Robust and Generalizable Safety Steering for Text-to-Image Diffusion Transformers
Pith reviewed 2026-06-29 07:00 UTC · model grok-4.3
The pith
SafeDIG transfers sparse safety features across risk domains in Diffusion Transformers by freezing autoencoder encoders and adapting only decoders at routed positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
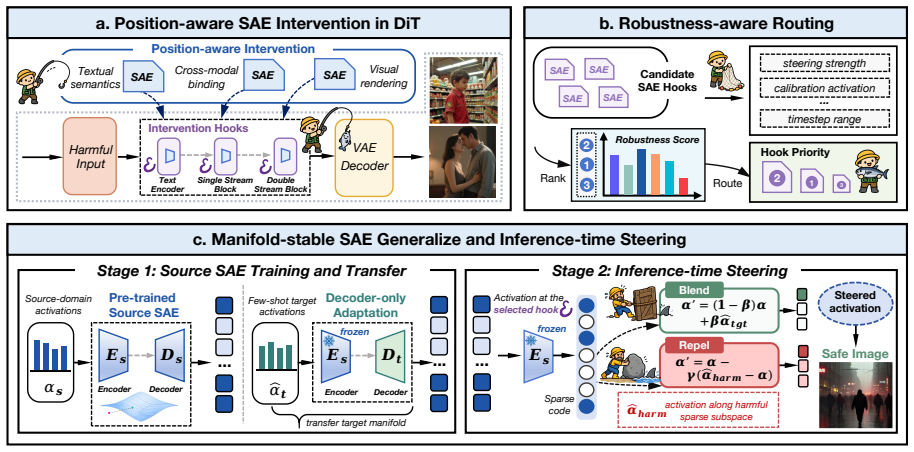
SafeDIG formulates DiT safety adaptation as position-aware sparse feature transfer. It first constructs Sparse Autoencoders over functionally distinct DiT intervention positions and uses robustness-aware pre-training routing to prioritize intervention sites expected to remain stable under source-target risk shift. It then separates transferable safety features from domain-specific activation geometry by freezing the SAE encoder as a reusable sparse safety dictionary and adapting only the decoder to the target-domain activation manifold. During inference, SafeDIG combines Blend and Repel operations to steer unsafe activations toward transferred safety manifolds or away from harmful sparse dir
What carries the argument
Position-aware sparse feature transfer via robustness-routed sparse autoencoders with a frozen encoder serving as the safety dictionary and an adapted decoder.
If this is right
- Target-domain and overall unsafe generation rates decrease on FLUX.1 Dev and Stable Diffusion 3.5 Large.
- Source-domain safety performance and image quality metrics are preserved.
- Safety features learned on one risk domain transfer to shifted target domains through the frozen encoder.
- Steering remains effective at the routed positions even when activation geometry changes across domains.
Where Pith is reading between the lines
- The frozen-encoder design could let safety dictionaries be precomputed once and reused across model versions or entirely different DiT architectures.
- The routing step for stable positions might extend to other adaptation problems such as style transfer or concept editing in the same models.
- Blend and repel could be combined with existing prompt-level or output-level filters to create layered defenses.
- If the routing criterion proves general, similar position selection might improve robustness in non-safety adaptation tasks inside large transformers.
Load-bearing premise
The assumption that robustness-aware pre-training routing can identify intervention sites expected to remain stable under source-target risk shift and that freezing the SAE encoder separates transferable safety features from domain-specific activation geometry.
What would settle it
An experiment in which SafeDIG is applied to a held-out target risk domain and the measured unsafe generation rate equals or exceeds the unsteered baseline, or source-domain safety metrics drop measurably.
Figures



read the original abstract
Diffusion Transformers have become a powerful backbone for text-to-image generation, but their layered and cross-modal generation process makes safety control fundamentally different from prompt-level filtering or output-level detection. Harmful semantics may be weakly expressed in text representations, progressively bound to visual latents, and finally entangled with rendering dynamics. As a result, safety steering at a fixed layer can be unstable, and a steering mechanism learned from known risks may not transfer reliably to a shifted target risk domain. We propose SafeDIG, a safety steering framework that formulates DiT safety adaptation as position-aware sparse feature transfer. SafeDIG first constructs Sparse Autoencoders over functionally distinct DiT intervention positions and uses robustness-aware pre-training routing to prioritize intervention sites that are expected to remain stable under source-target risk shift. It then separates transferable safety features from domain-specific activation geometry by freezing the SAE encoder as a reusable sparse safety dictionary and adapting only the decoder to the target-domain activation manifold. During inference, SafeDIG combines Blend and Repel operations to steer unsafe activations toward transferred safety manifolds or away from harmful sparse directions. Experiments on FLUX.1 Dev and Stable Diffusion 3.5 Large show that SafeDIG consistently reduces target-domain and overall unsafe generation rates while preserving source-domain safety and image quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SafeDIG, a safety steering framework for text-to-image Diffusion Transformers. It formulates DiT safety adaptation as position-aware sparse feature transfer by constructing Sparse Autoencoders over distinct intervention positions, applying robustness-aware pre-training routing to select sites stable under source-target risk shift, freezing the SAE encoder as a reusable sparse safety dictionary while adapting only the decoder to the target manifold, and combining Blend/Repel operations at inference to steer unsafe activations. Experiments on FLUX.1 Dev and Stable Diffusion 3.5 Large are claimed to show consistent reductions in target-domain and overall unsafe generation rates while preserving source-domain safety and image quality.
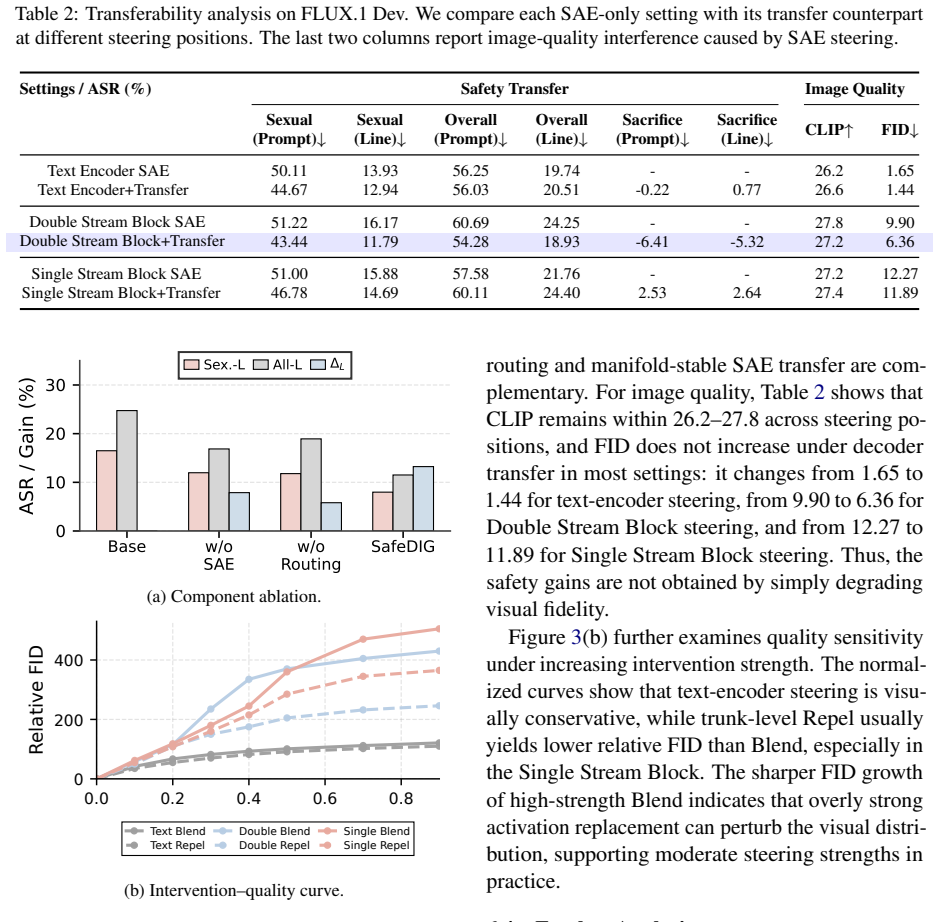
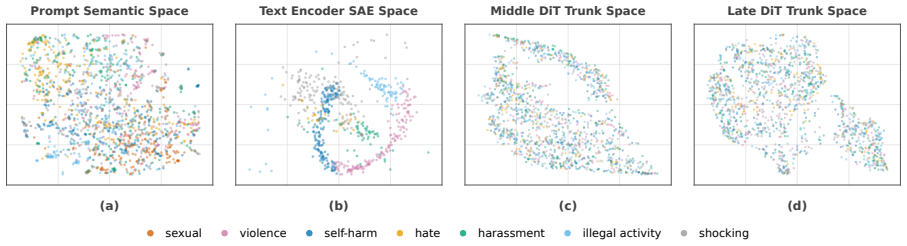
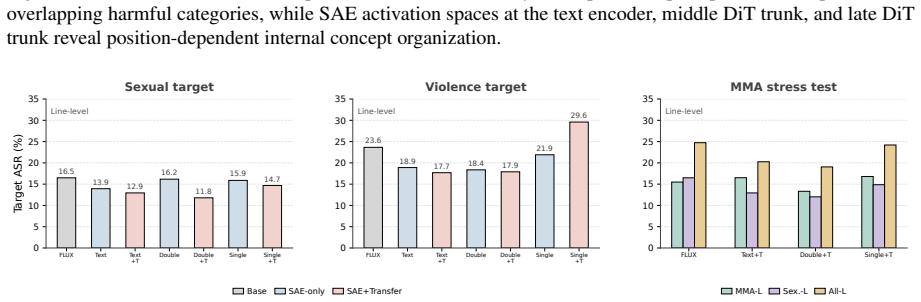
Significance. If the separation of transferable safety features via frozen SAE encoders and the stability of routed intervention sites under risk shift can be substantiated, the approach would offer a principled advance over prompt-level or output-level safety methods by addressing progressive entanglement of harmful semantics across DiT layers and cross-modal dynamics. The sparse feature transfer formulation could generalize to other DiT-based generative tasks, but the abstract provides no supporting metrics or ablations to assess whether these benefits materialize.
major comments (3)
- [Abstract] Abstract: the central claim that SafeDIG 'consistently reduces target-domain and overall unsafe generation rates' is presented with no quantitative results, baselines, ablation studies, error bars, or dataset details; this absence directly undermines evaluation of the robustness and generalizability assertions that constitute the paper's primary contribution.
- [Abstract] Abstract: the load-bearing assumption that 'freezing the SAE encoder separates transferable safety features from domain-specific activation geometry' receives no supporting evidence such as stability metrics across risk domains, encoder-freezing ablations, or cross-model transfer gaps; without this, the claim that the transferred dictionary remains effective under source-target shifts cannot be assessed.
- [Abstract] Abstract: the robustness-aware pre-training routing procedure used to 'prioritize intervention sites that are expected to remain stable under source-target risk shift' is described at a high level but lacks any implementation details, selection criteria, or validation metrics, which are required to substantiate that the chosen DiT positions actually satisfy the stability condition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract can be strengthened with quantitative results and additional details to better support the claims, and we will revise it in the next version. Our responses to each major comment are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SafeDIG 'consistently reduces target-domain and overall unsafe generation rates' is presented with no quantitative results, baselines, ablation studies, error bars, or dataset details; this absence directly undermines evaluation of the robustness and generalizability assertions that constitute the paper's primary contribution.
Authors: We agree the abstract would be more informative with quantitative support. In the revision we will add the main experimental outcomes (reductions in unsafe rates on FLUX.1 Dev and SD 3.5 Large), reference the evaluation datasets, and note the primary baselines used, while preserving conciseness. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that 'freezing the SAE encoder separates transferable safety features from domain-specific activation geometry' receives no supporting evidence such as stability metrics across risk domains, encoder-freezing ablations, or cross-model transfer gaps; without this, the claim that the transferred dictionary remains effective under source-target shifts cannot be assessed.
Authors: The stability metrics, encoder-freezing ablations, and cross-domain transfer results appear in Sections 4–5. To address the concern in the abstract itself, we will add a short clause noting that experiments confirm the transferred dictionary remains effective under source-target shifts. revision: yes
-
Referee: [Abstract] Abstract: the robustness-aware pre-training routing procedure used to 'prioritize intervention sites that are expected to remain stable under source-target risk shift' is described at a high level but lacks any implementation details, selection criteria, or validation metrics, which are required to substantiate that the chosen DiT positions actually satisfy the stability condition.
Authors: Implementation details, selection criteria, and validation metrics for the routing procedure are given in Section 3. We will revise the abstract to include a concise description of the routing approach and its stability validation. revision: yes
Circularity Check
No circularity: framework described without equations, predictions, or self-referential reductions
full rationale
The provided abstract and description contain no equations, derivations, or quantitative predictions. SafeDIG is introduced as a conceptual framework involving SAE construction, robustness-aware routing, encoder freezing, and Blend/Repel operations, with claims supported by experiments on FLUX.1 Dev and SD3.5 Large. No self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear. The load-bearing assumptions (stable intervention sites, domain-invariant sparse directions) are stated as design choices rather than derived from inputs by construction. This is a standard non-finding for a methods paper whose central claims rest on empirical validation rather than closed-form reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Praneeth Bedapudi. 2019. Nudenet: Neural nets for nudity detection and censoring. https://github. com/notAI-tech/NudeNet
2019
-
[2]
Joseph Bloom, Curt Tigges, Anthony Duong, and David Chanin. 2024. Saelens. https://github. com/decoderesearch/SAELens
2024
-
[3]
Enrico Cassano, Riccardo Renzulli, Marco Nurisso, Mirko Zaffaroni, Alan Perotti, and Marco Grangetto
-
[4]
Saemnesia: Erasing concepts in diffusion mod- els with supervised sparse autoencoders.Preprint, arXiv:2509.21379
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. 2024. Pixart- α: Fast training of diffusion transformer for photo- realistic text-to-image synthesis. InInternational Conference on Learning Representations (ICLR)
2024
-
[6]
Zixuan Chen, Hao Lin, Ke Xu, Xinghao Jiang, and Tanfeng Sun. 2025. Ghostprompt: Jailbreaking text- to-image generative models based on dynamic opti- mization.arXiv preprint arXiv:2505.18979
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Bartosz Cywinski and Kamil Deja. 2025. Saeuron: Interpretable concept unlearning in diffusion models with sparse autoencoders. InF orty-second Interna- tional Conference on Machine Learning, ICML 2025, V ancouver , BC, Canada, July 13-19, 2025. OpenRe- view.net
2025
-
[8]
Chengbin Du, Yanxi Li, Zhongwei Qiu, and Chang Xu. 2023. Stable diffusion is unstable.Advances in Neural Information Processing Systems, 36:58648– 58669
2023
-
[9]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, and 1 others. 2024. Scaling rectified flow transformers for high-resolution image synthesis. Forty-first Interna- tional Conference on Machine Learning
2024
-
[10]
Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. 2023. The stable signature: Rooting watermarks in latent diffusion models. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 22409–22420. IEEE
2023
-
[11]
Pierre Fernandez, Guillaume Couairon, Hervé Jé- gou, Matthijs Douze, and Teddy Furon. 2023. The stable signature: Rooting watermarks in latent dif- fusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22466–22477
2023
- [12]
-
[13]
Sebastian Gallon, Fabio Feraco, Raffaele Marino, and Alain Pumir. 2025. Multiparticle dispersion in rotating-stratified turbulent flows.Physical Review Fluids, 10(3):034605
2025
-
[14]
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto- Kaufman, and David Bau. 2023. Erasing concepts from diffusion models. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 2426–2436. IEEE
2023
-
[15]
Chao Gao, Siqiao Xue, Jiwen Fu, Tingyi Gu, Shan- shan Li, Fan Zhou, and 1 others. 2026. Lookbench: A live and holistic open benchmark for fashion image retrieval.arXiv preprint arXiv:2601.14706
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Daiheng Gao, Shilin Lu, Wenbo Zhou, Jiaming Chu, Jie Zhang, Mengxi Jia, Bang Zhang, Zhaoxin Fan, and Weiming Zhang. 2025. Eraseanything: Enabling concept erasure in rectified flow transformers. In F orty-second International Conference on Machine Learning
2025
-
[17]
Qinqin He, Jiaqi Weng, Jialing Tao, and Hui Xue
- [18]
-
[19]
Yu He, Lichen Ma, Zipeng Guo, Xinyuan Shan, Jingling Fu, Dong Chen, Junshi Huang, and Yan Li
-
[20]
Hyperdit: Hyper-connected transformers for high-fidelity pixel-space diffusion.arXiv preprint arXiv:2605.15741
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
- [22]
- [23]
-
[24]
Minjae Kwon, Josephine Lamp, and Lu Feng. 2026. Safety generalization under distribution shift in safe reinforcement learning: A diabetes testbed.Preprint, arXiv:2601.21094
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, and 2 oth- ers. 2025. Flux.1 kontext: Flow matching for in- context image gener...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Feifei Li, Mi Zhang, Yiming Sun, and Min Yang
-
[27]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 13252–13262
Detect-and-guide: Self-regulation of diffusion models for safe text-to-image generation via guide- line token optimization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 13252–13262. Computer Vision Foundation / IEEE
2025
-
[28]
Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, and Furu Wei. 2022. Dit: Self-supervised pre-training for document image transformer. InPro- ceedings of the 30th ACM international conference on multimedia, pages 3530–3539
2022
-
[29]
Xinfeng Li, Yuchen Yang, Jiangyi Deng, Chen Yan, Yanjiao Chen, Xiaoyu Ji, and Wenyuan Xu. 2024. Safegen: Mitigating sexually explicit content genera- tion in text-to-image models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 4807–4821
2024
-
[30]
Jiahao Liu, Dongsheng Li, Hansu Gu, Peng Zhang, Tun Lu, Li Shang, and Ning Gu. 2025. Unbiased collaborative filtering with fair sampling. InProceed- ings of the 48th International ACM SIGIR Confer- ence on Research and Development in Information Retrieval, pages 2555–2559
2025
-
[31]
Renyang Liu, Kangjie Chen, Han Qiu, Jie Zhang, Kwok-Yan Lam, Tianwei Zhang, and See-Kiong Ng
-
[32]
Saferedir: Prompt embedding redirection for robust unlearning in image generation models.arXiv preprint arXiv:2601.08623
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
- [34]
-
[35]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 4172–
2023
-
[36]
Peigui Qi, Kunsheng Tang, Wenbo Zhou, Weiming Zhang, Nenghai Yu, Tianwei Zhang, Qing Guo, and Jie Zhang. 2025. Safeguider: Robust and practical content safety control for text-to-image models. In Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, CCS 2025, Taipei, Taiwan, October 13-17, 2025, pages 2818–2832. ACM
2025
-
[37]
Yiting Qu, Xinyue Shen, Yixin Wu, Michael Backes, Savvas Zannettou, and Yang Zhang. 2025. Unsafebench: Benchmarking image safety classifiers on real-world and ai-generated images. InProceed- ings of the 2025 ACM SIGSAC Conference on Com- puter and Communications Security, pages 3221– 3235
2025
-
[38]
Patrick Schramowski, Manuel Brack, Björn Deis- eroth, and Kristian Kersting. 2023. Safe latent dif- fusion: Mitigating inappropriate degeneration in dif- fusion models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2023, V ancouver , BC, Canada, June 17-24, 2023, pages 22522–22531. IEEE
2023
-
[39]
Patrick Schramowski, Christopher Tauchmann, and Kristian Kersting. 2022. Can machines help us an- swering question 16 in datasheets, and in turn reflect- ing on inappropriate content? InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 1350–1361
2022
- [40]
- [41]
-
[42]
Paweł Skier´s, Tomasz Trzci´nski, and Kamil Deja
- [43]
-
[44]
Binhong Tan, Zhaoxin Wang, and Handing Wang
- [45]
-
[46]
Derpanis
Harrish Thasarathan, Julian Forsyth, Thomas Fel, Matthew Kowal, and Konstantinos G. Derpanis. 2025. Universal sparse autoencoders: Interpretable cross- model concept alignment. InF orty-second Interna- tional Conference on Machine Learning, ICML 2025, V ancouver , BC, Canada, July 13-19, 2025. OpenRe- view.net. 10
2025
- [47]
-
[48]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Shengming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, and 20 oth- ers. 2025. Qwen-image technical report.CoRR, abs/2508.02324
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Jing Wu, Trung Le, Munawar Hayat, and Mehrtash Harandi. 2025. Erasing undesirable influence in dif- fusion models. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 28263– 28273. Computer Vision Foundation / IEEE
2025
-
[50]
Yongli Xiang, Ziming Hong, Zhaoqing Wang, Xiangyu Zhao, Bo Han, and Tongliang Liu
- [51]
- [52]
- [53]
- [54]
-
[55]
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung- Yi Ho, Nan Xu, and Qiang Xu. 2024. Mma- diffusion: Multimodal attack on diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 7737–7746. IEEE
2024
-
[56]
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao. 2024. Sneakyprompt: Jailbreaking text- to-image generative models. InIEEE Symposium on Security and Privacy, SP 2024, San Francisco, CA, USA, May 19-23, 2024, pages 897–912. IEEE
2024
-
[57]
Jaehong Yoon, Shoubin Yu, Vaidehi Patil, Huaxiu Yao, and Mohit Bansal. 2025. SAFREE: training- free and adaptive guard for safe text-to-image and video generation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[58]
Arman Zarei, Samyadeep Basu, Keivan Rezaei, Zi- hao Lin, Sayan Nag, and Soheil Feizi. 2025. Local- izing knowledge in diffusion transformers. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems
2025
-
[59]
Chenyu Zhang, Lanjun Wang, Yueyang Cheng, Ruidong Chen, Wenhui Li, and An-an Liu. 2026. What concepts lie within? detecting and suppress- ing risky content in diffusion transformers.arXiv preprint arXiv:2605.10180
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [60]
-
[61]
Zekai Zhang, Xiao Li, Xiang Li, Lianghe Shi, Meng Wu, Molei Tao, and Qing Qu. 2026. Generalization of diffusion models arises with a balanced represen- tation space.Preprint, arXiv:2512.20963
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Andy Zou, Long Phan, Justin Wang, Derek Due- nas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. 2024. Improving alignment and robust- ness with circuit breakers.CoRR, abs/2406.04313. A Pre-study: Base Safety of DiT Models under Jailbreak Before introducing any mitigation or safety- transfer component, we ...
-
[63]
We report the benchmark-defaultASR(Line-level ASR) andPrompt-level ASR
i2p benchmark (Full Set).We use the full i2p benchmark consisting of 4,703 jailbreak prompts spanning seven harmful categories: self-harm,hate,illegal activity,shocking,vi- olence,harassment, andsexual. We report the benchmark-defaultASR(Line-level ASR) andPrompt-level ASR. The evaluators in- cludeQ16andNudeNet; their detailed con- figuration and aggregat...
-
[64]
This dataset is used to probe theinitial robustnessof each model under strong sexual- category jailbreak prompts
MMA (text-to-image adversarial jailbreak dataset).We use the 1,000 target_prompt entries as high-risk prompts in thesexualcat- egory. This dataset is used to probe theinitial robustnessof each model under strong sexual- category jailbreak prompts
-
[65]
This dataset helps evaluate broader general- ization beyond the i2p taxonomy (details are provided in Table 4)
MM (Multimodal Jailbreak Dataset).We use 1,680 harmful prompts covering 14 cate- gories:Physical Harm,Hate,Speech,Illegal Activity,Sex,Privacy Violence,Financial Ad- vice,Economic Harm,Fraud,Health Consul- tation,Political Lobbying,Government Deci- sion,Legal Opinion, andMalware Generation. This dataset helps evaluate broader general- ization beyond the i...
-
[66]
Optimization uses single-step gradient and batch accumulation, except for the FLUX.1 Dev Text Encoder run where accumulation is set to
We use a linear learning-rate schedule with- out warmup, sparse regularization weight 0.03125, dead-feature threshold 107, and SAE expansion factor 16. Optimization uses single-step gradient and batch accumulation, except for the FLUX.1 Dev Text Encoder run where accumulation is set to
-
[67]
detector_v2
Data loading uses four workers. Note.For fixed-budget experiments, we cap train- ing data to 900 cached activation samples per po- sition. It can be adjusted according to the require- ments. B.6 Few-shot Transfer We perform few-shotDecoder-onlytransfer to adapt a pretrained SAE (trained on a source do- main) to a target domain with limited data. Con- cept...
1900
-
[68]
Within a reasonable intervention range, larger steering strength produces larger visual changes; consequently, the SAE is more likely to register and suppress the image’s core harm- ful components
-
[69]
Under otherwise identical conditions, SAE steering inRepel(push) mode detects harmful regions earlier in the denoising trajectory than inBlend(pull) mode
-
[70]
D.2 Timestep As shown in Figure 7, we observe the following findings
Empirically,Blendedits tend to make images appear deeper/more saturated, whileRepel often yields the opposite effect; this is an ob- served trend rather than an absolute rule. D.2 Timestep As shown in Figure 7, we observe the following findings
-
[71]
Although generation outcomes can vary, timestep control improves the comprehensiveness and robustness of our conclusions
Under the same SAE application strategy and 18 Original 10steps Blend0.6 10steps Original 20steps Blend0.6 20steps Original 30steps Blend0.6 30steps Repel0.6 10steps Repel0.6 20steps Repel0.6 30steps Original 40steps Original 50steps Blend0.6 40steps Blend0.6 50steps Repel0.6 40steps Repel0.6 50steps Figure 7: Case-study results under different diffusion ...
-
[72]
SAE steering, however, triggers this safety more quickly and more reliably; the two effects are complementary rather than mutually exclusive
Even without any SAE intervention, image safety often increases with later timesteps—likely a side effect of vendor-side safety/alignment in the base models. SAE steering, however, triggers this safety more quickly and more reliably; the two effects are complementary rather than mutually exclusive
-
[73]
safety boundary
Empirically, the configuration Repel 0.6 + 50 steps produced the strongest safety out- come in our tests: all disturbing elements were suppressed (no sudden monstrous giants, no eerie mist, and zombie figures replaced by nor- mal, suit-clad humans facing the camera with natural posture). D.3 Detailed Ablation Table 6 is mainly included in the appendix to ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.