Compass: Navigating Global Marine Lead Data Integration through Expert-Guided LLM Agent
Pith reviewed 2026-06-29 07:27 UTC · model grok-4.3
The pith
An expert-guided LLM agent extracts 3751 new marine lead records from over 230000 papers to form the largest integrated database at 92 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
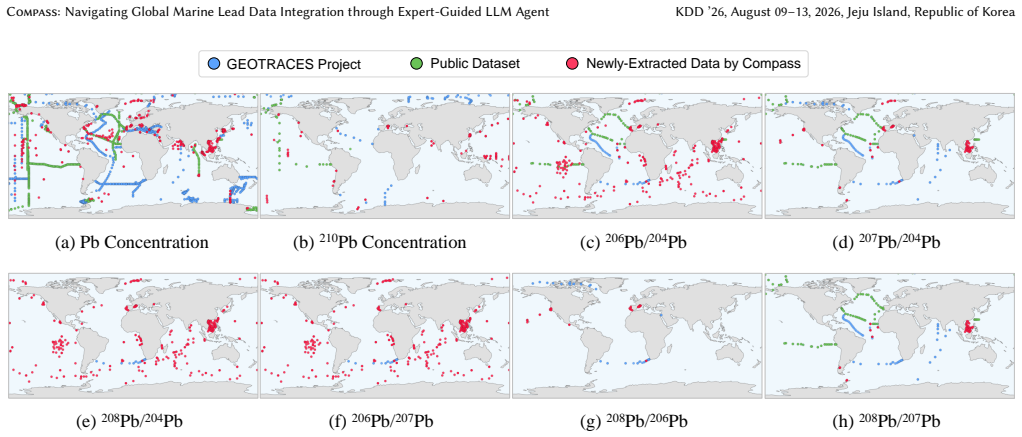
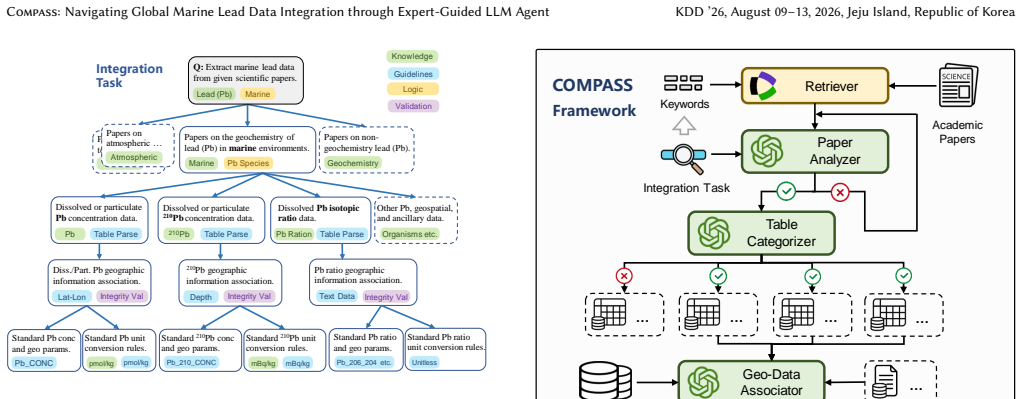
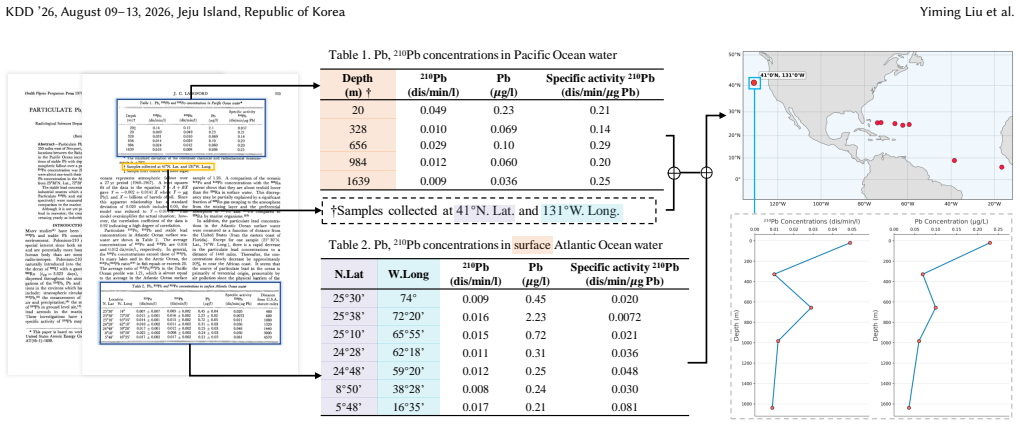
Compass is an LLM agent framework enhanced by a Knowledge Tree co-designed with marine scientists, which decomposes complex tasks into verifiable steps guiding the agent's reasoning to ensure scientific validity. Deployed across a corpus of over 230000 relevant open-access papers, Compass extracts 3751 previously unincorporated Pb records, establishing the largest integrated marine Pb database to date. The system achieves 92 percent accuracy confirmed by expert manual verification and expands coverage in under-sampled regions such as the East China Sea and the Southern Ocean.
What carries the argument
The Knowledge Tree, a structured set of task decompositions co-designed with marine scientists, which breaks extraction into verifiable steps that direct the LLM agent's reasoning.
Load-bearing premise
The Knowledge Tree created with marine scientists will reliably break down tasks into steps that keep the LLM's outputs scientifically valid and free of invented data.
What would settle it
An independent expert review of a random sample of the extracted records that finds accuracy well below 92 percent would show the method does not deliver the claimed reliability.
Figures



read the original abstract
Marine lead (Pb) and its isotopes are critical tracers for ocean circulation and anthropogenic pollution, yet in-situ observations remain costly and sparse. While vast historical records exist, they lie buried within the unstructured content of academic papers, creating "data silos" inaccessible to comprehensive analysis. Manual extraction is unscalable, while general-purpose Large Language Models (LLMs) lack the necessary domain-specific knowledge, leading to hallucinations and scientifically invalid outputs. To address this, we introduce an expert-guided adaptation approach that enables LLMs to perform rigorous scientific data extraction without fine-tuning. We operationalize this approach through Compass, an LLM agent framework enhanced by a Knowledge Tree co-designed with marine scientists, which decomposes complex tasks into verifiable steps, guiding the agent's reasoning to ensure scientific validity. Deploying Compass across a corpus of over 230,000 relevant open-access papers, we successfully extract 3,751 previously unincorporated Pb records. This effort establishes the largest integrated marine Pb database to date. Beyond standard metrics, Compass demonstrates superior reliability through multi-layered validation, achieving 92% accuracy as confirmed through expert manual verification. The newly integrated data expand coverage in previously under-sampled regions such as the East China Sea and the Southern Ocean, providing an enriched data foundation for future scientific discoveries. We release an interactive visualization platform to facilitate open scientific access. Our work demonstrates that expert-guided agents can effectively bridge the gap between general-purpose LLMs and high-stakes scientific domains, enabling scalable data discovery in geosciences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Compass, an LLM agent framework that uses an expert-co-designed Knowledge Tree to guide the extraction of marine lead (Pb) data from scientific literature. The authors deploy it on over 230,000 papers to extract 3,751 new Pb records, claiming this creates the largest integrated marine Pb database, with 92% accuracy confirmed by expert manual verification, and release an interactive visualization platform.
Significance. If the accuracy and representativeness of the extracted data can be substantiated, the work has potential significance in geosciences by providing a substantially larger dataset for Pb tracers in ocean studies, and in AI by showing how expert-guided agents can improve reliability in domain-specific extraction tasks without fine-tuning.
major comments (2)
- [Abstract] Abstract and validation description: The central claim of 92% accuracy 'confirmed through expert manual verification' and 'multi-layered validation' lacks any specification of sampling method, sample size, inter-expert agreement, or error taxonomy. This is load-bearing for the reliability and 'superior reliability' assertions, as the verification is the sole evidence presented for the Knowledge Tree's efficacy in preventing hallucinations.
- [Results] Results section on extraction: The claim of 3,751 previously unincorporated records establishing the 'largest integrated marine Pb database' depends on the unelaborated verification step; without details on how records were deduplicated against existing databases or how the Knowledge Tree decomposes tasks into verifiable steps, systematic errors (e.g., unit misparsing or citation linkage) cannot be ruled out.
minor comments (2)
- [Abstract] The abstract refers to 'standard metrics' and 'comparison against baselines' but provides no explicit list of metrics or baseline methods (e.g., general LLMs or rule-based systems).
- [Methods] Clarify the exact components and co-design process of the Knowledge Tree with an example workflow or figure to make the expert-guided adaptation reproducible.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The concerns about validation transparency and extraction methodology are valid and directly address the load-bearing claims in our work. We will revise the manuscript to provide the requested specifications and elaborations, strengthening the evidence for Compass's reliability without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation description: The central claim of 92% accuracy 'confirmed through expert manual verification' and 'multi-layered validation' lacks any specification of sampling method, sample size, inter-expert agreement, or error taxonomy. This is load-bearing for the reliability and 'superior reliability' assertions, as the verification is the sole evidence presented for the Knowledge Tree's efficacy in preventing hallucinations.
Authors: We agree that the current manuscript does not specify the sampling method, sample size, inter-expert agreement, or error taxonomy for the 92% accuracy figure. In the revised version, we will expand the Methods and Results sections (and update the abstract) to include: (1) the sampling strategy (stratified random sampling across data types and regions, n=250 records), (2) the number of domain experts (three marine geochemists), (3) inter-expert agreement (Fleiss' kappa = 0.87), and (4) a categorized error taxonomy (e.g., unit conversion errors, citation linkage failures, false positives from ambiguous text). This will directly substantiate the multi-layered validation process and the Knowledge Tree's role in reducing hallucinations. revision: yes
-
Referee: [Results] Results section on extraction: The claim of 3,751 previously unincorporated records establishing the 'largest integrated marine Pb database' depends on the unelaborated verification step; without details on how records were deduplicated against existing databases or how the Knowledge Tree decomposes tasks into verifiable steps, systematic errors (e.g., unit misparsing or citation linkage) cannot be ruled out.
Authors: We acknowledge the need for explicit details on deduplication and the Knowledge Tree's decomposition. In the revision, we will add a dedicated subsection in Results describing: (1) the deduplication pipeline, including fuzzy matching on coordinates, depth, and citation metadata against GEOTRACES, BODC, and other public repositories, with manual review of borderline cases; and (2) how the Knowledge Tree structures extraction into sequential, verifiable sub-tasks (e.g., separate agents for parameter identification, unit normalization, and source attribution) with intermediate validation checkpoints. These additions will address potential systematic errors and support the claim of 3,751 new records. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central result is an empirical count of 3,751 extracted records from an external corpus of >230,000 papers, with accuracy assessed via external expert manual verification. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the provided text. The Knowledge Tree is presented as a co-designed decomposition tool whose efficacy is tied to the external verification step rather than reducing any output to an internal input by construction. The derivation chain remains independent of the paper's own definitions or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maya Almaraz, Chao Wang, and Michelle Y Wong. 2025. Deep soil contributions to global nitrogen budgets.Nature Communications16, 1 (2025), 966
2025
-
[2]
Peters, Joanna Power, Sam Skjonsberg, Lucy Lu Wang, Chris Wilhelm, Zheng Yuan, Madeleine van Zuylen, and Oren Etzioni
Waleed Ammar, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Miles Craw- ford, Doug Downey, Jason Dunkelberger, Ahmed Elgohary, Sergey Feldman, Vu Ha, Rodney Kinney, Sebastian Kohlmeier, Kyle Lo, Tyler Murray, Hsu-Han Ooi, Matthew E. Peters, Joanna Power, Sam Skjonsberg, Lucy Lu Wang, Chris Wilhelm, Zheng Yuan, Madeleine van Zuylen, and Oren Etzioni. 2...
2018
-
[3]
Robert F Anderson. 2020. GEOTRACES: Accelerating research on the marine biogeochemical cycles of trace elements and their isotopes.Annual Review of Marine Science12, 1 (2020), 49–85
2020
- [4]
-
[5]
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A Pretrained Language Model for Scientific Text. InProceedings of the 2019 Conference on Empirical Meth- ods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (Eds.). Association ...
-
[6]
Zhen Bi, Ningyu Zhang, Yida Xue, Yixin Ou, Daxiong Ji, Guozhou Zheng, and Huajun Chen. 2024. OceanGPT: A Large Language Model for Ocean Science Tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguis...
-
[7]
Edward A Boyle, Jong-Mi Lee, Yolanda Echegoyen, Abigail Noble, Simone Moos, Gonzalo Carrasco, Ning Zhao, Richard Kayser, Jing Zhang, Toshitaka Gamo, et al. 2014. Anthropogenic lead emissions in the ocean: The evolving global experiment.Oceanography27, 1 (2014), 69–75
2014
- [8]
-
[9]
Daniel J Cziczo, Olaf Stetzer, Annette Worringen, Martin Ebert, Stephan Wein- bruch, Michael Kamphus, Stephane J Gallavardin, Joachim Curtius, Stephan Borrmann, Karl D Froyd, et al. 2009. Inadvertent climate modification due to anthropogenic lead.Nature geoscience2, 5 (2009), 333–336
2009
-
[10]
John Dagdelen, Alexander Dunn, Sanghoon Lee, Nicholas Walker, Andrew S Rosen, Gerbrand Ceder, Kristin A Persson, and Anubhav Jain. 2024. Structured information extraction from scientific text with large language models.Nature Communications15, 1 (2024), 1418
2024
-
[11]
Cheng Deng, Tianhang Zhang, Zhongmou He, Qiyuan Chen, Yuanyuan Shi, Yi Xu, Luoyi Fu, Weinan Zhang, Xinbing Wang, Chenghu Zhou, et al . 2024. K2: A foundation language model for geoscience knowledge understanding and utilization. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 161–170
2024
-
[12]
Jun-xuan Fan, Shu-zhong Shen, Douglas H Erwin, Peter M Sadler, Norman MacLeod, Qiu-ming Cheng, Xu-dong Hou, Jiao Yang, Xiang-dong Wang, Yue Wang, et al. 2020. A high-resolution summary of Cambrian to Early Triassic marine invertebrate biodiversity.Science367, 6475 (2020), 272–277
2020
-
[13]
Yuchen Fang, Zhenggang Tang, Kan Ren, Weiqing Liu, Li Zhao, Jiang Bian, Dong- sheng Li, Weinan Zhang, Yong Yu, and Tie-Yan Liu. 2023. Learning Multi-Agent Intention-Aware Communication for Optimal Multi-Order Execution in Finance. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). Associat...
-
[14]
Alireza Ghafarollahi and Markus J. Buehler. 2025. SciAgents: Au- tomating Scientific Discovery Through Bioinspired Multi-Agent Intel- ligent Graph Reasoning.Advanced Materials37, 22 (2025), 2413523. arXiv:https://advanced.onlinelibrary.wiley.com/doi/pdf/10.1002/adma.202413523 doi:10.1002/adma.202413523
-
[15]
Alex Griffiths, Hollie Packman, Yee-Lap Leung, Barry J Coles, Katharina Kreissig, Susan H Little, Tina van de Flierdt, and Mark Rehkaämper. 2020. Evaluation of optimized procedures for high-precision lead isotope analyses of seawater by multiple collector inductively coupled plasma mass spectrometry.Analytical Chemistry92, 16 (2020), 11232–11241
2020
-
[16]
Yue Guo, Wentao Zhang, Xiaojun Zhang, Vincent W. Zheng, and Yi Yang. 2025. Efficient Multi-Expert Tabular Language Model for Banking. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 (Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 2271–2281. doi:10.1145/3690624.3709400
-
[17]
Qianyue Hao, Wenzhen Huang, Tao Feng, Jian Yuan, and Yong Li. 2023. GAT-MF: Graph Attention Mean Field for Very Large Scale Multi-Agent Reinforcement Learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining(Long Beach, CA, USA)(KDD ’23). Association for Com- puting Machinery, New York, NY, USA, 685–697. doi:10.114...
-
[18]
Henderson and Ernst Maier-Reimer
Gideon M. Henderson and Ernst Maier-Reimer. 2002. Advection and removal of 210Pb and stable Pb isotopes in the oceans: a general circulation model study. Geochimica et Cosmochimica Acta66, 2 (2002), 257–272. doi:10.1016/S0016- 7037(01)00779-7
-
[19]
Mengkang Hu, Pu Zhao, Can Xu, Qingfeng Sun, Jian-Guang Lou, Qingwei Lin, Ping Luo, and Saravan Rajmohan. 2025. AgentGen: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1(Toronto ON, Canada)(KDD ’25). Association ...
-
[20]
Earl B Hunt, Janet Marin, and Philip J Stone. 1966. Experiments in induction. (1966)
1966
-
[21]
Song Jiang, Zijie Huang, Xiao Luo, and Yizhou Sun. 2023. CF-GODE: Continuous- Time Causal Inference for Multi-Agent Dynamical Systems. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). Association for Computing Machinery, New York, NY, USA, 997–1009. doi:10.1145/3580305.3599272
-
[22]
Anderson, Rickard Sture- borg, Aman Tyagi, and Bhuwan Dhingra
Ghazal Khalighinejad, Sharon Scott, Ollie Liu, Kelly L. Anderson, Rickard Sture- borg, Aman Tyagi, and Bhuwan Dhingra. 2025. MatViX: Multimodal Information Extraction from Visually Rich Articles. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
-
[23]
Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, et al. 2024. AutoWebGLM: A Large Language Model-based Web Navigating Agent. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5295–5306
2024
- [24]
-
[25]
J. C. Langford. 1971. Particulate Pb, 210Pb and 210Po in the Environment.Health Physics20, 3 (March 1971), 331–336
1971
-
[26]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[27]
Xin Li, Feng Liu, Chunfeng Ma, Jinliang Hou, Donghai Zheng, Hanqing Ma, Yulong Bai, Xujun Han, Harry Vereecken, Kun Yang, et al. 2024. Land data assim- ilation: Harmonizing theory and data in land surface process studies.Reviews of Geophysics62, 1 (2024), e2022RG000801
2024
-
[28]
Xin Li, Hanqing Ma, Youhua Ran, Xufeng Wang, Gaofeng Zhu, Feng Liu, Honglin He, Zhen Zhang, and Chunlin Huang. 2021. Terrestrial carbon cycle model- data fusion: Progress and challenges.Science China Earth Sciences64, 10 (2021), 1645–1657
2021
-
[29]
Jana Lipkova, Richard J Chen, Bowen Chen, Ming Y Lu, Matteo Barbieri, Daniel Shao, Anurag J Vaidya, Chengkuan Chen, Luoting Zhuang, Drew FK Williamson, et al. 2022. Artificial intelligence for multimodal data integration in oncology. Cancer cell40, 10 (2022), 1095–1110
2022
-
[30]
Yuxuan Liu, Hongda Sun, Wei Liu, Jian Luan, Bo Du, and Rui Yan. 2025. Mo- bileSteward: Integrating Multiple App-Oriented Agents with Self-Evolution to Automate Cross-App Instructions. InProceedings of the 31st ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining V.1(Toronto ON, Canada) (KDD ’25). Association for Computing Machinery, New York, NY...
-
[31]
Jerome O Nriagu and Jozef M Pacyna. 1988. Quantitative assessment of worldwide contamination of air, water and soils by trace metals.nature333, 6169 (1988), 134–139
1988
-
[32]
B. Nussbaumer-Streit, M. Ellen, I. Klerings, R. Sfetcu, N. Riva, M. Mahmić-Kaknjo, G. Poulentzas, P. Martinez, E. Baladia, L.E. Ziganshina, M.E. Marqués, L. Aguilar, A.P. Kassianos, G. Frampton, A.G. Silva, L. Affengruber, R. Spjker, J. Thomas, R.C. Berg, M. Kontogiani, M. Sousa, C. Kontogiorgis, and G. Gartlehner. 2021. Resource use during systematic rev...
-
[33]
Clair C Patterson. 1965. Contaminated and natural lead environments of man. Archives of Environmental Health: An International Journal11, 3 (1965), 344–360
1965
-
[34]
Bernhard K. Schaule and Clair C. Patterson. 1981. Lead concentrations in the northeast Pacific: evidence for global anthropogenic perturbations.Earth and Planetary Science Letters54, 1 (1981), 97–116. doi:10.1016/0012-821X(81)90072-8
-
[35]
Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, et al. 2025. Chema- gent: Self-updating memories in large language models improves chemical rea- soning. InThe Thirteenth International Conference on Learning Representations
2025
-
[36]
Omkarprasad S Vaidya and Sushil Kumar. 2006. Analytic hierarchy process: An overview of applications.European Journal of operational research169, 1 (2006), 1–29
2006
-
[37]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, Bo Zhang, Liqun Wei, Zhihao Sui, Wei Li, Botian Shi, Yu Qiao, Dahua Lin, and Conghui He. 2024. MinerU: An Open-Source Solution for Precise Document Content Extraction. arXiv:2409.18839 [cs.CV] https://arxiv.org/abs/2409.18839
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Jingwei Wang, Qianyue Hao, Wenzhen Huang, Xiaochen Fan, Qin Zhang, Zhen- tao Tang, Bin Wang, Jianye Hao, and Yong Li. 2025. CoopRide: Cooperate All Grids in City-Scale Ride-Hailing Dispatching with Multi-Agent Reinforcement Learn- ing. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1(Toronto ON, Canada)(KDD ’25). ...
-
[39]
Xinbing Wang, Luoyi Fu, Xiaoying Gan, Ying Wen, Guanjie Zheng, Jiaxin Ding, Liyao Xiang, Nanyang Ye, Meng Jin, Shiyu Liang, Bin Lu, Haiwen Wang, Yi Xu, Cheng Deng, Shao Zhang, Huquan Kang, Xingli Wang, Qi Li, Zhixin Guo, Jiexing Qi, Pan Liu, Yuyang Ren, Lyuwen Wu, Jungang Yang, Jianping Zhou, and Chenghu Zhou. 2024. AceMap: Knowledge Discovery through Aca...
-
[40]
Xumeng Wen, Han Zhang, Shun Zheng, Wei Xu, and Jiang Bian. 2024. From Supervised to Generative: A Novel Paradigm for Tabular Deep Learning with Large Language Models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 3323–3333. doi:10.1...
-
[41]
Jingfeng Wu and Edward A Boyle. 1997. Lead in the western North Atlantic Ocean: Completed response to leaded gasoline phaseout.Geochimica et Cosmochimica Acta61, 15 (1997), 3279–3283. doi:10.1016/S0016-7037(97)89711-6
-
[42]
Mingzhe Xing, Hangyu Mao, Shenglin Yin, Lichen Pan, Zhengchao Zhang, Zhen Xiao, and Jieyi Long. 2023. A Dual-Agent Scheduler for Distributed Deep Learning Jobs on Public Cloud via Reinforcement Learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). Association for Computing Machinery...
-
[43]
Hancheng Zhang, Guozheng Li, Chi Harold Liu, Guoren Wang, and Jian Tang
-
[44]
HiMacMic: Hierarchical Multi-Agent Deep Reinforcement Learning with Dynamic Asynchronous Macro Strategy. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA) (KDD ’23). Association for Computing Machinery, New York, NY, USA, 3239–3248. doi:10.1145/3580305.3599379
-
[45]
J. Zhang, Z.T. Ni, J.L. Ren, F. Yu, X.Y. Diao, Y. Wang, S.J. Zhang, H. Su, S.L. Cong, Z.J. Lu, S. Jiang, J. Ou, Y. Chen, Q. Wang, Z.B. Zhang, J.T. Ai, C.B. Wang, and Z.D. Tao. 2024. Modular ocean trace elements sampling for the international GEOTRACES studies – Evidence from analysis of dissolved Fe and Pb.Progress in Oceanography221 (2024), 103212. doi:1...
-
[46]
Weichao Zhao, Hao Feng, Qi Liu, Jingqun Tang, Binghong Wu, Lei Liao, Shu Wei, Yongjie Ye, Hao Liu, Wengang Zhou, et al. 2024. Tabpedia: Towards compre- hensive visual table understanding with concept synergy.Advances in Neural Information Processing Systems37 (2024), 7185–7212
2024
-
[47]
Cheryl M Zurbrick, Céline Gallon, and A Russell Flegal. 2017. Historic and industrial lead within the Northwest Pacific Ocean evidenced by lead isotopes in seawater.Environmental Science & Technology51, 3 (2017), 1203–1212. A Complete Paper List Table 4 presents the complete list of 110 papers that were identified byCompassduring its deployment in marine ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.