Make LLM Learn to Synthesize from Streaming Experiences through Feedback
Pith reviewed 2026-06-29 07:38 UTC · model grok-4.3
The pith
LLMs improve synthetic data generation on new tasks by accumulating experience from feedback on earlier ones in sequence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SynLearner enables synthesis models to acquire reusable experience over a task stream by encouraging exploration of diverse synthesis patterns, learning from feedback, and balancing sample quality with set-level diversity, which produces consistent cross-task transferability and higher performance on later tasks.
What carries the argument
SynLearner, the framework that converts isolated synthesis tasks into an accumulating experience process by using feedback from historical tasks to guide future synthesis.
If this is right
- Synthesis quality on subsequent tasks rises when the model retains and applies patterns learned from earlier tasks.
- The same model exhibits transfer across different benchmarks rather than resetting its synthesis behavior for each new task.
- Treating data generation as an experience-driven sequence reduces the need to restart learning for every new synthesis request.
Where Pith is reading between the lines
- The same feedback loop could be applied to other sequential LLM tasks such as instruction following or tool use where past outcomes inform future outputs.
- Over many tasks the accumulated experience might allow smaller models to match the output quality of larger ones trained from scratch on each task.
Load-bearing premise
Feedback collected from past synthesis tasks supplies useful signals that improve performance on future tasks without causing interference or loss of earlier gains.
What would settle it
A controlled run of SynLearner on a sequence of synthesis tasks in which later-task quality metrics show no gain or a drop relative to an isolated-task baseline that receives no historical feedback.
Figures

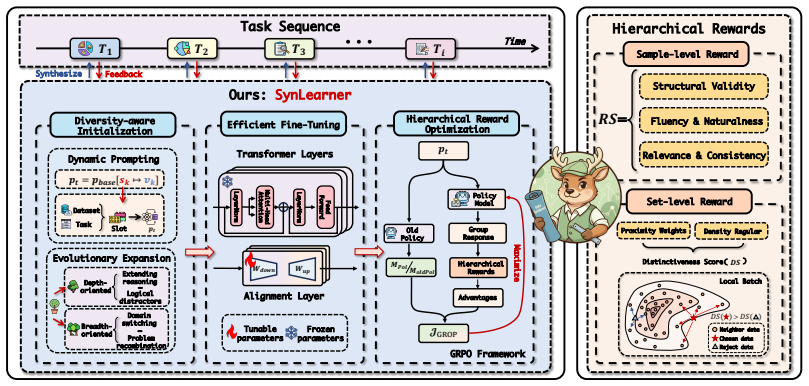
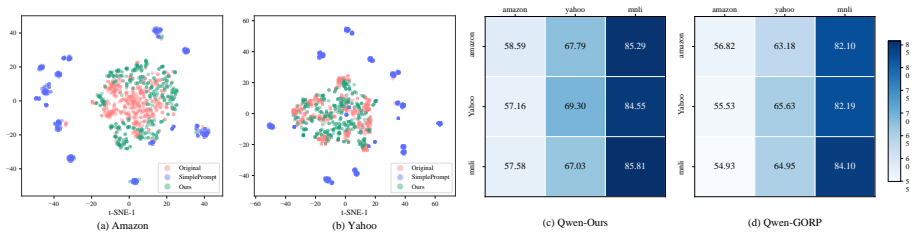
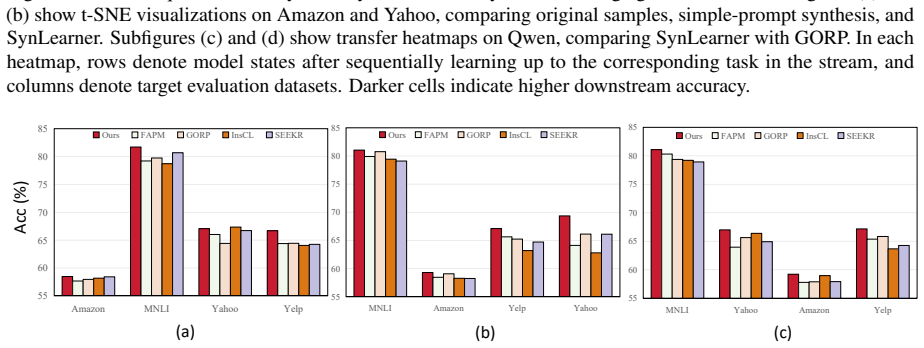
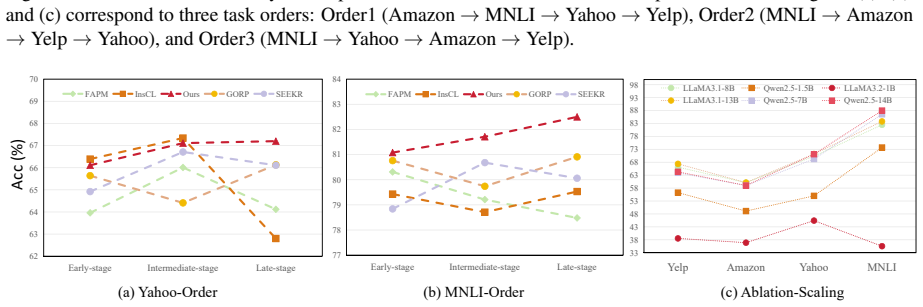
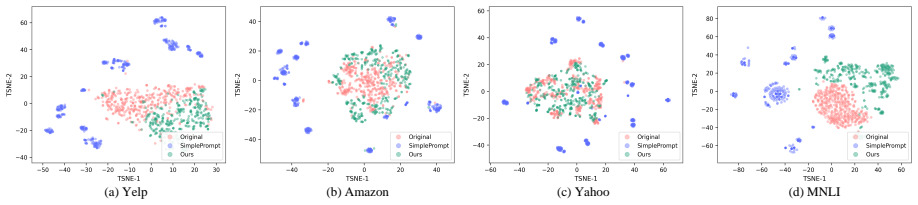
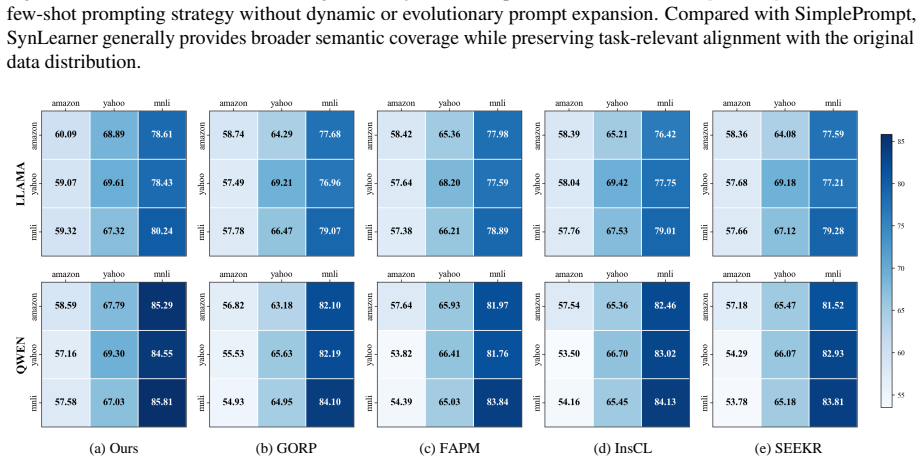
read the original abstract
Large language models (LLMs) have been widely adopted for synthetic data generation, significantly reducing annotation costs. However, most existing studies treat synthesis as a set of isolated tasks and overlook a more fundamental question: whether a model can learn to synthesize by accumulating experience from past tasks and transferring it to future ones. In this work, we introduce StreamSynth, a new setting in which synthesis tasks arrive sequentially and experience from historical tasks provides informative signals for future synthesis. To address this setting, we propose SynLearner, a general framework that enables synthesis models to acquire reusable synthesis experience over a task stream. Instead of generating data independently for each task, SynLearner encourages the model to explore diverse synthesis patterns, learn from feedback, and balance sample quality with set-level diversity as tasks evolve. Extensive experiments across multiple benchmarks show that SynLearner effectively leverages experience from earlier tasks to improve synthesis performance on later ones, exhibiting consistent cross-task transferability. These findings provide evidence for the feasibility of StreamSynth and highlight synthetic data generation as an experience-driven process that can benefit from task streams.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StreamSynth, a setting in which synthesis tasks arrive sequentially and historical experience provides signals for future tasks. It proposes SynLearner, a framework that encourages LLMs to explore diverse synthesis patterns, learn from feedback, and balance sample quality with set-level diversity across the task stream. The central empirical claim is that SynLearner produces consistent cross-task transferability, with performance on later tasks improving from experience accumulated on earlier ones, as demonstrated across multiple benchmarks.
Significance. If the experimental results hold under rigorous controls, the work would establish synthetic data generation as an experience-accumulating rather than isolated process. This could reduce annotation costs more effectively than current per-task approaches and open a new research direction on transfer in synthesis pipelines.
minor comments (3)
- [Abstract] Abstract: the phrase 'balance sample quality with set-level diversity' is introduced without a concrete definition or metric; a brief parenthetical or reference to the relevant section would improve clarity.
- [Abstract] The abstract states 'extensive experiments across multiple benchmarks' but does not name the benchmarks or report any aggregate statistics; adding these details would allow readers to assess the scope of the transferability claim.
- The manuscript would benefit from an explicit statement of the feedback signal (e.g., reward model, human preference, or automatic metric) used to update the synthesis policy between tasks.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We are encouraged by the view that the work could open a new direction on transfer in synthesis pipelines if the results hold under rigorous controls.
Circularity Check
No circularity: empirical framework validated externally by benchmark experiments
full rationale
The paper introduces StreamSynth as a sequential task setting and SynLearner as a practical framework for accumulating synthesis experience via feedback and diversity balancing. All load-bearing claims (cross-task transferability, performance gains on later tasks) are presented as outcomes of extensive experiments on multiple benchmarks rather than derived from equations or self-referential definitions. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central result is therefore falsifiable against external data and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
ZooClaw-FashionSigLIP2: Distilled Fine-tuning for Robust Fashion Retrieval
ZooClaw-FashionSigLIP2 applies distilled full fine-tuning plus WiseFT interpolation to SigLIP2-base and reports outperforming LoRA, larger backbones, and external data on fashion retrieval benchmarks while releasing a...
Reference graph
Works this paper leans on
-
[1]
Zhen Bi, Zhenlin Hu, Xueshu Chen, Mingyang Chen, Cheng Deng, Yida Xue, Zhen Wang, Qing Shen, Ningyu Zhang, and Jungang Lou. 2026. https://arxiv.org/abs/2509.24836 Logical structure as knowledge: Enhancing llm reasoning via structured logical knowledge density estimation . Preprint, arXiv:2509.24836
-
[2]
Younwoo Choi, Muhammad Adil Asif, Ziwen Han, John Willes, and Rahul Krishnan. 2025. https://openreview.net/forum?id=FS2nukC2jv Teaching LLM s how to learn with contextual fine-tuning . In The Thirteenth International Conference on Learning Representations
2025
-
[3]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
DeepSeek-AI. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning . Preprint, arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Ronen Eldan and Yuanzhi Li. 2023. https://arxiv.org/abs/2305.07759 Tinystories: How small can language models be and still speak coherent english? Preprint, arXiv:2305.07759
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, and Abhinav Jauhri et al. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Jinghan He, Haiyun Guo, and Kuan et al. Zhu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.190 SEEKR : Selective attention-guided knowledge retention for continual learning of large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 3254--3266, Miami, Florida, USA. Association for Computa...
-
[9]
Linda He, Jue WANG, Maurice Weber, Shang Zhu, Ben Athiwaratkun, and Ce Zhang. 2025. https://openreview.net/forum?id=BkwCrIsTbR Scaling instruction-tuned LLM s to million-token contexts via hierarchical synthetic data generation . In The Thirteenth International Conference on Learning Representations
2025
-
[10]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://openreview.net/forum?id=7Bywt2mQsCe Measuring mathematical problem solving with the MATH dataset . In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
2021
-
[11]
Zhenlin Hu, Zhizhi Peng, Zhen Bi, Qing Shen, Zhenfang Liu, Jungang Lou, and Xin Luo. 2025. https://doi.org/10.1109/JAS.2025.125540 Advancing healthcare with large language models: Techniques and application . IEEE/CAA Journal of Automatica Sinica, 12(12):2371--2398
-
[12]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025 a . https://doi.org/10.1145/3703155 A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions . ACM Transactions on Information Systems, 43(2)
-
[13]
Wei Huang, Anda Cheng, Zhao Zhang, Yinggui Wang, Lei Wang, Shoumeng Yan, and Tao Wei. 2025 b . https://openreview.net/forum?id=fHvh913U1H Mitigating catastrophic forgetting in large language models with forgetting-aware pruning
2025
-
[14]
Yuan Liang, Ruobin Zhong, Haoming Xu, Chen Jiang, Yi Zhong, Runnan Fang, Jia-Chen Gu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Xin Xu, Tongtong Wu, Kun Wang, Yang Liu, Zhen Bi, Jungang Lou, Yuchen Eleanor Jiang, Hangcheng Zhu, and 30 others. 2026. https://arxiv.org/abs/2603.04448 Skillnet: Create, evaluate, and connect ai skills . Preprint, arX...
-
[15]
Gouki Minegishi, Hiroki Furuta, Shohei Taniguchi, Yusuke Iwasawa, and Yutaka Matsuo. 2025. https://openreview.net/forum?id=Xw01vF13aV Beyond induction heads: In-context meta learning induces multi-phase circuit emergence . In Forty-second International Conference on Machine Learning
2025
-
[16]
OpenAI. 2024. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. 2024. https://openreview.net/forum?id=L4nOxziGf9 Rephrase, augment, reason: Visual grounding of questions for vision-language models . In The Twelfth International Conference on Learning Representations
2024
-
[18]
Qwen, :, and An Yang et al. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
-
[20]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. 2025. https://doi.org/10.1145/3735633 Continual learning of large language models: A comprehensive survey . ACM Comput. Surv., 58(5)
-
[21]
Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He. 2024. http://papers.nips.cc/paper\_files/paper/2024/hash/0ef1afa0daa888d695dcd5e9513bafa3-Abstract-Conference.html Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving . In Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information P...
2024
-
[22]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. https://doi.org/10.18653/v1/W18-5446 GLUE : A multi-task benchmark and analysis platform for natural language understanding . In Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pages 353--355, Brussels, Be...
-
[23]
Chenxu Wang, Yilin Lyu, Zicheng Sun, and Liping Jing. 2025 a . https://doi.org/10.18653/v1/2025.acl-long.721 Continual gradient low-rank projection fine-tuning for LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14815--14829, Vienna, Austria. Association for Computational Li...
- [24]
-
[25]
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. 2024 a . https://doi.org/10.1109/TPAMI.2024.3367329 A comprehensive survey of continual learning: Theory, method and application . IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362--5383
-
[26]
Maolin Wang, Xiangyu Zhao, Ruocheng Guo, and Junhui Wang. 2025 c . https://doi.org/10.1109/ICDE65448.2025.00376 Metalora: Tensor-enhanced adaptive low-rank fine-tuning . In 2025 IEEE 41st International Conference on Data Engineering (ICDE), pages 4680--4684
-
[27]
Xingjin Wang, Howe Tissue, Lu Wang, Linjing Li, and Daniel Dajun Zeng. 2025 d . https://openreview.net/forum?id=Vk1rNMl0J1 Learning dynamics in continual pre-training for large language models . In Forty-second International Conference on Machine Learning
2025
-
[28]
Yifan Wang, Yafei Liu, Chufan Shi, and 1 others. 2024 b . https://doi.org/10.18653/v1/2024.naacl-long.37 I ns CL : A data-efficient continual learning paradigm for fine-tuning large language models with instructions . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno...
-
[29]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.acl-long.754 Self-instruct: Aligning language models with self-generated instructions . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
- [30]
-
[31]
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. 2024. https://openreview.net/forum?id=CfXh93NDgH Wizard LM : Empowering large pre-trained language models to follow complex instructions . In The Twelfth International Conference on Learning Representations
2024
-
[32]
Siqiao Xue, Zihan Liao, Jin Qin, Ziyin Zhang, Yixiang Mu, Fan Zhou, and Hang Yu. 2026 a . https://arxiv.org/abs/2605.04615 Beyond retrieval: A multitask benchmark and model for code search . arXiv preprint arXiv:2605.04615
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [33]
- [34]
- [35]
-
[36]
Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2024. https://openreview.net/forum?id=N8N0hgNDRt Metamath: Bootstrap your own mathematical questions for large language models . In The Twelfth International Conference on Learning Representations
2024
- [37]
-
[38]
Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang
Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander J. Ratner, Ranjay Krishna, Jiaming Shen, and Chao Zhang. 2023 b . http://papers.nips.cc/paper\_files/paper/2023/hash/ae9500c4f5607caf2eff033c67daa9d7-Abstract-Datasets\_and\_Benchmarks.html Large language model as attributed training data generator: A tale of diversity and bias . In Advances in Neural...
2023
-
[39]
Weihao Zeng, Can Xu, Yingxiu Zhao, Jian-Guang Lou, and Weizhu Chen. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.397 Automatic instruction evolving for large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6998--7018, Miami, Florida, USA. Association for Computational Linguistics
- [40]
-
[41]
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. 2015. http://papers.nips.cc/paper/5782-character-level-convolutional-networks-for-text-classification Character-level convolutional networks for text classification . In NIPS, pages 649--657
2015
-
[42]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[43]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.