Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
Pith reviewed 2026-06-29 07:40 UTC · model grok-4.3
The pith
Domino decouples causal modeling from autoregressive drafting to accelerate speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
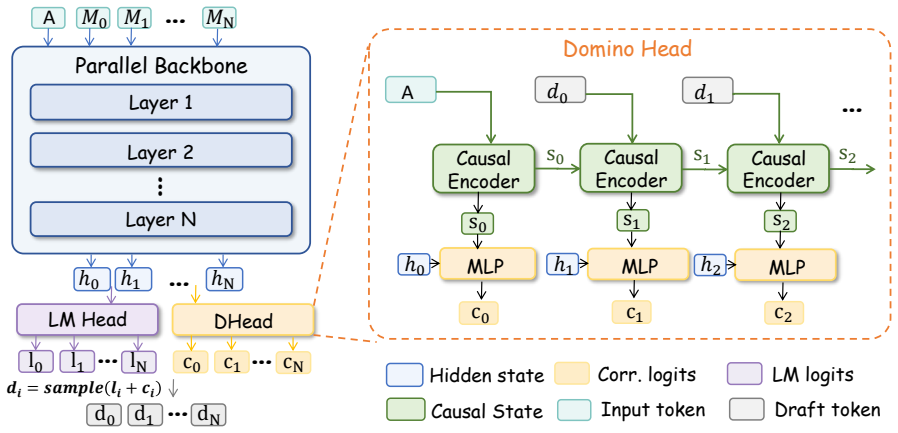
Domino decouples causal dependency modeling from expensive autoregressive draft execution by first using a parallel draft backbone to produce preliminary draft distributions for the entire block, then applying a lightweight Domino head to refine them with prefix-dependent causal information, stabilized by a base-anchored training curriculum that first strengthens the parallel backbone and then shifts optimization toward the causally corrected final distribution.
What carries the argument
The Domino head, a lightweight module that adds prefix-dependent causal information to parallel draft distributions.
If this is right
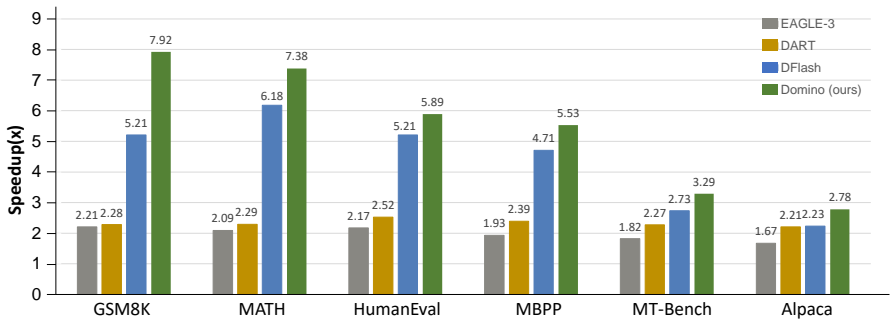
- Achieves up to 5.49× end-to-end speedup under the Transformers backend.
- Achieves up to 5.8× throughput speedup under SGLang serving.
- Maintains draft quality while reducing sequential overhead in drafting.
- Stabilizes training of causal encoding without degrading the parallel component.
Where Pith is reading between the lines
- The decoupling strategy may extend to other inference optimization techniques in language models.
- Similar training curricula could be used in other hybrid parallel-sequential model designs.
- Testing on additional model families beyond Qwen3 could reveal broader applicability.
Load-bearing premise
The lightweight Domino head can refine the parallel backbone's preliminary distributions with prefix-dependent causal information at negligible extra cost, and the base-anchored training curriculum successfully stabilizes teacher-forced causal encoding without degrading the parallel component.
What would settle it
If measurements on Qwen3 models show that the overall inference latency is not reduced compared to standard speculative decoding methods, the speedup claims would be falsified.
Figures


read the original abstract
Speculative decoding accelerates LLM inference by drafting multiple tokens and verifying them in parallel with the target model. However, its practical speedup is constrained by the trade-off between draft quality and drafting cost: autoregressive drafters model causal dependencies among draft tokens but incur sequential overhead, while parallel drafters reduce drafting cost but weaken intra-block dependency modeling. In this paper, we propose Domino, a speculative decoding framework that decouples causal dependency modeling from expensive autoregressive draft execution. Domino first uses a parallel draft backbone to produce preliminary draft distributions for the entire block, and then applies a lightweight Domino head to refine them with prefix-dependent causal information. To stabilize teacher-forced causal encoding, we further introduce a base-anchored training curriculum that first strengthens the parallel backbone and then gradually shifts optimization toward the causally corrected final distribution. Experiments on Qwen3 models show that Domino achieves up to \(5.49\times\) end-to-end speedup under the Transformers backend and up to \(5.8\times\) throughput speedup under SGLang serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Domino, a speculative decoding framework that decouples causal dependency modeling from autoregressive draft execution. It employs a parallel draft backbone to produce preliminary draft distributions for an entire block of tokens, followed by a lightweight Domino head that refines these distributions using prefix-dependent causal information. A base-anchored training curriculum is introduced to first strengthen the parallel backbone before gradually shifting optimization toward the causally corrected final distribution. Experiments on Qwen3 models report up to 5.49× end-to-end speedup under the Transformers backend and up to 5.8× throughput speedup under SGLang serving.
Significance. If the reported speedups are reproducible under controlled conditions with full experimental details, this work meaningfully advances speculative decoding by improving the draft quality versus cost trade-off through architectural decoupling rather than relying solely on autoregressive or parallel drafters. The approach maintains internal consistency with standard speculative decoding assumptions and avoids circularity in its performance claims, offering a practical contribution to efficient LLM inference that could influence both academic and serving-system designs.
minor comments (2)
- [Abstract] Abstract: The speedups are reported as 'up to' values; including average or median speedups across sequences (with standard deviations) would strengthen the empirical claims and allow better comparison to prior work.
- [§4] The description of how the Domino head's overhead is accounted for in the end-to-end measurements should be expanded in the experimental section to confirm the 'negligible extra cost' assumption holds across all tested configurations.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Domino and the recommendation for minor revision. The feedback correctly identifies the core contribution of decoupling causal modeling from autoregressive drafting while preserving standard speculative decoding assumptions.
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an empirical architecture (parallel draft backbone + lightweight Domino head + base-anchored curriculum) whose claimed speedups are measured on Qwen3 models under Transformers and SGLang backends. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the central claims to inputs by construction. The derivation chain is therefore self-contained and externally falsifiable via the reported throughput numbers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zihao An, Huajun Bai, Ziqiong Liu, Dong Li, and Emad Barsoum. 2026. Pard: Accelerating llm inference with low-cost parallel draft model adaptation. In International Conference on Learning Representations
2026
- [2]
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program synthesis with large language models. arXiv preprint arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 5209--5235. PMLR
2024
-
[5]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Jian Chen, Yesheng Liang, and Zhijian Liu. 2026. Dflash: Block diffusion for flash speculative decoding. arXiv preprint arXiv:2602.06036
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. Evaluating large language models trained on code. arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Kyunghyun Cho, Bart van Merri \"e nboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using rnn encoder--decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pages 1724--1734
2014
-
[9]
Jacob K Christopher, Brian R Bartoldson, Tal Ben-Nun, Michael Cardei, Bhavya Kailkhura, and Ferdinando Fioretto. 2025. Speculative diffusion decoding: Accelerating language generation through diffusion. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies...
2025
-
[10]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Ferenc Husz \'a r. 2015. How (not) to train your generative model: Scheduled sampling, likelihood, adversary? arXiv preprint arXiv:1511.05101
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast inference from transformers via speculative decoding. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 19274--19286. PMLR
2023
- [15]
-
[16]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024 a . https://doi.org/10.18653/v1/2024.emnlp-main.422 EAGLE -2: Faster inference of language models with dynamic draft trees . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7421--7432. Association for Computational Linguistics
-
[17]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024 b . EAGLE : Speculative sampling requires rethinking feature uncertainty. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 28935--28948. PMLR
2024
-
[18]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2025 b . EAGLE -3: Scaling up inference acceleration of large language models via training-time test. In Advances in Neural Information Processing Systems
2025
- [19]
-
[20]
Mathematical Association of America . 2025. American invitational mathematics examination 2025. American Mathematics Competitions. AIME 2025 problems
2025
-
[21]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, and 1 others. 2023. Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification. arXiv preprint arXiv:2305.09781
-
[22]
Qwen Team . 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 others. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models. Https://crfm.stanford.edu/2023/03/13/alpaca.html
2023
- [25]
- [26]
-
[27]
Weilin Zhao, Tengyu Pan, Xu Han, Yudi Zhang, Sun Ao, Yuxiang Huang, Kaihuo Zhang, Weilun Zhao, Yuxuan Li, Jie Zhou, and 1 others. 2025. Fr-spec: Accelerating large-vocabulary language models via frequency-ranked speculative sampling. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3...
2025
-
[28]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing Systems
2023
-
[29]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[30]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.