PTCG-Bench: Can LLM Agents Master Pok\'emon Trading Card Game?
Pith reviewed 2026-06-29 07:19 UTC · model grok-4.3
The pith
LLM agents reach non-trivial performance in Pokémon Trading Card Game but self-evolution stays unstable and harness-dependent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
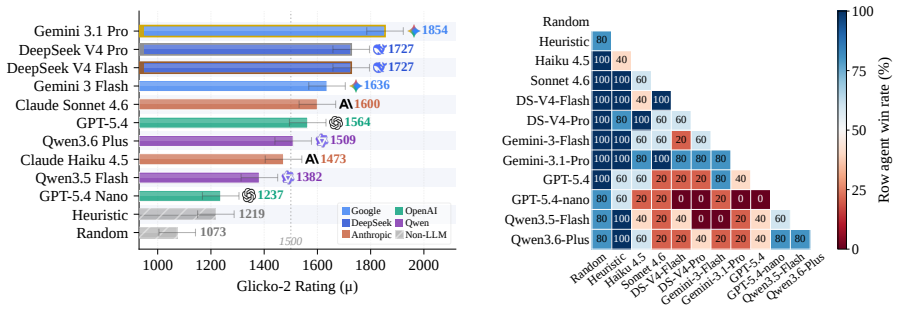
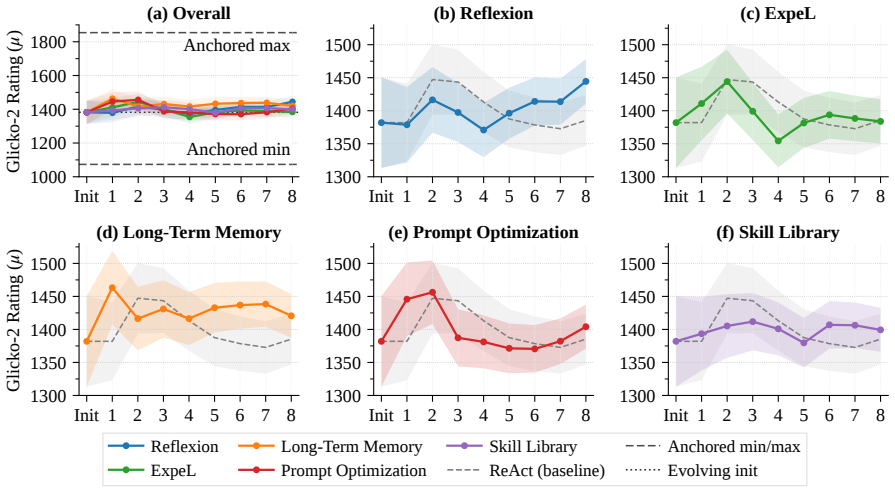
LLM agents demonstrate non-trivial gameplay performance inside the Pokémon Trading Card Game, yet sustained and stable self-evolution through accumulated experience remains challenging, with observed performance highly sensitive to the design of the modular harness that connects the agent to the environment.
What carries the argument
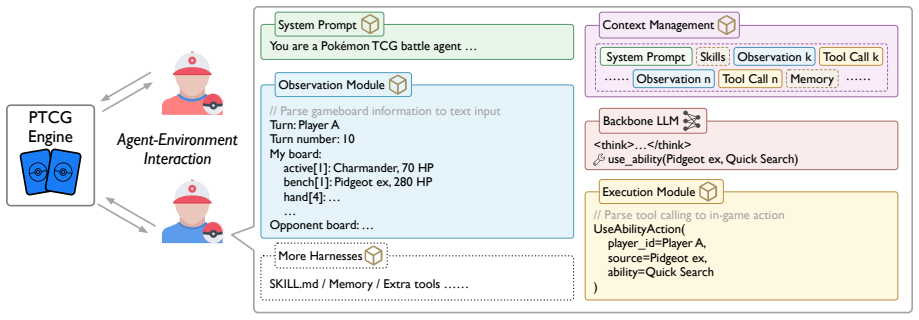
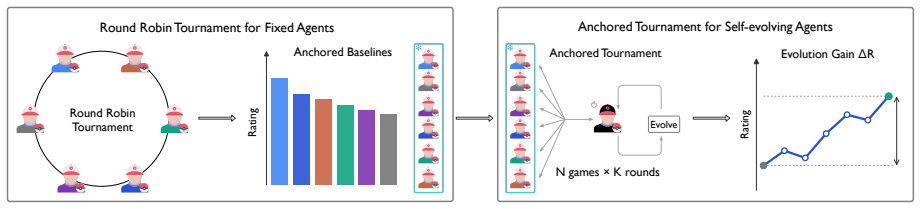
PTCG-Bench environment together with its modular harness ablation, which isolates agent decision-making and self-evolution from model capability and interface choices.
If this is right
- Agents can reach non-trivial levels of play in strategically complex card games without task-specific training.
- Self-evolution through experience does not occur reliably or stably under current agent setups.
- Small differences in how an agent is connected to the game environment produce large differences in measured performance.
- Benchmarks that combine single-environment decision-making with explicit self-evolution tracking are needed to study realistic agent improvement.
Where Pith is reading between the lines
- Harness design may need to become a first-class research target rather than an afterthought when building evolving agents.
- The benchmark could be reused to compare explicit memory or planning modules against pure LLM prompting.
- Similar harness-sensitive patterns may appear in other long-horizon interactive domains such as real-time strategy or negotiation tasks.
- If harness effects dominate, scaling model size alone may not close the gap to stable self-evolution.
Load-bearing premise
The PTCG environment plus the modular harness ablation successfully separates agent decision-making and self-evolution from effects of model capability and interface choices.
What would settle it
A controlled run in which multiple LLM agents exhibit consistent win-rate gains across successive games when the harness and base model are held fixed would falsify the claim that self-evolution is inherently unstable.
Figures



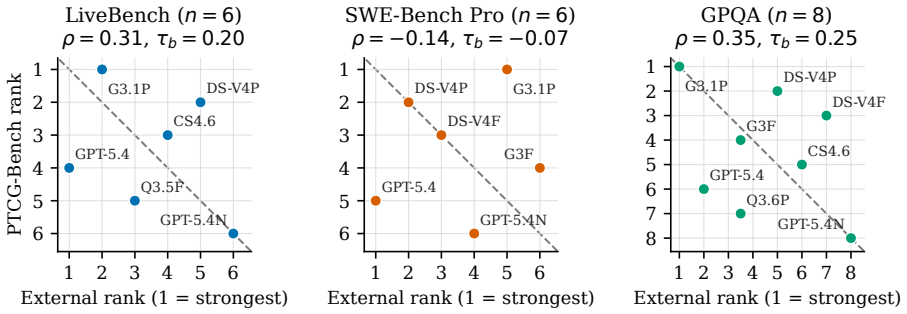
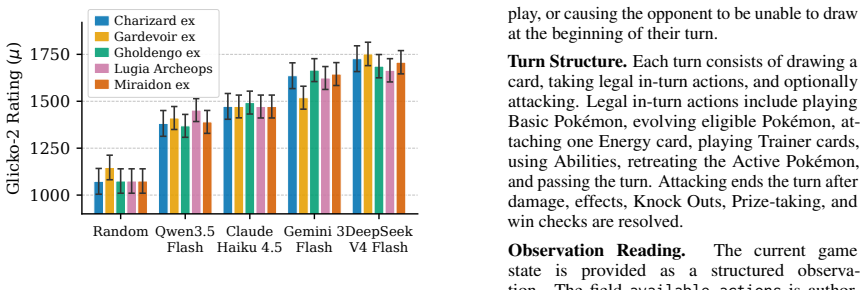
read the original abstract
Given a strategically complex board game, human players can quickly learn to devise strategies after playing a few rounds. Autonomous agents require similar capabilities in realistic interactive environments, yet existing agent benchmarks often fail to fully capture such strategic and evolving decision-making scenarios. We present PTCG-Bench, a benchmark built on the Pok'{e}mon Trading Card Game (PTCG) that evaluates LLM agents at two complementary levels: (1) their decision-making performance within a single complex environment, and (2) their ability to self-evolving through accumulated experience. We further include a modular harness ablation to better interpret agent performance without conflating it with model capability. Our experiments show that, although LLM agents can achieve non-trivial gameplay performance, sustained and stable self-evolution remains challenging, and performance is sensitive to harness design. We hope that PTCG-Bench will facilitate future research on harness-aware and self-evolving agents in realistic interactive environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PTCG-Bench, a benchmark built on the Pokémon Trading Card Game to evaluate LLM agents on two levels: decision-making performance in a complex interactive environment and the ability to self-evolve via accumulated experience. It incorporates a modular harness ablation intended to separate agent performance from model capability and interface effects. Experiments are reported to show non-trivial gameplay performance but persistent challenges with sustained, stable self-evolution, along with sensitivity to harness design.
Significance. If the central experimental claims hold after addressing isolation concerns, the work supplies a strategically rich, realistic benchmark that existing agent evaluations often lack, together with an explicit modular ablation for interpreting results. This directly supports research on harness-aware and self-evolving agents and provides a concrete testbed for experience accumulation in board-game settings.
major comments (1)
- [Modular harness ablation (methods/experiments)] The modular harness ablation (described in the methods and experiments sections) does not report whether harness variants were normalized for equivalent information density, state serialization format, token count, or output constraints. Without such controls, performance differences and the reported difficulty of stable self-evolution could arise from uncontrolled prompt or formatting interactions with the LLM rather than from intrinsic limitations in decision-making or experience accumulation, directly weakening the isolation claim that underpins the benchmark's interpretability.
minor comments (1)
- [Abstract] The abstract summarizes experimental outcomes on performance and self-evolution without any quantitative metrics, baselines, or error bars; adding even high-level numbers would strengthen the summary paragraph.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the modular harness ablation. We address the concern below.
read point-by-point responses
-
Referee: [Modular harness ablation (methods/experiments)] The modular harness ablation (described in the methods and experiments sections) does not report whether harness variants were normalized for equivalent information density, state serialization format, token count, or output constraints. Without such controls, performance differences and the reported difficulty of stable self-evolution could arise from uncontrolled prompt or formatting interactions with the LLM rather than from intrinsic limitations in decision-making or experience accumulation, directly weakening the isolation claim that underpins the benchmark's interpretability.
Authors: We appreciate the referee highlighting this important aspect of experimental control. The modular harness ablation was designed such that state serialization formats and output constraints were kept consistent across variants to isolate the effects of different harness components. However, we acknowledge that the manuscript does not explicitly report metrics such as token counts or information density for each variant. To address this, in the revised version we will include additional details and a supplementary table reporting the average token usage, information density, and formatting details for each harness variant. This will provide stronger evidence that the observed performance differences and challenges in self-evolution are attributable to the harness design rather than variations in prompt characteristics. revision: yes
Circularity Check
Empirical benchmark paper with no derivation chain or self-referential reductions
full rationale
The paper presents PTCG-Bench as a new external evaluation environment for LLM agents, reporting empirical performance on decision-making and self-evolution via harness ablations. No equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear in the provided text. Central claims rest on experimental runs in the PTCG simulator rather than any closed derivation that reduces to its own inputs by construction. This is the standard case of a self-contained benchmark contribution with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Swe-bench pro: Can ai agents solve long- horizon software engineering tasks?arXiv preprint arXiv:2509.16941. Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Man- dlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
lmgame-bench: How good are llms at playing games? arXiv preprint arXiv:2505.15146, 2025
Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343– 18362. Mark E Glickman. 2012. Example of the glicko-2 sys- tem.Boston University, 28:2012. Frank Harary and Leo Moser. 1966. The theory of round robin tournaments.The American Mathemati- cal Monthly, 73(3):231–246. Lanxi...
-
[3]
Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games
Orak: A foundational benchmark for training and evaluating llm agents on diverse video games. arXiv preprint arXiv:2506.03610. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S Bern- stein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th an- nual acm symposium o...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Livebench: A challenging, contamination-free llm benchmark.arXiv preprint arXiv:2406.19314, 4:2. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2026. A-mem: Agentic memory for llm agents.Advances in Neural Informa- tion Processing Systems, 38:17577–17604. John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.