Future Forcing: Future-aware Training-free KV Cache Policy for Autoregressive Video Generation
Pith reviewed 2026-06-29 08:27 UTC · model grok-4.3
The pith
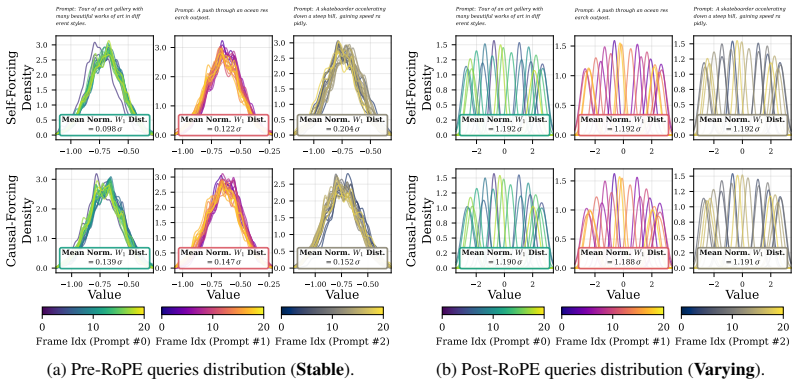
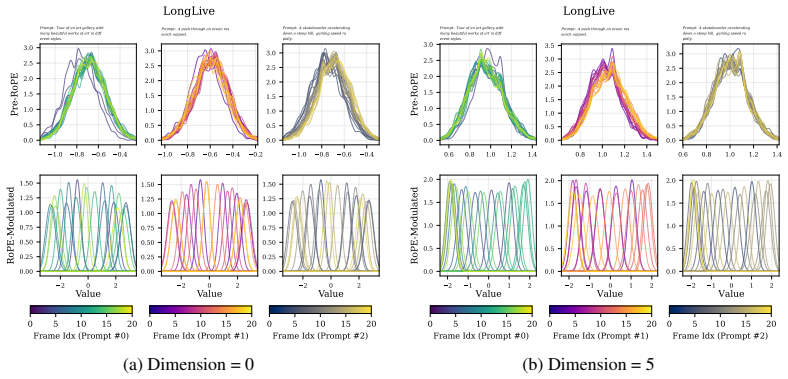
The pre-RoPE query distribution stays stable enough during autoregressive video generation that historical statistics can predict future query needs for KV cache management.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
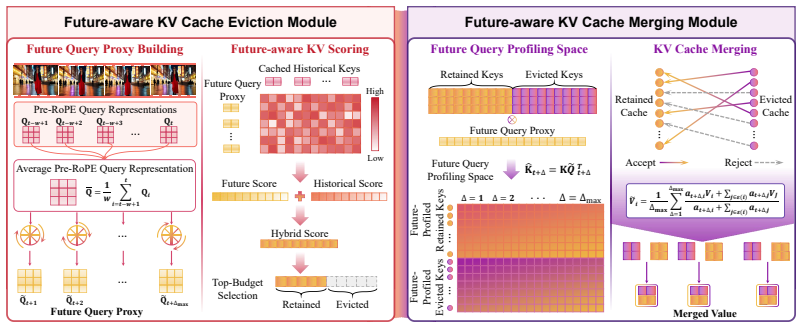
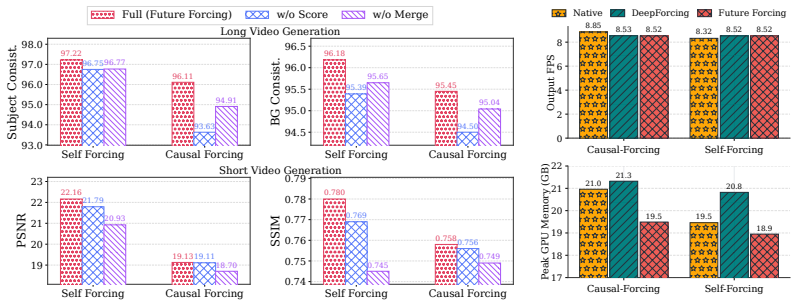
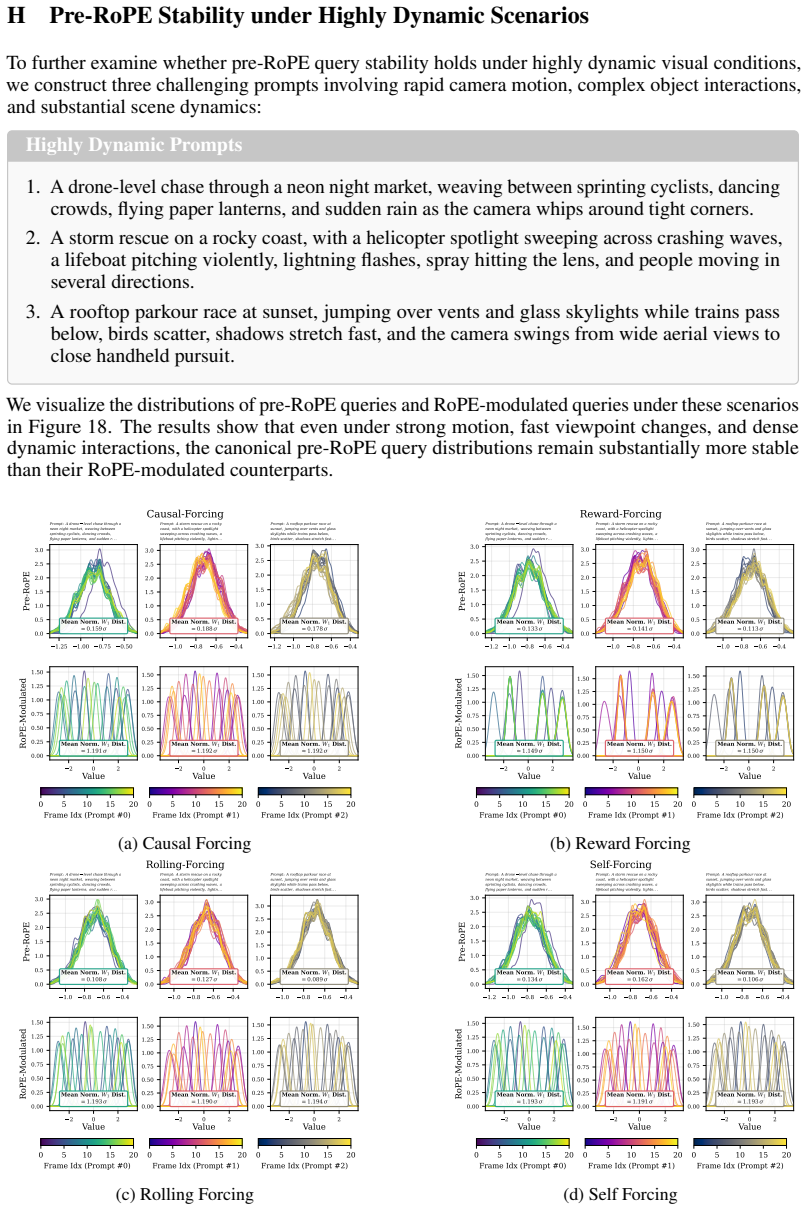
Although RoPE-modulated queries evolve across autoregressive steps, the underlying canonical pre-RoPE query distribution remains remarkably stable throughout the video generation process. This approximate stationarity implies that future query distributions are estimable from historical statistics, enabling principled future-aware cache decisions without any additional training. Future Forcing constructs a future query proxy from historical statistics, scores KV cache tokens by their importance under this proxy, and merges redundant token pairs within the affine subspace induced by the future query.
What carries the argument
Future query proxy constructed from historical pre-RoPE query statistics that scores KV tokens and defines merging subspaces.
Load-bearing premise
The canonical pre-RoPE query distribution must stay close enough to stationary that early statistics reliably estimate later query requirements.
What would settle it
Compare the distribution of pre-RoPE queries computed at the start versus the end of a long video generation; large shifts would mean the historical proxy no longer matches future needs.
Figures












read the original abstract
Autoregressive (AR) video generation has emerged as a promising paradigm for long-horizon video synthesis, where each frame is generated conditioned on previously generated tokens. To accelerate inference, the KV cache is used to avoid redundant recomputation across generation steps. Nevertheless, its growth with generation length introduces increasing memory and error accumulation, limiting the scalability of AR models to even longer sequences. Existing KV cache compression methods mitigate this issue by selectively retaining only video tokens deemed important. However, most existing methods assess token importance using short-horizon signals derived from the current or historical generation context, making these methods prone to overlooking tokens that appear unimportant at early steps but later become critical for future frames. In this work, we identify an important property of trained AR video models: although RoPE-modulated queries evolve across autoregressive steps, the underlying canonical pre-RoPE query distribution remains remarkably stable throughout the video generation process. This approximate stationarity implies that future query distributions are estimable from historical statistics, enabling principled future-aware cache decisions without any additional training. Building on this insight, we propose Future Forcing, a training-free future-aware KV cache policy for AR video generation. Specifically, Future Forcing first constructs a future query proxy from historical statistics, then scores KV cache tokens by their importance under this proxy, and finally merges redundant token pairs within the affine subspace induced by the future query. Extensive experiments show that Future Forcing improves long-horizon consistency under limited KV caches, achieving up to 1.49 improvement in subject consistency on VBench-Long for 60s generation over existing AR video KV cache policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies an approximate stationarity property in the canonical (pre-RoPE) query distribution of trained autoregressive video models, despite the evolution of RoPE-modulated queries across generation steps. This property is used to construct a future query proxy from historical statistics, enabling a training-free KV cache policy (Future Forcing) that scores token importance under the proxy and merges redundant pairs in the induced affine subspace. Experiments on VBench-Long report improvements in long-horizon consistency (up to 1.49 in subject consistency for 60s generation) over prior AR video KV cache policies.
Significance. If the stationarity holds across models and the proxy-derived importance scores correlate with those from true future queries, the method offers a practical way to improve memory efficiency and reduce error accumulation in long AR video synthesis without retraining. The training-free aspect and use of an empirical distributional property are notable strengths if the proxy is shown to preserve relevant attention patterns.
major comments (2)
- [Abstract] The central claim requires that the historical proxy not only matches marginal statistics but also produces token-importance rankings close to those obtained from actual future queries (i.e., that inner products or attention patterns with cached keys are preserved). The abstract presents stationarity as an empirical observation enabling the proxy but provides no quantitative evidence (e.g., correlation coefficients or ranking agreement on long sequences) that marginal stability suffices for this ranking task.
- [Abstract (method description)] Without reported ablations or verification on the proxy construction (e.g., how historical statistics are aggregated into the future query proxy and whether the affine-subspace merge preserves the necessary geometry), it is unclear whether the reported consistency gains are attributable to the future-aware component or to other implementation choices.
minor comments (1)
- [Abstract] The abstract states 'extensive experiments' but does not reference specific tables, figures, or metrics beyond the single 1.49 subject-consistency number; adding cross-model and cross-length results would strengthen the stationarity claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address the two major comments point by point below and will revise the manuscript to strengthen the presentation of evidence for the proxy.
read point-by-point responses
-
Referee: [Abstract] The central claim requires that the historical proxy not only matches marginal statistics but also produces token-importance rankings close to those obtained from actual future queries (i.e., that inner products or attention patterns with cached keys are preserved). The abstract presents stationarity as an empirical observation enabling the proxy but provides no quantitative evidence (e.g., correlation coefficients or ranking agreement on long sequences) that marginal stability suffices for this ranking task.
Authors: We agree that the abstract does not contain quantitative metrics such as correlation coefficients or ranking agreement to link the observed stationarity directly to preserved token-importance rankings. The manuscript reports end-to-end consistency gains but does not include these specific proxy-validation statistics in the abstract or main text. In the revision we will add a concise reference in the abstract and a new paragraph (with correlation and rank-agreement numbers computed on held-out long sequences) in Section 3 to demonstrate that the proxy rankings align with those from true future queries. revision: yes
-
Referee: [Abstract (method description)] Without reported ablations or verification on the proxy construction (e.g., how historical statistics are aggregated into the future query proxy and whether the affine-subspace merge preserves the necessary geometry), it is unclear whether the reported consistency gains are attributable to the future-aware component or to other implementation choices.
Authors: We concur that the absence of ablations on proxy aggregation and the affine-subspace merge leaves the source of the gains ambiguous. The current manuscript presents only the final policy and overall results. We will add a dedicated ablation subsection in the experiments that varies the aggregation window, the choice of historical moments, and the merge geometry, thereby isolating the contribution of the future-aware proxy. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents the stationarity of the canonical pre-RoPE query distribution as an empirical observation identified in trained AR video models, which then motivates the construction of a future query proxy for the KV cache policy. This observation is treated as an external property rather than derived from or reduced to the proposed Future Forcing method itself. The subsequent steps (proxy construction, token scoring, and merging) follow from this observation without any self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. The derivation chain remains self-contained against external benchmarks, with the stationarity serving as an independent premise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The canonical pre-RoPE query distribution remains approximately stationary during autoregressive video generation.
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1 0 (8): 0 1, 2024
2024
-
[2]
Genie: Generative interactive environments
Jake Bruce et al. Genie: Generative interactive environments. In ICML, 2024
2024
-
[3]
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Wen Xiao. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. COLM, 2025
2025
-
[4]
Past-and future-informed kv cache policy with salience estimation in autoregressive video diffusion
Hanmo Chen, Chenghao Xu, Xu Yang, Xuan Chen, and Cheng Deng. Past-and future-informed kv cache policy with salience estimation in autoregressive video diffusion. arXiv preprint arXiv:2601.21896, 2026 a
-
[5]
Context forcing: Consistent autoregressive video generation with long context
Shuo Chen et al. Context forcing: Consistent autoregressive video generation with long context. arXiv preprint arXiv:2602.06028, 2026 b
-
[6]
Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple characters
Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, and Qinglin Lu. Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple characters. arXiv preprint arXiv:2505.20156, 2025
-
[7]
Flash A ttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flash A ttention-2: Faster attention with better parallelism and work partitioning. In ICLR, 2024
2024
-
[8]
Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . Flash A ttention: Fast and memory-efficient exact attention with IO -awareness. In NeurIPS, 2022
2022
-
[9]
Veo 3 technical report
Google DeepMind. Veo 3 technical report. Technical report, Google DeepMind, 2024
2024
-
[10]
Autoregressive Video Generation without Vector Quantization
Haoge Deng et al. Autoregressive video generation without vector quantization. arXiv preprint arXiv:2412.14169, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Efficient autoregressive video diffusion with dummy head
Hang Guo, Zhaoyang Jia, Jiahao Li, Bin Li, Yuanhao Cai, Jiangshan Wang, Yawei Li, and Yan Lu. Efficient autoregressive video diffusion with dummy head. arXiv preprint arXiv:2601.20499, 2026
-
[12]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen et al. LTX-Video : Realtime video latent diffusion. arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Cogvideo: Large-scale pretraining for text-to-video generation via transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. ICLR, 2023
2023
-
[14]
Self forcing: Bridging the train-test gap in autoregressive video diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. NeurIPS, 2025
2025
-
[15]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. CVPR, 2024
2024
-
[16]
Videoar: Autoregressive video generation via next-frame & scale prediction
Longbin Ji et al. Videoar: Autoregressive video generation via next-frame & scale prediction. arXiv preprint arXiv:2601.05966, 2026
-
[17]
Pyramidal flow matching for efficient video generative modeling
Yang Jin et al. Pyramidal flow matching for efficient video generative modeling. ICLR, 2025
2025
-
[18]
Videopoet: A large language model for zero-shot video generation
Dan Kondratyuk et al. Videopoet: A large language model for zero-shot video generation. ICML, 2024
2024
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Train short, inference long: Training-free horizon extension for autoregressive video generation
Jia Li et al. Train short, inference long: Training-free horizon extension for autoregressive video generation. arXiv preprint arXiv:2602.14027, 2026 a
-
[21]
Kunyang Li, Mubarak Shah, and Yuzhang Shang. Packcache: A training-free acceleration method for unified autoregressive video generation via compact kv-cache. arXiv preprint arXiv:2601.04359, 2026 b
-
[22]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time. NeurIPS, 2023
2023
-
[24]
Vrope: Rotary position embedding for video large language models
Zikang Liu, Longteng Guo, Yepeng Tang, Junxian Cai, Kai Ma, Xi Chen, and Jing Liu. Vrope: Rotary position embedding for video large language models. arXiv preprint arXiv:2502.11664, 2025 b
-
[25]
Yunhong Lu et al. Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation. arXiv preprint arXiv:2512.04678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
Guoqing Ma et al. Step-Video-T2V technical report: The practice, challenges, and future of video foundation model. arXiv preprint arXiv:2502.10248, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Latte : Latent diffusion transformer for video generation
Xin Ma et al. Latte : Latent diffusion transformer for video generation. TMLR, 2025 b
2025
-
[28]
Flow caching for autoregressive video generation
Yuexiao Ma, Xuzhe Zheng, Jing Xu, Xiwei Xu, Feng Ling, Xiawu Zheng, Huafeng Kuang, Huixia Li, Xing Wang, Xuefeng Xiao, et al. Flow caching for autoregressive video generation. arXiv preprint arXiv:2602.10825, 2026
-
[29]
Xiaofeng Mao, Shaohao Rui, Kaining Ying, Bo Zheng, Chuanhao Li, Mingmin Chi, and Kaipeng Zhang. Packforcing: Short video training suffices for long video sampling and long context inference. arXiv preprint arXiv:2603.25730, 2026
-
[30]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak et al. Movie Gen : A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Kv cache quantization for self-forcing video generation: A 33-method empirical study
Suraj Ranganath, Vaishak Menon, and Anish Patnaik. Kv cache quantization for self-forcing video generation: A 33-method empirical study. arXiv preprint arXiv:2603.27469, 2026
-
[32]
Dvir Samuel, Issar Tzachor, Matan Levy, Micahel Green, Gal Chechik, and Rami Ben-Ari. Fast autoregressive video diffusion and world models with temporal cache compression and sparse attention. arXiv preprint arXiv:2602.01801, 2026
-
[33]
Roformer: Enhanced transformer with rotary position embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 2021
2021
-
[34]
Ar-diffusion: Asynchronous video generation with auto-regressive diffusion
Mingzhen Sun, Weining Wang, Gen Li, Jiawei Liu, Jiahui Sun, Wanquan Feng, Shanshan Lao, SiYu Zhou, Qian He, and Jing Liu. Ar-diffusion: Asynchronous video generation with auto-regressive diffusion. arXiv preprint arXiv:2503.07418, 2025
-
[35]
Genmo Team. Mochi 1. https://github.com/genmoai/models, 2024
2024
-
[36]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report. arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Phenaki: Variable length video generation from open domain textual descriptions
Ruben Villegas et al. Phenaki: Variable length video generation from open domain textual descriptions. In ICLR, 2023
2023
-
[38]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Image quality assessment: From error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 13 0 (4): 0 600--612, 2004
2004
-
[40]
Videorope: What makes for good video rotary position embedding? ICML, 2025
Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Jian Tong, Haodong Duan, Qipeng Guo, Jiaqi Wang, Xipeng Qiu, and Dahua Lin. Videorope: What makes for good video rotary position embedding? ICML, 2025
2025
-
[41]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report. arXiv preprint arXiv:2511.18870, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Pack and force your memory: Long-form and consistent video generation
Xiaofei Wu et al. Pack and force your memory: Long-form and consistent video generation. arXiv preprint arXiv:2510.01784, 2025 b
-
[43]
Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Haocheng Xi, Shuo Yang, Yilong Zhao, Muyang Li, Han Cai, Xingyang Li, Yujun Lin, Zhuoyang Zhang, Jintao Zhang, Xiuyu Li, Zhiying Xu, Jun Wu, Chenfeng Xu, Ion Stoica, Song Han, and Kurt Keutzer. Quant videogen: Auto-regressive long video generation via 2-bit kv-cache quantization. arXiv preprint arXiv:2602.02958, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Progressive autoregressive video diffusion models
Desai Xie, Zhan Xu, Yicong Hong, Hao Tan, Difan Liu, Feng Liu, Arie Kaufman, and Yang Zhou. Progressive autoregressive video diffusion models. arXiv preprint arXiv:2410.08151, 2024
-
[45]
Boxun Xu, Yuming Du, Zichang Liu, Siyu Yang, Ziyang Jiang, Siqi Yan, Rajasi Saha, Albert Pumarola, Wenchen Wang, and Peng Li. Sparse forcing: Native trainable sparse attention for real-time autoregressive diffusion video generation. arXiv preprint arXiv:2604.21221, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
VideoGPT: Video Generation using VQ-VAE and Transformers
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[47]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang et al. Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Anchor forcing: Anchor memory and tri-region rope for interactive streaming video diffusion
Yang Yang, Tianyi Zhang, Wei Huang, Jinwei Chen, Boxi Wu, Xiaofei He, Deng Cai, Bo Li, and Peng-Tao Jiang. Anchor forcing: Anchor memory and tri-region rope for interactive streaming video diffusion. arXiv preprint arXiv:2603.13405, 2026
-
[49]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. ICLR, 2025 b
2025
-
[50]
Deep forcing: Training-free long video generation with deep sink and participative compression
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081, 2025
-
[51]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin et al. From slow bidirectional to fast autoregressive video diffusion models. In CVPR, 2025
2025
-
[52]
Videomar: Autoregressive video generation with continuous tokens
Hu Yu et al. Videomar: Autoregressive video generation with continuous tokens. arXiv preprint arXiv:2506.14168, 2025 a
-
[53]
Yifei Yu et al. Videossm: Autoregressive long video generation with hybrid state-space memory. arXiv preprint arXiv:2512.04519, 2025 b
-
[54]
Helios: Real real-time long video generation model
Shenghai Yuan et al. Helios: Real real-time long video generation model. arXiv preprint arXiv:2603.04379, 2026
-
[55]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018
2018
-
[56]
Cam: Cache merging for memory-efficient llms inference
Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji. Cam: Cache merging for memory-efficient llms inference. In ICML, 2024
2024
-
[57]
H _2 o: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R \'e , Clark Barrett, Zhangyang Wang, and Beidi Chen. H _2 o: Heavy-hitter oracle for efficient generative inference of large language models. NeurIPS, 2023
2023
-
[58]
Relax forcing: Relaxed kv-memory for consistent long video generation
Zengqun Zhao, Yanzuo Lu, Ziquan Liu, Jifei Song, Jiankang Deng, and Ioannis Patras. Relax forcing: Relaxed kv-memory for consistent long video generation. arXiv preprint arXiv:2603.21366, 2026
-
[59]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng et al. Open-Sora : Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
Taming teacher forcing for masked autoregressive video generation
Deyu Zhou et al. Taming teacher forcing for masked autoregressive video generation. arXiv preprint arXiv:2501.12389, 2025
-
[61]
Hongzhou Zhu et al. Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation. arXiv preprint arXiv:2602.02214, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[62]
Hiar: Efficient autoregressive long video generation via hierarchical denoising
Kai Zou et al. Hiar: Efficient autoregressive long video generation via hierarchical denoising. arXiv preprint arXiv:2603.08703, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.