal-gradient steps to the Moreau envelope of a penalty plus convex DC part, with parallel concave prox, yielding stated O(ε^{-4}) and O(ε^{-3}) oracle complexities for ε-KKT points under standard smoothness/Lipschitz assumptions. No equations or steps in the provided abstract reduce a claimed result to a fitted input, self-definition, or self-citation chain by construction; the complexity guarantees are derived from the algorithmic structure rather than presupposing the target bounds. This is the common case of an independent algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
and Wright, S
Alacaoglu, A. and Wright, S. J. Complexity of single loop algorithms for nonlinear programming with stochastic objective and constraints. In International Conference on Artificial Intelligence and Statistics (AISTATS), pp.\ 4627--4635, 2024
2024
-
[3]
C., Foster, D
Arjevani, Y., Carmon, Y., Duchi, J. C., Foster, D. J., Srebro, N., and Woodworth, B. Lower bounds for non-convex stochastic optimization. Math. Program., 199 0 (1): 0 165--214, 2023
2023
-
[4]
S., Curtis, F
Berahas, A. S., Curtis, F. E., Robinson, D., and Zhou, B. Sequential quadratic optimization for nonlinear equality constrained stochastic optimization. SIAM J. Optim., 31 0 (2): 0 1352--1379, 2021
2021
-
[5]
S., Bollapragada, R., and Zhou, B
Berahas, A. S., Bollapragada, R., and Zhou, B. An adaptive sampling sequential quadratic programming method for equality constrained stochastic optimization. P reprint at arXiv:2206.00712 , 2022
-
[6]
P., Santos, E
Bergmann, R., Ferreira, O. P., Santos, E. M., and Souza, J. C. O. T he difference of convex algorithm on H adamard manifolds. J. Optim. Theory Appl., 201 0 (1): 0 221--251, 2024
2024
-
[7]
and Lin, C.-J
Chang, C.-C. and Lin, C.-J. LIBSVM : A library for support vector machines. ACM Trans. Intell. Syst. Technol., 2 0 (3): 0 1--27, 2011
2011
- [8]
-
[9]
Constraint-aware deep neural network compression
Chen, C., Tung, F., Vedula, N., and Mori, G. Constraint-aware deep neural network compression. In European Conference on Computer Vision (ECCV), pp.\ 400--415, 2018
2018
-
[10]
An exact penalty method for stochastic equality-constrained optimization
Cui, Y., Shi, Q., Wang, X., and Xiao, X. An exact penalty method for stochastic equality-constrained optimization. O ptimization Online , 2025
2025
-
[11]
E., O'Neill, M
Curtis, F. E., O'Neill, M. J., and Robinson, D. P. Worst-case complexity of an SQP method for nonlinear equality constrained stochastic optimization. Math. Program., 205 0 (1): 0 431--483, 2024
2024
-
[12]
E., Jiang, X., and Wang, Q
Curtis, F. E., Jiang, X., and Wang, Q. A lmost-sure convergence of iterates and multipliers in stochastic sequential quadratic optimization. J. Optim. Theory Appl., 204 0 (2): 0 28, 2025
2025
-
[13]
and Orabona, F
Cutkosky, A. and Orabona, F. Momentum-based variance reduction in non-convex SGD . In Advances in Neural Information Processing Systems (NeurIPS), pp.\ 15236--15245, 2019
2019
-
[14]
and Drusvyatskiy, D
Davis, D. and Drusvyatskiy, D. Stochastic model-based minimization of weakly convex functions. SIAM J. Optim., 29 0 (1): 0 207--239, 2019
2019
-
[15]
Proximal bundle methods for nonsmooth DC programming
de Oliveira, W. Proximal bundle methods for nonsmooth DC programming. J. Glob. Optim., 75 0 (2): 0 523--563, 2019
2019
-
[16]
J., Lin, Z., and Zhang, T
Fang, C., Li, C. J., Lin, Z., and Zhang, T. SPIDER : N ear-optimal non-convex optimization via stochastic path-integrated differential estimator. In Advances in Neural Information Processing Systems (NeurIPS), volume 31, 2018
2018
-
[17]
Gao, Y., Rodomanov, A., and Stich, S. U. Non-convex stochastic composite optimization with P olyak momentum. In International Conference on Machine Learning (ICML), volume 235, 2024
2024
-
[18]
and Lan, G
Ghadimi, S. and Lan, G. Stochastic first- and zeroth-order methods for nonconvex stochastic programming. SIAM J. Optim., 23 0 (4): 0 2341--2368, 2013
2013
-
[19]
A general iterative shrinkage and thresholding algorithm for non-convex regularized optimization problems
Gong, P., Zhang, C., Lu, Z., Huang, J., and Ye, J. A general iterative shrinkage and thresholding algorithm for non-convex regularized optimization problems. In International Conference on Machine Learning (ICML), pp.\ 37--45, 2013
2013
-
[20]
How to regularize a difference of convex functions
Hiriart-Urruty, J.-B. How to regularize a difference of convex functions. J. Math. Anal. Appl., 162 0 (1): 0 196--209, 1991
1991
-
[21]
W., and Kolar, M
Hong, I., Na, S., Mahoney, M. W., and Kolar, M. Constrained optimization via exact A ugmented L agrangian and randomized iterative sketching. In International Conference on Machine Learning (ICML), pp.\ 13174--13198, 2023
2023
-
[22]
Single-loop stochastic algorithms for difference of max-structured weakly convex functions
Hu, Q., Qi, Q., Lu, Z., and Yang, T. Single-loop stochastic algorithms for difference of max-structured weakly convex functions. In Advances in Neural Information Processing Systems (NeurIPS), volume 37, pp.\ 56738--56765, 2024
2024
-
[23]
and Li, Y
Jelassi, S. and Li, Y. Towards understanding how momentum improves generalization in deep learning. In International Conference on Machine Learning (ICML), pp.\ 9965--10040, 2022
2022
-
[24]
arX iv preprint arXiv:2509.08561 (2025)
Jiang, B., Xu, M., Cai, X., and Liu, Y.-F. An inexact proximal framework for nonsmooth R iemannian difference-of-convex optimization. P reprint at arXiv:2509.08561 , 2025
-
[25]
and Wang, X
Jin, L. and Wang, X. A stochastic primal-dual method for a class of nonconvex constrained optimization. Comput. Optim. Appl., 83 0 (1): 0 143--180, 2022
2022
-
[26]
and Wang, X
Jin, L. and Wang, X. Stochastic nested primal-dual method for nonconvex constrained composition optimization. Math. Comp., 94 0 (351): 0 305--358, 2025
2025
-
[27]
and Neder, T
Kanzow, C. and Neder, T. A n adaptive proximal safeguarded augmented L agrangian method for nonsmooth DC problems with convex constraints. J. Nonsmooth Anal. Optim., 6: 0 15731, 2026
2026
-
[28]
C., and Sugiyama, M
Kiryo, R., Niu, G., du Plessis, M. C., and Sugiyama, M. Positive-unlabeled learning with non-negative risk estimator. In Advances in Neural Information Processing Systems (NeurIPS), volume 30, pp.\ 1675--1685, 2017
2017
-
[29]
Kushner, H. J. and Sanvicente, E. Penalty function methods for constrained stochastic approximation. J. Math. Anal. Appl., 46 0 (2): 0 499--512, 1974
1974
-
[30]
Le Thi, H. A. and Pham Dinh, T. DC programming and DCA : thirty years of developments. Math. Program., 169 0 (1): 0 5--68, 2018
2018
-
[31]
A., Huynh, V
Le Thi, H. A., Huynh, V. N., and Pham Dinh, T. Minimizing compositions of differences-of-convex functions with smooth mappings. Math. Oper. Res., 49 0 (2): 0 1140--1168, 2024
2024
-
[32]
Convergence analysis of an inexact MBA method for constrained DC problems
Liu, R., Pan, S., and Bi, S. Convergence analysis of an inexact MBA method for constrained DC problems. P reprint at arXiv:2504.14488 , 2025
-
[33]
and Takeda, A
Liu, T. and Takeda, A. A n inexact successive quadratic approximation method for a class of difference-of-convex optimization problems. Comput. Optim. Appl., 82: 0 141--173, 2022
2022
-
[34]
K., and Takeda, A
Liu, T., Pong, T. K., and Takeda, A. A refined convergence analysis of p DCA _e with applications to simultaneous sparse recovery and outlier detection. Comput. Optim. Appl., 73 0 (1): 0 69--100, 2019
2019
- [35]
-
[36]
An improved analysis of stochastic gradient descent with momentum
Liu, Y., Gao, Y., and Yin, W. An improved analysis of stochastic gradient descent with momentum. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pp.\ 18261--18271, 2020
2020
-
[37]
Penalty and augmented L agrangian methods for constrained DC programming
Lu, Z., Sun, Z., and Zhou, Z. Penalty and augmented L agrangian methods for constrained DC programming. Math. Oper. Res., 47 0 (3): 0 2260--2285, 2022
2022
-
[38]
Variance-reduced first-order methods for deterministically constrained stochastic nonconvex optimization with strong convergence guarantees
Lu, Z., Mei, S., and Xiao, Y. Variance-reduced first-order methods for deterministically constrained stochastic nonconvex optimization with strong convergence guarantees. SIAM J. Optim., 36 0 (1): 0 1--31, 2026
2026
-
[39]
New improved penalty methods for sparse reconstruction based on difference of two norms
Luo, Z., Wang, Y., and Zhang, X. New improved penalty methods for sparse reconstruction based on difference of two norms. Technical report, Optimization Online, 2015
2015
-
[40]
Truncated _ 1-2 models for sparse recovery and rank minimization
Ma, T.-H., Lou, Y., and Huang, T.-Z. Truncated _ 1-2 models for sparse recovery and rank minimization. SIAM J. Imaging Sci., 10 0 (3): 0 1346--1380, 2017
2017
-
[41]
Proximit\' e et dualit\' e dans un espace hilbertien
Moreau, J.-J. Proximit\' e et dualit\' e dans un espace hilbertien. Bull. Soc. Math. France, 93: 0 273--299, 1965
1965
-
[42]
A regularization of DC optimization
Moudafi, A. A regularization of DC optimization. Pure Appl. Funct. Anal., 8 0 (3): 0 847--854, 2023
2023
-
[43]
and Mahoney, M
Na, S. and Mahoney, M. Statistical inference of constrained stochastic optimization via sketched sequential quadratic programming. J. Mach. Learn. Res., 26 0 (33): 0 1--75, 2025
2025
-
[44]
A n adaptive stochastic sequential quadratic programming with differentiable exact augmented L agrangians
Na, S., Anitescu, M., and Kolar, M. A n adaptive stochastic sequential quadratic programming with differentiable exact augmented L agrangians. Math. Program., 199 0 (1): 0 721--791, 2023 a
2023
-
[45]
I nequality constrained stochastic nonlinear optimization via active-set sequential quadratic programming
Na, S., Anitescu, M., and Kolar, M. I nequality constrained stochastic nonlinear optimization via active-set sequential quadratic programming. Math. Program., 202: 0 279--353, 2023 b
2023
-
[46]
M., Liu, J., Scheinberg, K., and Tak \'a c , M
Nguyen, L. M., Liu, J., Scheinberg, K., and Tak \'a c , M. SARAH : A novel method for machine learning problems using stochastic recursive gradient. In International Conference on Machine Learning (ICML), pp.\ 2613--2621, 2017
2017
-
[47]
and Suzuki, T
Nitanda, A. and Suzuki, T. Stochastic difference of convex algorithm and its application to training deep B oltzmann machines. In AAAI Conference on Artificial Intelligence (AAAI), pp.\ 470--478, 2017
2017
-
[48]
Computing B -stationary points of nonsmooth DC programs
Pang, J.-S., Razaviyayn, M., and Alvarado, A. Computing B -stationary points of nonsmooth DC programs. Math. Oper. Res., 42 0 (1): 0 95--118, 2017
2017
-
[49]
Paternain, S., Chamon, L. F. O., Calvo-Fullana, M., and Ribeiro, A. Constrained reinforcement learning has zero duality gap. In Advances in Neural Information Processing Systems (NeurIPS), volume 32, pp.\ 7553--7563, 2019
2019
-
[50]
Polyak, B. T. Some methods of speeding up the convergence of iteration methods. Comput. Math. Math. Phys., 4 0 (5): 0 1--17, 1964
1964
-
[51]
Rockafellar, R. T. and Wets, R. J.-B. Variational analysis. Springer Science & Business Media, 2009
2009
-
[52]
K., Mhammedi, Z., and Harandi, M
Roy, S. K., Mhammedi, Z., and Harandi, M. Geometry aware constrained optimization techniques for deep learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 4460--4469, 2018
2018
-
[53]
A momentum-based linearized augmented L agrangian method for nonconvex constrained stochastic optimization
Shi, Q., Wang, X., and Wang, H. A momentum-based linearized augmented L agrangian method for nonconvex constrained stochastic optimization. Math. Oper. Res., 51 0 (1): 0 92--133, 2026
2026
-
[54]
and Sun, X
Sun, K. and Sun, X. A. Algorithms for difference-of-convex programs based on difference-of- M oreau-envelopes smoothing. INFORMS J. Optim., 5 0 (4): 0 321--339, 2023
2023
-
[55]
Tao, P. D. and Souad, E. B. Algorithms for solving a class of nonconvex optimization problems. methods of subgradients. In North-Holland Mathematics Studies, volume 129, pp.\ 249--271. Elsevier, 1986
1986
-
[56]
Complexity analysis of inexact cubic-regularized primal-dual methods for finding second-order stationary points
Wang, X. Complexity analysis of inexact cubic-regularized primal-dual methods for finding second-order stationary points. Math. Comp., 94 0 (356): 0 2961--3008, 2025
2025
-
[57]
Penalty methods with stochastic approximation for stochastic nonlinear programming
Wang, X., Ma, S., and Yuan, Y.-x. Penalty methods with stochastic approximation for stochastic nonlinear programming. Math. Comp., 86 0 (306): 0 1793--1820, 2017
2017
-
[58]
Wen, B., Chen, X., and Pong, T. K. A proximal difference-of-convex algorithm with extrapolation. Comput. Optim. Appl., 69: 0 297--324, 2018
2018
-
[59]
M., Tibshirani, R., and Hastie, T
Witten, D. M., Tibshirani, R., and Hastie, T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics, 10 0 (3): 0 515--534, 2009
2009
-
[60]
and Wright, S
Xie, Y. and Wright, S. J. Complexity of proximal augmented L agrangian for nonconvex optimization with nonlinear equality constraints. J. Sci. Comput., 86 0 (3): 0 38, 2021
2021
-
[61]
Xu, J., Pong, T. K., and Sze, N.-s. A smoothing moving balls approximation method for a class of conic-constrained difference-of-convex optimization problems. P reprint at arXiv:2505.12314 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Primal-dual stochastic gradient method for convex programs with many functional constraints
Xu, Y. Primal-dual stochastic gradient method for convex programs with many functional constraints. SIAM J. Optim., 30 0 (2): 0 1664--1692, 2020
2020
-
[63]
and Xu, Y
Xu, Y. and Xu, Y. Momentum-based variance-reduced proximal stochastic gradient method for composite nonconvex stochastic optimization. J. Optim. Theory Appl., 196 0 (1): 0 266--297, 2023
2023
-
[64]
Stochastic optimization for DC functions and non-smooth non-convex regularizers with non-asymptotic convergence
Xu, Y., Qi, Q., Lin, Q., Jin, R., and Yang, T. Stochastic optimization for DC functions and non-smooth non-convex regularizers with non-asymptotic convergence. In International Conference on Machine Learning (ICML), pp.\ 6942--6951, 2019
2019
-
[65]
ECC : Platform-independent energy-constrained deep neural network compression via a bilinear regression model
Yang, H., Zhu, Y., and Liu, J. ECC : Platform-independent energy-constrained deep neural network compression via a bilinear regression model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[66]
Yang, L., Hu, J., and Liu, T. A nonmonotone extrapolated proximal gradient-subgradient algorithm beyond global L ipschitz gradient continuity. P reprint at arXiv:2511.22011 , 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
An inexact B regman proximal difference-of-convex algorithm with two types of relative stopping criteria
Yang, L., Hu, J., and Toh, K.-C. An inexact B regman proximal difference-of-convex algorithm with two types of relative stopping criteria. J. Sci. Comput., 103 0 (3): 0 91, 2025 b
2025
-
[68]
Single-loop algorithms for stochastic non-convex optimization with weakly-convex constraints
Yang, M., Li, G., Hu, Q., Lin, Q., and Yang, T. Single-loop algorithms for stochastic non-convex optimization with weakly-convex constraints. Trans. Mach. Learn. Res., 2026
2026
-
[69]
Large-scale optimization of partial AUC in a range of false positive rates
Yao, Y., Lin, Q., and Yang, T. Large-scale optimization of partial AUC in a range of false positive rates. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pp.\ 31239--31253, 2022
2022
-
[70]
Minimization of _ 1-2 for compressed sensing
Yin, P., Lou, Y., He, Q., and Xin, J. Minimization of _ 1-2 for compressed sensing. SIAM J. Sci. Comput., 37 0 (1): 0 A536--A563, 2015
2015
-
[71]
K., and Lu, Z
Yu, P., Pong, T. K., and Lu, Z. Convergence rate analysis of a sequential convex programming method with line search for a class of constrained difference-of-convex optimization problems. SIAM J. Optim., 31 0 (3): 0 2024--2054, 2021
2024
- [72]
-
[73]
Augmented Lagrangian Multiplier Network for State-wise Safety in Reinforcement Learning
Zhang, J., Yang, Y., Lyu, Y., Li, S. E., and Zhang, L. Augmented lagrangian multiplier network for state-wise safety in reinforcement learning. P reprint at arXiv:2605.00667 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[74]
A proximal alternating direction method of multipliers for DC programming with structured constraints
Zhou, Y., He, H., and Zhang, L. A proximal alternating direction method of multipliers for DC programming with structured constraints. J. Sci. Comput., 99 0 (3), 2024
2024
-
[75]
An adaptive single-loop stochastic penalty method for nonconvex constrained stochastic optimization
Zuo, S., Wang, X., and Wang, H. An adaptive single-loop stochastic penalty method for nonconvex constrained stochastic optimization. O ptimization Online , 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.