Native Audio-Visual Alignment for Generation
Pith reviewed 2026-06-29 07:51 UTC · model grok-4.3
The pith
NAVA establishes audio-video correspondence in a dedicated interaction space before applying external context to condition joint denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
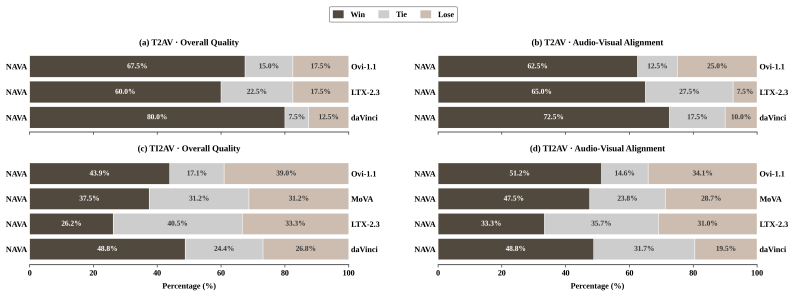
By first establishing audio-video correspondence in a dedicated interaction space and then using external context to condition the joint denoising process, NAVA achieves superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability.
What carries the argument
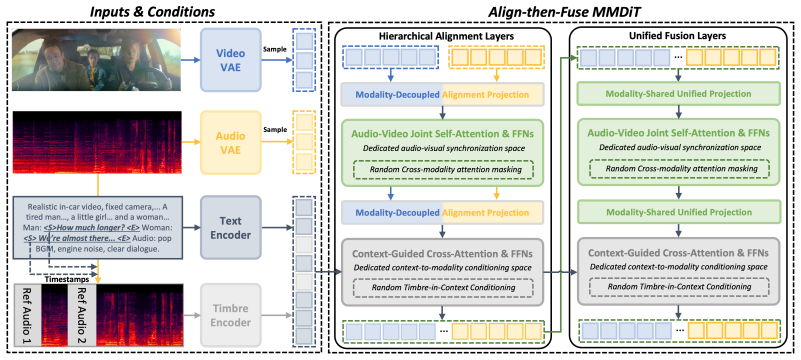
The Align-then-Fuse MMDiT architecture that transitions from modality-aware audio-video alignment to modality-shared joint denoising.
If this is right
- Precise temporal audio-video synchronization is obtained without posterior alignment weakening co-evolution.
- Reference timbre cues associate with corresponding speech spans for controllable output.
- Audio quality remains competitive while video quality and synchronization improve.
- These outcomes hold for a 6.3B-parameter model evaluated on Verse-Bench and Seed-TTS.
Where Pith is reading between the lines
- The staged alignment-then-conditioning pattern may reduce objective interference when scaling model size or sequence length.
- The dedicated interaction space could be reused for other paired modalities that require decoupling of low-level timing from semantic context.
- Timbre-in-Context Conditioning indicates a template for span-specific injection of reference attributes in generation models.
Load-bearing premise
That establishing audio-video correspondence first in a dedicated interaction space, followed by external context conditioning on joint denoising, avoids the fine-grained co-evolution weakness of dual-tower designs and the semantic-lowlevel coupling of unified tri-modal designs.
What would settle it
A benchmark or user-study result in which a dual-tower or unified tri-modal baseline matches or exceeds NAVA on video quality, synchronization metrics, and timbre controllability on Verse-Bench.
Figures

read the original abstract
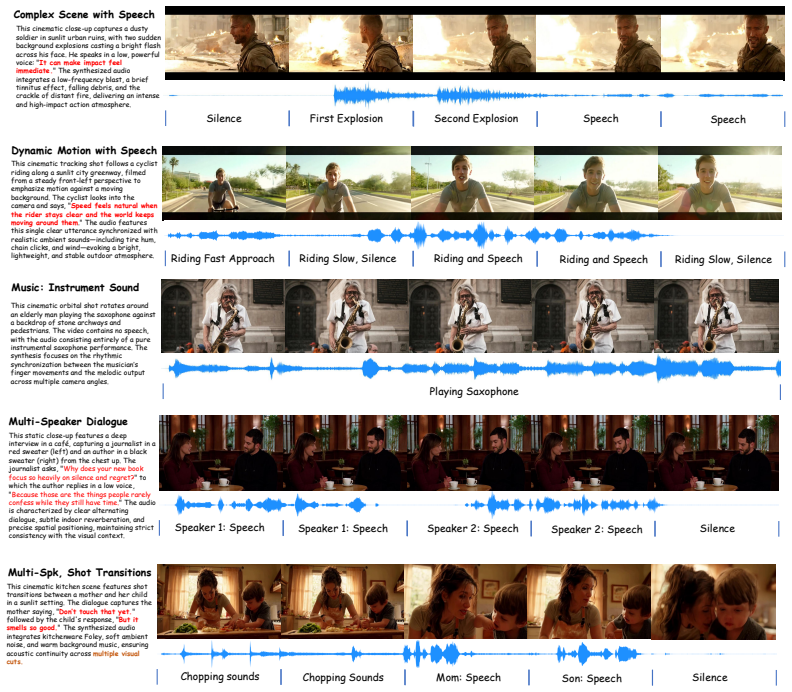
Joint audio-video generation aims to synthesize temporally synchronized and semantically coherent visual-acoustic content. However, existing open-source methods mainly rely on either dual-tower designs with posterior alignment or fully unified tri-modal designs that mix textual context, audio and video in one shared space. The former weakens fine-grained audio-video co-evolution, while the latter couples semantic conditioning with low-level synchronization. To address these limitations, we propose NAVA, a Native Audio-Visual Alignment framework for joint audio-video generation. NAVA is built upon context-conditioned native audio-visual alignment: it first establishes audio-video correspondence in a dedicated interaction space, and then uses external context to condition the joint denoising process. Specifically, NAVA is instantiated with an Align-then-Fuse MMDiT architecture, which transitions from modality-aware audio-video alignment to modality-shared joint denoising. Furthermore, we introduce Timbre-in-Context Conditioning to associate reference timbre cues with corresponding speech spans to achieve controllable speech timbre. Experiments on Verse-Bench and Seed-TTS, together with a user study, demonstrate that NAVA achieves superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability using only 6.3B parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NAVA, a Native Audio-Visual Alignment framework for joint audio-video generation. It first establishes audio-video correspondence in a dedicated interaction space before applying external context conditioning for joint denoising, instantiated via an Align-then-Fuse MMDiT architecture that transitions from modality-aware alignment to modality-shared denoising. It further proposes Timbre-in-Context Conditioning to link reference timbre cues with speech spans. Experiments on Verse-Bench and Seed-TTS plus a user study are reported to show superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability at 6.3B parameters.
Significance. If the performance claims hold under rigorous evaluation, the Align-then-Fuse design could provide a practical middle ground between dual-tower and unified tri-modal approaches for synchronized audio-video synthesis, with potential efficiency benefits from the parameter count and improved controllability for applications such as dubbing or multimedia content creation.
major comments (1)
- [Abstract] Abstract: the central claims of experimental superiority (video quality, synchronization, timbre controllability) and the user study validation are stated without any quantitative metrics, baseline comparisons, statistical tests, or ablation results, preventing assessment of whether the reported gains are load-bearing or robust.
minor comments (1)
- The abstract references Verse-Bench and Seed-TTS but provides no description of dataset characteristics, evaluation protocols, or how the 6.3B parameter count was measured relative to competitors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of experimental superiority (video quality, synchronization, timbre controllability) and the user study validation are stated without any quantitative metrics, baseline comparisons, statistical tests, or ablation results, preventing assessment of whether the reported gains are load-bearing or robust.
Authors: We acknowledge that the abstract presents the experimental claims at a high level without specific numbers. The full manuscript supplies the requested details in Sections 4 and 5: quantitative metrics and baseline comparisons on Verse-Bench and Seed-TTS (including video quality, AV synchronization, audio quality, and timbre controllability scores), ablation studies on the Align-then-Fuse MMDiT and Timbre-in-Context Conditioning components, and statistical results from the user study. These sections allow assessment of whether the gains are robust. We are prepared to incorporate a small number of key quantitative highlights into the abstract in revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and available text contain no equations, derivations, fitted parameters presented as predictions, or self-citation chains that reduce the central claims to inputs by construction. The architecture description (Align-then-Fuse MMDiT, Timbre-in-Context Conditioning) and reported improvements on Verse-Bench/Seed-TTS are presented as empirical outcomes rather than self-definitional or fitted-input results. No load-bearing uniqueness theorems or ansatzes imported via self-citation appear. This is the expected outcome for a paper whose contributions rest on architectural proposal and external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion-based joint denoising can be conditioned after initial modality alignment.
invented entities (2)
-
Align-then-Fuse MMDiT architecture
no independent evidence
-
Timbre-in-Context Conditioning
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Kling 3.0.https://kling.ai, 2026
Kuaishou Technology. Kling 3.0.https://kling.ai, 2026
2026
-
[3]
Veo 3.1, 2025
Google DeepMind. Veo 3.1, 2025. URLhttps://deepmind.google/models/veo
2025
-
[4]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Chetwin Low, Weimin Wang, and Calder Katyal. Ovi: Twin backbone cross-modal fusion for audio-video generation, 2025. URLhttps://arxiv.org/abs/2510.01284
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Mova: Towards scalable and synchronized video-audio generation.arXiv preprint arXiv:2602.08794, 2026
OpenMOSS Team, Donghua Yu, Mingshu Chen, Qi Chen, Qi Luo, Qianyi Wu, Qinyuan Cheng, Ruixiao Li, Tianyi Liang, Wenbo Zhang, et al. Mova: Towards scalable and synchronized video-audio generation.arXiv preprint arXiv:2602.08794, 2026
-
[7]
Ethan Chern, Hansi Teng, Hanwen Sun, Hao Wang, Hong Pan, Hongyu Jia, Jiadi Su, Jin Li, Junjie Yu, Lijie Liu, et al. Speed by simplicity: A single-stream architecture for fast audio-video generative foundation model.arXiv preprint arXiv:2603.21986, 2026
-
[8]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Duomin Wang, Wei Zuo, Aojie Li, Ling-Hao Chen, Xinyao Liao, Deyu Zhou, Zixin Yin, Xili Dai, Daxin Jiang, and Gang Yu. Universe-1: Unified audio-video generation via stitching of experts.arXiv preprint arXiv:2509.06155, 2025
-
[10]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality versatile speech generation models.arXiv preprint arXiv:2406.02430, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Xu Guo, Fulong Ye, Qichao Sun, Liyang Chen, Bingchuan Li, Pengze Zhang, Jiawei Liu, Song- tao Zhao, Qian He, and Xiangwang Hou. Dreamid-omni: Unified framework for controllable human-centric audio-video generation.arXiv preprint arXiv:2602.12160, 2026
-
[12]
Out of time: automated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wild. InAsian conference on computer vision, pages 251–263. Springer, 2016
2016
-
[13]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15180–15190, 2023
2023
-
[14]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, Carleigh Wood, Ann Lee, and Wei-Ning Hsu. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound. arXiv preprint arXiv:2502.05139, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text.Advances in neural information processing systems, 34:24206–24221, 2021
Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text.Advances in neural information processing systems, 34:24206–24221, 2021
2021
-
[19]
Video-to-audio generation with fine-grained temporal semantics.arXiv preprint arXiv:2409.14709, 2024
Yuchen Hu, Yu Gu, Chenxing Li, Rilin Chen, and Dong Yu. Video-to-audio generation with fine-grained temporal semantics.arXiv preprint arXiv:2409.14709, 2024
-
[20]
Temporally aligned audio for video with autoregression
Ilpo Viertola, Vladimir Iashin, and Esa Rahtu. Temporally aligned audio for video with autoregression. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[21]
Frieren: Efficient video-to-audio generation network with rectified flow matching.Advances in neural information processing systems, 37:128118–128138, 2024
Yongqi Wang, Wenxiang Guo, Rongjie Huang, Jiawei Huang, Zehan Wang, Fuming You, Ruiqi Li, and Zhou Zhao. Frieren: Efficient video-to-audio generation network with rectified flow matching.Advances in neural information processing systems, 37:128118–128138, 2024
2024
-
[22]
Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28901–28911, 2025
2025
-
[23]
Jun Wang, Xijuan Zeng, Chunyu Qiang, Ruilong Chen, Shiyao Wang, Le Wang, Wangjing Zhou, Pengfei Cai, Jiahui Zhao, Nan Li, et al. Kling-foley: Multimodal diffusion transformer for high-quality video-to-audio generation.arXiv preprint arXiv:2506.19774, 2025
-
[24]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721–725. IEEE, 2020
2020
-
[25]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:3339–3354, 2024
2024
-
[26]
Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation
Ludan Ruan, Yiyang Ma, Huan Yang, Huiguo He, Bei Liu, Jianlong Fu, Nicholas Jing Yuan, Qin Jin, and Baining Guo. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10219–10228, 2023
2023
-
[27]
Kai Liu, Wei Li, Lai Chen, Shengqiong Wu, Yanhao Zheng, Jiayi Ji, Fan Zhou, Jiebo Luo, Ziwei Liu, Hao Fei, et al. Javisdit: Joint audio-video diffusion transformer with hierarchical spatio-temporal prior synchronization.arXiv preprint arXiv:2503.23377, 2025
-
[28]
Guozhen Zhang, Zixiang Zhou, Teng Hu, Ziqiao Peng, Youliang Zhang, Yi Chen, Yuan Zhou, Qinglin Lu, and Limin Wang. Uniavgen: Unified audio and video generation with asymmetric cross-modal interactions.arXiv preprint arXiv:2511.03334, 2025
-
[29]
Klear: Unified multi-task audio-video joint generation.arXiv preprint arXiv:2601.04151, 2026
Jun Wang, Chunyu Qiang, Yuxin Guo, Yiran Wang, Xijuan Zeng, Chen Zhang, and Pengfei Wan. Klear: Unified multi-task audio-video joint generation.arXiv preprint arXiv:2601.04151, 2026. 12 6 Appendix 6.1 Data Pipeline Large-scale collection and preprocessing.We construct a large-scale audio-visual training corpus from heterogeneous sources, including Koala-3...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.