ActTraitBench: Quantifying the Knowledge-Decision Gap in Large Language Models via Human-Grounded Behavioral Validation
Pith reviewed 2026-06-29 08:06 UTC · model grok-4.3
The pith
Large language models exhibit a pervasive knowledge-decision gap in personality traits, with larger models showing greater behavioral divergence despite consistent self-reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
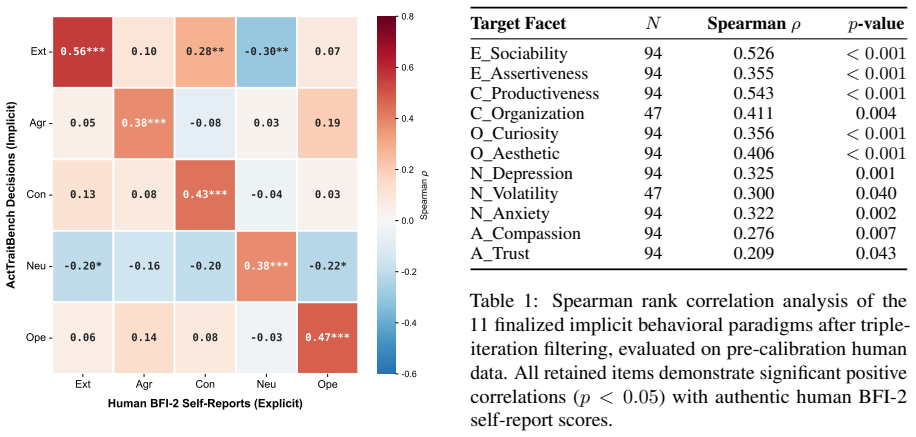
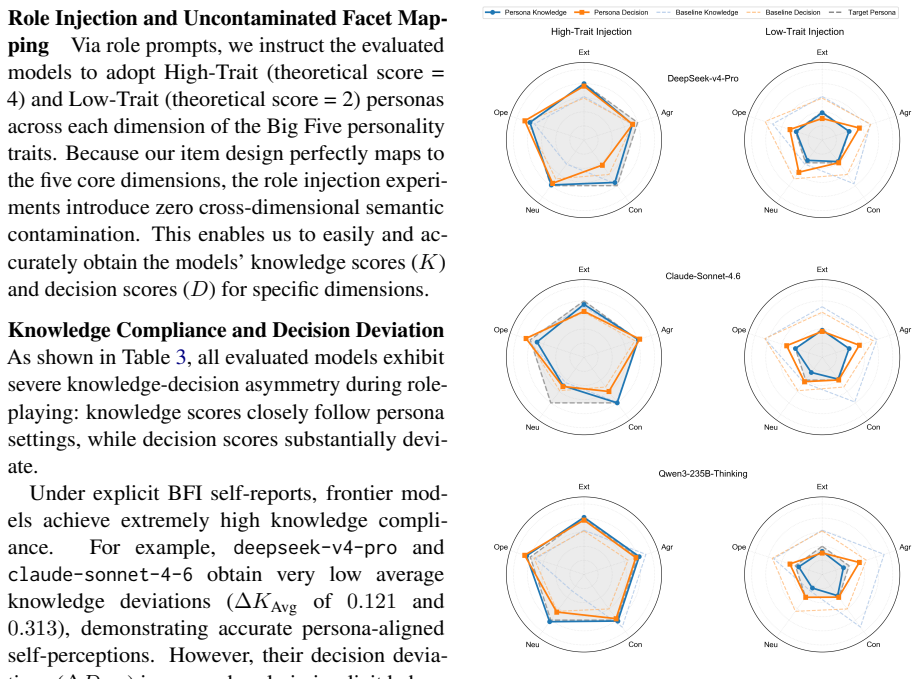
ActTraitBench reveals a knowledge-decision asymmetry (G_KD) in LLMs: models produce highly consistent self-reports on personality facets yet diverge substantially when making implicit behavioral decisions in the mapped paradigms. The framework establishes direct facet-to-paradigm mappings from human psychometric data and uses Distributional Calibration via Quantile Mapping to align score distributions with human baselines. Larger and more capable models exhibit stronger behavioral divergence. Chain of Cognitive Alignment reduces the gap at inference time in frontier models while exposing limits in smaller architectures.
What carries the argument
ActTraitBench framework, which creates one-to-one mappings between psychometric facets and behavioral paradigms from human data, plus Distributional Calibration via Quantile Mapping to align LLM outputs with human norms; supplemented by Chain of Cognitive Alignment inference intervention.
If this is right
- Self-report consistency alone is insufficient to certify personality trait stability in LLMs.
- The knowledge-decision gap widens rather than narrows as model size and capability increase.
- Human-grounded distributional calibration is required to produce valid comparisons between LLM and human personality measures.
- Chain of Cognitive Alignment narrows the gap in reasoning-capable models but cannot overcome capability limits in smaller models.
Where Pith is reading between the lines
- The observed scaling trend suggests that future model improvements may require explicit mechanisms to enforce consistency between stated knowledge and action rather than relying on scale alone.
- ActTraitBench-style human-grounded calibration could be extended to other consistency domains such as factual recall versus reasoning or stated values versus policy choices.
- If the gap reflects a general knowledge-action dissociation, then deployment of LLMs in roles requiring stable persona simulation may need ongoing behavioral monitoring beyond self-report checks.
Load-bearing premise
The one-to-one mappings between psychometric facets and behavioral paradigms, derived from human data, accurately capture the intended personality consistency construct when applied to LLM outputs.
What would settle it
Re-running the behavioral paradigms on a fresh human participant sample and finding no reliable correlation between the mapped decisions and the original psychometric facet scores would undermine the validity of the one-to-one mappings.
Figures


read the original abstract
While Large Language Models (LLMs) can convincingly simulate personas in explicit self-reports, they often deviate in implicit behavioral decisions, revealing a substantial Knowledge-Decision Gap ($G_{\text{KD}}$). Existing benchmarks struggle to measure this asymmetry due to limited construct validity, multi-dimensional entanglement, and distributional biases in LLM-based evaluation. To address these issues, we propose ActTraitBench, a human-grounded evaluation framework for measuring personality consistency in LLMs. Grounded in empirical human data, ActTraitBench establishes one-to-one mappings between psychometric facets and behavioral paradigms, and applies a Distributional Calibration via Quantile Mapping procedure to align LLM-judge score distributions with human norms. Experiments on 14 mainstream LLMs reveal a pervasive knowledge-decision asymmetry, where larger and more capable models often exhibit stronger behavioral divergence despite highly consistent self-reports. To mitigate this gap, we further introduce the Chain of Cognitive Alignment (CoCA), a plug-and-play inference-time intervention that improves alignment in reasoning-capable frontier models while exposing clear capability limitations in smaller architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActTraitBench, a human-grounded evaluation framework that establishes one-to-one mappings between psychometric facets and behavioral paradigms from empirical human data, applies Distributional Calibration via Quantile Mapping to align LLM score distributions with human norms, and quantifies a Knowledge-Decision Gap (G_KD) in personality consistency. Experiments across 14 mainstream LLMs report a pervasive asymmetry in which larger models exhibit stronger behavioral divergence despite consistent self-reports; the work also proposes the Chain of Cognitive Alignment (CoCA) inference-time intervention to reduce the gap in reasoning-capable models.
Significance. If the human-derived mappings preserve construct validity when applied to LLMs, the benchmark supplies a concrete, falsifiable method for measuring trait-behavior consistency that existing self-report or multi-dimensional evaluations lack. The reported inverse relationship between capability and consistency, together with the plug-and-play CoCA mitigation, would directly inform deployment decisions for persona-based applications and would supply a reproducible testbed for future alignment research.
major comments (3)
- [Benchmark construction and mapping procedure] The central claim of pervasive knowledge-decision asymmetry rests on the one-to-one mappings between psychometric facets and behavioral paradigms (derived from human data) remaining construct-valid for LLM outputs. The manuscript provides no validation—such as preserved inter-facet correlations, factor-structure replication, or differential item functioning analysis—on LLM-generated responses, leaving open the possibility that measured divergence arises from prompt sensitivity or surface pattern completion rather than the intended consistency mechanism.
- [Distributional Calibration via Quantile Mapping] The Distributional Calibration via Quantile Mapping aligns marginal score distributions to human norms but does not test whether the joint facet-paradigm relationships are preserved after calibration. If these relationships shift under LLM scoring, the quantified G_KD becomes an artifact of mismatched measurement rather than evidence of asymmetry; this step is load-bearing for all downstream claims about model size and divergence.
- [Experimental results on 14 LLMs] The abstract states that larger and more capable models exhibit stronger behavioral divergence, yet no table, figure, or section supplies the per-model G_KD values, statistical tests, or confidence intervals that would allow readers to assess whether the trend is driven by a few outliers or holds after controlling for prompt variation.
minor comments (3)
- [Abstract] The abstract supplies only high-level claims; the main text should include at minimum the number of behavioral paradigms, the exact human sample size used to derive the mappings, and the LLM judge prompt template.
- [Related work] Newly introduced terms G_KD and CoCA are used without an explicit comparison table against prior personality-consistency benchmarks in the NLP literature.
- [CoCA intervention] The description of CoCA as a 'plug-and-play' intervention would benefit from an ablation showing which components (chain-of-thought, cognitive alignment prompts, etc.) drive the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction and mapping procedure] The central claim of pervasive knowledge-decision asymmetry rests on the one-to-one mappings between psychometric facets and behavioral paradigms (derived from human data) remaining construct-valid for LLM outputs. The manuscript provides no validation—such as preserved inter-facet correlations, factor-structure replication, or differential item functioning analysis—on LLM-generated responses, leaving open the possibility that measured divergence arises from prompt sensitivity or surface pattern completion rather than the intended consistency mechanism.
Authors: We acknowledge the importance of demonstrating construct validity specifically for LLM outputs. The mappings were derived from human empirical data to ground the benchmark, but we agree that additional checks on LLM responses are needed to strengthen the interpretation of G_KD. In the revised manuscript, we will add analyses of inter-facet correlations and factor structure replication on LLM-generated responses, comparing them to human norms, along with discussion of differential item functioning where feasible. revision: yes
-
Referee: [Distributional Calibration via Quantile Mapping] The Distributional Calibration via Quantile Mapping aligns marginal score distributions to human norms but does not test whether the joint facet-paradigm relationships are preserved after calibration. If these relationships shift under LLM scoring, the quantified G_KD becomes an artifact of mismatched measurement rather than evidence of asymmetry; this step is load-bearing for all downstream claims about model size and divergence.
Authors: This is a substantive point about the calibration step. The quantile mapping procedure is designed to align marginal distributions, but we agree that verifying preservation of joint relationships is critical. We will include in the revision supplementary analyses reporting correlation matrices and other joint statistics before and after calibration for both human and LLM data to confirm that the G_KD quantification is not an artifact of the procedure. revision: yes
-
Referee: [Experimental results on 14 LLMs] The abstract states that larger and more capable models exhibit stronger behavioral divergence, yet no table, figure, or section supplies the per-model G_KD values, statistical tests, or confidence intervals that would allow readers to assess whether the trend is driven by a few outliers or holds after controlling for prompt variation.
Authors: We agree that explicit per-model reporting with statistical details would improve transparency and allow readers to evaluate the trend. In the revised manuscript, we will add a dedicated table presenting per-model G_KD values, associated statistical tests, and confidence intervals. We will also include robustness checks that control for prompt variation and ensure the trend visualization includes appropriate error bars. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation introduces ActTraitBench with mappings grounded in external empirical human data and applies quantile mapping solely for distributional alignment to human norms. The knowledge-decision gap G_KD is then measured as observed divergence between self-report consistency and behavioral paradigm scores. No equation, definition, or procedure reduces the quantified asymmetry to a self-referential input, fitted parameter renamed as prediction, or self-citation chain; the human data anchor remains independent of the LLM outputs being evaluated.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Empirical human data establishes valid one-to-one mappings between psychometric facets and behavioral paradigms for measuring personality consistency
invented entities (2)
-
Knowledge-Decision Gap (G_KD)
no independent evidence
-
Chain of Cognitive Alignment (CoCA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeek-AI
Personality testing of large language models: limited temporal stability, but highlighted prosocial- ity.Royal Society Open Science, 11(10). DeepSeek-AI. 2026. Deepseek-v4: Towards highly ef- ficient million-token context intelligence. Technical report, DeepSeek. Ravi Dhar, Stephen M Nowlis, and Steven J Sherman
2026
-
[2]
Trying hard or hardly trying: An analysis of context effects in choice.Journal of Consumer Psychology, 9(4):189–200. Ed Diener and Mark Wallbom. 1976. Effects of self- awareness on antinormative behavior.Journal of Research in Personality, 10:107–111. Shelley Duval and Robert A Wicklund. 1972. A theory of objective self awareness. Kfir Eliaz and Andrew Sc...
-
[3]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
Principles of topological psychology. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
-
[4]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Marilù Miotto, Nicola Rossberg, and Bennett Kleinberg
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Who is gpt-3? an exploration of personal- ity, values and demographics. InProceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+ CSS), pages 218–227. Max Pellert, Clemens M Lechner, Claudia Wagner, Beatrice Rammstedt, and Markus Strohmaier. 2024. Ai psychometrics: Assessing the psychological pro- files of l...
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. A Iterative Testing Standards Due to the three-stage optimization of the behav- ioral tasks, participants encountered different ver- sions of the questions. To ensure the reliability of our empirical validity, we strictly included only data from participants who completed the "Final Version" of a spe...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.