Causal Interventions on Continuous Variables: A Case Study on Verb Bias in Steering Vectors for In-Context Learning
Pith reviewed 2026-06-29 07:34 UTC · model grok-4.3
The pith
Counterfactual edits to verb bias in steering vectors shift language models' syntactic structure preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
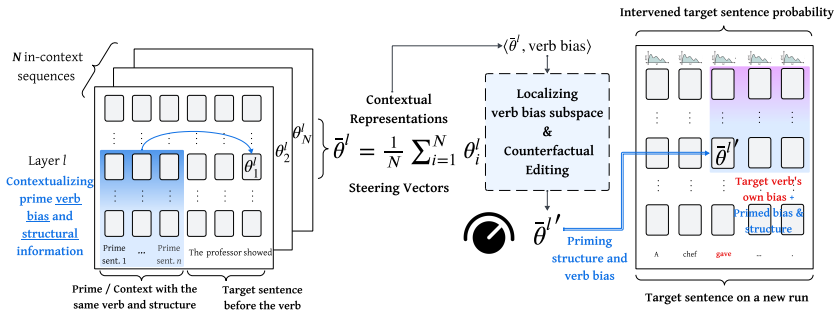
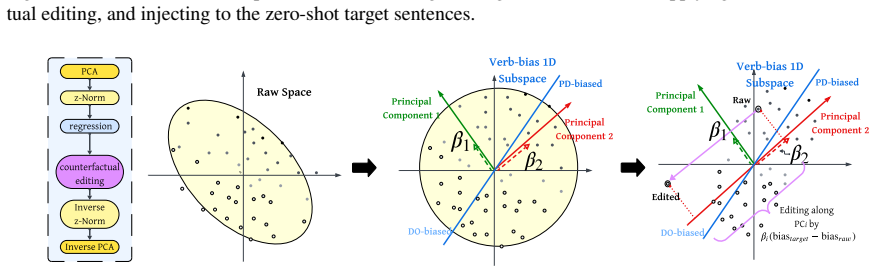
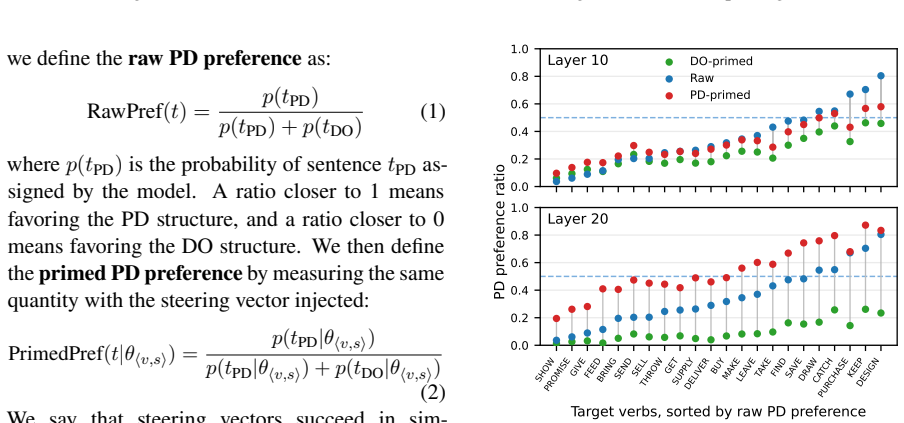
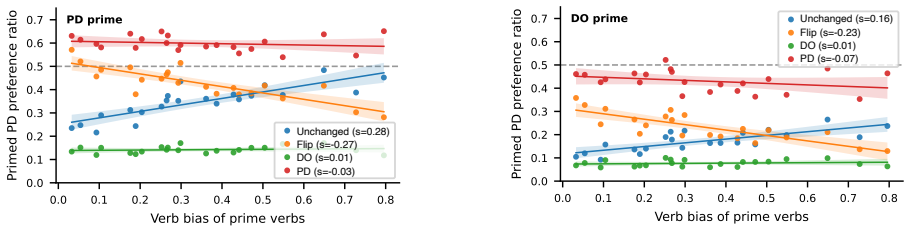
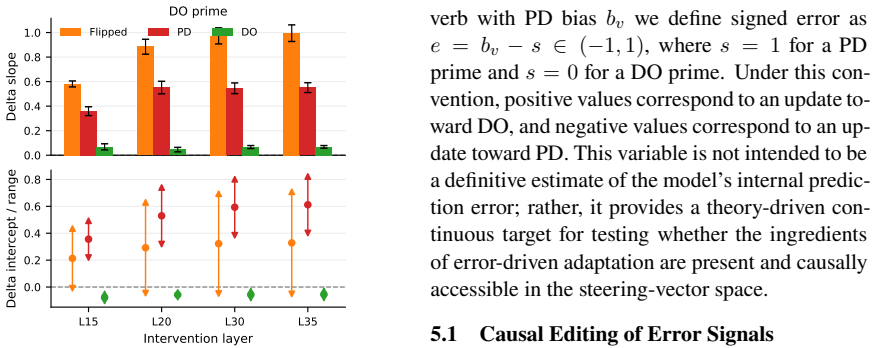
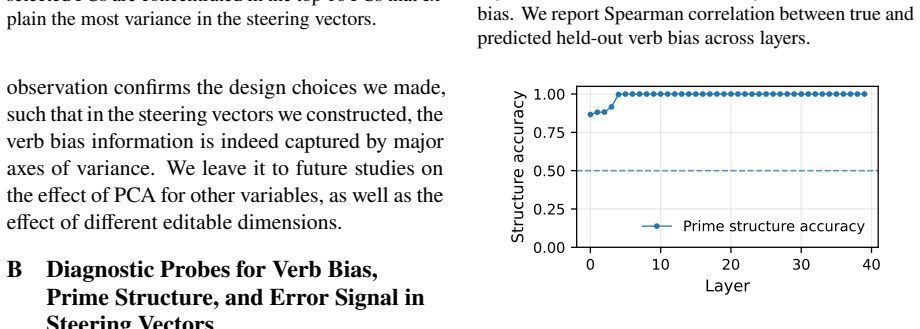
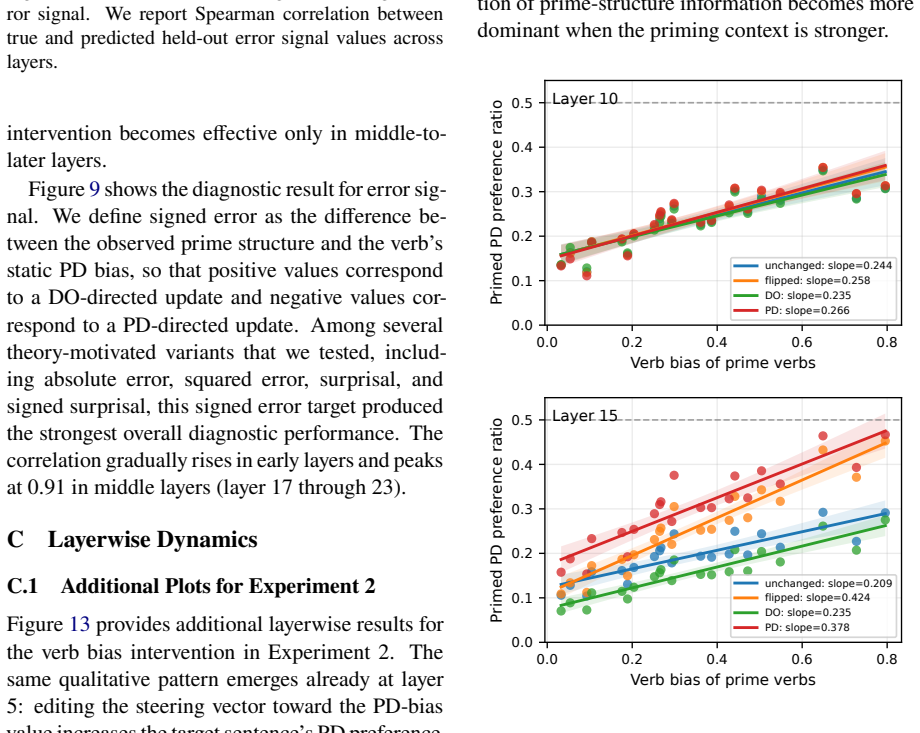
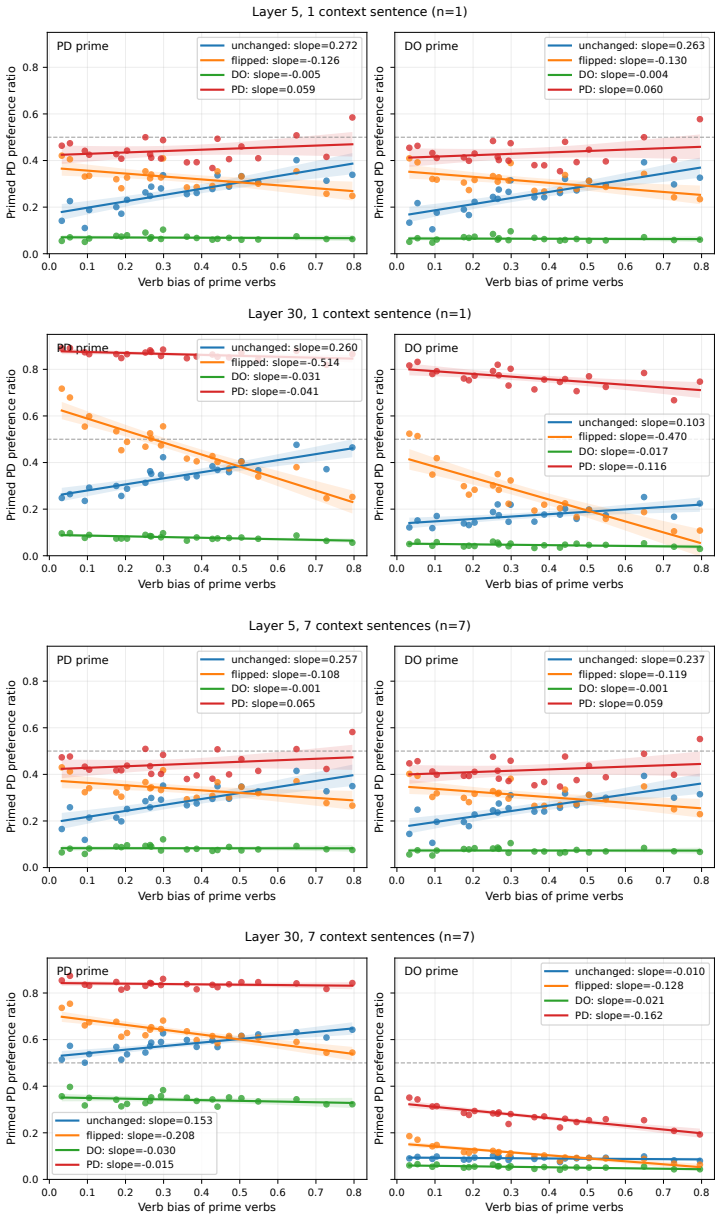
We introduce a method for causal intervention on continuous variables: given activation vectors paired with a graded target variable, we localize a low-dimensional direction for that variable and use this direction to edit vectors toward counterfactual target values. We apply this method to a continuous feature that is well-studied in psycholinguistics, namely verb bias. We show that verb bias is causally represented in steering vectors extracted from large language models: counterfactual edits to verb bias systematically shift downstream structural preferences. Verb bias has also previously been linked to in-context learning; in further analyses, we find that steering vectors encode error s
What carries the argument
Low-dimensional direction localized from activation vectors paired with a graded target variable, then used to shift those vectors toward counterfactual values of the variable.
If this is right
- Counterfactual edits along the identified direction produce measurable shifts in the syntactic structures the model prefers after a given verb.
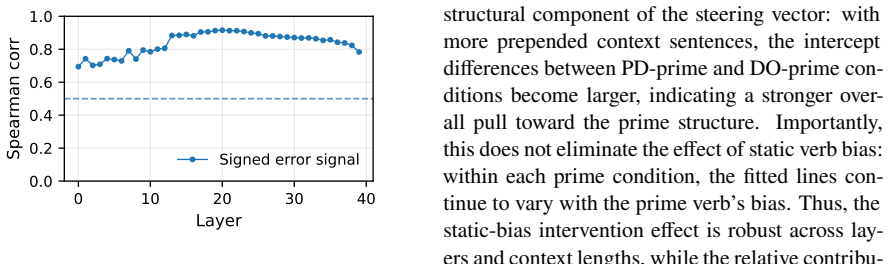
- Steering vectors extracted from the model contain error signals that align with the update rule observed in in-context learning.
- Those same error-signal components are not required for the model's actual downstream token predictions.
- Causal intervention techniques that were previously restricted to discrete features can now be applied to continuous variables inside language models.
Where Pith is reading between the lines
- The same localization-and-edit procedure could be tested on other graded variables such as semantic plausibility or lexical frequency to check whether they are likewise causally represented.
- If the direction truly isolates verb bias, then ablating it should leave other model behaviors intact while selectively disrupting structure choice.
- The finding that error signals are encoded but not used causally points to a possible separation between the mechanisms that support learning from context and those that support generation.
- Replicating the edits across model families of different sizes would test whether the causal representation of verb bias scales with model capacity.
Load-bearing premise
The low-dimensional direction extracted from the activation vectors paired with graded verb bias isolates the causal contribution of verb bias rather than correlated features or artifacts of how the direction was found.
What would settle it
Running the same counterfactual edits on a held-out set of verbs and sentences and observing no systematic change in the model's choice of syntactic structures while control edits on unrelated directions produce changes.
Figures


read the original abstract
Causal interventions in language model representations have largely targeted discrete features, like grammatical number. However, language models must also make use of features that are graded. We introduce a method for causal intervention on continuous variables: given activation vectors paired with a graded target variable, we localize a low-dimensional direction for that variable and use this direction to edit a vectors toward counterfactual target values. We apply this method to a continuous feature that is well-studied in psycholinguistics, namely verb bias (which reflects which syntactic structures tend to follow a given verb). We show that verb bias is causally represented in steering vectors extracted from large language models: counterfactual edits to verb bias systematically shift downstream structural preferences. Verb bias has also previously been linked to in-context learning; in further analyses, we find that steering vectors encode error signals that could drive the error-driven update behavior seen in in-context learning but that these aspects of the steering vectors are not causally used in downstream production. Overall, these results show causal interventions can be applied to continuous variables, though connecting continuous variables to in-context learning remains a challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a method for causal intervention on continuous variables in language model representations: given activation vectors paired with a graded target, localize a low-dimensional direction and edit vectors toward counterfactual target values. It applies this to verb bias (a graded psycholinguistic feature), claiming that counterfactual edits systematically shift downstream structural preferences. Additional analyses suggest steering vectors encode error signals relevant to in-context learning, though these are not causally used in downstream production.
Significance. If the central causal claim is supported by appropriate quantitative controls and isolation of the target feature, the work would meaningfully extend causal intervention techniques from discrete to continuous linguistic features and connect model representations to established psycholinguistic constructs. The empirical intervention approach and the attempt to link to in-context learning error-driven updates are potentially valuable contributions.
major comments (2)
- [Abstract] Abstract: the claim that counterfactual edits 'systematically shift downstream structural preferences' supplies no quantitative details, error bars, controls, or dataset descriptions, so the soundness of the central causal claim cannot be evaluated from the provided text.
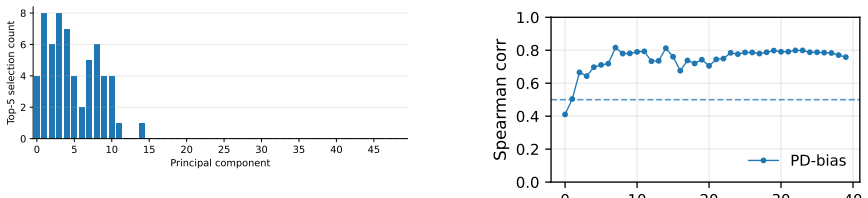
- [Approach] Approach (direction extraction): the low-dimensional direction found from activation vectors paired with graded verb-bias targets may capture correlated features (e.g., argument structure frequency, semantic category, or lexical frequency) rather than isolating the causal contribution of verb bias; without explicit orthogonalization or controls against these confounds, the subsequent edits could shift structural preferences via artifacts rather than verb bias per se.
minor comments (1)
- The abstract would benefit from explicit mention of the models, datasets, and statistical tests used to support the 'systematic shifts' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, providing clarifications on the quantitative results and the direction extraction method while committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that counterfactual edits 'systematically shift downstream structural preferences' supplies no quantitative details, error bars, controls, or dataset descriptions, so the soundness of the central causal claim cannot be evaluated from the provided text.
Authors: We agree the abstract is high-level and omits quantitative details due to length limits. The full manuscript reports these elements in the Results and Methods sections, including error bars across multiple model runs and seeds, dataset descriptions (using established psycholinguistic verb bias norms), and intervention controls. We will revise the abstract to include a concise quantitative summary of the observed shifts to improve evaluability. revision: yes
-
Referee: [Approach] Approach (direction extraction): the low-dimensional direction found from activation vectors paired with graded verb-bias targets may capture correlated features (e.g., argument structure frequency, semantic category, or lexical frequency) rather than isolating the causal contribution of verb bias; without explicit orthogonalization or controls against these confounds, the subsequent edits could shift structural preferences via artifacts rather than verb bias per se.
Authors: We acknowledge this concern about potential confounds. The direction is localized via regression on the graded verb bias targets, which by design captures variance associated with that variable. The manuscript includes checks that the direction is not reducible to lexical frequency alone. To strengthen isolation, we will add explicit orthogonalization by including frequency, semantic category, and argument structure frequency as covariates in the regression and report the resulting direction in a revised version. revision: yes
Circularity Check
No circularity: empirical intervention study with falsifiable experimental claims
full rationale
The paper introduces an empirical method for localizing and editing directions in activation space based on paired activation-target data, then reports observed shifts in downstream behavior from counterfactual edits. No derivation chain, first-principles prediction, or mathematical result is claimed that reduces by construction to fitted parameters or self-citations. The central claim rests on experimental outcomes (systematic shifts after edits) that are presented as falsifiable via controls and measurements, not as a tautological renaming or self-referential fit. Self-citations, if present, are not load-bearing for the uniqueness or validity of the intervention results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation vectors paired with a graded target variable contain a recoverable low-dimensional direction that supports valid counterfactual edits.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. 2023. LEACE : Perfect linear concept erasure in closed form. Advances in Neural Information Processing Systems, 36:66044--66063
2023
-
[4]
Hartsuiker
Sarah Bernolet and Robert J. Hartsuiker. 2010. Does verb bias modulate syntactic priming? Cognition, 114(3):455--461
2010
-
[5]
Kathryn Bock
J. Kathryn Bock. 1986. Syntactic persistence in language production. Cognitive Psychology, 18(3):355--387
1986
-
[6]
Sasha Boguraev, Christopher Potts, and Kyle Mahowald. 2025. Causal Interventions Reveal Shared Structure Across English Filler - Gap Constructions . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25032--25053
2025
-
[7]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. Language models are few-shot learner...
2020
-
[8]
Dell, and J
Franklin Chang, Gary S. Dell, and J. Kathryn Bock. 2006. Becoming syntactic. Psychological Review, 113(2):234
2006
-
[9]
Yanda Chen, Chen Zhao, Zhou Yu, Kathleen McKeown, and He He. 2024. https://doi.org/10.18653/v1/2024.acl-long.465 Parallel Structures in Pre -training Data Yield In - Context Learning . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8582--8592, Bangkok, Thailand. Association for Com...
-
[10]
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. 2023. Why can GPT Learn In - Context ? language Models Implicitly Perform Gradient Descent as Meta - Optimizers . In ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models
2023
-
[11]
Benoit Dherin, Michael Munn, Hanna Mazzawi, Michael Wunder, and Javier Gonzalvo. 2025. Learning without training: The implicit dynamics of in-context learning. arXiv preprint arXiv:2507.16003
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. 2021. Causal abstractions of neural networks. Advances in neural information processing systems, 34:9574--9586
2021
-
[14]
Sophie Hao and Tal Linzen. 2023. Verb conjugation in transformers is determined by linear encodings of subject number. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4531--4539
2023
-
[15]
Robert Hawkins, Takateru Yamakoshi, Thomas Griffiths, and Adele Goldberg. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.376 Investigating representations of verb bias in neural language models . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4653--4663, Online. Association for Computational Linguistics
-
[16]
Roee Hendel, Mor Geva, and Amir Globerson. 2023. In-context learning creates task vectors. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 9318--9333
2023
-
[17]
Florian Jaeger and Neal Snider
T. Florian Jaeger and Neal Snider. 2008. Implicit learning and syntactic persistence: Surprisal and cumulativity. In Proceedings of the 30th Annual Conference of the Cognitive Science Society, volume 827812. Cognitive Science Society Austin, TX
2008
-
[18]
Florian Jaeger and Neal E
T. Florian Jaeger and Neal E. Snider. 2013. Alignment as a consequence of expectation adaptation: Syntactic priming is affected by the prime’s prediction error given both prior and recent experience. Cognition, 127(1):57--83
2013
-
[19]
Kaschak, Timothy J
Michael P. Kaschak, Timothy J. Kutta, and John L. Jones. 2011. Structural priming as implicit learning: Cumulative priming effects and individual differences. Psychonomic Bulletin & Review, 18:1133--1139
2011
-
[20]
Michael A Lepori, Tal Linzen, Ann Yuan, and Katja Filippova. 2026. Language Models Struggle to Use Representations Learned In - Context . arXiv preprint arXiv:2602.04212
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiuding Sun, and 1 others. 2024. The quest for the right mediator: A history, survey, and theoretical grounding of causal interpretability. arXiv preprint arXiv:2408.01416
-
[22]
Satoru Ozaki, Rajesh Bhatt, and Brian Dillon. 2025. A LSTM language model learns Hindi - Urdu case-agreement interactions, and has a linear encoding of case. Society for Computation in Linguistics, 8(1)
2025
-
[23]
Pickering and Holly P
Martin J. Pickering and Holly P. Branigan. 1998. The representation of verbs: Evidence from syntactic priming in language production. Journal of Memory and Language, 39(4):633--651
1998
-
[24]
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. 2020. Null it out: Guarding protected attributes by iterative nullspace projection. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 7237--7256
2020
-
[25]
Shauli Ravfogel, Grusha Prasad, Tal Linzen, and Yoav Goldberg. 2021. Counterfactual interventions reveal the causal effect of relative clause representations on agreement prediction. In Proceedings of the 25th Conference on Computational Natural Language Learning, pages 194--209
2021
-
[26]
Arabella Sinclair, Jaap Jumelet, Willem Zuidema, and Raquel Fern \'a ndez. 2022. Structural persistence in language models: Priming as a window into abstract language representations. Transactions of the Association for Computational Linguistics, 10:1031--1050
2022
-
[27]
Wei Tang, Xinyan Jiang, Fakhri Karray, and Lijie Hu. 2026. In- Context Learning Operates as Concept Subspace Learning . arXiv preprint arXiv:2605.18830
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Eric Todd, Millicent Li, Arnab Sen Sharma, Aaron Mueller, Byron Wallace, and David Bau. 2024. Function vectors in large language models. In International conference on learning representations, volume 2024, pages 17282--17333
2024
-
[29]
Tooley and Matthew J
Kristen M. Tooley and Matthew J. Traxler. 2010. Syntactic priming effects in comprehension: A critical review. Language and Linguistics Compass, 4(10):925--937
2010
-
[30]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, and 49 others. 2023. https://arxiv.org/abs/2307.09288 Llama 2: Open Fo...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, Joao Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. 2023. Transformers Learn In - Context by Gradient Descent . In Proc. MLR, volume 202, pages 35151--35174. PMLR
2023
-
[32]
An Explanation of In-context Learning as Implicit Bayesian Inference
Sang Michael Xie, Aditi Raghunathan, Percy S. Liang, and Tengyu Ma. 2021. An explanation of in-context learning as implicit bayesian inference. arXiv:2111.02080
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Zhenghao Zhou, Robert Frank, and R. Thomas McCoy. 2025. https://doi.org/10.18653/v1/2025.naacl-long.586 Is In - Context Learning a Type of Error - Driven Learning ? Evidence from the Inverse Frequency Effect in Structural Priming . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.