Latent Performance Profiling of Large Language Models
Pith reviewed 2026-06-29 07:28 UTC · model grok-4.3
The pith
Latent Performance Profiling extracts task-agnostic signatures from LLM hidden activations and output distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
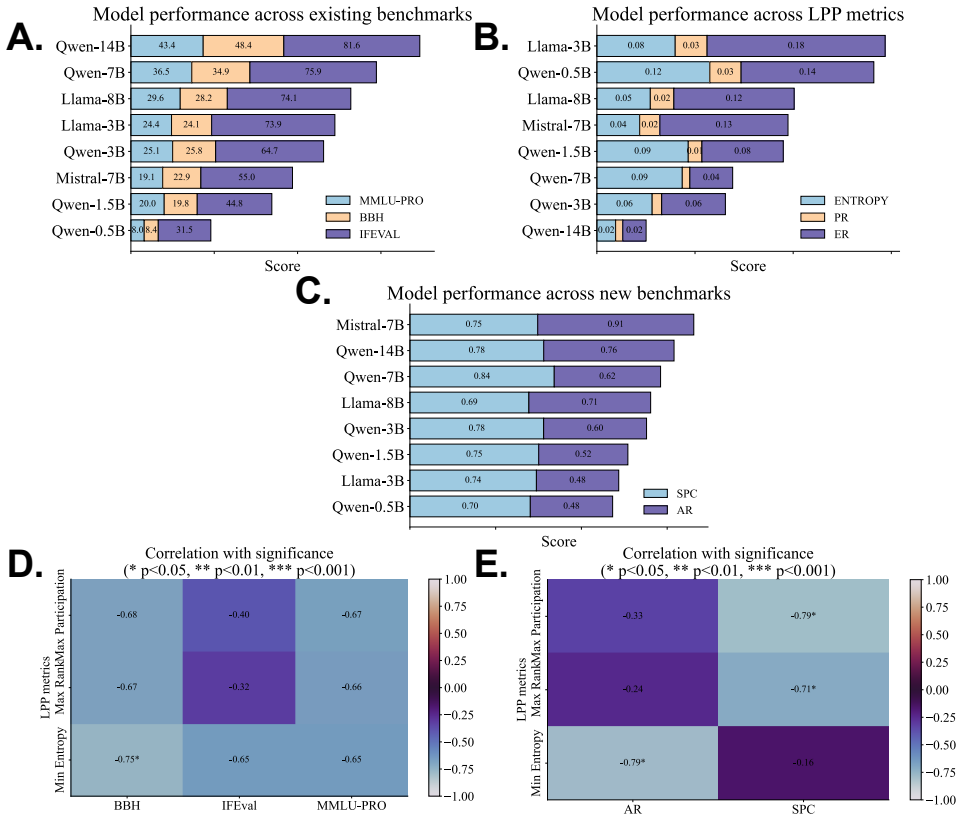
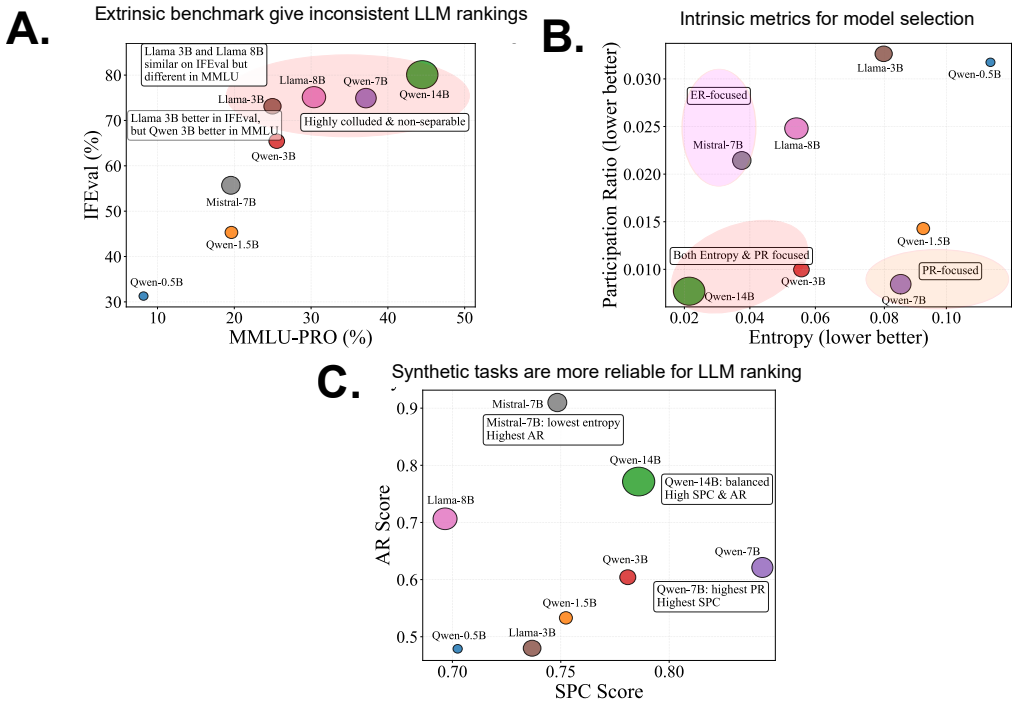
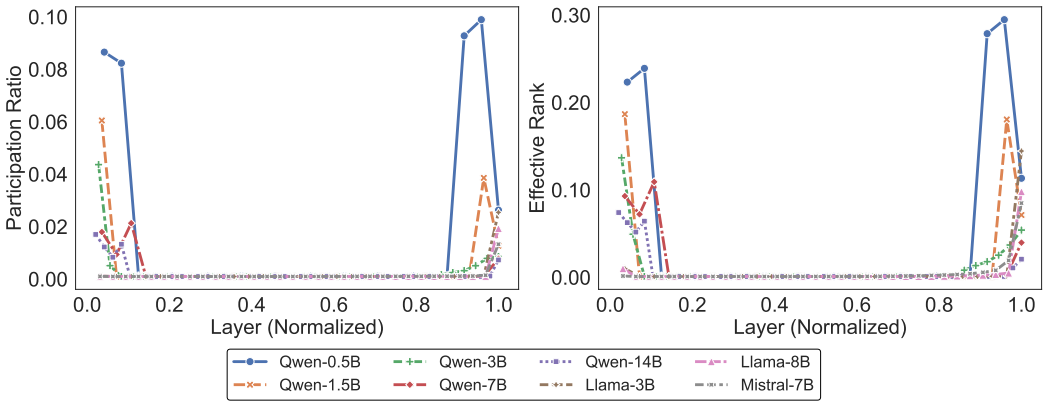
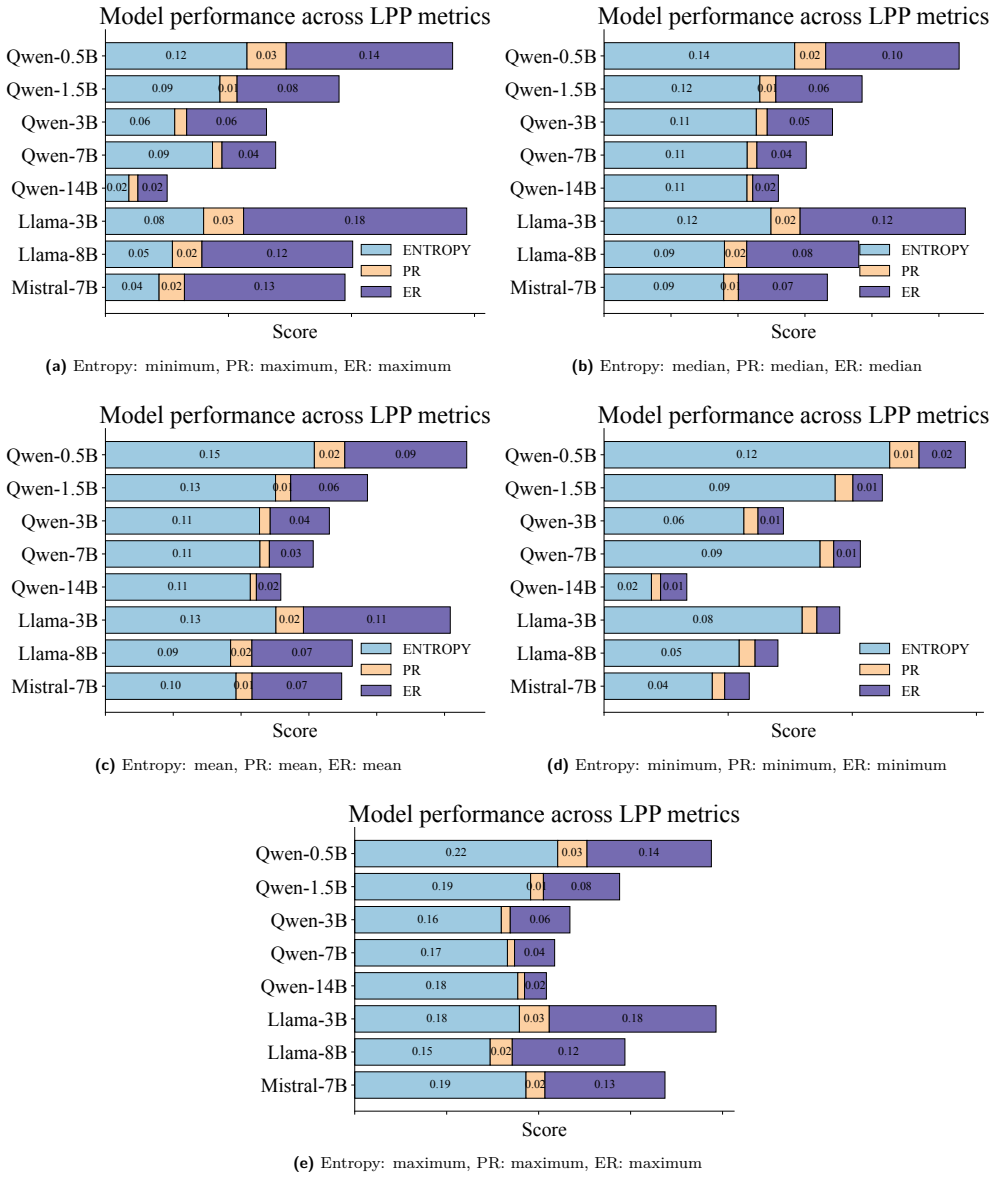
LPP defines a set of scalar metrics on a model's latent representations and dynamics, revealing scale-independent traits that enable interpretable comparisons and uncover hidden vulnerabilities. Unlike static accuracy scores, LPP provides stable, architecture-sensitive signatures across models of similar size. With extensive empirical analyses across eight LLMs, spanning a size range of 0.5B-14B, models with similar benchmark scores can exhibit contrasting latent profiles, such as differences in entropy or adaptability.
What carries the argument
Latent Performance Profiling (LPP), a framework that derives task-agnostic scalar metrics from hidden activations and output distributions to characterize latent representations and dynamics.
If this is right
- Models posting similar benchmark scores can still be separated by their latent profiles in entropy or adaptability.
- Synthetic probes for uncertainty and symbolic reasoning can be constructed to match LPP metrics while remaining decoupled from leaderboard data.
- Reporting LPP values together with benchmark scores supplies a deeper basis for model selection and safety assessment.
Where Pith is reading between the lines
- LPP signatures might indicate how a model will behave on entirely new tasks outside current benchmarks.
- The approach could help flag internal inconsistencies that signal data contamination even when benchmark accuracy appears high.
- Characteristic LPP patterns tied to model families might guide selection for deployment contexts where adaptability or calibrated uncertainty matters most.
Load-bearing premise
Metrics taken from hidden activations and output distributions are task-agnostic and capture meaningful scale-independent traits that remain independent of benchmark performance and data contamination.
What would settle it
Finding that the same model produces substantially different LPP metric values when tested on varied but semantically related tasks, or that LPP differences fail to predict outcomes on new synthetic probes for uncertainty and symbolic reasoning.
Figures




read the original abstract
Large language models (LLMs) frequently achieve impressive scores on standardized benchmarks, yet accuracy alone offers a limited view of their capabilities. Evaluating open-source LLMs through leaderboards faces persistent issues like data contamination, narrow task scope, and weak alignment with real-world reliability. Benchmark-based evaluations such as MMLU PRO, BBH, or IFEval primarily capture what a model outputs on fixed test sets, not how it processes information, calibrates uncertainty, or structures internal knowledge. In this article, we advocate for a shift from benchmark-centric evaluation toward a complementary, state-centered intrinsic assessment of LLMs. To this end, we introduce Latent Performance Profiling (LPP) -- a framework that derives task-agnostic diagnostics from hidden activations and output distributions. LPP defines a set of scalar metrics on a model's latent representations and dynamics, revealing scale-independent traits that enable interpretable comparisons and uncover hidden vulnerabilities. Unlike static accuracy scores, LPP provides stable, architecture-sensitive signatures across models of similar size. With extensive empirical analyses across eight LLMs, spanning a size range of 0.5B-14B, we demonstrate that models with similar benchmark scores can exhibit contrasting latent profiles, such as differences in entropy or adaptability. Guided by these insights, we design synthetic probes for uncertainty and symbolic reasoning that align with intrinsic metrics while decoupling from leaderboard bias. We recommend that reporting LPP alongside benchmarks provides a deeper, interpretable understanding of model behavior, enabling more reliable model selection, safety assessment, and evaluation beyond surface-level accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Latent Performance Profiling (LPP), a framework deriving task-agnostic scalar metrics (e.g., entropy, adaptability) from LLMs' hidden activations and output distributions. It positions LPP as complementary to benchmarks, claiming these metrics yield stable, architecture-sensitive, scale-independent signatures. Empirical results across eight models (0.5B–14B parameters) are said to show that models with similar benchmark scores can have contrasting latent profiles, and the work proposes synthetic probes for uncertainty and symbolic reasoning aligned with the intrinsic metrics.
Significance. If the LPP metrics can be shown to be robustly task-agnostic and independent of input choice and benchmark contamination, the approach would offer a valuable intrinsic complement to leaderboard evaluations, enabling better detection of hidden vulnerabilities and more reliable model selection. The reported ability to distinguish models with matched benchmark performance via latent signatures would be a concrete strength if empirically substantiated.
major comments (1)
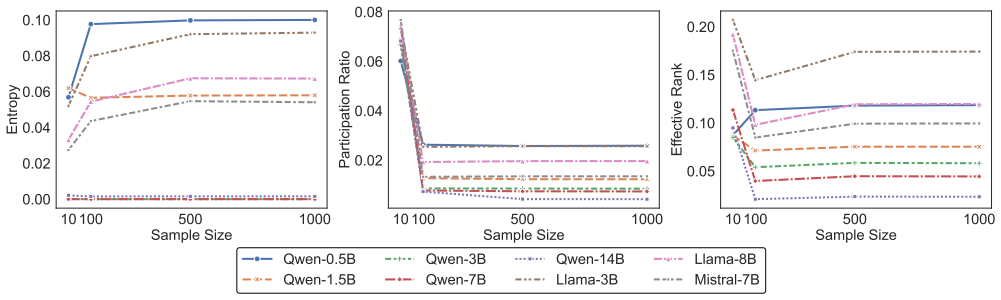
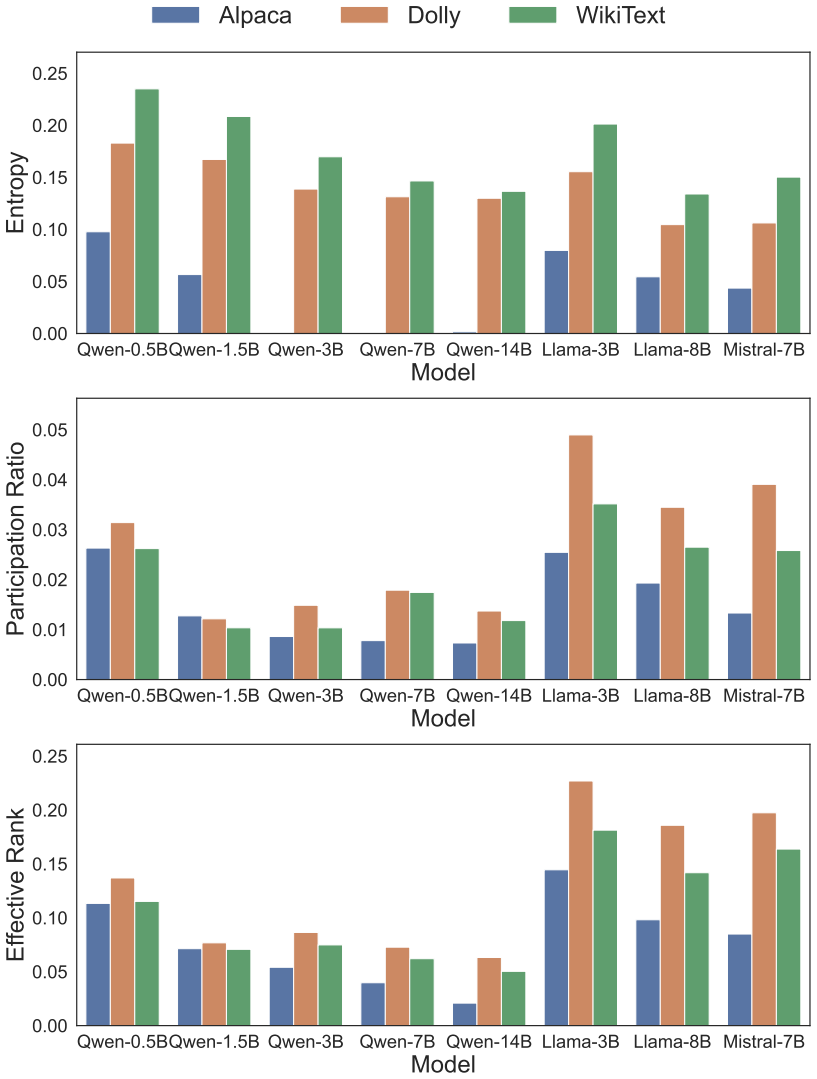
- [Abstract] Abstract: the central claim that LPP metrics are task-agnostic and reveal intrinsic, scale-independent traits independent of benchmarks rests on the unverified assumption that the derived scalars remain stable under different input regimes. Because any activation-based metric requires feeding the model some distribution of inputs, the absence of any description of input sampling, variation across regimes, or invariance tests means the signatures could be artifacts of the chosen inputs rather than intrinsic properties; this directly undermines the asserted contrast with benchmark-centric evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address the concern regarding input sampling and invariance below, and will revise the manuscript to strengthen the presentation of the task-agnostic claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that LPP metrics are task-agnostic and reveal intrinsic, scale-independent traits independent of benchmarks rests on the unverified assumption that the derived scalars remain stable under different input regimes. Because any activation-based metric requires feeding the model some distribution of inputs, the absence of any description of input sampling, variation across regimes, or invariance tests means the signatures could be artifacts of the chosen inputs rather than intrinsic properties; this directly undermines the asserted contrast with benchmark-centric evaluation.
Authors: We agree that the absence of explicit details on input sampling and invariance testing in the abstract (and methods) leaves the task-agnostic claim open to the interpretation raised. The current manuscript does not report variation across input regimes or formal invariance tests. In the revised version we will add a dedicated subsection describing the input distribution used for activation collection and include new experiments that quantify metric stability under altered input regimes (for example, domain-restricted prompt sets). These changes will directly substantiate the intrinsic nature of the signatures. revision: yes
Circularity Check
No circularity: LPP introduced as empirical framework without self-referential definitions or fitted predictions
full rationale
The provided abstract and description present LPP as a new set of scalar metrics extracted from hidden activations and output distributions, with claims of task-agnosticism and scale-independence supported by empirical analyses across models. No equations, parameter-fitting steps, or self-citations are shown that would reduce any metric to its own inputs by construction. The derivation chain consists of proposing diagnostics and demonstrating contrasts with benchmarks, remaining self-contained as an observational proposal rather than a closed definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden activations and output distributions contain task-agnostic information about model capabilities and vulnerabilities
invented entities (1)
-
Latent Performance Profiling (LPP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Y., Gulamali, F., and Joshi, S
Agrawal, M., Chen, I. Y., Gulamali, F., and Joshi, S. (2025). The evaluation illusion of large language models in medicine. npj Digital Medicine , 8(1):600
2025
- [2]
- [3]
-
[4]
and Gavves, S
Bereska, L. and Gavves, S. (2024). Mechanistic interpretability for AI safety - a review. Transactions on Machine Learning Research , pages 1--55
2024
-
[5]
A., MacKnight, R., Kline, B., and Gomes, G
Boiko, D. A., MacKnight, R., Kline, B., and Gomes, G. (2023). Autonomous chemical research with large language models. Nature , 624(7992):570--578
2023
-
[6]
Carranza, J. M. N. (2025). LLM s show surface-form brittleness under paraphrase stress tests. In NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , pages 1--5
2025
-
[7]
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., Chen, H., Yi, X., Wang, C., Wang, Y., et al. (2024). A survey on evaluation of large language models. ACM transactions on intelligent systems and technology , 15(3):1--45
2024
-
[8]
Chen, M. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. (2021). Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Conover, M., Hayes, M., Mathur, A., Xie, J., Wan, J., Shah, S., Ghodsi, A., Wendell, P., Zaharia, M., and Xin, R. (2023). Free dolly: Introducing the world's first truly open instruction-tuned llm
2023
-
[11]
F., Lan, Q., Rahman, P., Mahmood, A
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. (2024). Loss of plasticity in deep continual learning. Nature , 632(8026):768--774
2024
-
[12]
Dreyer, M., Berend, J., Labarta, T., Vielhaben, J., Wiegand, T., Lapuschkin, S., and Samek, W. (2025). Mechanistic understanding and validation of large AI models with SemanticLens . Nature Machine Intelligence , 7(9):1572--1585
2025
-
[13]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. (2024). The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Farquhar, S., Kossen, J., Kuhn, L., and Gal, Y. (2024). Detecting hallucinations in large language models using semantic entropy. Nature , 630(8017):625--630
2024
- [15]
-
[16]
Fourrier, C., Habib, N., Lozovskaya, A., Szafer, K., and Wolf, T. (2024). Open llm leaderboard v2
2024
-
[17]
Gilardi, F., Alizadeh, M., and Kubli, M. (2023). Chatgpt outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences , 120(30):e2305016120
2023
-
[18]
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. (2017). On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 , ICML'17, pages 1321--1330. JMLR.org
2017
-
[19]
Guo, J., Gu, S., Jin, M., Spanos, C., and Lavaei, J. (2025). Stylebench: Evaluating thinking styles in large language models. arXiv preprint arXiv:2509.20868
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
-
[21]
A., and Gal, Y
Han, J., Kossen, J., Razzak, M., Schut, L., Malik, S. A., and Gal, Y. (2024). Semantic entropy probes: Robust and cheap hallucination detection in llms. In ICML 2024 Workshop on Foundation Models in the Wild
2024
-
[22]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. (2021). Measuring massive multitask language understanding. In International Conference on Learning Representations , pages 1--27
2021
-
[23]
Hernandez, D., Kaplan, J., Henighan, T., and McCandlish, S. (2021). Scaling laws for transfer. arXiv preprint arXiv:2102.01293
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Jha, N. K. and Reagen, B. (2025). Spectral scaling laws in language models: emph How Effectively Do Feed-Forward Networks Use Their Latent Space? In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V., editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 35047--35058, Suzhou, China. Associatio...
2025
-
[25]
Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. (2023). Mistral 7b
2023
-
[26]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. (2024). Mixtral of experts. arXiv preprint arXiv:2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [28]
-
[29]
D., Re, C., Acosta-Navas, D., Hudson, D
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., Newman, B., Yuan, B., Yan, B., Zhang, C., Cosgrove, C., Manning, C. D., Re, C., Acosta-Navas, D., Hudson, D. A., Zelikman, E., Durmus, E., Ladhak, F., Rong, F., Ren, H., Yao, H., WANG, J., Santhanam, K., Orr, L., Zheng, L., Yuksekgonul, M....
2023
-
[30]
Y., Deng, Y., Chandu, K., Ravichander, A., Pyatkin, V., Dziri, N., Bras, R
Lin, B. Y., Deng, Y., Chandu, K., Ravichander, A., Pyatkin, V., Dziri, N., Bras, R. L., and Choi, Y. (2025). Wildbench: Benchmarking LLM s with challenging tasks from real users in the wild. In The Thirteenth International Conference on Learning Representations , pages 1--19
2025
-
[31]
Lin, S., Hilton, J., and Evans, O. (2022). T ruthful QA : Measuring how models mimic human falsehoods. In Muresan, S., Nakov, P., and Villavicencio, A., editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
2022
-
[32]
Merity, S., Xiong, C., Bradbury, J., and Socher, R. (2017). Pointer sentinel mixture models. In International Conference on Learning Representations , pages 1--15
2017
-
[33]
Meta, A. (2025). The llama 4 herd: The beginning of a new era of natively multimodal ai innovation. https://ai. meta. com/blog/llama-4-multimodal-intelligence/, checked on , 4(7):2025
2025
-
[34]
A., and Leonelli, S
Milano, S., McGrane, J. A., and Leonelli, S. (2023). Large language models challenge the future of higher education. Nature Machine Intelligence , 5(4):333--334
2023
-
[35]
and Krishnan, N
Miret, S. and Krishnan, N. M. A. (2025). Enabling large language models for real-world materials discovery. Nature Machine Intelligence , 7(7):991--998
2025
-
[36]
Muralidharan, S., Turuvekere Sreenivas, S., Joshi, R., Chochowski, M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz, J., and Molchanov, P. (2024). Compact language models via pruning and knowledge distillation. Advances in Neural Information Processing Systems , 37:41076--41102
2024
-
[37]
Ovadia, Y., Fertig, E., Ren, J., Nado, Z., Sculley, D., Nowozin, S., Dillon, J., Lakshminarayanan, B., and Snoek, J. (2019). Can you trust your model s uncertainty? evaluating predictive uncertainty under dataset shift. In Wallach, H., Larochelle, H., Beygelzimer, A., d Alch\' e -Buc, F., Fox, E., and Garnett, R., editors, Advances in Neural Information P...
2019
-
[38]
G., Mao, H., Yan, F., Ji, C
Patil, S. G., Mao, H., Yan, F., Ji, C. C.-J., Suresh, V., Stoica, I., and Gonzalez, J. E. (2025). The berkeley function calling leaderboard ( BFCL ): From tool use to agentic evaluation of large language models. In Forty-second International Conference on Machine Learning , pages 1--22
2025
-
[39]
L., and Agirre, E
Sainz, O., Campos, J., Garc \'i a-Ferrero, I., Etxaniz, J., de Lacalle, O. L., and Agirre, E. (2023). NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Bouamor, H., Pino, J., and Bali, K., editors, Findings of the Association for Computational Linguistics: EMNLP 2023 , pages 10776--10787, Singapore. Associatio...
2023
-
[40]
Sharma, A. and Chopra, P. (2025). Think just enough: Sequence-level entropy as a confidence signal for llm reasoning. arXiv preprint arXiv:2510.08146
-
[41]
R., Zhao, D., Patel, N
Skean, O., Arefin, M. R., Zhao, D., Patel, N. N., Naghiyev, J., LeCun, Y., and Shwartz-Ziv, R. (2025). Layer by layer: Uncovering hidden representations in language models. In Forty-second International Conference on Machine Learning , pages 1--22
2025
-
[42]
Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., Brown, A. R., Santoro, A., Gupta, A., Garriga-Alonso, A., Kluska, A., Lewkowycz, A., Agarwal, A., Power, A., Ray, A., Warstadt, A., Kocurek, A. W., Safaya, A., Tazarv, A., Xiang, A., Parrish, A., Nie, A., Hussain, A., Askell, A., Dsouza, A., Slone, A., Rahane, A., Iyer, A. S., And...
2023
-
[43]
W., and Smyth, P
Steyvers, M., Tejeda, H., Kumar, A., Belem, C., Karny, S., Hu, X., Mayer, L. W., and Smyth, P. (2025). What large language models know and what people think they know. Nature Machine Intelligence , 7(2):221--231
2025
-
[44]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. (2023). Stanford alpaca: An instruction-following llama model. GitHub repository
2023
-
[45]
Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang, K., Zhuang, A., Fan, R., Yue, X., and Chen, W. (2024). Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C., ed...
2024
-
[46]
Wei, L., Tan, Z., Li, C., Wang, J., and Huang, W. (2024). Diff-erank: A novel rank-based metric for evaluating large language models. Advances in Neural Information Processing Systems , 37:39501--39521
2024
-
[47]
R., and Kulik, H
Xin, H., Kitchin, J. R., and Kulik, H. J. (2025). Towards agentic science for advancing scientific discovery. Nature Machine Intelligence , 7(9):1373--1375
2025
-
[48]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Zhao, Q., Huang, Y., Lv, T., Cui, L., Sun, Q., Mao, S., Zhang, X., Xin, Y., Yin, Q., Li, S., and Wei, F. (2025). MMLU - CF : A contamination-free multi-task language understanding benchmark. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T., editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1:...
2025
-
[50]
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., and Hou, L. (2023). Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Zhou, L., Schellaert, W., Martínez-Plumed, F., Moros-Daval, Y., Ferri, C., and Hernández-Orallo, J. (2024). Larger and more instructable language models become less reliable. Nature , 634(8032):61--68
2024
-
[52]
Zhuang, R., Wu, T., Wen, Z., Li, A., Jiao, J., and Ramchandran, K. (2025). Embed LLM : Learning compact representations of large language models. In The Thirteenth International Conference on Learning Representations , pages 1--14
2025
-
[53]
Y., Chien, V
Zhuo, T. Y., Chien, V. M., Chim, J., Hu, H., Yu, W., Widyasari, R., Yusuf, I. N. B., Zhan, H., He, J., Paul, I., Brunner, S., GONG, C., Hoang, J., Zebaze, A. R., Hong, X., Li, W.-D., Kaddour, J., Xu, M., Zhang, Z., Yadav, P., Jain, N., Gu, A., Cheng, Z., Liu, J., Liu, Q., Wang, Z., Lo, D., Hui, B., Muennighoff, N., Fried, D., Du, X., de Vries, H., and Wer...
2025
-
[54]
, " * write output.state after.block = add.period write newline
ENTRY address archive author booktitle chapter edition editor eprint howpublished institution journal key month note number organization pages publisher school series title type url doi volume year label INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 'after.sente...
-
[55]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.