Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
Pith reviewed 2026-06-29 07:55 UTC · model grok-4.3
The pith
Wikipedia co-occurrence statistics supply sentence-level process rewards that improve factual accuracy in question answering for every tested model and benchmark while training several times faster than neural verifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
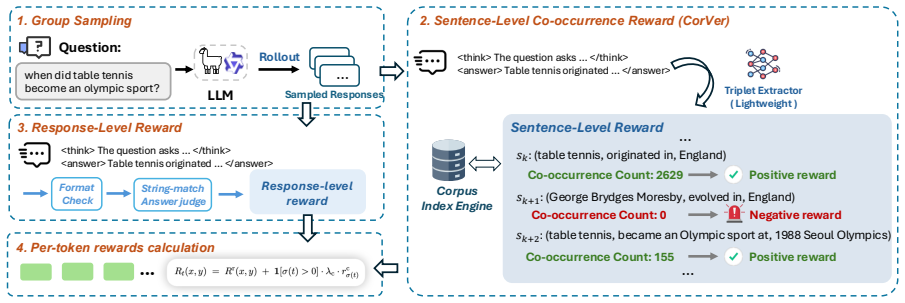
CorVer derives sentence-level credit directly from Wikipedia co-occurrence statistics and aligns the resulting scores to token-level advantages, thereby supplying verifiable process supervision that improves factual question-answering performance without relying on NLI models, LLM judges, or heavy verification pipelines.
What carries the argument
CorVer, a corpus-grounded process reward that assigns sentence-level credit from Wikipedia co-occurrence statistics and maps it to token-level advantages via simple alignment.
If this is right
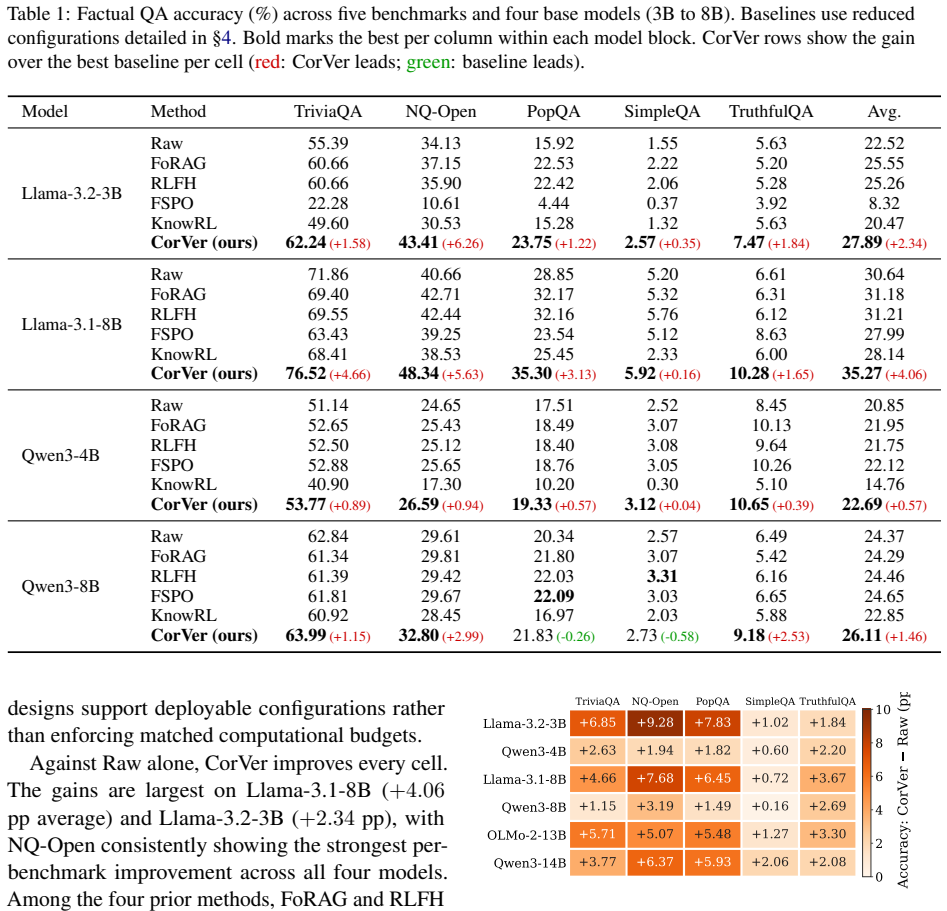
- Performance improves over the raw baseline in all thirty model-benchmark cells.
- Average TriviaQA gain reaches 4.1 percentage points.
- The method outperforms four neural-verifier baselines in eighteen of twenty feasible cells.
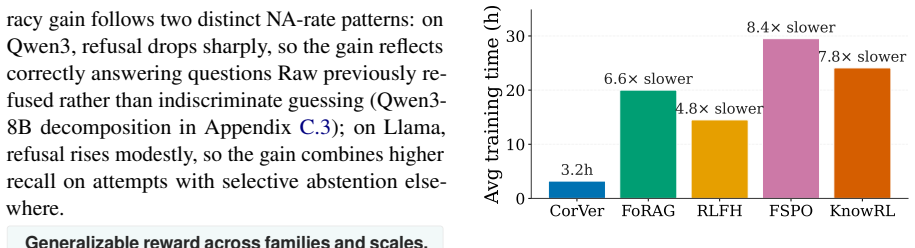
- Training runs 4.8 to 8.4 times faster than the neural-verifier baselines.
- Only a 0.5B extractor and a single corpus lookup per sentence are required at RL scale.
Where Pith is reading between the lines
- The same co-occurrence approach could be tested on other large static corpora to handle domains where Wikipedia coverage is thin.
- Because the reward is parameter-light, it may allow process supervision to be applied at larger batch sizes or longer context lengths than neural-verifier methods currently permit.
- Gains on rare entities suggest the signal could be combined with retrieval-augmented generation to further reduce hallucinations on long-tail facts.
Load-bearing premise
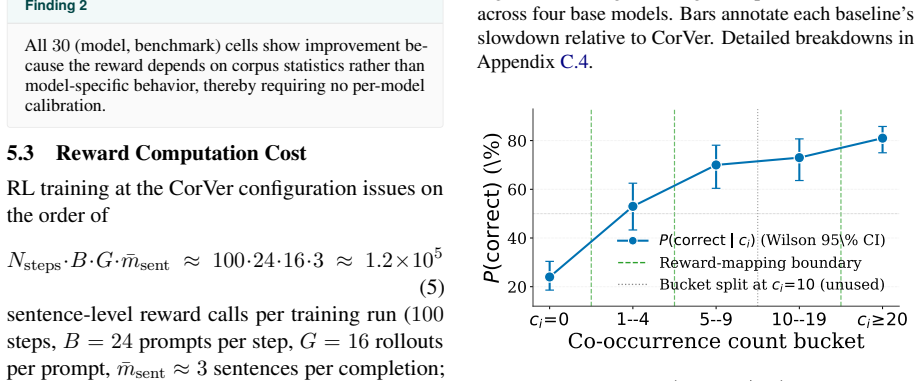
Wikipedia co-occurrence statistics provide a reliable proxy for factual correctness of individual statements in reasoning traces, especially for rare-entity facts.
What would settle it
A held-out collection of reasoning traces in which incorrect statements about rare entities receive systematically higher Wikipedia co-occurrence scores than correct statements, or in which correct statements receive low scores.
Figures



read the original abstract
Applying reinforcement learning to improve factual accuracy in knowledge-intensive question answering faces a reward design dilemma. Response-level rewards provide only coarse supervision and cannot distinguish correct from incorrect statements within a reasoning trace. Sentence-level alternatives offer finer-grained feedback, but typically rely on NLI verifiers, LLM judges, or knowledge-verification pipelines that are expensive to deploy at RL scale and often unreliable for rare-entity facts, where accurate reward signals are especially important. We propose CorVer (Corpus Verify), a lightweight, plug-in-ready process reward that replaces neural verifiers with a corpus-grounded signal derived from Wikipedia co-occurrence statistics. CorVer assigns sentence-level credit and maps it to token-level advantages via a simple alignment, requiring only a 0.5B extractor and a single corpus lookup per sentence. Across 30 (model, benchmark) cells spanning six instruction-tuned models (3B to 14B) and five QA benchmarks, CorVer improves over the raw baseline for every cell, with an average TriviaQA gain of +4.1 pp. It also outperforms four neural-verifier baselines in 18 of 20 cells under their feasible configurations, while training 4.8 to 8.4x faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CorVer, a lightweight process reward for RL in factual QA that derives sentence-level credit from Wikipedia co-occurrence statistics rather than neural verifiers or LLM judges. It reports uniform gains over the raw baseline in all 30 (model, benchmark) cells across six instruction-tuned models (3B–14B) and five QA benchmarks, an average +4.1 pp TriviaQA improvement, outperformance of four neural-verifier baselines in 18/20 feasible cells, and 4.8–8.4× faster training.
Significance. If the central claim holds, CorVer supplies a scalable, low-cost alternative to expensive neural process rewards for knowledge-intensive tasks, addressing the expense and rare-entity unreliability of NLI/LLM verifiers while enabling finer-grained supervision than response-level rewards.
major comments (2)
- [Abstract] Abstract: the central claim that sentence-level CorVer rewards serve as a reliable proxy for factual accuracy in reasoning traces is load-bearing, yet the manuscript provides no error analysis, controls for confounds (e.g., common misconceptions or error discussions in Wikipedia), or validation that co-occurrence distinguishes correctness from association, particularly for the rare-entity regime highlighted as critical.
- [Abstract] Abstract: the reported uniform improvements and speedups rest on an unspecified reward computation, alignment procedure, and extractor details; without these, the 30-cell gains cannot be reproduced or isolated from potential confounds in the co-occurrence signal.
minor comments (1)
- The abstract states a '0.5B extractor' and 'single corpus lookup' but does not specify the exact Wikipedia dump version, preprocessing, or co-occurrence threshold used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to strengthen validation and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that sentence-level CorVer rewards serve as a reliable proxy for factual accuracy in reasoning traces is load-bearing, yet the manuscript provides no error analysis, controls for confounds (e.g., common misconceptions or error discussions in Wikipedia), or validation that co-occurrence distinguishes correctness from association, particularly for the rare-entity regime highlighted as critical.
Authors: We agree that direct validation of the proxy would strengthen the central claim beyond the observed empirical gains. The manuscript currently presents the 30-cell improvements as supporting evidence but lacks explicit error analysis. We will add a dedicated subsection with manual and quantitative analysis of cases where co-occurrence may reflect association rather than correctness, including controls for confounds such as Wikipedia discussions of common misconceptions and a focused breakdown on rare-entity examples. revision: yes
-
Referee: [Abstract] Abstract: the reported uniform improvements and speedups rest on an unspecified reward computation, alignment procedure, and extractor details; without these, the 30-cell gains cannot be reproduced or isolated from potential confounds in the co-occurrence signal.
Authors: The reward computation (Section 3.2), alignment procedure (Section 3.3), and 0.5B extractor details (Section 3.1) are specified in the manuscript with pseudocode and hyperparameters. To improve accessibility and reproducibility, we will expand the abstract with a brief summary of these components and ensure all implementation details are consolidated in a dedicated reproducibility subsection. revision: yes
Circularity Check
No circularity: CorVer reward sourced from external Wikipedia co-occurrence statistics
full rationale
The paper constructs its sentence-level reward directly from Wikipedia co-occurrence counts as an external proxy, with no equations or definitions that reduce the claimed prediction or advantage to a fitted parameter or self-referential input. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no renaming of known results occurs. The empirical improvements across 30 cells are presented as external validation rather than definitional. This satisfies the self-contained criterion against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wikipedia co-occurrence statistics reliably indicate factual correctness of sentences.
Reference graph
Works this paper leans on
-
[1]
Learning to reason for factuality.arXiv preprint arXiv:2508.05618, 2025
Reward hacking mitigation using verifiable composite rewards. InProceedings of the 16th ACM International Conference on Bioinformatics, Com- putational Biology, and Health Informatics, pages 1–6. Tianchi Cai, Zhiwen Tan, Xierui Song, Tao Sun, Jiyan Jiang, Yunqi Xu, Yinger Zhang, and Jinjie Gu. 2024. Forag: Factuality-optimized retrieval augmented gen- era...
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capa- bility in LLMs via Reinforcement Learning.Nature, 645(8081):633–638. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tra, A...
-
[3]
arXiv preprint arXiv:2401.17377 , year=
Curran Associates, Inc. Junyi Li and Hwee Tou Ng. 2025. Reasoning mod- els hallucinate more: Factuality-aware reinforcement learning for large reasoning models. InAdvances in Neural Information Processing Systems, volume 38, pages 151064–151085. Curran Associates, Inc. 9 Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, ...
-
[4]
Quco-rag: Quantifying uncertainty from the pre-training corpus for dynamic retrieval-augmented generation.arXiv preprint arXiv:2512.19134. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettle- moyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
i don’t know
Qwen3 Technical Report.arXiv preprint. A Training Setup and Recipe A.1 Full Hyperparameters All Raw + RL runs use a LoRA policy with rank r= 128 , α= 256 , dropout 0.0, no bias, and target modules q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj (task type CAUSAL_LM). For CorVer, the same LoRA shape is used for every model from 3B to 14B. Ran...
2024
-
[6]
Do not loop or repeat the same point or phrase
The step-100 row matches the canonical CorVer entry for Llama-3.2-3B-Instruct in Table 15; the step-200 row is the empirical peak. Step Cor (%) Inc (%) NA (%)∆Cor 0(Raw)55.39 42.43 2.18— 50 59.20 38.23 2.57 +3.81 100(default)62.24 32.72 5.04 +6.85 150 61.65 35.36 2.99 +6.26 200(peak)63.8533.04 3.11 +8.46 250 63.72 33.40 2.88 +8.33 300 63.40 33.81 2.79 +8....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.