Evaluating Cross-lingual Knowledge Consistency in Code-Mixed vis-a-vis Indian Languages using IndicKLAR
Pith reviewed 2026-06-29 08:01 UTC · model grok-4.3
The pith
Code-mixed inputs close most of the native-language accuracy gap to English in large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
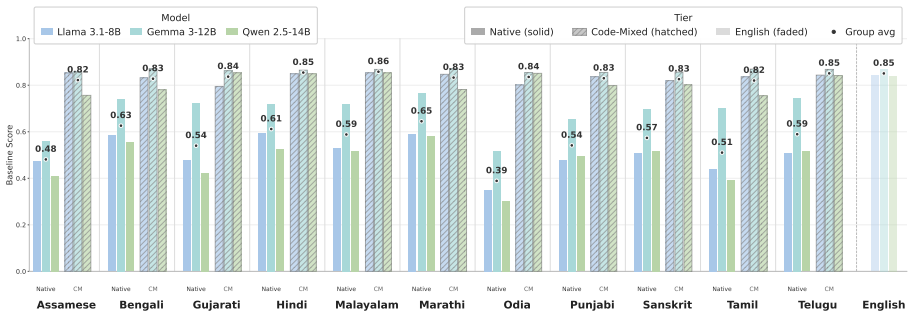
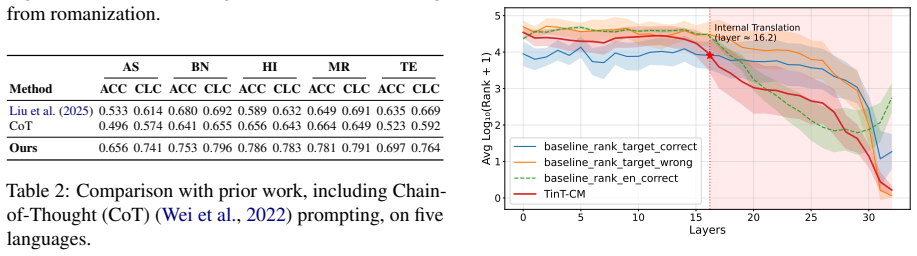
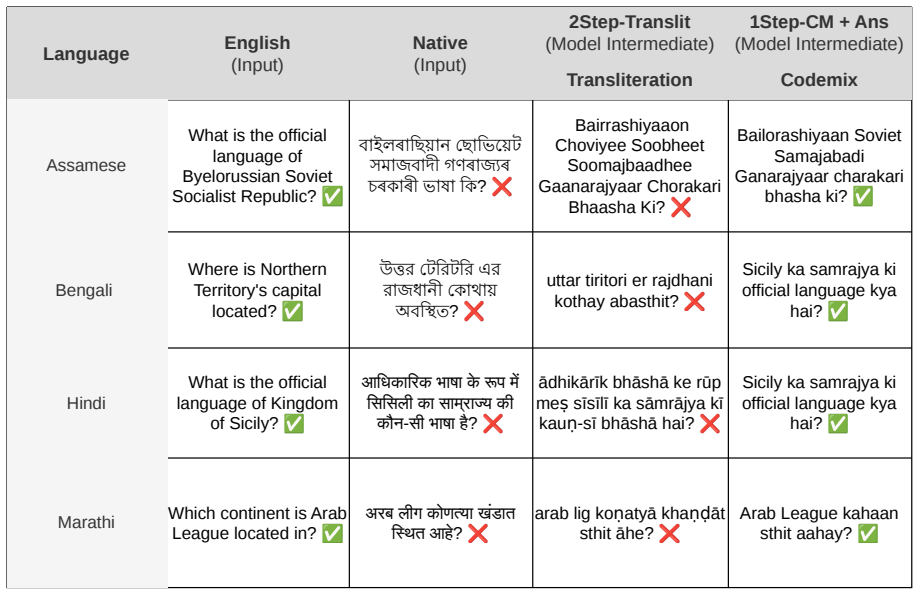
Across the tested models the native-language accuracy gap to English reaches approximately 0.50 while code-mixed inputs reduce it to approximately 0.05; a consistent flip point separating incorrect from correct predictions lies between the native and code-mixed settings whether the trajectory is produced by changing the input surface form or by the model's internal conversion process.
What carries the argument
IndiKLAR benchmark providing three-way aligned English, code-mixed, and native-language question sets for 11 language pairs with native-speaker verification.
If this is right
- Code-mixed surface forms can serve as an effective intermediate regime for knowledge recall without model changes.
- The performance boundary between native and code-mixed forms appears whether language conversion occurs externally or inside the model.
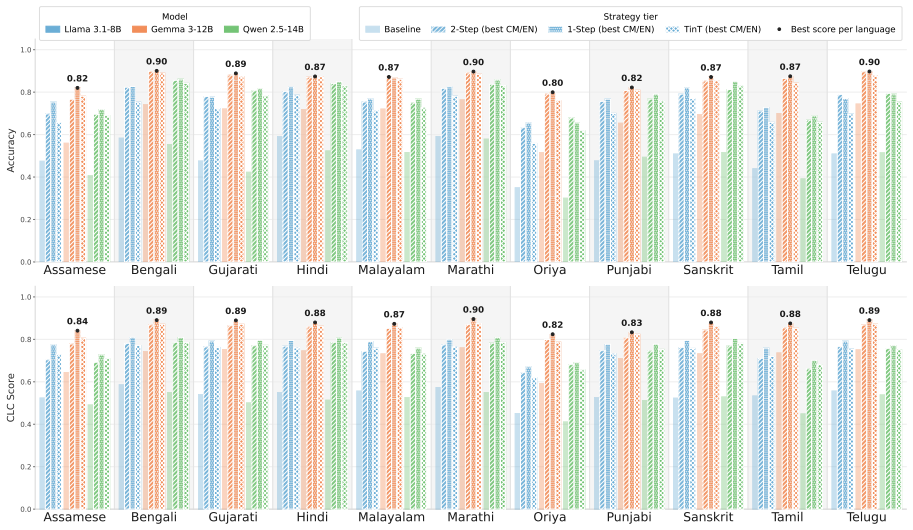
- Translate-in-Thought prompting produces the same flip-point pattern as explicit two-stage translation.
- The pattern holds across the nine evaluated open-weight models and the 11 language pairs in IndiKLAR.
Where Pith is reading between the lines
- The results suggest that models possess the relevant knowledge but access it more readily when the input contains English tokens.
- Future benchmarks could test whether the same native-to-code-mixed flip point appears in non-Indian low-resource language pairs.
- If the equivalence of question difficulty holds, the gap sizes give a direct measure of how much additional English signal is needed to unlock stored facts.
Load-bearing premise
The native-language and code-mixed versions of each question test identical underlying knowledge and have comparable difficulty.
What would settle it
A set of verified questions in which code-mixed accuracy remains more than 0.10 below English while native accuracy is not substantially lower, or in which the flip point between incorrect and correct answers disappears.
Figures



read the original abstract
Large language models recall knowledge reliably in English but often fail on the same query posed in a lower-resourced language -- a crosslingual consistency gap that remains underexplored for Indian languages and their code-mixed counterparts. To study this gap, we introduce IndiKLAR, an Indic extension of the KLAR-CLC benchmark covering 18 of the 22 scheduled Indian languages and pairing them with code-mixed variants for 11 widely used language pairs, with native-speaker verification of both monolingual and code-mixed variants for these 11 settings. This three-way alignment offers a unique opportunity to examine how knowledge recall consistency varies across the spectrum of English, code-mixed, and native Indian language inputs. Evaluating across nine open-weight models, we find that the native-language accuracy gap to English can reach $\sim$0.50, while code-mixed inputs close most of it -- bringing performance within $\sim$0.05 of English without any model-level intervention. Motivated by this, we evaluate several prompting strategies that vary in how language conversion is exposed, including a two-stage translate-then-answer setup, a one-stage joint translation-and-answer prompt, and Translate-in-Thought (TinT) -- a single-step strategy in which the model converts the input internally and emits only the final answer. Across the performance trajectory native $\rightarrow$ code-mixed $\rightarrow$ English, we identify a consistent flip point -- the boundary between incorrect and correct prediction -- that lies between the native and code-mixed settings. Interestingly, this holds whether the trajectory is induced by the input surface form or by the model's internal conversion process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IndiKLAR, an extension of the KLAR-CLC benchmark to 18 scheduled Indian languages with code-mixed variants for 11 language pairs, all verified by native speakers. It evaluates nine open-weight LLMs on three-way aligned queries (English, native, code-mixed) and reports that native-language accuracy gaps to English reach ~0.50 while code-mixed inputs reduce the gap to ~0.05. The work further tests prompting strategies (two-stage translate-then-answer, one-stage joint, and Translate-in-Thought) and identifies a consistent performance flip point lying between native and code-mixed regimes, independent of whether the trajectory is driven by input form or internal model conversion.
Significance. If the equivalence of the aligned items holds, the results demonstrate that code-mixing can substantially close cross-lingual knowledge gaps for Indian languages without any model modification, and the new benchmark supplies a reusable three-way testbed. The flip-point observation across prompting regimes offers a concrete empirical handle on where internal language conversion occurs. These contributions would be of clear interest to the multilingual LLM evaluation community.
major comments (2)
- [Benchmark construction / native-speaker verification] The central claims rest on the three-way alignment measuring identical underlying knowledge at comparable difficulty, yet the abstract and benchmark-construction description provide no protocol details: number of verifiers, inter-rater statistics, explicit criteria distinguishing "same knowledge" from surface-form effects, or whether English versions received the same verification. Without these, it remains possible that code-mixed items are easier precisely because they contain English lexical items the models already handle well, mechanically producing the reported gap compression.
- [Evaluation protocol and results] The headline numeric gaps (~0.50 native, ~0.05 code-mixed) are presented without dataset sizes per language, per-model accuracy tables, statistical significance tests, confidence intervals, or exact model versions and prompting templates. These omissions make it impossible to assess whether the reported differences are reliable or whether the flip-point identification is robust to measurement choices.
minor comments (2)
- The abstract states results for "nine open-weight models" but does not list the exact model names or sizes; this information should appear in the main text or an appendix table.
- The description of the flip point would benefit from an explicit operational definition (e.g., how the boundary between incorrect and correct prediction is quantified across the three regimes).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Benchmark construction / native-speaker verification] The central claims rest on the three-way alignment measuring identical underlying knowledge at comparable difficulty, yet the abstract and benchmark-construction description provide no protocol details: number of verifiers, inter-rater statistics, explicit criteria distinguishing "same knowledge" from surface-form effects, or whether English versions received the same verification. Without these, it remains possible that code-mixed items are easier precisely because they contain English lexical items the models already handle well, mechanically producing the reported gap compression.
Authors: We agree that additional protocol details are required for full transparency. In the revised manuscript we will expand the benchmark-construction section with a dedicated subsection that reports the number of native-speaker verifiers, inter-rater agreement statistics, the explicit criteria used to confirm that variants test identical underlying knowledge (distinct from surface-form differences), and confirmation that the English items received equivalent verification. We will also add an explicit discussion of the potential confound raised, explaining how the verification protocol required native speakers to judge semantic equivalence and comparable difficulty across the three-way aligned items, thereby ensuring that any performance difference is not mechanically attributable to English lexical items alone. revision: yes
-
Referee: [Evaluation protocol and results] The headline numeric gaps (~0.50 native, ~0.05 code-mixed) are presented without dataset sizes per language, per-model accuracy tables, statistical significance tests, confidence intervals, or exact model versions and prompting templates. These omissions make it impossible to assess whether the reported differences are reliable or whether the flip-point identification is robust to measurement choices.
Authors: We concur that these supporting details are necessary for reproducibility and for readers to evaluate the reliability of the reported gaps and the flip-point observation. The revised manuscript will include per-language and per-pair dataset sizes, full per-model accuracy tables (main text or appendix), results of statistical significance tests between conditions, confidence intervals, the precise model versions and checkpoints employed, and the complete prompting templates for the two-stage translate-then-answer, one-stage joint, and Translate-in-Thought strategies. These additions will permit direct assessment of whether the ~0.50 / ~0.05 gaps and the consistent location of the flip point are robust. revision: yes
Circularity Check
No circularity: purely empirical benchmark results with no derivations or fitted reductions
full rationale
The paper constructs IndicKLAR as a new three-way aligned benchmark (English, native Indian languages, code-mixed) and reports direct accuracy measurements on nine models. The abstract and provided text contain no equations, parameters, or derivation steps. The central claims (native gap ~0.50, code-mixed gap ~0.05) are presented as observed outcomes of running the models on the benchmark, not as outputs of any model or formula fitted to the same data. Native-speaker verification is described only as a construction step for the dataset; it is not invoked as a mathematical reduction or self-citation that forces the reported gaps. No self-citation load-bearing, ansatz smuggling, or renaming of known results occurs. The work is self-contained against external benchmarks and therefore receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
As- sociation for Computational Linguistics
Are knowledge and reference in multilingual language models cross-lingually consistent? InFind- ings of the Association for Computational Linguistics: EMNLP 2025, pages 4975–5011, Suzhou, China. As- sociation for Computational Linguistics. Xiyan Fu and Wei Liu
2025
-
[2]
Association for Computational Linguistics
How reliable is multilin- gual LLM-as-a-judge? InFindings of the Associa- tion for Computational Linguistics: EMNLP 2025, pages 11040–11053, Suzhou, China. Association for Computational Linguistics. David W Green and Jubin Abutalebi
2025
-
[3]
Journal of cognitive psychology, 25(5):515–530
Language control in bilinguals: The adaptive control hypothesis. Journal of cognitive psychology, 25(5):515–530. François Grosjean. 2008.Studying bilinguals. Oxford University Press. Ashim Gupta, Maitrey Mehta, Zhichao Xu, and Vivek Srikumar
2008
-
[4]
Hongjin Kim, Jaewook Lee, Kiyoung Lee, Jong-hun Shin, Soojong Lim, and Oh-Woog Kwon
Mubench: Assessment of multilingual capabilities of large language models across 61 languages.arXiv preprint arXiv:2506.19468. Hongjin Kim, Jaewook Lee, Kiyoung Lee, Jong-hun Shin, Soojong Lim, and Oh-Woog Kwon
-
[5]
Yihong Liu, Bingyu Xiong, and Hinrich Schütze
On the entity-level align- ment in crosslingual consistency.arXiv preprint arXiv:2510.10280. Yihong Liu, Bingyu Xiong, and Hinrich Schütze
-
[6]
Evaluating contextually mediated factual recall in multilingual large language models.arXiv preprint arXiv:2601.12555. Nostalgebraist
-
[7]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10650–10666, Singa- pore
Cross-lingual consistency of factual knowledge in multilingual language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10650–10666, Singa- pore. Association for Computational Linguistics. Dan Wang, Boxi Cao, Ning Bian, Xuanang Chen, Yao- jie Lu, Hongyu Lin, Jia Zheng, Le Sun, Shanshan Jiang, Bin Don...
2023
-
[8]
to quantify whether the model retrieves consistent knowledge across different languages.CLC is computed using the overlap ratio between the sets of correctly predicted sample indices across language pairs. Given two languages La and Lb, with corresponding correct prediction sets Ca and Cb, the consistency score is defined as: CLC(La, Lb) = |Ca ∩C b| |Ca ∪...
2020
-
[9]
averaged across evaluation samples. 11 Variant #Instances Avg Query Length Avg Answer Length Native Indian Languages 2619 9.23 1.13Code-Mixed Variants 2619 9.20 1.02 Table 5: Dataset statistics for INDIKLAR (open-source under CC-BY-4.0 license). A.2 Inference Time Analysis Table 6 reports the average per-sample end-to-end runtime across prompting strategi...
1902
-
[10]
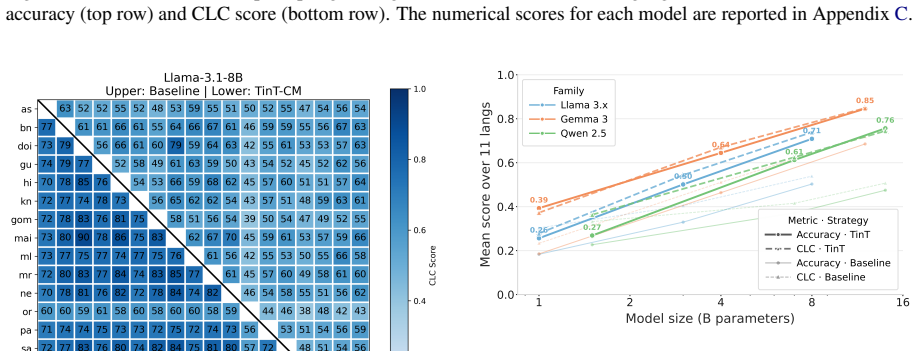
The trend is sharpest within the Qwen family, where the average TinT-EN ac- curacy gain rises from 0.062 for Qwen2.5-1.5B to 0.244and0.288for the7B and14B variants
This insta- bility largely disappears at scale— Llama-3.1-8B, Qwen2.5-7B, and Qwen2.5-14B all achieve posi- tive accuracy and CLC gains across every language under both variants. The trend is sharpest within the Qwen family, where the average TinT-EN ac- curacy gain rises from 0.062 for Qwen2.5-1.5B to 0.244and0.288for the7B and14B variants. The two varia...
2026
-
[11]
translation
This bench- Variant #Instances Avg Query Length Avg Answer Length Liu et al. (2026) 1742 22.00 1.02 Table 8: Dataset statistics for the contextually mediated knowledge recall benchmark. mark differs from INDIKLAR in that knowledge is accessed through naturalistic referential con- text rather than direct entity queries, making it a stronger test of crossli...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.