Uncertainty Quantification for Multimodal Retrieval Augmented Generation
Pith reviewed 2026-06-29 05:19 UTC · model grok-4.3
The pith
LeMUQ quantifies uncertainty in multimodal RAG by feeding token probabilities from modality and context removals into a finetuned model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LeMUQ improves uncertainty estimation in multimodal RAG by analyzing token-level probabilities under controlled input ablations that remove visual information, retrieved passages, or both, then training a lightweight model on these probability sequences to predict answer correctness.
What carries the argument
LeMUQ encodes probability sequences obtained after modality or context removal as probability tokens and passes them through a finetuned model that learns to combine multimodal and retrieval-aware uncertainty signals.
If this is right
- LeMUQ yields consistent AUROC gains over both non-learned and finetuned uncertainty baselines across evaluated datasets and retrievers.
- The method generalizes reliably when the retriever or dataset changes but shows mixed results when the underlying vision-language model is swapped.
- The approach isolates uncertainty contributions from visual understanding, retrieval quality, and generation by design.
- The resulting uncertainty scores can be used to decide whether to trust or reject a generated answer in multimodal RAG pipelines.
Where Pith is reading between the lines
- The ablation-based signals may also help diagnose which stage of the RAG pipeline is most responsible for an error on any given query.
- Similar probability-token encodings could be applied to non-RAG multimodal tasks such as visual captioning or document understanding.
- Combining LeMUQ signals with calibration techniques that operate on the final answer distribution might further tighten the uncertainty estimates.
Load-bearing premise
Signals from simply removing modalities or retrieved context are sufficient to expose the uncertainty interactions that matter, and a model trained on those signals will generalize to new retrieval setups and vision-language models.
What would settle it
A test on a previously unseen vision-language model or retrieval corpus where LeMUQ produces no AUROC improvement over a strong baseline that uses only the original token probabilities.
Figures

read the original abstract
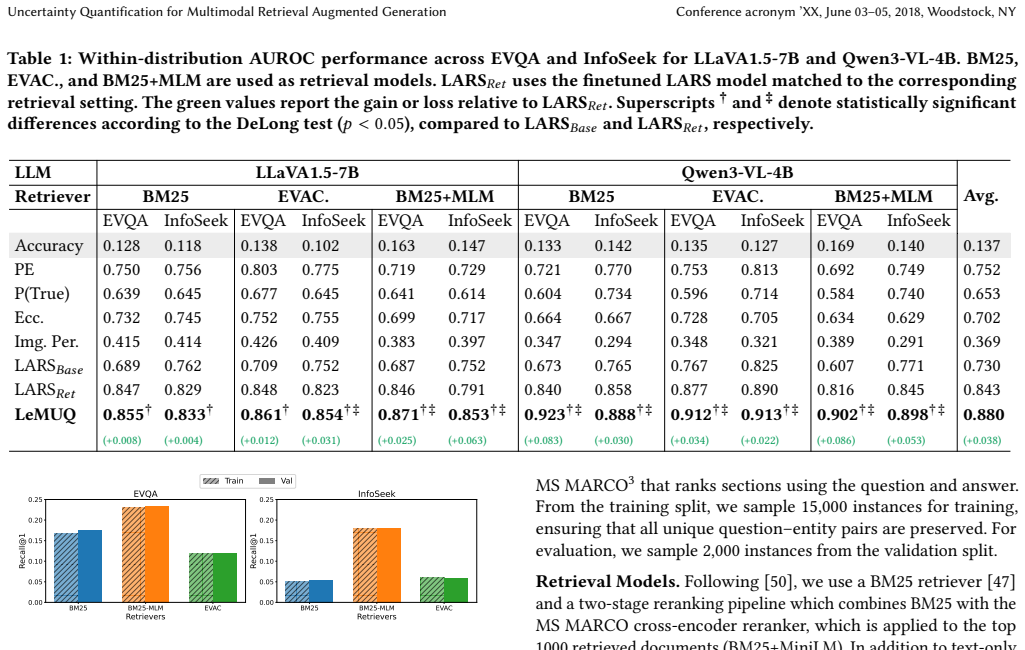
Retrieval Augmented Generation (RAG) improves the question answering capabilities of Large Language Models (LLMs) by incorporating external knowledge and has recently been extended to multimodal settings through Vision-Language Models (VLMs) that integrate visual and textual information. Despite these advances, generated answers can still be incorrect or misleading. Uncertainty Quantification (UQ) methods aim to estimate the reliability of model outputs, but most existing approaches are designed for text-only models and perform poorly in multimodal RAG scenarios. A key challenge is capturing uncertainty arising from multiple stages of the pipeline, including retrieval, visual understanding, and generation. In this work, we show that modeling uncertainty using multimodal and retrieval-aware probability signals improves estimation in multimodal RAG systems. We introduce LeMUQ, a Learnable Multimodal UQ method that analyzes token probabilities under input modifications, such as removing modalities or retrieved context. By encoding these signals as probability tokens and processing them with a finetuned model, our approach captures interactions between modalities and retrieval. Experiments across datasets, retrievers, and VLMs show consistent improvements over baseline and finetuned UQ methods. Our proposed LeMUQ increases the AUROC metric by 3.8% on average. Additionally, our method shows strong generalization performance across different retrieval setups and datasets with mixed results when transferring across different VLMs. Our findings highlight the importance of modeling multimodal uncertainty and provide a step toward more reliable and safer multimodal RAG systems. Code is available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LeMUQ, a learnable multimodal uncertainty quantification method for RAG with VLMs. It extracts token-probability signals by ablating modalities or retrieved context, encodes them as probability tokens, and trains a small model on these signals to estimate answer reliability. The central claim is that this captures modality-retrieval interactions better than baselines, yielding a 3.8% average AUROC gain, consistent improvements across datasets/retrievers/VLMs, and strong generalization to new retrieval setups and datasets (with mixed cross-VLM transfer).
Significance. If the empirical gains are robust, the work would be a useful step toward UQ tailored to multimodal RAG pipelines, where standard token-probability or text-only methods are known to underperform. The use of held-out data for evaluation and public code release are positive for reproducibility.
major comments (2)
- [Abstract] Abstract: the claim that the finetuned model 'captures interactions between modalities and retrieval' is undermined by the immediately following statement of 'mixed results when transferring across different VLMs'. If the learned signals are VLM-specific rather than reflecting general multimodal uncertainty structure, the 3.8% AUROC improvement and generalization narrative hold only within-VLM and do not support the modeling contribution for multimodal RAG systems at large.
- [Experiments] Experiments (transfer results): the mixed cross-VLM transfer performance directly contradicts the assumption that token-probability signals obtained by modality/context removal are sufficient to capture relevant uncertainty interactions that generalize reliably across VLMs; this is load-bearing for the central claim that LeMUQ improves estimation in multimodal RAG systems.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address the two major comments point-by-point below, providing clarifications on the scope of our claims and the interpretation of the transfer results while remaining faithful to the reported experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the finetuned model 'captures interactions between modalities and retrieval' is undermined by the immediately following statement of 'mixed results when transferring across different VLMs'. If the learned signals are VLM-specific rather than reflecting general multimodal uncertainty structure, the 3.8% AUROC improvement and generalization narrative hold only within-VLM and do not support the modeling contribution for multimodal RAG systems at large.
Authors: The abstract claim refers to LeMUQ's design, which explicitly constructs probability signals via modality and context ablations and trains a model to learn from their joint patterns; this is what enables it to capture modality-retrieval interactions within a given VLM pipeline, as demonstrated by the consistent AUROC gains when training and evaluating on the same VLM. The paper already reports mixed cross-VLM transfer transparently, indicating that while the underlying signals are informative, the learned mapping can exhibit VLM-specific characteristics due to differences in token probability distributions across models. This does not undermine the within-VLM contribution or the 3.8% average improvement, which holds across multiple VLMs, datasets, and retrievers. We agree that the abstract wording could be tightened to avoid any implication of universal cross-VLM generalization. revision: partial
-
Referee: [Experiments] Experiments (transfer results): the mixed cross-VLM transfer performance directly contradicts the assumption that token-probability signals obtained by modality/context removal are sufficient to capture relevant uncertainty interactions that generalize reliably across VLMs; this is load-bearing for the central claim that LeMUQ improves estimation in multimodal RAG systems.
Authors: The signals from modality and context removal are sufficient to capture relevant interactions for a given VLM, as shown by the strong within-VLM results and the fact that LeMUQ outperforms baselines that do not model these signals jointly. The mixed transfer results are consistent with the expectation that different VLMs produce distinct probability behaviors, so a model trained on one VLM's signals may not transfer perfectly; this is why the paper explicitly states 'mixed results when transferring across different VLMs' rather than claiming broad cross-VLM generalization. The core contribution remains the learnable multimodal UQ approach that improves estimation in multimodal RAG, with the transfer experiments serving to delineate its practical scope rather than contradict the method's validity. revision: no
Circularity Check
Empirical method evaluated on held-out data; no circularity in derivation
full rationale
The paper introduces LeMUQ as a finetuned model trained on token-probability signals obtained by input modifications (modality or context removal). Performance is reported via AUROC gains measured on held-out data across datasets, retrievers, and VLMs. No load-bearing step reduces a claimed prediction or result to the same fitted quantities by construction, nor relies on self-citation chains or self-definitional mappings. The method is a standard supervised learning pipeline whose outputs are falsifiable on external test distributions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Omar Adjali, Olivier Ferret, Sahar Ghannay, and Hervé Le Borgne. 2024. Multi- Level Information Retrieval Augmented Generation for Knowledge-based Visual Question Answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Lingu...
-
[2]
Kiana Avestimehr, Emily Aye, Zalan Fabian, and Erum Mushtaq. 2025. Detecting unreliable responses in generative vision-language models via visual uncertainty. InICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI
2025
-
[3]
Yavuz Faruk Bakman, Duygu Nur Yaldiz, Baturalp Buyukates, Chenyang Tao, Dimitrios Dimitriadis, and Salman Avestimehr. 2024. MARS: Meaning-aware response scoring for uncertainty estimation in generative LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 7752–7767
2024
-
[4]
Jinyeong Chae and Jihie Kim. 2022. Uncertainty-based Visual Question Answer- ing: Estimating Semantic Inconsistency between Image and Knowledge Base. In International Joint Conference on Neural Networks, IJCNN 2022, Padua, Italy, July 18-23, 2022. IEEE, 1–9. doi:10.1109/IJCNN55064.2022.9892787
-
[5]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al . 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
2024
-
[6]
Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming-Wei Chang. 2023. Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 14948–14968
2023
-
[7]
Federico Cocchi, Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2025. Augmenting multimodal llms with self-reflective tokens for knowledge-based visual question answering. InProceedings of the Computer Vision and Pattern Recognition Conference. 9199–9209
2025
-
[8]
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E Ho. 2024. Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models.Journal of Legal Analysis16, 1 (01 2024), 64–93. arXiv:https://academic.oup.com/jla/article- pdf/16/1/64/58336922/laae003.pdf doi:10.1093/jla/laae003
-
[9]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. 2024. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 5050–5063
2024
-
[10]
Ekaterina Fadeeva, Maiya Goloburda, Aleksandr Rubashevskii, Roman Vashurin, Artem Shelmanov, Preslav Nakov, Mrinmaya Sachan, and Maxim Panov. 2025. Don’t Throw Away Your Beams: Improving Consistency-based Uncertainties in LLMs via Beam Search.CoRRabs/2512.09538 (2025). arXiv:2512.09538 doi:10. 48550/ARXIV.2512.09538
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Dzianis Piatrashyn, Roman Vashurin, Shehzaad Dhuliawala, Artem Shelmanov, Timothy Baldwin, Preslav Nakov, Mrin- maya Sachan, and Maxim Panov. 2025. Faithfulness-aware uncertainty quan- tification for fact-checking the output of retrieval augmented generation.arXiv preprint arXiv:2505.21072(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy.Nature630, 8017 (2024), 625–630
2024
-
[13]
Tom Fawcett. 2006. An introduction to ROC analysis.Pattern recognition letters 27, 8 (2006), 861–874
2006
-
[14]
Shangbin Feng, Weijia Shi, Yike Wang, Wenxuan Ding, Vidhisha Balachandran, and Yulia Tsvetkov. 2024. Don’t Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL. Association for Computational Linguistics, 14664–14690
2024
-
[15]
Oscar Freyer, Isabella Catharina Wiest, Jakob Nikolas Kather, and Stephen Gilbert
-
[16]
doi:10.1016/S2589-7500(24)00124-9
A future role for health applications of large language models depends on regulators enforcing safety standards.The Lancet Digital Health6, 9 (2024), e662–e672. doi:10.1016/S2589-7500(24)00124-9
-
[17]
Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, et al. 2023. A survey of uncertainty in deep neural networks. Artificial Intelligence Review56, Suppl 1 (2023), 1513–1589
2023
-
[18]
James Harrison, John Willes, and Jasper Snoek. 2024. Variational Bayesian Last Layers. InThe Twelfth International Conference on Learning Representations, ICLR. OpenReview.net
2024
-
[19]
Bairu Hou, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang, and Yang Zhang. 2024. Decomposing Uncertainty for Large Language Models through Input Clarification Ensembling. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https: //openreview.net/forum?id=byxXa99PtF
2024
-
[20]
de Vries, Maarten de Rijke, and Faegheh Hasibi
Mohanna Hoveyda, Jelle Piepenbrock, Arjen P. de Vries, Maarten de Rijke, and Faegheh Hasibi. 2026. OrLog: Resolving Complex Queries with LLMs and Proba- bilistic Reasoning. InAdvances in Information Retrieval. Springer Nature Switzer- land, 98–114
2026
-
[21]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. (2025)
2025
-
[22]
Hideaki Joko and Faegheh Hasibi. 2026. FACE: A Fine-Grained Reference-Free Evaluator for Conversational Information Access. InProceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR
2026
-
[23]
Hailey Joren, Jianyi Zhang, Chun-Sung Ferng, Da-Cheng Juan, Ankur Taly, and Cyrus Rashtchian. 2025. Sufficient Context: A New Lens on Retrieval-Augmented Generation Systems. InInternational Conference on Learning Representations (ICLR)
2025
-
[24]
Brown, Jack Clark, Nicholas Joseph, Benjamin Mann, Sam McCandlish, Chris Olah, and Jared Kaplan
Saurav Kadavath, Tom Conerly, Amanda Askell, Thomas Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zachary Dodds, Nova Dassarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, John Kernion, Shauna Kravec, Lian...
-
[26]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, et al. 2022. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Alex Kendall and Yarin Gal. 2017. What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems30 (2017)
2017
-
[28]
Zaid Khan and Yun Fu. 2024. Consistency and uncertainty: Identifying unreliable responses from black-box vision-language models for selective visual question Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Binz et al. answering. InProceedings of the ieee/cvf conference on computer vision and pattern recognition. 10854–10863
2024
-
[29]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Gen- eration. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=VD-AYtP0dve
2023
-
[30]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[31]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
2023
-
[32]
I-Fan Lin, Faegheh Hasibi, and Suzan Verberne. 2026. LLMs Enable Bag-of-Texts Representations for Short-Text Clustering. InProceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
2026
-
[33]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2024. Generating with Confi- dence: Uncertainty Quantification for Black-box Large Language Models.Trans- actions on Machine Learning Research(2024). https://openreview.net/forum?id= DWkJCSxKU5
2024
-
[34]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[35]
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei
-
[36]
InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Uncertainty quantification and confidence calibration in large language models: A survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 6107–6117
-
[37]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.CoRRabs/1907.11692 (2019). arXiv:1907.11692 http://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[38]
Zhenghao Liu, Chenyan Xiong, Yuanhuiyi Lv, Zhiyuan Liu, and Ge Yu. 2023. Universal Vision-Language Dense Retrieval: Learning A Unified Representation Space for Multi-Modal Retrieval. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenRe- view.net. https://openreview.net/forum?id=PQOlkgsBsik
2023
-
[39]
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query rewriting in retrieval-augmented large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 5303–5315
2023
-
[40]
Nishanth Madhusudhan, Sathwik Tejaswi Madhusudhan, Vikas Yadav, and Ma- soud Hashemi. 2025. Do LLMs Know When to NOT Answer? Investigating Abstention Abilities of Large Language Models. InProceedings of the 31st In- ternational Conference on Computational Linguistics, COLING. Association for Computational Linguistics, 9329–9345
2025
-
[41]
Andrey Malinin and Mark Gales. 2021. Uncertainty Estimation in Autoregressive Structured Prediction. InInternational Conference on Learning Representations. https://openreview.net/forum?id=jN5y-zb5Q7m
2021
-
[42]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9802–9822
2023
-
[43]
Thomas Mensink, Jasper Uijlings, Lluis Castrejon, Arushi Goel, Felipe Cadar, Howard Zhou, Fei Sha, André Araujo, and Vittorio Ferrari. 2023. Encyclopedic vqa: Visual questions about detailed properties of fine-grained categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3113– 3124
2023
-
[44]
Erum Mushtaq, Zalan Fabian, Yavuz Faruk Bakman, Anil Ramakrishna, Mahdi Soltanolkotabi, and Salman Avestimehr. 2025. HARMONY: Hidden Activation Representations and Model Output-Aware Uncertainty Estimation for Vision- Language Models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). 1654–1659. doi:10.1109/CVPRW67362...
-
[45]
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshminarayanan, and Jasper Snoek. 2019. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift.Advances in neural information processing systems32 (2019)
2019
- [46]
-
[47]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. 2023. Measuring and Narrowing the Compositionality Gap in Language Models. InFindings of the Association for Computational Linguistics: EMNLP
2023
-
[48]
Zexuan Qiu, Zijing Ou, Bin Wu, Jingjing Li, Aiwei Liu, and Irwin King. 2025. Entropy-based decoding for retrieval-augmented large language models. InPro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 4616–4627
2025
-
[49]
Mahta Rafiee, Heydar Soudani, Zahra Abbasiantaeb, Mohammad Aliannejadi, Faegheh Hasibi, and Hamed Zamani. 2026. Total Recall QA: A Verifiable Eval- uation Suite for Deep Research Agents. InProceedings of the 49th International ACM SIGIR Conference on Research and Development in Information Retrieval
2026
-
[50]
Robertson and Hugo Zaragoza
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009), 333–389
2009
-
[51]
Heydar Soudani. 2025. Enhancing Knowledge Injection in Large Language Models for Efficient and Trustworthy Responses. InProceedings of the 48th International ACM Conference on Research and Development in Information Retrieval, SIGIR
2025
-
[52]
Heydar Soudani, Evangelos Kanoulas, and Faegheh Hasibi. 2024. Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge. InProceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, SIGIR-AP 2024. 12–22
2024
-
[53]
Heydar Soudani, Evangelos Kanoulas, and Faegheh Hasibi. 2025. Why Uncer- tainty Estimation Methods Fall Short in RAG: An Axiomatic Analysis. InFindings of the Association for Computational Linguistics: ACL 2025. 16596–16616
2025
-
[54]
Heydar Soudani, Roxana Petcu, Evangelos Kanoulas, and Faegheh Hasibi. 2026. A Survey on Recent Advances in Conversational Data Generation.ACM Comput. Surv.58 (4 2026). Issue 10. doi:10.1145/3795686
-
[55]
Heydar Soudani, Hamed Zamani, and Faegheh Hasibi. 2026. Uncertainty Quan- tification for Retrieval-Augmented Reasoning. (2026)
2026
-
[56]
selective prediction
Tejas Srinivasan, Jack Hessel, Tanmay Gupta, Bill Yuchen Lin, Yejin Choi, Jesse Thomason, and Khyathi Chandu. 2024. Selective “selective prediction”: Reducing unnecessary abstention in vision-language reasoning. InFindings of the Associa- tion for Computational Linguistics: ACL 2024. 12935–12948
2024
-
[57]
Prashant Upadhyay, Rishabh Agarwal, Sumeet Dhiman, Abhinav Sarkar, and Saumya Chaturvedi. 2024. A comprehensive survey on answer generation methods using NLP.Natural Language Processing Journal8 (2024), 100088. doi:10.1016/j.nlp.2024.100088
-
[58]
Artem Vazhentsev, Lyudmila Rvanova, Gleb Kuzmin, Ekaterina Fadeeva, Ivan Lazichny, Alexander Panchenko, Maxim Panov, Timothy Baldwin, Mrinmaya Sachan, Preslav Nakov, and Artem Shelmanov. 2026. Uncertainty-Aware At- tention Heads: Efficient Unsupervised Uncertainty Quantification for LLMs. In Proceedings of 43rd International Conference on Machine Learning (ICML)
2026
-
[59]
Aparna Vinayan Kozhipuram, Samar Shailendra, and Rajan Kadel. 2025. Retrieval- Augmented Generation vs. Baseline LLMs: A Multi-Metric Evaluation for Knowledge-Intensive Content.Information16, 9 (2025). doi:10.3390/info16090766
-
[60]
Weihao Xuan, Qingcheng Zeng, Heli Qi, Junjue Wang, and Naoto Yokoya. 2025. Seeing is believing, but how much? a comprehensive analysis of verbalized calibration in vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 1408–1450
2025
-
[61]
Duygu Nur Yaldiz, Yavuz Faruk Bakman, Baturalp Buyukates, Chenyang Tao, Anil Ramakrishna, Dimitrios Dimitriadis, Jieyu Zhao, and Salman Avestimehr
-
[62]
InFindings of the Association for Computational Linguistics: NAACL 2025
Do Not Design, Learn: A Trainable Scoring Function for Uncertainty Estimation in Generative LLMs. InFindings of the Association for Computational Linguistics: NAACL 2025
2025
-
[63]
Yibin Yan and Weidi Xie. 2024. Echosight: Advancing visual-language models with wiki knowledge. InFindings of the Association for Computational Linguistics: EMNLP 2024. 1538–1551
2024
-
[64]
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Zhiyuan Zeng, Xiaonan Li, Junqi Dai, Qinyuan Cheng, Xuanjing Huang, and Xipeng Qiu. 2024. Reasoning in Flux: Enhancing Large Language Models Reasoning through Uncertainty-aware Adap- tive Guidance. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL. 2401–2416
2024
-
[65]
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zheng- hao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. 2025. Vis- RAG: Vision-based Retrieval-augmented Generation on Multi-modality Doc- uments. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=zG459X3Xge
2025
-
[66]
Qiwei Zhao, Dong Li, Yanchi Liu, Wei Cheng, Yiyou Sun, Mika Oishi, Takao Osaki, Katsushi Matsuda, Huaxiu Yao, Chen Zhao, Haifeng Chen, and Xujiang Zhao. 2025. Uncertainty Propagation on LLM Agent. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1...
2025
-
[67]
The generated answer is true
Yukun Zhao, Lingyong Yan, Weiwei Sun, Guoliang Xing, Chong Meng, Shuaiqiang Wang, Zhicong Cheng, Zhaochun Ren, and Dawei Yin. 2024. Know- ing What LLMs DO NOT Know: A Simple Yet Effective Self-Detection Method. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.