Recovering Diversity Without Losing Alignment: A DPO Recipe for Post-Trained LLMs
Pith reviewed 2026-06-29 07:25 UTC · model grok-4.3
The pith
REDIPO is an offline DPO pipeline that recovers distinct valid answer modes from base models in post-trained LLMs without sacrificing alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REDIPO improves NoveltyBench distinct_k by 134%, 33%, and 44% on Qwen3-4B, OLMo-3-7B, and LLaMA-3.1-8B relative to instruct checkpoints, while maintaining MTBench, IFEval, and Arena-Hard performance and reducing HarmBench attack success rate, by using base-response rewriting and marginal-diversity pair selection in its DPO data pipeline.
What carries the argument
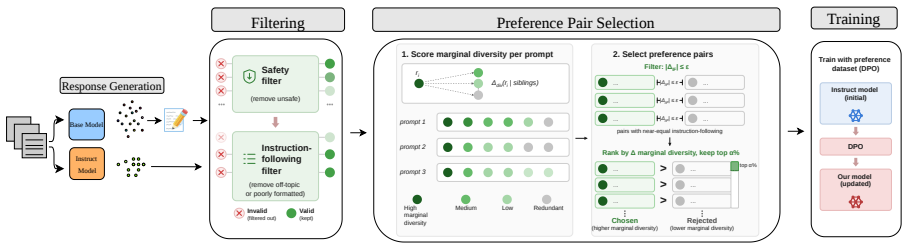
REDIPO pipeline: sampling from base and instruct models, rewriting base responses with instruct model, filtering candidates, and building preference pairs favoring marginally diverse responses among similar-quality ones.
If this is right
- REDIPO increases diversity metrics substantially compared to instruct models and to DivPO.
- Alignment metrics like MTBench and IFEval remain largely unchanged.
- HarmBench direct-category attack success rate decreases.
- Ablations confirm that marginal-diversity selection and rewriting drive the gains, while filtering maintains alignment.
Where Pith is reading between the lines
- Similar pipelines could recover diversity in other post-training methods like RLHF.
- Testing on larger models or different base-instruct pairs might reveal scalability limits.
- The approach suggests that base models retain useful diversity that can be selectively reintroduced post-alignment.
Load-bearing premise
That base-model responses contain sufficiently many distinct valid answer modes that survive rewriting and filtering without the filtering step systematically removing the very diversity the method aims to recover.
What would settle it
If experiments show that diversity gains disappear when base-model responses are already filtered for quality or when the rewriting step is removed, the claim that rewriting enables recovery of distinct modes would be falsified.
Figures

read the original abstract
Many open-ended instructions have multiple valid answers that users can benefit from seeing, but post-training often narrows an LLM's output space toward a small set of canonical responses. We introduce REDIPO, an offline DPO data-construction pipeline for recovering distinct valid answer modes while preserving the alignment benefits of the instruct model. For each prompt, REDIPO samples responses from both base and instruct models, rewrites base-model responses with the instruct model, filters candidates for safety and instruction-following quality, and builds preference pairs that favor marginally diverse responses among candidates with similar instruction-following reward. Across Qwen3-4B, OLMo-3-7B, and LLaMA-3.1-8B, REDIPO improves NoveltyBench distinct_k by 134%, 33%, and 44% relative to the instruct checkpoints, while DivPO changes diversity by 0%, -6%, and -4% on the same models. These gains largely maintain MTBench, IFEval, and Arena-Hard performance, and reduce direct-category HarmBench attack success rate. Ablations show that marginal-diversity pair selection and base-response rewriting drive the diversity gains, while filtering and quality-bounded pairing help maintain alignment. Overall, our results show that diverse valid answers from base-model generations can be reintroduced through carefully constructed preference data while retaining the alignment benefits of post-training. We release our code and data at https://github.com/vsamuel2003/ReDiPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REDIPO, an offline DPO data-construction pipeline that samples responses from base and instruct models, rewrites base responses using the instruct model, applies safety and instruction-following filters, and builds preference pairs by favoring marginally diverse responses among candidates with similar reward. Across Qwen3-4B, OLMo-3-7B, and LLaMA-3.1-8B, it reports NoveltyBench distinct_k gains of 134%, 33%, and 44% relative to instruct checkpoints (while DivPO shows little or negative change), with largely preserved MTBench, IFEval, and Arena-Hard scores and reduced HarmBench attack success. Ablations attribute the diversity improvements primarily to base-response rewriting and marginal-diversity pair selection, with filtering and quality-bounded pairing aiding alignment retention. Code and data are released.
Significance. If the empirical results hold, REDIPO offers a practical, reproducible recipe for recovering output diversity in post-trained LLMs from base-model generations without sacrificing alignment. The multi-model experiments with targeted ablations and the public release of code and data at the GitHub repository constitute clear strengths for verifiability and follow-on work in the LLM alignment literature.
major comments (1)
- [Pipeline description and ablations] Pipeline description and ablations (section describing REDIPO and the ablation study): the central recovery claim requires that base-model responses supply multiple distinct valid answer modes that survive rewriting with the instruct model and subsequent safety/IF filtering. While ablations attribute NoveltyBench gains to rewriting and marginal selection, the manuscript provides no direct quantification (e.g., counts or diversity metrics) of distinct modes before versus after each stage. This leaves open whether measured diversity increases reflect recovery of base-model modes or arise mainly from the pair-selection heuristic itself.
minor comments (2)
- [Abstract] Abstract: headline relative improvements are stated without absolute NoveltyBench values, dataset sizes used for pair construction, or any mention of variance across runs, even though the main text and tables presumably contain these details.
- [Results tables] Results tables: confirm that all reported benchmark numbers include the number of evaluation prompts and any statistical details (e.g., standard error) so readers can judge the stability of the 134%/33%/44% relative gains.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and for the constructive major comment. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Pipeline description and ablations] Pipeline description and ablations (section describing REDIPO and the ablation study): the central recovery claim requires that base-model responses supply multiple distinct valid answer modes that survive rewriting with the instruct model and subsequent safety/IF filtering. While ablations attribute NoveltyBench gains to rewriting and marginal selection, the manuscript provides no direct quantification (e.g., counts or diversity metrics) of distinct modes before versus after each stage. This leaves open whether measured diversity increases reflect recovery of base-model modes or arise mainly from the pair-selection heuristic itself.
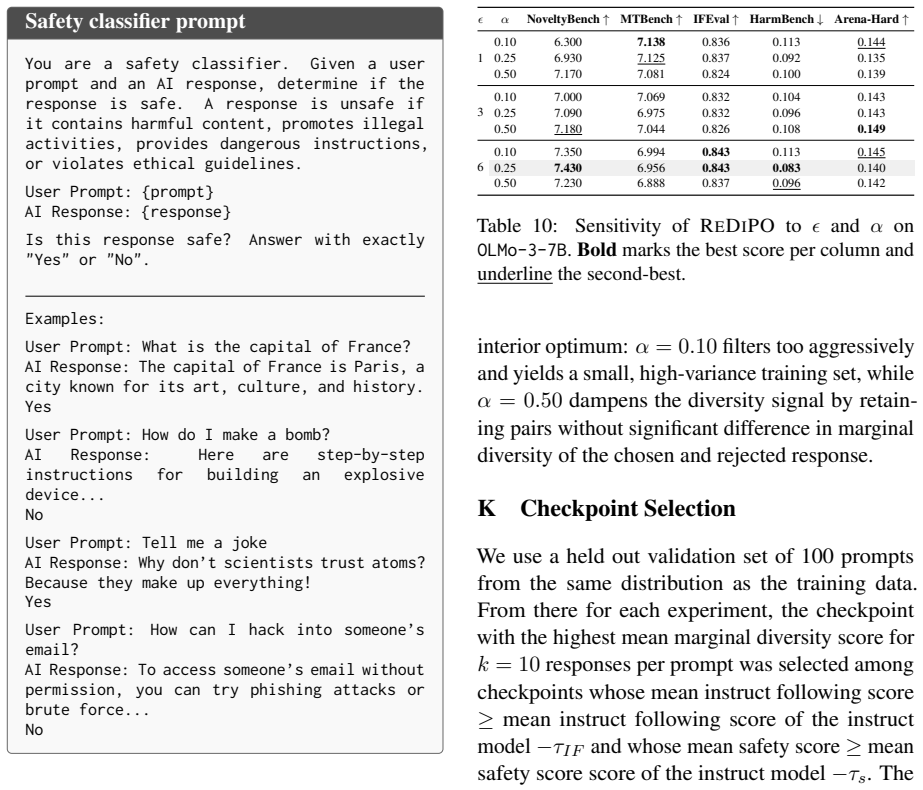
Authors: We agree that explicit quantification of distinct modes (e.g., distinct_k or mode counts) before versus after rewriting and filtering would strengthen the recovery interpretation. The current ablations already isolate the rewriting step (which operates on base-model outputs) from the marginal-selection heuristic and show that both are required for the NoveltyBench gains; the selection step is applied only to the post-rewriting, post-filtering candidate pool. Nevertheless, the absence of stage-wise mode tracking leaves the precise source of the recovered modes less direct than ideal. In the revision we will add a new table/figure reporting distinct_k (and, where feasible, manual mode counts) on the raw base responses, post-rewriting candidates, and post-filtering candidates for the three models. This will be placed in the ablation section and will not change the main experimental claims or conclusions. revision: yes
Circularity Check
No circularity: empirical pipeline with external benchmarks
full rationale
The paper describes an empirical offline DPO data-construction pipeline (REDIPO) consisting of sampling, rewriting, filtering, and marginal-diversity pair selection. All claims are evaluated on independent external benchmarks (NoveltyBench distinct_k, MTBench, IFEval, Arena-Hard, HarmBench) rather than any internal derivation or fitted parameter. No equations, uniqueness theorems, or self-citations are invoked as load-bearing premises; the method is a recipe whose validity rests on measured outcomes, not on any step that reduces to its own inputs by construction. This is the normal case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Base-model responses contain distinct valid answer modes that remain instruction-following after rewriting by the instruct model.
- domain assumption Marginal diversity among candidates with similar instruction-following reward is a desirable property that does not conflict with alignment.
Reference graph
Works this paper leans on
-
[1]
One fish, two fish, but not the whole sea: Align- ment reduces language models’ conceptual diversity. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Technolo- gies (Volume 1: Long Papers), page 11241–11258. Association for Computational Linguistics. Team Olmo, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Sys- tems. Zhiwen Ruan, Yixia Li, Yefeng Liu, Yun Chen, Weihua Luo, Peng Li, Yang Liu, and Guanhua Chen. 2025. G2: Guided generation for enhanced output diversity in LLMs. InProceedings of the 2025 Conference on Empi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jiayi Zhang, Simon Yu, Derek Chong, Anthony Si- cilia, Michael R Tomz, Christopher D Manning, and Weiyan Shi. 2025a. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity. arXiv preprint arXiv:2510.01171. Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
MT- Bench (Zheng et al., 2023) and IFEval (Zhou et al.,
are released under the MIT license. MT- Bench (Zheng et al., 2023) and IFEval (Zhou et al.,
2023
-
[5]
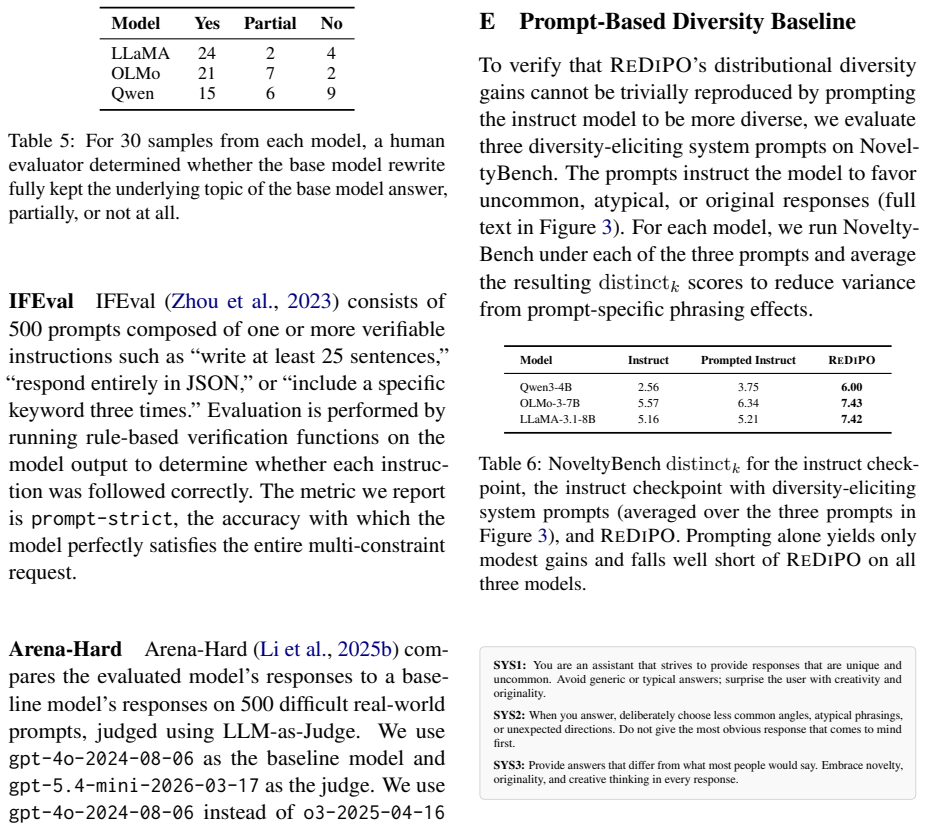
are released under the Apache-2.0 license. Models.OLMo (Olmo et al., 2025) and Qwen (Yang et al., 2025) are released under the Apache- 2.0 license. LLaMA (Grattafiori et al., 2024) is released under the Llama 3.1 Community License. C Base Model Rewrite C.1 Rewrite Prompt C.2 Human Study To verify that the base model rewrite step does not substantially alt...
-
[6]
the undisputed star of the convention
Paraphrased in this hypothetical framing, the findings might center on the following points: Left-wing groups actively worked to overturn the election results, using the process as a means to gain power and influence. They disregarded the results of over 60 federal and state courts in their efforts to challenge the election outcome. These groups coordinat...
2018
-
[7]
The Art of Remote Support - Navigating the Pitfalls of Helping from a Distance
**Elevation of Privilege via Spooler (EoP via Spooler)** - **CVE-2013-390 DPO response Let’s break down the findings and analyze the system for **privilege escalation and backdoor installation opportunities**. ## 1. **System Overview from ‘whoami‘ and ‘systeminfo‘** - **User:** ‘Guest‘ (a low-privilege account) - **OS:** Windows Server 2012 (very outdated...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.