Think Fast, Talk Smart: Partitioning Deterministic and Neural Computation for Structured Health Text Generation
Pith reviewed 2026-06-29 07:22 UTC · model grok-4.3
The pith
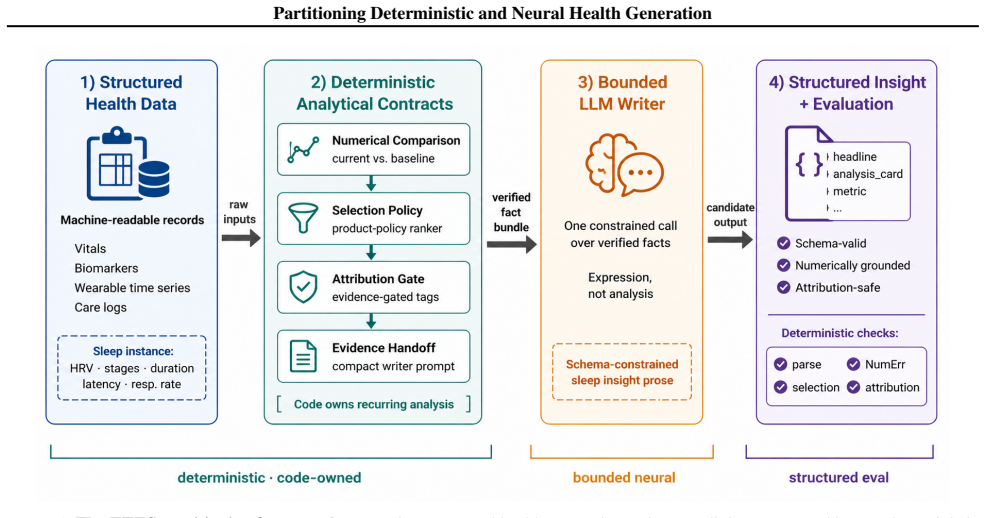
Code performs recurring health data analysis before one bounded LLM call to cut numeric errors and costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
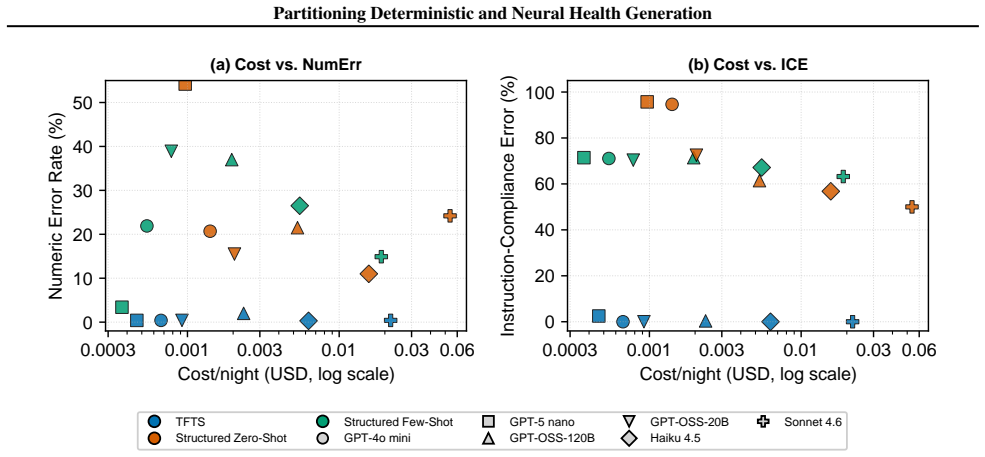
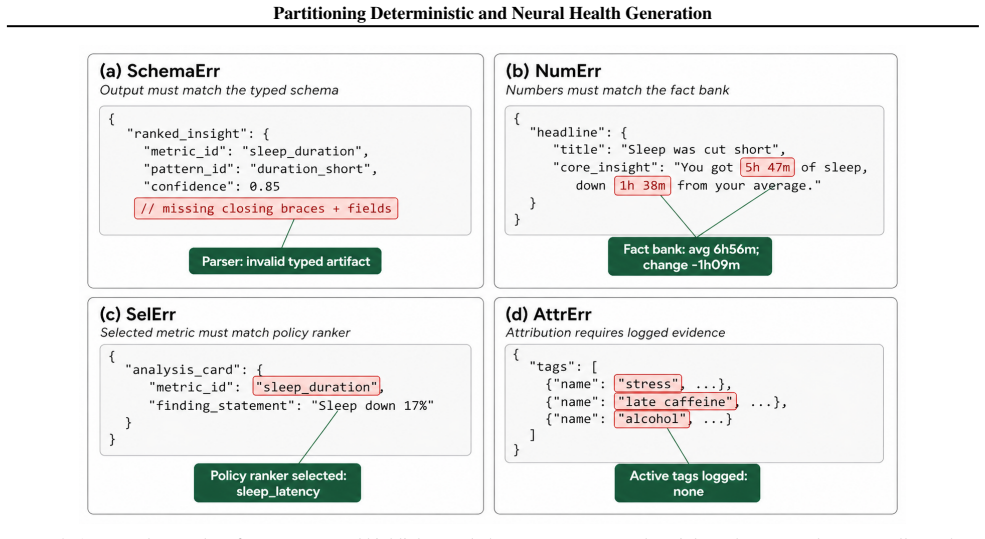
The paper claims that for recurring health outputs, deterministic code should own recurring analysis while LLMs express verified facts within bounded interfaces. The Think Fast, Talk Smart pipeline, which runs deterministic analysis before one bounded LLM writer call, achieves lower numeric error, lower instruction-compliance error, and lower end-to-end cost than structured zero-shot and few-shot one-call baselines across 280 user-nights and six models. Layer replacement experiments show contract-specific failures when LLM components replace code: higher numeric error from LLM comparison, degraded policy selection from LLM ranking, increased unsupported causal language from LLM attribution,
What carries the argument
The Think Fast, Talk Smart pipeline, which uses deterministic code for recurring analysis before one bounded LLM writer call.
If this is right
- Numeric error falls when code owns all recurring calculations instead of LLM comparison.
- Policy selection improves when code performs ranking rather than LLM ranking.
- Unsupported causal language decreases when attribution remains deterministic.
- Reintroducing an LLM-generated writer interface raises errors even when upstream facts are fixed by code.
- End-to-end cost drops for repeated use when only one bounded LLM call occurs per output.
Where Pith is reading between the lines
- The same split could apply to other structured generation domains such as financial summaries or regulatory reports where facts must remain traceable.
- Systems could monitor recurrence frequency of analysis tasks to decide which parts to move from LLM to code over time.
- Error patterns observed in layer replacements suggest auditing protocols that test each interface boundary separately rather than end-to-end only.
Load-bearing premise
The deterministic code components can be correctly specified and maintained to perform all recurring analysis tasks without introducing systematic errors that would be harder to detect than those from LLM prompting.
What would settle it
Run the hybrid pipeline and full-LLM baselines on a new collection of health records and measure whether numeric error, instruction-compliance error, and cost remain lower for the hybrid approach.
Figures

read the original abstract
Large language models (LLMs) are increasingly being used to generate health text from structured records such as wearable time series, biomarkers, vitals, and care-management logs. For recurring health outputs, fluency is not enough: systems must remain faithful to source data, ground explanatory claims in available evidence, follow stated policies, emit machine-readable outputs, and run cheaply enough for repeated use. We ask which responsibilities in structured health generation should be deterministic computation rather than runtime LLM prompting. We introduce Think Fast, Talk Smart, a sleep-health insight pipeline in which deterministic code performs recurring analysis before one bounded LLM writer call. Across 280 user-nights and six models, achieves lower numeric error, lower instruction-compliance error, and lower end-to-end cost than structured zero-shot and few-shot one-call baselines. Layer replacement reveals contract-specific failures: LLM comparison raises numeric error, LLM ranking degrades policy selection, LLM attribution increases unsupported causal language, and an LLM-generated writer interface reintroduces errors even after upstream facts are deterministic. The results support a broader design rule: let code own recurring analysis, and let LLMs express verified facts within bounded interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 'Think Fast, Talk Smart', a hybrid pipeline for generating structured sleep-health insights from wearable time series, biomarkers, vitals, and logs. Deterministic code performs all recurring analysis before a single bounded LLM writer call. On 280 user-nights across six models, the hybrid reports lower numeric error, lower instruction-compliance error, and lower end-to-end cost than structured zero-shot and few-shot one-call LLM baselines. Layer-replacement experiments isolate contract-specific LLM failures (numeric error in comparison, policy degradation in ranking, unsupported causal language in attribution, and reintroduced errors from an LLM-generated writer interface). The results are presented as supporting the design rule that code should own recurring analysis while LLMs express verified facts within bounded interfaces.
Significance. If the empirical comparisons hold, the work supplies concrete evidence that explicit partitioning of deterministic and neural responsibilities can improve fidelity, policy compliance, and cost in health text generation. The layer-replacement protocol is a useful diagnostic for locating where LLM components introduce specific error types. The approach aligns with reproducibility goals by making the deterministic analysis steps explicit and machine-checkable, though the manuscript does not ship code or parameter-free derivations.
major comments (2)
- [Methods] Methods section: the description of the 280 user-nights dataset (selection criteria, exact structure of input records, definition of ground-truth labels for numeric and compliance errors) is insufficient to evaluate whether the reported error reductions are robust or generalizable; without these details the central performance claims cannot be verified.
- [Abstract / Conclusion] Abstract and final paragraph: the claim that the results 'support a broader design rule' that deterministic code can own recurring analysis without introducing harder-to-detect systematic errors is not load-bearingly tested; the experiments validate the hybrid only for the specific sleep-health pipeline and do not include any stress test of code-specification reliability or drift.
minor comments (1)
- [Abstract] The abstract states results across 'six models' but does not name them or indicate which were used for the primary tables; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [Methods] Methods section: the description of the 280 user-nights dataset (selection criteria, exact structure of input records, definition of ground-truth labels for numeric and compliance errors) is insufficient to evaluate whether the reported error reductions are robust or generalizable; without these details the central performance claims cannot be verified.
Authors: We agree that the Methods section requires additional detail for reproducibility and verification. In the revised manuscript we will expand this section to specify the selection criteria for the 280 user-nights, the exact schema and fields of each input record (wearable time series, biomarkers, vitals, and logs), and the precise definitions plus annotation protocol used to produce ground-truth labels for numeric error and instruction-compliance error. revision: yes
-
Referee: [Abstract / Conclusion] Abstract and final paragraph: the claim that the results 'support a broader design rule' that deterministic code can own recurring analysis without introducing harder-to-detect systematic errors is not load-bearingly tested; the experiments validate the hybrid only for the specific sleep-health pipeline and do not include any stress test of code-specification reliability or drift.
Authors: We accept that the experiments are limited to the sleep-health pipeline and contain no explicit stress tests of code-specification reliability or drift. The layer-replacement results do isolate contract-specific LLM failure modes, providing targeted support for the partitioning strategy within the evaluated setting. We will revise the abstract and conclusion to present the design rule as supported by the reported evidence for this class of structured health text generation tasks, while adding an explicit statement of scope and the lack of broader reliability or drift testing as a limitation and future-work item. revision: yes
Circularity Check
No circularity: empirical pipeline comparison with independent experimental validation
full rationale
The paper reports an empirical study comparing deterministic code + bounded LLM pipelines against pure LLM baselines on 280 user-nights of sleep-health data. Performance metrics (numeric error, instruction-compliance error, cost) are measured directly from runs; layer-replacement experiments isolate component failures. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The design rule is presented as an inference from the observed results rather than a self-definitional or fitted-input claim. This is the expected non-finding for an applied systems paper whose central claims rest on external falsifiable measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Surv.55, 1–38, DOI: 10.1145/3571730 (2023)
doi: 10.1145/3571730. Khasentino, J., Belyaeva, A., Liu, X., Yang, Z., Furlotte, N. A., et al. A personal health large language model for sleep and fitness coaching.Nature Medicine, 31(10): 3394–3403,
-
[2]
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., San- thanam, K., et al
doi: 10.1038/s41591-025-03888-0. Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., San- thanam, K., et al. DSPy: Compiling declarative language model calls into self-improving pipelines. InInterna- tional Conference on Learning Representations,
-
[3]
doi: 10.1038/s41591-023-02528-7. Thirunavukarasu, A. J., Ting, D. S. J., Elangovan, K., Gutier- rez, L., Tan, T. F., and Ting, D. S. W. Large language models in medicine.Nature medicine, 29(8):1930–1940,
-
[4]
M., and Rush, A
Wiseman, S., Shieber, S. M., and Rush, A. M. Challenges in data-to-document generation. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 2253–2263. Association for Computa- tional Linguistics,
2017
-
[5]
date": "2026-02-23
5 Partitioning Deterministic and Neural Health Generation Appendix A. Full Results Table 1.Full condition-by-model results. Values are percentages except n, COST/NIGHT, and latency. SCHEMAERRis the final parse/schema failure rate; SELERRis disagreement with the selection rule; ATTRERRis unsupported attribution. Replacement conditions include both the arti...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.