Nine Judges, Two Effective Votes: Correlated Errors Undermine LLM Evaluation Panels
Pith reviewed 2026-06-29 07:59 UTC · model grok-4.3
The pith
Nine frontier LLMs acting as judges supply only about two independent votes due to shared errors on the same items.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
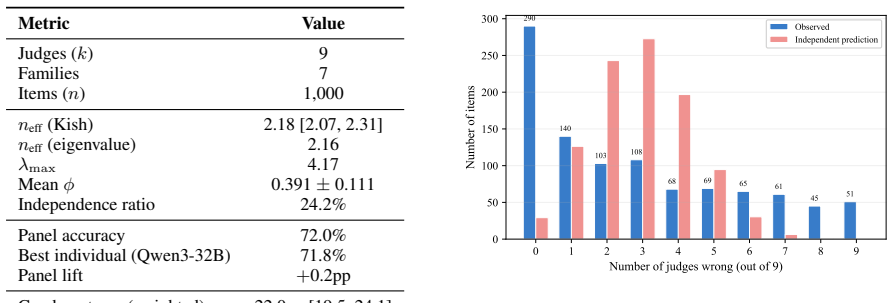
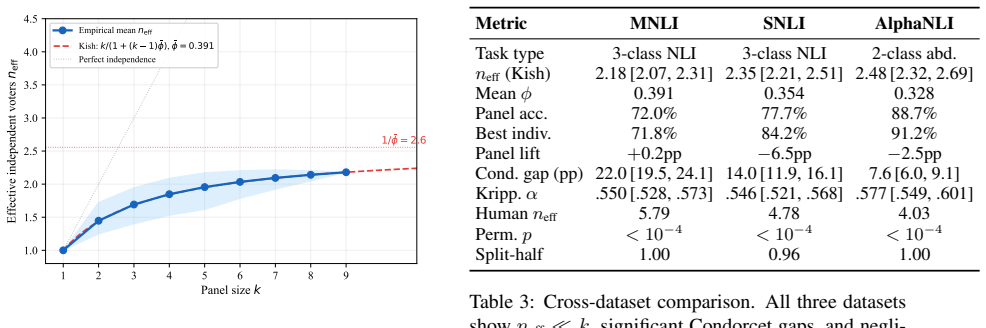
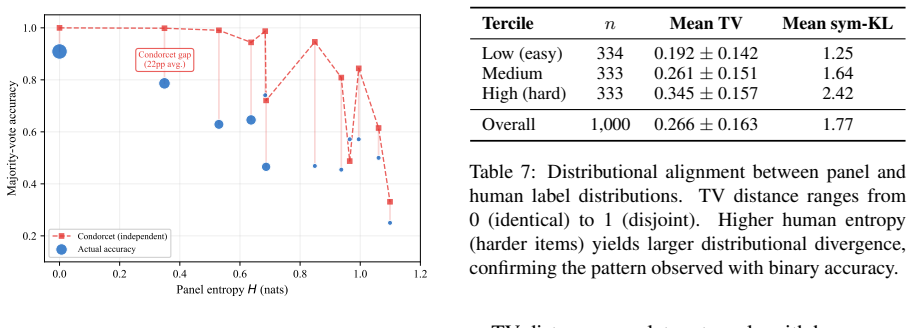
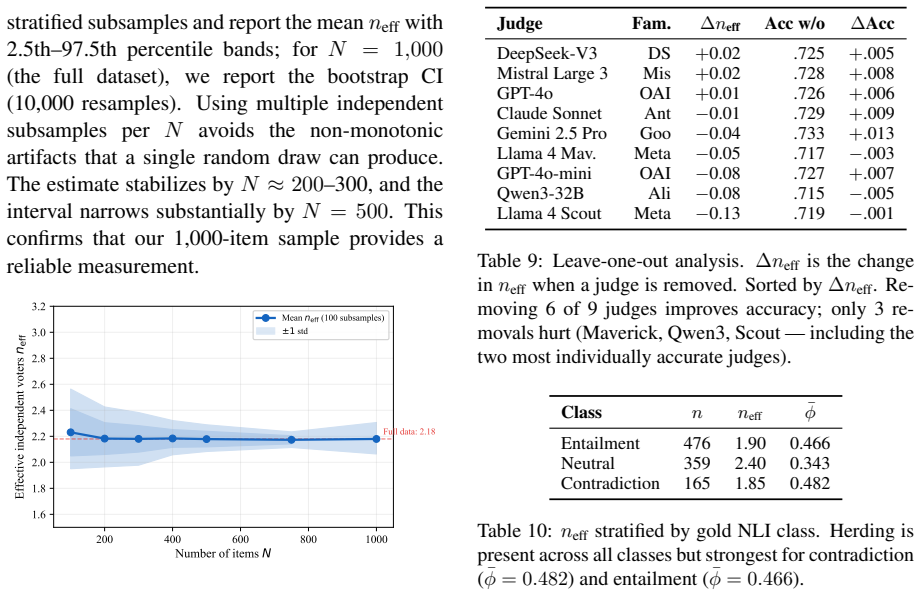
Testing a panel of nine frontier LLMs from seven model families on three natural language inference datasets, each with 100 human annotations per item, shows that the judges effectively provide only about two independent votes' worth of information. Roughly three-quarters of the panel's nominal independence is lost because the models make the same mistakes on the same items. The panel's actual accuracy falls 8-22 percentage points short of what independent voting would achieve, the best single judge matches or outperforms the full panel, and neither adding more judges nor using smarter aggregation algorithms closes more than 11 percent of the gap.
What carries the argument
Kish effective sample size (n_eff) paired with a Condorcet null model, which quantifies how much real informational value the panel supplies once observed error correlations are taken into account.
If this is right
- The panel's accuracy is 8-22 percentage points below the independent-voting ideal.
- The best single judge matches or outperforms the full panel across all tested conditions.
- Adding more judges or changing the aggregation method closes at most 11 percent of the performance gap.
- The bottleneck remains correlated judges rather than the choice of voting algorithm.
- Scaling the number of judges cannot substitute for genuinely independent evaluation sources.
Where Pith is reading between the lines
- Evaluation protocols may need to select or train models for complementary error patterns rather than simply increasing panel size.
- The same correlation issue could limit reliability in other multi-model setups such as reward models or debate systems.
- A direct test would be to measure n_eff on panels deliberately trained or prompted to disagree on hard cases.
Load-bearing premise
The human annotations of 100 per item on each dataset constitute reliable ground truth for measuring judge errors and their pairwise correlations.
What would settle it
Finding an effective sample size near nine or panel accuracy matching the independent-voting prediction on new datasets or tasks would falsify the claim that correlated errors dominate.
Figures

read the original abstract
LLM-as-a-judge panels aggregate votes from multiple models, with the expectation that diverse models yield more reliable evaluations. We develop a framework to measure the true informational value of such panels and quantify how far their reliability falls short of the independent-voting ideal. Testing a panel of 9 frontier LLMs from 7 model families on three natural language inference datasets (each with 100 human annotations per item), we find that the 9 judges effectively provide only about 2 independent votes' worth of information. Roughly three-quarters of the panel's nominal independence is lost because the models make the same mistakes on the same items. The consequences are stark: the panel's actual accuracy falls 8-22 percentage points short of what independent voting would achieve, and the best single judge matches or outperforms the full panel across all conditions. Neither adding more judges nor using smarter aggregation algorithms helps -- established methods close at most 11% of this gap, even with access to the correct answers. We quantify these findings using the Kish effective sample size (n_eff) and a Condorcet null model, and show the deficit is robust across prompt variants, temperatures, chain-of-thought reasoning, and a pairwise preference task (RewardBench). The bottleneck is correlated judges, not the aggregation algorithm, implying that scaling up panels cannot substitute for genuinely independent evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that panels of 9 frontier LLMs as judges on three NLI datasets (each with 100 human annotations per item) yield only ~2 effective independent votes due to high pairwise error correlations, losing ~75% of nominal independence. This results in panel accuracy 8-22pp below the Condorcet independent-voting baseline; single judges match or exceed the panel; neither more judges nor standard aggregation closes the gap. The deficit is quantified via Kish n_eff and a Condorcet null model and shown robust to prompt variants, temperature, CoT, and RewardBench.
Significance. If the central result holds, the work has clear practical significance for LLM evaluation: it demonstrates that simply scaling judge panels cannot substitute for model diversity and provides a concrete metric (n_eff) plus falsifiable comparison to an independent baseline. Strengths include the use of 100 annotations per item across three datasets, explicit robustness checks, and zero free parameters in the n_eff derivation.
major comments (2)
- [Abstract / testing setup] Abstract / testing setup: The computation of per-judge error rates, pairwise error correlations, and the resulting n_eff ≈ 2 relies on treating the majority vote over 100 human annotations as error-free ground truth. No inter-annotator agreement statistics, expert re-labeling of a subset, or sensitivity analysis under plausible human error rates (e.g., 5-10%) are reported; non-negligible label noise would systematically inflate observed correlations and widen the reported 8-22pp accuracy gap.
- [Methods] Methods (Kish n_eff and Condorcet baseline): The claim that the panel supplies only two effective votes is obtained directly from the observed error-correlation matrix via the standard Kish formula; however, the paper does not state the exact exclusion rules for items where human majority is tied or low-confidence, nor does it report the raw correlation matrix or per-dataset n_eff values, making it impossible to verify that the three-quarters independence loss is not an artifact of data filtering.
minor comments (1)
- [Abstract] The abstract states results are robust across RewardBench but does not specify whether the same 100-annotation protocol was used or whether only pairwise preference accuracy was measured.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and agree that clarifications and additional analyses are warranted.
read point-by-point responses
-
Referee: [Abstract / testing setup] Abstract / testing setup: The computation of per-judge error rates, pairwise error correlations, and the resulting n_eff ≈ 2 relies on treating the majority vote over 100 human annotations as error-free ground truth. No inter-annotator agreement statistics, expert re-labeling of a subset, or sensitivity analysis under plausible human error rates (e.g., 5-10%) are reported; non-negligible label noise would systematically inflate observed correlations and widen the reported 8-22pp accuracy gap.
Authors: We agree that the manuscript does not report inter-annotator agreement statistics or include a sensitivity analysis to human label noise. Although 100 annotations per item make the majority vote robust under typical agreement levels, the absence of these checks is a genuine gap. In revision we will add inter-annotator agreement figures from the source datasets and a sensitivity analysis that injects 5-10% label flips into the human majorities to quantify effects on pairwise correlations and n_eff. This will be added to the methods and results sections. revision: yes
-
Referee: [Methods] Methods (Kish n_eff and Condorcet baseline): The claim that the panel supplies only two effective votes is obtained directly from the observed error-correlation matrix via the standard Kish formula; however, the paper does not state the exact exclusion rules for items where human majority is tied or low-confidence, nor does it report the raw correlation matrix or per-dataset n_eff values, making it impossible to verify that the three-quarters independence loss is not an artifact of data filtering.
Authors: The referee is correct that the manuscript omits the precise exclusion rules for tied or low-confidence human majorities and does not provide the raw correlation matrices or per-dataset n_eff values. These details are required for full reproducibility. We will revise the methods section to state the exclusion criteria explicitly (e.g., majority agreement threshold), move the full pairwise correlation matrices to an appendix, and report n_eff separately for each of the three datasets. These additions will allow direct verification that the reported loss of independence is not driven by filtering choices. revision: yes
Circularity Check
No significant circularity; empirical application of standard formulas
full rationale
The paper computes judge error rates and pairwise correlations by comparing LLM outputs against aggregated human labels (treated as ground truth), then plugs the observed correlations into the standard Kish n_eff formula and contrasts against a Condorcet independent-voting baseline. This is a direct measurement followed by application of an external statistical formula, with no self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The assumption that human annotations are error-free is a methodological choice affecting external validity, but it does not reduce any equation or claim to its own inputs by construction. The derivation chain remains self-contained against the described datasets and formulas.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Kish effective sample size formula accurately quantifies the informational value of correlated binary votes.
- domain assumption The Condorcet null model supplies the correct baseline for fully independent voting accuracy.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
David Austen-Smith and Jeffrey S. Banks. 1996. Information aggregation, rationality, and the Condorcet jury theorem. American Political Science Review, 90(1):34--45
1996
-
[4]
Chandra Bhagavatula, Ronan Le Bras, Chaitanya Malaviya, Keisuke Sakaguchi, Ari Holtzman, Hannah Rashkin, Doug Downey, Scott Wen-tau Yih, and Yejin Choi. 2020. Abductive commonsense reasoning. In Proceedings of the International Conference on Learning Representations (ICLR)
2020
-
[5]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 632--642
2015
-
[6]
Christopher S Bretherton, Martin Widmann, Viktor P Dymnikov, John M Wallace, and Ileana Blad \'e . 1999. The effective number of spatial degrees of freedom of a time-varying field. Journal of Climate, 12(7):1990--2009
1999
-
[7]
Nitay Calderon, Roi Reichart, and Rotem Dror. 2025. The alternative annotator test for LLM -as-a-judge: How to statistically justify replacing human annotators with LLMs . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), pages 16051--16081
2025
-
[8]
Khaoula Chehbouni, Mohammed Haddou, Jackie Chi Kit Cheung, and Golnoosh Farnadi. 2025. Neither valid nor reliable? investigating the use of LLMs as judges. In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[9]
A. P. Dawid and A. M. Skene. 1979. Maximum likelihood estimation of observer error-rates using the EM algorithm. Journal of the Royal Statistical Society: Series C (Applied Statistics), 28(1):20--28
1979
-
[10]
Marquis de Condorcet. 1785. Essai sur l'application de l'analyse \` a la probabilit\' e des d\' e cisions rendues \` a la pluralit\' e des voix . Imprimerie Royale, Paris
-
[11]
Dietterich
Thomas G. Dietterich. 2000. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems (MCS), pages 1--15. Springer
2000
-
[12]
Dorner, Vivian Yvonne Nastl, and Moritz Hardt
Florian E. Dorner, Vivian Yvonne Nastl, and Moritz Hardt. 2025. Limits to scalable evaluation at the frontier: LLM as judge won't beat twice the data. In International Conference on Learning Representations (ICLR). Oral presentation
2025
-
[13]
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, Alon Albalak, and Yejin Choi. 2025. Artificial hivemind: The open-ended homogeneity of language models (and beyond). In Advances in Neural Information Processing Systems (NeurIPS). Best Paper Award
2025
-
[14]
Jaehun Jung, Faeze Brahman, and Yejin Choi. 2025. Trust or escalate: LLM judges with provable guarantees for human agreement. In International Conference on Learning Representations (ICLR)
2025
-
[15]
Elliot Kim, Avi Garg, Kenny Peng, and Nikhil Garg. 2025. Correlated errors in large language models. In International Conference on Machine Learning (ICML)
2025
-
[16]
Leslie Kish. 1965. Survey Sampling. John Wiley & Sons, New York
1965
-
[17]
Klaus Krippendorff. 2011. https://repository.upenn.edu/entities/publication/034a6030-c584-4d14-9d3d-7b7e8d16df20 Computing Krippendorff 's alpha-reliability . Departmental Papers (ASC), University of Pennsylvania
2011
-
[18]
Smith, and Hannaneh Hajishirzi
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. 2025. RewardBench : Evaluating reward models for language modeling. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 1755--1797
2025
-
[19]
Noah Lee, Na Min An, and James Thorne. 2023. Can large language models capture dissenting human voices? In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4569--4585
2023
- [20]
-
[21]
Felipe Maia Polo, Xinhe Wang, Mikhail Yurochkin, Gongjun Xu, Moulinath Banerjee, and Yuekai Sun. 2025. Bridging human and LLM judgments: Understanding and narrowing the gap. In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[22]
RewardBench 2: Advancing Reward Model Evaluation
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A. Smith, Hannaneh Hajishirzi, and Nathan Lambert. 2025. Rewardbench 2: Advancing reward model evaluation. arXiv preprint arXiv:2506.01937
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Jingwei Ni, Yu Fan, Vil\' e m Zouhar, Donya Rooein, Alexander Miserlis Hoyle, Mrinmaya Sachan, Markus Leippold, Dirk Hovy, and Elliott Ash. 2026. Can reasoning help large language models capture human annotator disagreement? In Proceedings of the 2026 Conference of the European Chapter of the Association for Computational Linguistics (EACL)
2026
-
[24]
Yixin Nie, Xiang Zhou, and Mohit Bansal. 2020. What can we learn from collective human opinions on natural language inference data? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9131--9143
2020
-
[25]
Ellie Pavlick and Tom Kwiatkowski. 2019. Inherent disagreements in human textual inferences. Transactions of the Association for Computational Linguistics, 7:677--694
2019
-
[26]
Barbara Plank. 2022. The ``problem'' of human label variation: On ground truth in data, modeling and evaluation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2022
-
[27]
Raykar, Shipeng Yu, Linda H
Vikas C. Raykar, Shipeng Yu, Linda H. Zhao, Gerardo Hermosillo Valadez, Charles Florin, Luca Bogoni, and Linda Moy. 2010. Learning from crowds. Journal of Machine Learning Research, 11:1297--1322
2010
-
[28]
James Surowiecki. 2004. The Wisdom of Crowds. Doubleday, New York
2004
-
[29]
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. 2025. Judging the judges: Evaluating alignment and vulnerabilities in LLMs -as-judges. In Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM), pages 404--430
2025
- [30]
-
[31]
Pat Verga, Sebastian Hofst \"a tter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. 2024. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models. arXiv preprint arXiv:2404.18796
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. 2024. Large language models are not fair evaluators. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 9440--9450
2024
-
[33]
Adina Williams, Nikita Nangia, and Samuel R. Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 1112--1122
2018
-
[34]
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V Chawla, and Xiangliang Zhang. 2025. Justice or prejudice? quantifying biases in LLM -as-a-judge. In International Conference on Learning Representations (ICLR)
2025
-
[35]
Jitian Zhao, Changho Shin, Tzu-Heng Huang, Satya Sai Srinath Namburi, and Frederic Sala. 2025. From many voices to one: A statistically principled aggregation of LLM judges. In NeurIPS 2025 Workshop on Reliable ML from Unreliable Data
2025
-
[36]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM -as-a-judge with MT-Bench and Chatbot Arena . In Advances in Neural Information Processing Systems (NeurIPS)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.