Distributionally Robust Set Representation Learning Under Inference-Time Element Corruption
Pith reviewed 2026-06-29 08:59 UTC · model grok-4.3
The pith
SW-DRSO trains set representation models to minimize worst-case loss over plausible element corruptions at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
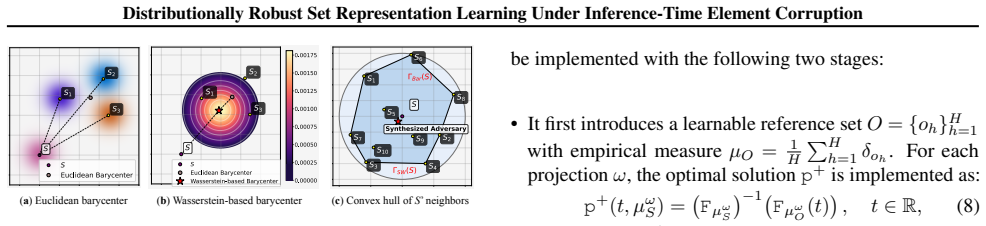
Rather than minimizing loss solely on observed training data, SW-DRSO optimizes a tractable surrogate of the worst-case expected loss over a family of plausible inference-time variations. It introduces a barycentric adversary that approximates the intractable search over corrupted sets by a differentiable training-time optimization over simplex weights.
What carries the argument
Barycentric adversary, which approximates the worst-case corruption search by optimizing simplex weights differentiably during training.
If this is right
- Trained models maintain high performance on clean sets while resisting degradation from outliers or missing elements at inference.
- The method applies across multiple set representation tasks without changing the underlying encoder architecture.
- Training explicitly accounts for distribution shifts that occur only after deployment.
- The surrogate optimization remains computationally feasible because the adversary operates over simplex weights rather than full set enumerations.
Where Pith is reading between the lines
- The same worst-case surrogate idea could be tested on sequence or graph data where element-level noise appears only at test time.
- Tighter bounds might be obtained by replacing the barycentric approximation with a learned adversary network.
- The framework suggests a general recipe for making any set encoder robust by adding a training-time adversary over plausible corruptions.
Load-bearing premise
The barycentric adversary sufficiently approximates the intractable worst-case search over corrupted sets and the chosen family of variations covers the relevant corruptions.
What would settle it
A controlled test where SW-DRSO is applied to a corruption type deliberately excluded from the variation family and shows no robustness gain over standard training.
Figures

read the original abstract
Standard Set Representation Learning methods typically excel on curated data but often overlook the challenge of inference-time element corruption. This refers to scenarios where deployed models encounter element-level degradations, such as outliers or missing components, that may distort set representation and degrade performance. We propose SW-DRSO, a distributionally robust optimization framework tailored for sets. Rather than minimizing loss solely on observed training data, SW-DRSO optimizes a tractable surrogate of the worst-case expected loss over a family of plausible inference-time variations. We introduce a barycentric adversary that approximates the intractable search over corrupted sets by a differentiable training-time optimization over simplex weights. Extensive experiments across four tasks demonstrate that SW-DRSO effectively enhances robustness against corruption while maintaining high overall performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SW-DRSO, a distributionally robust optimization framework for set representation learning. Instead of minimizing loss on observed training data, it optimizes a tractable surrogate of the worst-case expected loss over a family of plausible inference-time element corruptions (outliers, missing components). The key technical device is a barycentric adversary that approximates the intractable sup over corrupted sets via differentiable optimization over simplex weights. Experiments on four tasks are reported to show improved robustness to corruption while preserving overall performance.
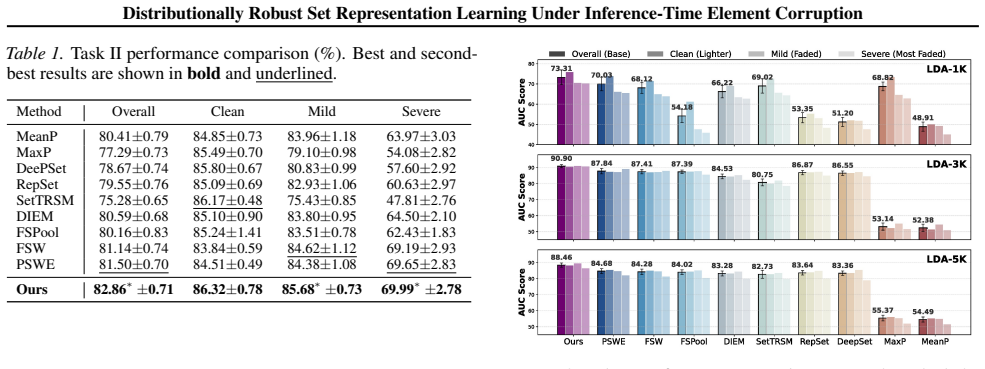
Significance. If the barycentric surrogate is sufficiently tight, the framework would address a practically relevant gap between curated training sets and inference-time degradations in set-based models. The differentiability of the training-time adversary is a methodological strength that could enable end-to-end robust training. The significance is currently limited by the absence of verification that the chosen simplex parameterization and variation family capture the relevant worst-case corruptions.
major comments (1)
- [Method description of the barycentric adversary (around the definition of the surrogate objective)] The central claim that SW-DRSO enhances robustness rests on the barycentric adversary providing a sufficiently tight surrogate for the intractable worst-case search over corrupted sets. No theoretical bound, tightness analysis, or ablation against stronger adversaries (e.g., structured outliers outside the simplex family) is provided to substantiate this approximation quality. Without such verification, the reported gains on the four tasks may not generalize beyond the modeled corruption family.
minor comments (1)
- The abstract and method overview would benefit from explicit notation for the set corruption model and the precise definition of the plausible variation family before introducing the barycentric weights.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment identifies a key limitation in the validation of the barycentric surrogate, which we address below with planned revisions.
read point-by-point responses
-
Referee: The central claim that SW-DRSO enhances robustness rests on the barycentric adversary providing a sufficiently tight surrogate for the intractable worst-case search over corrupted sets. No theoretical bound, tightness analysis, or ablation against stronger adversaries (e.g., structured outliers outside the simplex family) is provided to substantiate this approximation quality. Without such verification, the reported gains on the four tasks may not generalize beyond the modeled corruption family.
Authors: We agree that the absence of a theoretical bound or explicit tightness analysis limits the strength of the claims regarding generalization. The barycentric formulation is selected specifically to yield a differentiable surrogate via simplex weights, enabling end-to-end training while modeling convex combinations that capture element-level corruptions such as outliers (low weights) and missing components (zero weights). However, we recognize that this does not automatically guarantee tightness against all possible worst-case corruptions. In the revised manuscript we will add a dedicated discussion of the approximation's scope and limitations, together with an empirical ablation comparing the simplex adversary against alternative parameterizations that permit structured perturbations outside the current family. revision: partial
- A theoretical bound establishing the tightness of the barycentric surrogate relative to the true worst-case over corrupted sets
Circularity Check
No significant circularity; derivation introduces independent approximation without reduction to inputs
full rationale
The abstract and description present SW-DRSO as a new distributionally robust framework that introduces a barycentric adversary as a tractable surrogate for worst-case search over corrupted sets. No equations, self-citations, or fitted-parameter renamings are visible that would make any prediction equivalent to its inputs by construction. The central claim rests on the proposed approximation and experimental validation rather than self-referential definitions or load-bearing prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning prototype-oriented set representations for meta- learning.arXiv preprint arXiv:2110.09140,
Guo, D., Tian, L., Zhang, M., Zhou, M., and Zha, H. Learning prototype-oriented set representations for meta- learning.arXiv preprint arXiv:2110.09140,
-
[2]
Dynamic embedding size search with minimum regret for streaming recommender system
He, B., He, X., Zhang, R., Zhang, Y ., Tang, R., and Ma, C. Dynamic embedding size search with minimum regret for streaming recommender system. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management, pp. 741–750, 2023a. He, B., He, X., Zhang, Y ., Tang, R., and Ma, C. Dynamically expandable graph convolution for str...
-
[3]
He, B., Chen, Y ., Zhang, X., Kong, L., Yu, P. S., Liu, X., and Ma, C. Pedagogically-inspired data synthesis for language model knowledge distillation.arXiv preprint arXiv:2602.12172, 2026a. He, B., Hu, M., Xu, Z., Wang, H., Zong, L., Chen, Y ., Ma, C., Liu, X., Zhou, P., and King, I. Search-r2: Enhancing search-integrated reasoning via actor-refiner coll...
-
[4]
P., Wu, Y ., Li, D., Chen, Y ., Zhang, W., Li, Y ., Zangari, A., Guo, J., Miao, C., et al
10 Distributionally Robust Set Representation Learning Under Inference-Time Element Corruption Huang, W.-C., Zou, H. P., Wu, Y ., Li, D., Chen, Y ., Zhang, W., Li, Y ., Zangari, A., Guo, J., Miao, C., et al. Deep- researchguard: Deep research with open-domain evalua- tion and multi-stage guardrails for safety.arXiv preprint arXiv:2510.10994,
-
[5]
Li, D., Tan, S., Zhang, Y ., Jin, M., Pan, S., Okumura, M., and Jiang, R. Dyg-mamba: Continuous state space model- ing on dynamic graphs.Advances in Neural Information Processing Systems, 38:129101–129130, 2026a. Li, D., Zhang, Y ., Wu, Y ., and Jiang, R. Node role-guided llms for dynamic graph clustering. InProceedings of the ACM Web Conference 2026, pp....
-
[6]
Lin, M., Chen, Q., and Yan, S. Network in network.arXiv preprint arXiv:1312.4400,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Luo, H., Deng, Z., Huang, H., Liu, X., Chen, R., and Liu, Z. Versusdebias: Universal zero-shot debiasing for text- to-image models via slm-based prompt engineering and generative adversary.arXiv preprint arXiv:2407.19524,
-
[8]
AtelierEval: Agentic Evaluation of Humans & LLMs as Text-to-Image Prompters
Luo, H., Jin, Y ., Wang, Y ., Li, X., Shang, T., Liu, X., Chen, R., Wang, K., Salam, H., Wen, Q., and Liu, Z. Dynam- icner: A dynamic, multilingual, and fine-grained dataset for llm-based named entity recognition. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025a. Luo, H., Dai, S., Ni, C., Li, X., Zhang, G., W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Rahimian, H. and Mehrotra, S. Distributionally robust op- timization: A review.arXiv preprint arXiv:1908.05659,
-
[10]
Rezatofighi, S. H., Kaskman, R., Motlagh, F. T., Shi, Q., Cremers, D., Leal-Taix´e, L., and Reid, I. Deep perm-set net: Learn to predict sets with unknown permutation and cardinality using deep neural networks.arXiv preprint arXiv:1805.00613,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case gener- alization.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[12]
3d shapenets: A deep representation for volumetric shapes
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., and Xiao, J. 3d shapenets: A deep representation for volumetric shapes. InProceedings of the IEEE CVPR, pp. 1912–1920,
1912
-
[13]
Xu, F., Jiang, S., Huang, Z., Luo, X., Zhang, S., Chen, A., and Sun, Y . Fuse: Measure-theoretic compact fuzzy set representation for taxonomy expansion.arXiv preprint arXiv:2506.08409,
-
[14]
CoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Zhang, H., Fan, S., Zou, H. P., Chen, Y ., Wang, Z., Zhou, J., Li, C., Huang, W.-C., Yao, Y ., Zheng, K., et al. Co- evoskills: Self-evolving agent skills via co-evolutionary verification.arXiv preprint arXiv:2604.01687, 2026a. Zhang, Q., Zhou, Y ., Khan, S., Prater-Bennette, A., Shen, L., and Zou, S. Revisiting large-scale non-convex distri- butionally r...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zhang, X., Chen, Y ., Gao, C., Liao, Q., Zhao, S., and King, I. Knowledge-aware neural networks with personalized feature referencing for cold-start recommendation.arXiv preprint arXiv:2209.13973,
-
[16]
From token to item: Enhancing large language models for rec- ommendation via item-aware attention mechanism
Zhang, X., He, B., Chen, J., Cui, Z., and Ma, C. From token to item: Enhancing large language models for rec- ommendation via item-aware attention mechanism. In Proceedings of the ACM Web Conference 2026, pp. 6700– 6708, 2026b. Zhang, Y ., Hare, J., and Pr¨ugel-Bennett, A. Learning rep- resentations of sets through optimized permutations. In ICLR,
2026
-
[17]
covering radius
Table 8.Summary of notation used throughout the paper. Symbol Description X ⊆R d,YElement space of individual set elements and label space xi ∈ XThei-th element in a set S={x i}n i=1,S ′ Unordered input set with cardinalitynand corrupted version of setSat inference time S(X)Space of all finite subsets ofX f:S(X)→R c Permutation-invariant set encoder vS =f...
2021
-
[18]
hidden sets
Proof of Eq. (3).For any two measuresµ, νonR d, expanding the squaredℓ 2 distance yields fSW(µ)−f SW(ν) 2 2 (26) = 1 RH RX r=1 HX h=1 p+(tωr h , µωr)−p +(tωr h , νωr) 2 .(27) Let uωr h :=F µωr O (tωr h )∈(0,1) . By definition of p+, p+(tωr h , µωr) = Fµωr −1 (uωr h ). Then in 1D, the squared 2- Wasserstein distance admits the quantile form: W 2(µωr , νωr)...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.