A Predictive Law for On-Policy Self-Distillation From World Feedback
Pith reviewed 2026-06-29 09:06 UTC · model grok-4.3
The pith
A linear correlation between the initial student-self-teacher performance gap and final OPSD improvement predicts training outcomes without running the full procedure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
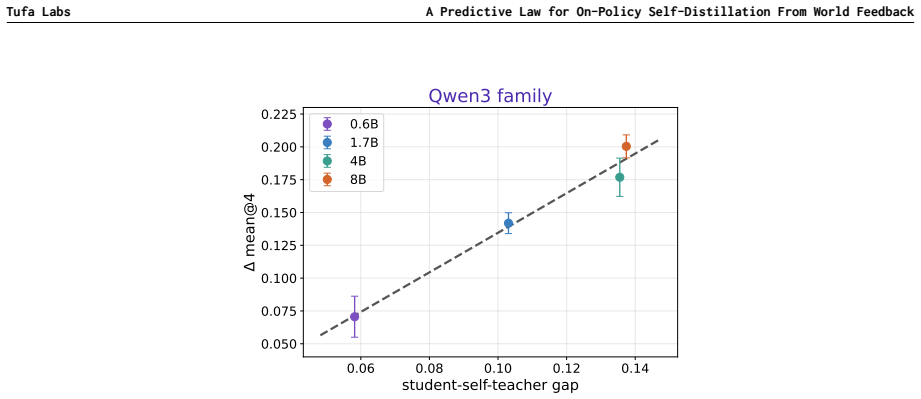
The central claim is that a strikingly consistent linear correlation exists between the initial student-self-teacher performance gap and the final performance improvement achieved by on-policy self-distillation. This relationship holds across context types and model families and continues to hold with increasing model scale, supplying a predictive law that anticipates OPSD outcomes without executing the complete training procedure.
What carries the argument
The linear correlation between initial performance gap and final improvement, which functions as a predictive law for OPSD configurations.
If this is right
- OPSD outcomes can be anticipated from a short initial measurement rather than a full training run.
- The same linear relationship applies across different context types and model families.
- The linearity persists with model scale, supporting the possibility of empirical scaling laws for in-context learning under world feedback.
- World feedback can be incorporated into post-training pipelines in a predictable rather than trial-and-error manner.
Where Pith is reading between the lines
- A small pilot run could be used to measure the gap and decide whether to launch full OPSD training on a given configuration.
- The same gap-based predictor might apply to other distillation or feedback-driven methods beyond the setups tested here.
- If the linear pattern breaks at frontier scales, it would mark a transition point where stronger in-context learning changes how self-distillation behaves.
Load-bearing premise
The linear correlation between initial gap and final improvement stays stable enough to predict new configurations and continues to hold as models scale, without being overturned by unmeasured confounding variables.
What would settle it
A new OPSD experiment on a different model family or context type in which the plotted relationship between initial gap and final improvement deviates substantially from a straight line would falsify the claimed predictive law.
Figures

read the original abstract
Moving beyond simple scalar rewards toward richer world feedback is a natural path to more scalable RL post-training. On-policy self-distillation (OPSD) is a promising recent approach that uses arbitrary feedback as learning signal, yet its reliability compared to established methods, such as GRPO, remains unclear. We identify a strikingly consistent linear correlation between the initial student-self-teacher performance gap and the final performance improvement in OPSD. This relationship holds across context types and model families, providing a powerful predictive law for anticipating the outcome of an OPSD configuration without running the full training procedure. Interestingly, we show that this linear predictability holds with model scale, suggesting a potential basis for new empirical scaling laws on larger models with stronger in-context learning capabilities. In essence, our findings show that OPSD performance can be predicted and tuned before training, offering a principled way to incorporate world feedback as a first-class component of the post-training pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces on-policy self-distillation (OPSD) for incorporating arbitrary world feedback into RL post-training and reports a strikingly consistent linear correlation between the initial student-self-teacher performance gap and the final performance improvement. This correlation is claimed to hold across context types and model families, serving as a predictive law that allows anticipation of OPSD outcomes without full training, and to remain stable with model scale.
Significance. If the linear mapping is shown to be stable under out-of-sample evaluation and generalizes across new configurations, it would offer a practical method for pre-selecting OPSD hyperparameters and could support empirical scaling analyses for feedback-based post-training. The reported consistency across model families is a potentially useful observation if supported by appropriate statistical controls.
major comments (2)
- [Abstract and §4] Abstract and §4 (Results): The central claim that the linear relationship constitutes a 'predictive law' for new OPSD configurations is load-bearing, yet the manuscript fits the slope and intercept to the full set of runs without reporting cross-validation, hold-out configurations, or forward prediction error on unseen context/model combinations. This leaves the relationship descriptive rather than demonstrably predictive.
- [§3 and Figure 2] §3 (Experimental Setup) and Figure 2: No information is supplied on the number of independent runs per configuration, statistical tests for the correlation, error bars on the fitted line, data exclusion criteria, or controls for potential confounders such as context length or training duration, making it impossible to assess whether the reported linearity is robust.
minor comments (2)
- [§2] Notation for the performance gap and improvement metrics should be defined explicitly in §2 before being used in the correlation plots.
- [Figure 4] The abstract states the relationship 'holds with model scale' but the corresponding scaling plot lacks axis labels indicating the range of model sizes tested.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate revisions to strengthen the manuscript's claims regarding the predictive nature of the observed relationship.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): The central claim that the linear relationship constitutes a 'predictive law' for new OPSD configurations is load-bearing, yet the manuscript fits the slope and intercept to the full set of runs without reporting cross-validation, hold-out configurations, or forward prediction error on unseen context/model combinations. This leaves the relationship descriptive rather than demonstrably predictive.
Authors: We agree that explicit out-of-sample validation would more rigorously support the predictive claim. While the manuscript demonstrates consistency across the tested context types and model families, we will add cross-validation, hold-out configuration tests, and forward prediction error metrics on unseen combinations in the revised version to demonstrate the law's utility for anticipating OPSD outcomes without full training runs. revision: yes
-
Referee: [§3 and Figure 2] §3 (Experimental Setup) and Figure 2: No information is supplied on the number of independent runs per configuration, statistical tests for the correlation, error bars on the fitted line, data exclusion criteria, or controls for potential confounders such as context length or training duration, making it impossible to assess whether the reported linearity is robust.
Authors: We acknowledge the need for these experimental details to assess robustness. The revised manuscript will report the number of independent runs per configuration, statistical tests (including p-values) for the reported correlations, error bars on the fitted lines, any data exclusion criteria, and analyses or controls addressing potential confounders such as context length and training duration. revision: yes
Circularity Check
Linear correlation from experimental runs presented as predictive law for unseen OPSD configurations
specific steps
-
fitted input called prediction
[Abstract]
"We identify a strikingly consistent linear correlation between the initial student-self-teacher performance gap and the final performance improvement in OPSD. This relationship holds across context types and model families, providing a powerful predictive law for anticipating the outcome of an OPSD configuration without running the full training procedure."
The linear correlation is extracted from the performance metrics of the OPSD training runs performed in the paper. The same relationship is then labeled a 'predictive law' that can anticipate results for new configurations without executing those runs. This makes the claimed prediction statistically equivalent to the fitted input from the original data rather than an independent forecast.
full rationale
The paper's central claim is an empirical linear relationship between initial performance gap and final improvement, observed across tested setups and then asserted to enable prediction without full training. This matches the fitted_input_called_prediction pattern because the law is derived directly from the same experimental data it claims to forecast. No explicit hold-out, cross-validation, or forward testing on unseen configurations is described in the provided text, so the predictive utility reduces to re-applying the fitted mapping. However, the observation itself may still have descriptive value, and no self-citation chain or definitional loop is shown, keeping the circularity partial rather than total.
Axiom & Free-Parameter Ledger
free parameters (1)
- slope and intercept of the linear fit
Reference graph
Works this paper leans on
-
[1]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, et al. OpenAI o1 system card, 2024. URL https://arxiv.org/abs/2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, et al. Kimi k1.5: Scaling reinforcement learning with LLMs, 2025. URLhttps://arxiv.org/abs/2501.12599
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation. arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Self-Distillation Enables Continual Learning
IdanShenfeld, MehulDamani, JonasHübotter, andPulkitAgrawal. Self-distillationenablescontinuallearning. arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
SiyanZhao, ZhihuiXie, MengchenLiu, JingHuang, GuanPang, FeiyuChen, andAdityaGrover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Online experiential learning for language models.arXiv preprint arXiv:2603.16856, 2026
Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, and Furu Wei. Online experiential learning for language models.arXiv preprint arXiv:2603.16856, 2026
-
[8]
On-policy self-distillation for reasoning compression.arXiv e-prints, pages arXiv–2603, 2026
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. On-policy self-distillation for reasoning compression.arXiv e-prints, pages arXiv–2603, 2026
2026
-
[9]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Opsd isn’t a silver bullet for continual learning
Harry Partridge. Opsd isn’t a silver bullet for continual learning. Post on X (formerly Twitter), March 2026. URLhttps://x.com/part_harry_/status/2038715548071325794
-
[11]
On sft, rl, and on-policy distillation
Will Brown. On sft, rl, and on-policy distillation. Post on X (formerly Twitter), April 2026. URL https://x.com/willccbb/status/2050038277454143918
-
[12]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
2024
-
[13]
On-policy distillation
Kevin Lu and Thinking Machines Lab. On-policy distillation. Thinking Machines Lab Blog (Connectionism), October 2025. URLhttps://thinkingmachines.ai/blog/on-policy-distillation. Blog post
2025
-
[14]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
NamanJain,KingHan,AlexGu,Wen-DingLi,FanjiaYan,TianjunZhang,SidaWang,ArmandoSolar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
AnYang,AnfengLi,BaosongYang,BeichenZhang,BinyuanHui,BoZheng,BowenYu,ChangGao,Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, S...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe, 2026. URLhttps://arxiv.org/abs/2604.13016
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. Scaling reasoning efficiently 6 Tufa Labs A Predictive Law for On-Policy Self-Distillation From World Feedback via relaxed on-policy distillation, 2026. URLhttps://arxiv.org/abs/2603.11137
-
[19]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021. URLhttps://arxiv.org/abs/2005.11401
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
LakshyaAAgrawal,ShangyinTan,DilaraSoylu,NoahZiems,RishiKhare,KristaOpsahl-Ong,ArnavSinghvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026. URLhttps://arxiv.org/abs/2507.19457
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines, 2023. URLhttps://arxiv.org/abs/2310.03714
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models, 2026. URLhttps: //arxiv.org/abs/2510.04618
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Amrith Setlur, Nived Rajaraman, Sergey Levine, and Aviral Kumar. Scaling test-time compute without verification or rl is suboptimal.arXiv preprint arXiv:2502.12118, 2025
-
[27]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[29]
Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, and Jieyu Zhao. Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
-
[30]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297. ACM, March 2025. doi: 10.1145/3689031.3696075. URLhttp://dx.doi.org/10.1145/3689031.3696...
-
[31]
We ran additional experiments with more context constructions, where the same law holds well, but omit them because they lack sufficient seed coverage
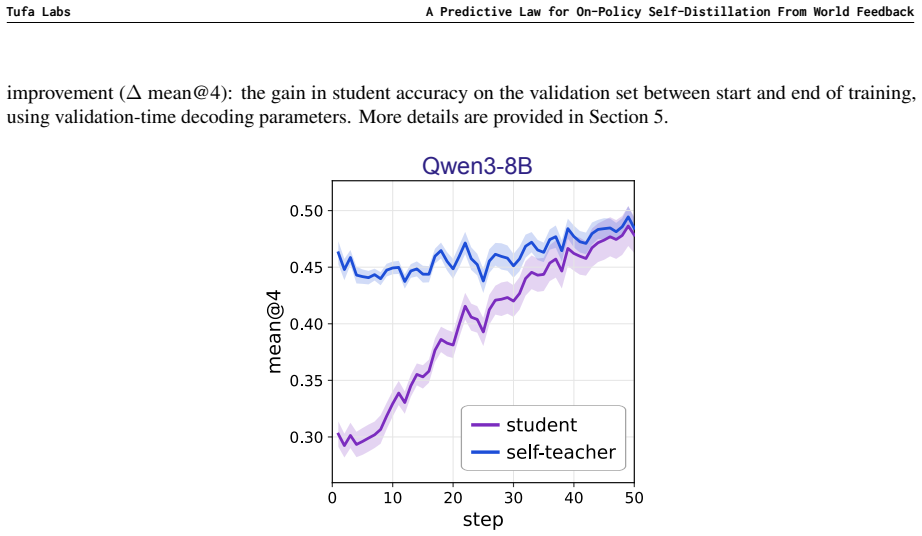
For the experiments in Subsection 3.1, we run OPSD for 50 steps on Qwen3-8B for 3 seeds and Olmo-3-7B- Instruct for 2 seeds while varying the context according to the self-teacher constructions in Table 3. We ran additional experiments with more context constructions, where the same law holds well, but omit them because they lack sufficient seed coverage
-
[32]
For the experiments in Subsection 3.2, we run OPSD for 50 steps on Qwen3-{0.6B, 1.7B, 4B, 8B} for 3 seeds while fixing the privileged context typePeer Solution + Feedback. We note that we did initial experiments on Qwen3-14B; however, we believe that for larger models we might have to tune hyperparameters separately and hence do not include these inconclu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.