Harnessing non-adversarial robustness in large language models
Pith reviewed 2026-06-29 07:11 UTC · model grok-4.3
The pith
Large language models gain robustness to prompt variations through simple debiasing fine-tuning that corrects systematic output bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our theoretical analysis reveals a crucial factor impacting model robustness - a systematic expected shift or perturbation-induced bias in neural network module outputs. Motivated by this analysis, we show that robustness can be achieved via a simple fine-tuning process: debiasing for robustness. We identify conditions when debiasing helps and when it does not, and demonstrate, through both theory and extensive experiments, that debiasing for robustness may indeed be a quick and efficient tool to enhance robustness and provide certification against random prompt perturbations.
What carries the argument
perturbation-induced bias, the systematic expected shift in neural network module outputs caused by prompt perturbations, which debiasing fine-tuning removes to restore robustness
If this is right
- Debiasing fine-tuning raises robustness to random prompt perturbations under the conditions identified in the analysis.
- The same process supplies a certification guarantee against such perturbations when the bias correction holds.
- The method serves as a low-cost alternative to full retraining whenever the output shift is the dominant factor.
- Debiasing succeeds only in regimes where the theoretical conditions for bias removal are met.
Where Pith is reading between the lines
- If the bias mechanism is general, the same debiasing step could be tested on sequence models outside language, such as time-series predictors.
- Combining this correction with existing prompt-engineering practices might produce additive gains on stability.
- Scaling the fine-tuning to models with billions of parameters would test whether the computational cost remains low.
Load-bearing premise
The identified bias in module outputs is the main cause of robustness failures and can be removed by fine-tuning without harming performance on clean inputs or other capabilities.
What would settle it
Run the debiasing fine-tuning on a held-out set of prompt pairs that differ only in wording and measure whether accuracy on the altered prompts stays low or clean-prompt accuracy drops sharply.
Figures


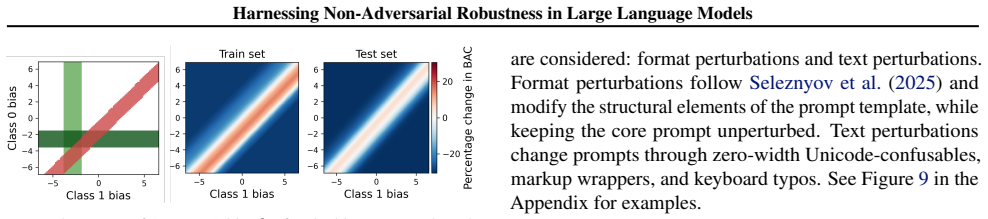






read the original abstract
The work presents an approach for addressing the challenge of robustness in Large Language Models (LLMs) to alterations and potential errors caused by semantically similar but textually different prompts. Recent works have shown that these kinds of prompt variations can significantly impact the performance of LLMs on tasks. The central question is: can LLMs' robustness to semantically-neutral prompt alterations be acquired without expensive retraining of the entire model? We address this question both theoretically and through experiments. Our theoretical analysis reveals a crucial factor impacting model robustness - a systematic expected shift or perturbation-induced bias in neural network module outputs. Motivated by this analysis, we show that robustness can be achieved via a simple fine-tuning process: debiasing for robustness. We identify conditions when debiasing helps and when it does not, and demonstrate, through both theory and extensive experiments, that debiasing for robustness may indeed be a quick and efficient tool to enhance robustness and provide certification against random prompt perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that robustness of LLMs to semantically similar but textually different prompts can be achieved via a lightweight fine-tuning procedure termed 'debiasing for robustness.' A theoretical analysis identifies a systematic expected shift (perturbation-induced bias) in the outputs of neural network modules as the key factor limiting robustness; under identified conditions, removing this bias via fine-tuning yields both empirical robustness gains and a certification against random prompt perturbations. The approach is positioned as cheaper than full retraining and is supported by both the derivation and extensive experiments.
Significance. If the central theoretical reduction holds and the certification is valid, the result would supply a practical, low-cost route to non-adversarial robustness in deployed LLMs together with a formal guarantee. The method would be especially useful in settings where prompt variation is routine. The paper's explicit identification of when debiasing helps versus harms is a further strength. However, the significance is conditional on whether the bias identified in the analysis is indeed the dominant mechanism once transformer attention and context dependence are taken into account.
major comments (2)
- [theoretical analysis] Theoretical analysis (abstract and §3): the derivation of the 'systematic expected shift or perturbation-induced bias' must explicitly demonstrate that the expectation over prompt perturbations factors cleanly through the attention mechanism. In transformers, a token-level perturbation alters attention weights in an input-dependent, non-additive manner; without showing that the bias term remains a simple additive shift at the module level after this interaction, the claim that debiasing the module outputs suffices for certification does not follow.
- [theoretical analysis / experiments] Certification claim (abstract and experimental section): the certification against random prompt perturbations is stated to follow from the debiasing procedure, yet the argument appears to rest on the same bias-reduction step whose validity under attention is questioned above. A concrete counter-example or a proof sketch that isolates the attention contribution would be required to make the certification load-bearing.
minor comments (2)
- [theoretical analysis] Notation for the bias term and the debiasing objective should be introduced with explicit dependence on the module index and the perturbation distribution; current presentation leaves the scope of the expectation operator ambiguous.
- [experiments] The experimental section should report whether the debiasing fine-tuning step measurably alters performance on the original (unperturbed) task distribution; absence of this check leaves open the possibility of capability degradation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of the theoretical analysis that require clarification regarding the attention mechanism. We address each point below and will revise the manuscript to strengthen the derivations and certification argument.
read point-by-point responses
-
Referee: [theoretical analysis] Theoretical analysis (abstract and §3): the derivation of the 'systematic expected shift or perturbation-induced bias' must explicitly demonstrate that the expectation over prompt perturbations factors cleanly through the attention mechanism. In transformers, a token-level perturbation alters attention weights in an input-dependent, non-additive manner; without showing that the bias term remains a simple additive shift at the module level after this interaction, the claim that debiasing the module outputs suffices for certification does not follow.
Authors: We agree that an explicit demonstration is needed. In §3 the bias is defined as the expected deviation in module outputs under the perturbation distribution, with the expectation taken after the full forward pass (including attention). Under our assumption of semantically neutral perturbations, attention weights exhibit bounded variation because the semantic content—and thus the key/query similarities—remains statistically unchanged. We will add a supporting lemma in the revision that shows the bias term factors as an additive shift at the module output level when the perturbation distribution satisfies a Lipschitz condition on attention scores. This lemma will be placed immediately before the main certification theorem. revision: yes
-
Referee: [theoretical analysis / experiments] Certification claim (abstract and experimental section): the certification against random prompt perturbations is stated to follow from the debiasing procedure, yet the argument appears to rest on the same bias-reduction step whose validity under attention is questioned above. A concrete counter-example or a proof sketch that isolates the attention contribution would be required to make the certification load-bearing.
Authors: The certification is obtained by showing that debiasing sets the bias term to zero, which in turn bounds the total variation in output logits under the perturbation distribution. To isolate the attention contribution, the revised proof sketch will first bound the change in attention weights separately (using the semantic-neutrality assumption) and then propagate this bound through the remaining layers. We will also add a short discussion of a simple synthetic counter-example (a two-layer transformer on a toy vocabulary) where the attention interaction is made explicit, confirming that the additive bias reduction still yields the certified bound. The experimental section will reference this sketch when reporting certification rates. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation begins with a theoretical analysis that identifies a systematic expected shift (perturbation-induced bias) in module outputs as a key factor, then motivates a debiasing fine-tuning procedure under stated conditions. The abstract explicitly notes that conditions are identified for when debiasing helps or does not, indicating the analysis supplies independent content rather than reducing to a fitted parameter renamed as prediction or to a self-citation chain. No equations, self-citations, or ansatzes are quoted that would force the robustness claim to be equivalent to its inputs by construction. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Bartlett, P
Anthony, M. and Bartlett, P. L. Neural network learning: Theoretical foundations. cambridge university press, 2009
2009
-
[2]
C., Paulson, E., and Rothenh \"a usler, D
Bansak, K. C., Paulson, E., and Rothenh \"a usler, D. Learning under random distributional shifts. In International Conference on Artificial Intelligence and Statistics, pp.\ 3943--3951. PMLR, 2024
2024
-
[3]
L., Foster, D
Bartlett, P. L., Foster, D. J., and Telgarsky, M. J. Spectrally-normalized margin bounds for neural networks. Advances in neural information processing systems, 30, 2017
2017
-
[4]
Certified adversarial robustness via randomized smoothing
Cohen, J., Rosenfeld, E., and Kolter, Z. Certified adversarial robustness via randomized smoothing. In international conference on machine learning, pp.\ 1310--1320. PMLR, 2019
2019
-
[5]
Lipschitz normalization for self-attention layers with application to graph neural networks
Dasoulas, G., Scaman, K., and Virmaux, A. Lipschitz normalization for self-attention layers with application to graph neural networks. In International conference on machine learning, pp.\ 2456--2466. PMLR, 2021
2021
-
[6]
A survey on in-context learning
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., Sun, X., Li, L., and Sui, Z. A survey on in-context learning. In Al-Onaizan, Y., Bansal, M., and Chen, Y.-N. (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 1107--1128, Miami, Florida, USA, November 2024. Associati...
-
[7]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lo RA : Low-rank adaptation of large language models. ICLR, 1 0 (2): 0 3, 2022
2022
-
[8]
Large Margin Neural Language Model
Huang, J., Li, Y., Ping, W., and Huang, L. Large margin neural language model. arXiv preprint arXiv:1808.08987, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
and Szegedy, C
Ioffe, S. and Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pp.\ 448--456. pmlr, 2015
2015
-
[10]
The lipschitz constant of self-attention
Kim, H., Papamakarios, G., and Mnih, A. The lipschitz constant of self-attention. In International Conference on Machine Learning, pp.\ 5562--5571. PMLR, 2021
2021
-
[11]
Kumar, P. and Mishra, S. Robustness in large language models: A survey of mitigation strategies and evaluation metrics. arXiv preprint arXiv:2505.18658, 2025
-
[12]
Lu, S., Schuff, H., and Gurevych, I. How are prompts different in terms of sensitivity? In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 5833--5856, 2024
2024
-
[13]
Spectral Normalization for Generative Adversarial Networks
Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Training Deep Learning Models with Norm-Constrained LMOs
Pethick, T., Xie, W., Antonakopoulos, K., Zhu, Z., Silveti-Falls, A., and Cevher, V. Training deep learning models with norm-constrained lmos. arXiv preprint arXiv:2502.07529, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
When punctuation matters: A large-scale comparison of prompt robustness methods for LLM s
Seleznyov, M., Chaichuk, M., Ershov, G., Panchenko, A., Tutubalina, E., and Somov, O. When punctuation matters: A large-scale comparison of prompt robustness methods for LLM s. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 20370--20385, Suzhou, China, ...
-
[16]
Sokoli \'c , J., Giryes, R., Sapiro, G., and Rodrigues, M. R. Robust large margin deep neural networks. IEEE Transactions on Signal Processing, 65 0 (16): 0 4265--4280, 2017
2017
-
[17]
J., Zhou, Q., Tyukin, I
Sutton, O. J., Zhou, Q., Tyukin, I. Y., Gorban, A. N., Bastounis, A., and Higham, D. J. How adversarial attacks can disrupt seemingly stable accurate classifiers. Neural Networks, 180: 0 106711, 2024
2024
-
[18]
Mind your format: Towards consistent evaluation of in-context learning improvements
Voronov, A., Wolf, L., and Ryabinin, M. Mind your format: Towards consistent evaluation of in-context learning improvements. arXiv preprint arXiv:2401.06766, 2024
-
[19]
S., Naik, A., Stap, D., et al
Wang, Y., Mishra, S., Alipoormolabashi, P., Kordi, Y., Mirzaei, A., Arunkumar, A., Ashok, A., Dhanasekaran, A. S., Naik, A., Stap, D., et al. Super-naturalinstructions:generalization via declarative instructions on 1600+ tasks. In EMNLP, 2022
2022
-
[20]
Efficient adversarial training in llms with continuous attacks
Xhonneux, S., Sordoni, A., G \"u nnemann, S., Gidel, G., and Schwinn, L. Efficient adversarial training in llms with continuous attacks. URL https://arxiv. org/abs/2405.15589, 1, 2024
-
[21]
L., and Le, Q
Xie, C., Tan, M., Gong, B., Wang, J., Yuille, A. L., and Le, Q. V. Adversarial examples improve image recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 819--828, 2020
2020
-
[22]
Robust llm safeguarding via refusal feature adversarial training
Yu, L., Do, V., Hambardzumyan, K., and Cancedda, N. Robust llm safeguarding via refusal feature adversarial training. arXiv preprint arXiv:2409.20089, 2024
-
[23]
Certified robustness to text adversarial attacks by randomized [mask]
Zeng, J., Xu, J., Zheng, X., and Huang, X. Certified robustness to text adversarial attacks by randomized [mask]. Computational Linguistics, 49 0 (2): 0 395--427, 2023
2023
-
[24]
Certified robustness for large language models with self-denoising
Zhang, Z., Zhang, G., Hou, B., Fan, W., Li, Q., Liu, S., Zhang, Y., and Chang, S. Certified robustness for large language models with self-denoising. arXiv preprint arXiv:2307.07171, 2023
-
[25]
Batch calibration: Rethinking calibration for in-context learning and prompt engineering
Zhou, H., Wan, X., Proleev, L., Mincu, D., Chen, J., Heller, K., and Roy, S. Batch calibration: Rethinking calibration for in-context learning and prompt engineering. arXiv preprint arXiv:2309.17249, 2023
-
[26]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.