Test Time Training for Supervised Causal Learning
Pith reviewed 2026-06-29 08:19 UTC · model grok-4.3
The pith
Dynamically generating test-aligned training sets resolves the generalization failures of supervised causal learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Test-Time Training for Supervised Causal Learning dynamically generates training sets explicitly aligned with any specific test instance via an efficient scoring function module, overcoming the out-of-distribution generalization challenges that limit prior supervised causal learning practices and producing superior performance compared with existing SCL and traditional causal discovery methods.
What carries the argument
The scoring function module that dynamically generates training sets aligned with the test instance.
If this is right
- TTT-SCL significantly outperforms existing SCL methods on synthetic benchmarks.
- TTT-SCL demonstrates improved robustness on pseudo-real and real-world datasets affected by distribution shifts.
- TTT-SCL succeeds at compositional generalization tasks where prior SCL approaches fail.
- TTT-SCL surpasses traditional causal discovery methods across the tested datasets.
Where Pith is reading between the lines
- The same test-time alignment strategy could be tested on other supervised learning problems that suffer from distribution shift.
- The explicit link drawn to score-based methods opens the possibility of hybrid models that use both supervised predictors and scoring functions.
- Practical deployment would depend on whether the scoring module remains computationally light as the number of variables grows.
Load-bearing premise
Dynamically generating training sets explicitly aligned with any specific test instance via a scoring function module will resolve the performance gap, fragility to shifts, and compositional failure of prior supervised causal learning.
What would settle it
Experiments on the same real-world datasets showing no significant outperformance by TTT-SCL over baseline supervised causal learning methods would falsify the central claim.
Figures

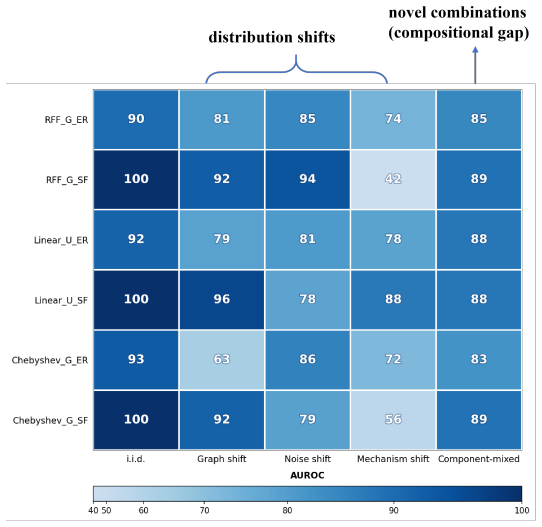
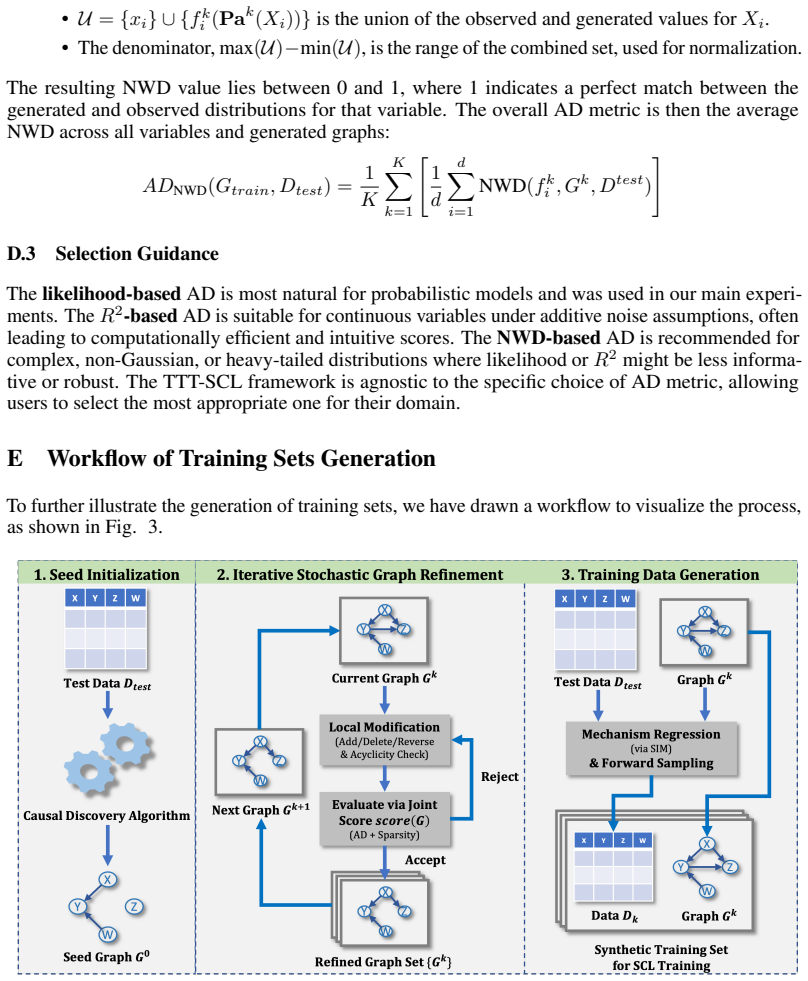
read the original abstract
Supervised Causal Learning (SCL) has shown promise in causal discovery by framing it as a supervised learning problem. However, it suffers from significant out-of-distribution generalization challenges. We reveal three limitations of previous SCL practices: a significant performance gap between synthetic benchmarks and real-world data, fragility to distribution shifts, and failure in compositional generalization, collectively questioning its real-world applicability. To address this, we propose Test-Time Training for Supervised Causal Learning (TTT-SCL), a novel framework that dynamically generates training sets explicitly aligned with any specific test instance. We demonstrate the correlation between TTT-SCL and score-based methods, and design an efficient module for generating training sets based on the classic scoring function. Experiments on synthetic benchmarks, pseudo-real and real-world datasets demonstrate that TTT-SCL significantly outperforms existing SCL and traditional causal discovery methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies three limitations of prior supervised causal learning (SCL) approaches—performance gaps between synthetic benchmarks and real-world data, fragility to distribution shifts, and failure in compositional generalization—and proposes Test-Time Training for Supervised Causal Learning (TTT-SCL). TTT-SCL dynamically generates training sets aligned with each test instance via an efficient module based on classic scoring functions, notes a correlation with score-based causal discovery, and reports significant outperformance over existing SCL and traditional methods on synthetic, pseudo-real, and real-world datasets.
Significance. If the central claims hold, TTT-SCL would meaningfully advance the practical utility of supervised causal discovery by addressing out-of-distribution challenges through test-time adaptation, potentially making SCL competitive with score-based methods on real data where prior supervised approaches have underperformed.
major comments (1)
- [Abstract] Abstract: The assertion that the scoring-function module resolves compositional generalization failure (one of the three load-bearing limitations) lacks a described mechanism; classic scoring functions evaluate a fixed graph on observed data and do not inherently generate training distributions containing novel combinations of causal mechanisms. Without explicit construction of such unseen compositions, outperformance on the reported benchmarks does not establish resolution of this limitation.
minor comments (1)
- [Abstract] Abstract: The description of the 'efficient module' and its correlation with score-based methods would benefit from at least one equation or algorithmic outline to clarify whether the alignment step remains independent of fitted quantities.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying this point regarding the abstract. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the scoring-function module resolves compositional generalization failure (one of the three load-bearing limitations) lacks a described mechanism; classic scoring functions evaluate a fixed graph on observed data and do not inherently generate training distributions containing novel combinations of causal mechanisms. Without explicit construction of such unseen compositions, outperformance on the reported benchmarks does not establish resolution of this limitation.
Authors: We appreciate this observation. TTT-SCL employs the scoring-function module to dynamically generate training sets aligned with each test instance rather than relying on a static pre-training distribution. The module leverages the scoring function to evaluate candidate structures and construct or select data that matches the observed test statistics, thereby producing training examples whose causal mechanisms reflect those in the test case. This alignment enables the supervised learner to encounter and adapt to novel combinations of mechanisms that were absent from the original synthetic training data, which is the intended mechanism for addressing compositional generalization. The noted correlation with score-based causal discovery further motivates this design, as scoring functions can surface structures beyond those explicitly enumerated in fixed training sets. That said, we agree the abstract would be strengthened by a clearer statement of this mechanism. We will revise the abstract to qualify the claim and add an explicit paragraph in the methods section describing how the generation process constructs test-aligned distributions that can contain unseen compositions. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper proposes TTT-SCL as a new framework that dynamically generates test-aligned training sets via a scoring-function module and reports empirical gains on benchmarks. The abstract and available text describe the approach, its correlation to score-based methods, and experimental results without any derivation chain, equations, or claims that reduce a result to its own fitted inputs or self-citations by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear. The central claims rest on the proposed module and reported performance rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scale-free networks: a decade and beyond.science, 325(5939):412– 413, 2009
Albert-László Barabási. Scale-free networks: a decade and beyond.science, 325(5939):412– 413, 2009
2009
-
[2]
Huang, Christopher Robinson, Jeremy Reffin, Sema K
Bradley Butcher, Vincent S. Huang, Christopher Robinson, Jeremy Reffin, Sema K. Sgaier, Grace Charles, and Novi Quadrianto. Causal datasheet for datasets: An evaluation guide for real-world data analysis and data collection design using bayesian networks.Frontiers in Artificial Intelligence, V olume 4 - 2021, 2021
2021
-
[3]
Wei Chen, Rui Ding, Bojun Huang, Yang Zhang, Qiang Fu, Yuxuan Liang, Han Shi, and Dongmei Zhang. Test-time learning of causal structure from interventional data.arXiv preprint arXiv:2602.19131, 2026
-
[4]
Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
2002
-
[5]
Ml4c: Seeing causality through latent vicinity
Haoyue Dai, Rui Ding, Yuanyuan Jiang, Shi Han, and Dongmei Zhang. Ml4c: Seeing causality through latent vicinity. InProceedings of the 2023 SIAM International Conference on Data Mining (SDM), pages 226–234. SIAM, 2023
2023
-
[6]
Graph structure inference with bam: neural dependency processing via bilinear attention
Philipp Froehlich and Heinz Koeppl. Graph structure inference with bam: neural dependency processing via bilinear attention. InProceedings of the 38th International Conference on Neural Information Processing Systems, pages 128847–128885, 2024
2024
-
[7]
Random graphs.The Annals of Mathematical Statistics, 30(4):1141–1144, 1959
Edgar N Gilbert. Random graphs.The Annals of Mathematical Statistics, 30(4):1141–1144, 1959
1959
-
[8]
Hoyer, Dominik Janzing, Joris Mooij, Jonas Peters, and Bernhard Schölkopf
Patrik O. Hoyer, Dominik Janzing, Joris Mooij, Jonas Peters, and Bernhard Schölkopf. Non- linear causal discovery with additive noise models. InProceedings of the 22nd International Conference on Neural Information Processing Systems, page 689–696, 2008
2008
-
[9]
Learning to induce causal structure.arXiv preprint arXiv:2204.04875, 2022
Nan Rosemary Ke, Silvia Chiappa, Jane Wang, Anirudh Goyal, Jorg Bornschein, Melanie Rey, Theophane Weber, Matthew Botvinic, Michael Mozer, and Danilo Jimenez Rezende. Learning to induce causal structure.arXiv preprint arXiv:2204.04875, 2022. 10
-
[10]
Gradient- based neural dag learning
Sébastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient- based neural dag learning. InInternational Conference on Learning Representations, 2020
2020
-
[11]
A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025
2025
-
[12]
Yuejiang Liu, Parth Kothari, Bastien van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. Ttt++: when does self-supervised test-time training fail or thrive? In Proceedings of the 35th International Conference on Neural Information Processing Systems, pages 21808–21820, 2021
2021
-
[13]
Amortized inference for causal structure learning
Lars Lorch, Scott Sussex, Jonas Rothfuss, Andreas Krause, and Bernhard Schölkopf. Amortized inference for causal structure learning. InProceedings of the 36th International Conference on Neural Information Processing Systems, pages 13104 – 13118, 2022
2022
-
[14]
Ml4s: Learning causal skeleton from vicinal graphs
Pingchuan Ma, Rui Ding, Haoyue Dai, Yuanyuan Jiang, Shuai Wang, Shi Han, and Dongmei Zhang. Ml4s: Learning causal skeleton from vicinal graphs. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1213–1223, 2022
2022
-
[15]
De- mystifying amortized causal discovery with transformers.arXiv preprint arXiv:2405.16924, 2024
Francesco Montagna, Max Cairney-Leeming, Dhanya Sridhar, and Francesco Locatello. De- mystifying amortized causal discovery with transformers.arXiv preprint arXiv:2405.16924, 2024
-
[16]
Causal discovery with score matching on additive models with arbitrary noise
Francesco Montagna, Nicoletta Noceti, Lorenzo Rosasco, Kun Zhang, and Francesco Locatello. Causal discovery with score matching on additive models with arbitrary noise. InConference on Causal Learning and Reasoning, pages 726–751. PMLR, 2023
2023
-
[17]
Cambridge university press, 2009
Judea Pearl.Causality. Cambridge university press, 2009
2009
-
[18]
The MIT press, 2017
Jonas Peters, Dominik Janzing, and Bernhard Schölkopf.Elements of causal inference: founda- tions and learning algorithms. The MIT press, 2017
2017
-
[19]
Causal discovery with continuous additive noise models.The Journal of Machine Learning Research, 15(1):2009– 2053, 2014
Jonas Peters, Joris M Mooij, Dominik Janzing, and Bernhard Schölkopf. Causal discovery with continuous additive noise models.The Journal of Machine Learning Research, 15(1):2009– 2053, 2014
2009
-
[20]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InPro- ceedings of the 21st International Conference on Neural Information Processing Systems, page 1177–1184, 2007
2007
-
[21]
Score matching enables causal discovery of nonlinear additive noise models
Paul Rolland, V olkan Cevher, Matthäus Kleindessner, Chris Russell, Dominik Janzing, Bernhard Schölkopf, and Francesco Locatello. Score matching enables causal discovery of nonlinear additive noise models. InInternational Conference on Machine Learning, pages 18741–18753. PMLR, 2022
2022
-
[22]
Lauffenburger, and Garry P
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A. Lauffenburger, and Garry P. Nolan. Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721):523–529, 2005
2005
-
[23]
A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
Shohei Shimizu, Patrik O Hoyer, Aapo Hyvärinen, Antti Kerminen, and Michael Jordan. A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
2006
-
[24]
Test: Test-time self- training under distribution shift
Samarth Sinha, Peter Gehler, Francesco Locatello, and Bernt Schiele. Test: Test-time self- training under distribution shift. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2759–2769, 2023
2023
-
[25]
MIT press, 2000
Peter Spirtes, Clark N Glymour, and Richard Scheines.Causation, prediction, and search. MIT press, 2000
2000
-
[26]
Test-time training with self-supervision for generalization under distribution shifts
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, and Moritz Hardt. Test-time training with self-supervision for generalization under distribution shifts. InInternational conference on machine learning, pages 9229–9248. PMLR, 2020. 11
2020
-
[27]
Syntren: a generator of synthetic gene expression data for design and analysis of structure learning algorithms.BMC bioinformatics, 7(1):43, 2006
Tim Van den Bulcke, Koenraad Van Leemput, Bart Naudts, Piet van Remortel, Hongwu Ma, Alain Verschoren, Bart De Moor, and Kathleen Marchal. Syntren: a generator of synthetic gene expression data for design and analysis of structure learning algorithms.BMC bioinformatics, 7(1):43, 2006
2006
-
[28]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[29]
Dag-gnn: Dag structure learning with graph neural networks
Yue Yu, Jie Chen, Tian Gao, and Mo Yu. Dag-gnn: Dag structure learning with graph neural networks. InInternational conference on machine learning, pages 7154–7163. PMLR, 2019
2019
-
[30]
Learning to Discover at Test Time
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time. arXiv preprint arXiv:2601.16175, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Learning identifiable structures avoids bias in DNN-based supervised causal learning
Jiaru Zhang, Rui Ding, Qiang Fu, Huang Bojun, zizhen Deng, Yang Hua, Haibing Guan, Shi Han, and Dongmei Zhang. Learning identifiable structures avoids bias in DNN-based supervised causal learning. InThe 28th International Conference on Artificial Intelligence and Statistics, 2025
2025
-
[32]
On the identifiability of the post-nonlinear causal model
Kun Zhang and Aapo Hyvärinen. On the identifiability of the post-nonlinear causal model. UAI ’09, page 647–655, Arlington, Virginia, USA, 2009. AUAI Press
2009
-
[33]
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing. Dags with no tears: continuous optimization for structure learning. InProceedings of the 32nd International Conference on Neural Information Processing Systems, page 9492–9503, 2018. A Detailed configuration A.1 Setting of static training data For all static SCL training setups evaluated(includ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.