Recognition: 2 theorem links
· Lean TheoremCoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Pith reviewed 2026-05-13 21:36 UTC · model grok-4.3
The pith
CoEvoSkills lets LLM agents autonomously build complex multi-file skills by co-evolving a generator with a surrogate verifier that gives feedback without ground-truth tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
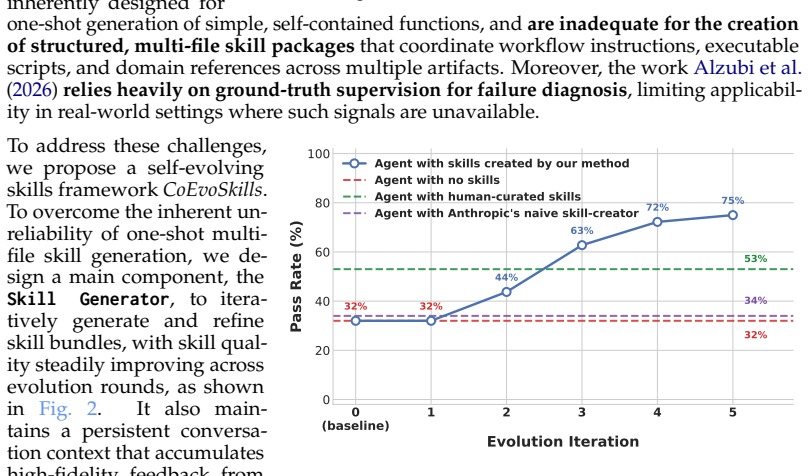
CoEvoSkills couples a Skill Generator that iteratively refines skills with a Surrogate Verifier that co-evolves to provide informative and actionable feedback without access to ground-truth test content, achieving the highest pass rate among five baselines on both Claude Code and Codex while showing strong generalization to six additional LLMs.
What carries the argument
The co-evolutionary loop between the Skill Generator and Surrogate Verifier, where the verifier supplies feedback to refine generated multi-file skill packages without seeing test ground truth.
If this is right
- Agents can generate and refine skills autonomously, reducing the need for manual human authoring of complex packages.
- Iterative co-evolution improves skill alignment with agent capabilities, leading to higher success on professional multi-step tasks.
- The framework generalizes beyond the primary models to additional LLMs, suggesting broad applicability.
- Skills become more robust through repeated refinement cycles driven by surrogate signals.
Where Pith is reading between the lines
- This approach could lower the barrier to deploying capable agents in new domains by automating what was previously manual skill engineering.
- The co-evolution pattern between generator and verifier might transfer to refining other agent elements such as planning routines or memory structures.
- If the surrogate feedback proves reliable, similar loops could support ongoing skill maintenance in deployed systems without fresh human labels.
Load-bearing premise
A surrogate verifier can supply informative and actionable feedback for skill refinement without any access to ground-truth test content.
What would settle it
Evaluating CoEvoSkills on SkillsBench and observing that its pass rates fail to exceed the five baselines on Claude Code or Codex would disprove the performance advantage.
Figures





read the original abstract
Anthropic proposes the concept of skills for LLM agents to tackle multi-step professional tasks that simple tool invocations cannot address. A tool is a single, self-contained function, whereas a skill is a structured bundle of interdependent multi-file artifacts. Currently, skill generation is not only label-intensive due to manual authoring, but also may suffer from human--machine cognitive misalignment, which can lead to degraded agent performance, as evidenced by evaluations on SkillsBench. Therefore, we aim to enable agents to autonomously generate skills. However, existing self-evolving methods designed for tools cannot be directly applied to skills due to their increased complexity. To address these issues, we propose CoEvoSkills, a self-evolving skills framework that enables agents to autonomously construct complex, multi-file skill packages. Specifically, CoEvoSkills couples a Skill Generator that iteratively refines skills with a Surrogate Verifier that co-evolves to provide informative and actionable feedback without access to ground-truth test content. On SkillsBench, CoEvoSkills achieves the highest pass rate among five baselines on both Claude Code and Codex, and also exhibits strong generalization capabilities to six additional LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoEvoSkills, a framework enabling LLM agents to autonomously generate complex multi-file skills for professional tasks. It introduces a Skill Generator that iteratively refines skills in tandem with a co-evolving Surrogate Verifier, which supplies feedback without access to ground-truth test content. The central empirical claim is that this approach yields the highest pass rate on SkillsBench among five baselines when tested on Claude Code and Codex, while also generalizing to six additional LLMs.
Significance. If the performance gains are robust, the work would meaningfully advance autonomous skill acquisition for agents, reducing dependence on manual authoring and mitigating human-machine misalignment. The co-evolutionary verification mechanism without ground truth represents a distinctive contribution to self-improving agent systems, provided it can be shown to deliver genuine rather than spurious improvements.
major comments (3)
- [Abstract] Abstract: The claim that CoEvoSkills achieves the highest pass rate among five baselines on Claude Code and Codex is presented without any description of baseline implementations, statistical significance tests, variance across runs, or controls for prompt sensitivity. This absence makes the central performance superiority difficult to evaluate and potentially non-reproducible.
- [Abstract] Abstract and method description: The Surrogate Verifier is asserted to provide 'informative and actionable feedback' without ground-truth test content, yet no mechanism details, ablation results, or correlation analysis between verifier signals and downstream pass-rate gains on SkillsBench are supplied. Without such evidence, it remains possible that reported gains arise from closed-loop bias amplification between generator and verifier rather than true capability improvement.
- [Abstract] Abstract: The generalization claim to six additional LLMs is stated without identifying the models, reporting quantitative pass rates, or describing the evaluation protocol, rendering the breadth of the result impossible to assess from the given text.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of the size and composition of SkillsBench (number of tasks, skill complexity) to contextualize the reported pass rates.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We believe the comments highlight important areas for improving the clarity and completeness of our presentation. Below, we provide point-by-point responses to the major comments and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that CoEvoSkills achieves the highest pass rate among five baselines on Claude Code and Codex is presented without any description of baseline implementations, statistical significance tests, variance across runs, or controls for prompt sensitivity. This absence makes the central performance superiority difficult to evaluate and potentially non-reproducible.
Authors: We agree with the referee that the abstract lacks sufficient detail on these methodological aspects. In the revised manuscript, we will expand the abstract to briefly describe the baseline implementations, note that results include variance across runs and statistical significance tests, and mention controls for prompt sensitivity. Detailed descriptions remain in the main text and appendix, and we will release the code to ensure reproducibility. revision: yes
-
Referee: [Abstract] Abstract and method description: The Surrogate Verifier is asserted to provide 'informative and actionable feedback' without ground-truth test content, yet no mechanism details, ablation results, or correlation analysis between verifier signals and downstream pass-rate gains on SkillsBench are supplied. Without such evidence, it remains possible that reported gains arise from closed-loop bias amplification between generator and verifier rather than true capability improvement.
Authors: We agree that the initial submission did not provide sufficient mechanism details, ablation results, or correlation analysis for the Surrogate Verifier. We will revise the method section to include a more detailed explanation of the co-evolutionary verification process without ground-truth. Additionally, we will incorporate ablation studies and a correlation analysis between verifier signals and pass-rate improvements in the results section to rule out bias amplification and demonstrate genuine capability gains. revision: yes
-
Referee: [Abstract] Abstract: The generalization claim to six additional LLMs is stated without identifying the models, reporting quantitative pass rates, or describing the evaluation protocol, rendering the breadth of the result impossible to assess from the given text.
Authors: We agree that the abstract does not identify the specific LLMs or provide quantitative details. In the revision, we will update the abstract to list the six additional LLMs and report the key quantitative pass rates. The evaluation protocol is already described in the methods section, but we will add a summary sentence to the abstract for completeness. revision: yes
Circularity Check
No circularity: empirical benchmark claims rest on external evaluation
full rationale
The paper presents CoEvoSkills as an empirical framework coupling a Skill Generator with a co-evolving Surrogate Verifier. No equations, derivations, or fitted parameters are described that could reduce to self-definition or self-reinforcement by construction. Performance claims (highest pass rate on SkillsBench for Claude Code and Codex, generalization to six LLMs) are evaluated against external baselines and held-out test content, not against the method's own internal signals. Any self-citations that may exist in the full text are not load-bearing for a derivation chain, as the core argument is the observed benchmark improvement rather than a uniqueness theorem or ansatz imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can iteratively improve structured multi-file artifacts when given feedback from another model instance
invented entities (1)
-
Surrogate Verifier
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCoEvoSkills couples a Skill Generator that iteratively refines skills with a Surrogate Verifier that co-evolves to provide informative and actionable feedback without access to ground-truth test content... ˜R(x,V) ≜ 1/|V| ∑ 1[ek(x)]
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearThe Surrogate Verifier... operates in a completely independent LLM session... information isolation ensures that the verifier’s test generation is conditionally independent of the generator’s internal state
Forward citations
Cited by 11 Pith papers
-
From Context to Skills: Can Language Models Learn from Context Skillfully?
Ctx2Skill lets language models autonomously evolve context-specific skills via multi-agent self-play, improving performance on context learning tasks without human supervision.
-
Evolutionary Ensemble of Agents
EvE uses co-evolving populations of solvers and guidance states with Elo-based evaluation to autonomously discover a rescale-then-interpolate mechanism for better generalization in In-Context Operator Networks.
-
SkillGen: Verified Inference-Time Agent Skill Synthesis
SkillGen synthesizes auditable skills from agent trajectories via contrastive induction on successes and failures, then verifies net performance impact by comparing outcomes with and without the skill on identical tasks.
-
SkillMaster: Toward Autonomous Skill Mastery in LLM Agents
SkillMaster is a training framework that lets LLM agents autonomously propose, update, and apply skills, yielding 8.8% and 9.3% higher success rates on ALFWorld and WebShop than prior methods.
-
SkillMaster: Toward Autonomous Skill Mastery in LLM Agents
SkillMaster enables LLM agents to autonomously develop skills via trajectory review, counterfactual evaluation, and DualAdv-GRPO training, boosting success rates by 8.8% on ALFWorld and 9.3% on WebShop.
-
SkillLens: Adaptive Multi-Granularity Skill Reuse for Cost-Efficient LLM Agents
SkillLens organizes skills into policies-strategies-procedures-primitives layers, retrieves via degree-corrected random walk, and uses a verifier for local adaptation, yielding up to 6.31 pp gains on MuLocbench and ra...
-
ClawTrace: Cost-Aware Tracing for LLM Agent Skill Distillation
ClawTrace enables cost-aware LLM agent skill distillation by tracing per-step costs and generating preserve, prune, and repair patches, with ablations showing reduced regressions and prune rules transferring to cut co...
-
GAM: Hierarchical Graph-based Agentic Memory for LLM Agents
GAM decouples event-level memory encoding from topic-level consolidation in LLM agents using hierarchical graphs to reduce interference and improve long-term coherence and retrieval.
-
Ace-Skill: Bootstrapping Multimodal Agents with Prioritized and Clustered Evolution
Ace-Skill boosts multimodal agent self-evolution via prioritized rollouts with lazy-decay tracking and semantic knowledge clustering, yielding up to 35% relative gains on tool-use benchmarks and zero-shot transfer to ...
-
EvoAgent: An Evolvable Agent Framework with Skill Learning and Multi-Agent Delegation
EvoAgent is an evolvable LLM agent framework using structured skill learning, user-feedback loops, and hierarchical delegation that boosts GPT5.2 performance by about 28% in real-world trade scenarios under LLM-as-Jud...
-
SkillMOO: Multi-Objective Optimization of Agent Skills for Software Engineering
SkillMOO automatically evolves skill bundles for LLM coding agents via LLM-proposed edits and NSGA-II, achieving up to 131% higher pass rates and 32% lower costs on three SkillsBench tasks.
Reference graph
Works this paper leans on
-
[1]
The evolved skills are structured multi-file packages installed before agent test
CoEvoSkills(Full framework): the completeCoEvoSkillswith iterative skill evolution and surrogate verification. The evolved skills are structured multi-file packages installed before agent test
-
[2]
W/O surrogate verifier: skill evolution proceeds without the surrogate verifier. The generator produces a skill package with the background context, and then immediately submits it to the ground-truth oracle test. If the test fails, the generator evolves the skill using only the opaque pass/fail signal without synthesized diagnostic feedback from the veri...
-
[3]
The agent reads the background context and then directly attempts the task without evolution
W/O skill evolution: the surrogate generator and skill verifier are both removed. The agent reads the background context and then directly attempts the task without evolution
-
[4]
No-Skill Baseline: the agent directly attempts each task with the raw task instruction and environment. Ablation analysis.First, removing the surrogate verifier drops the pass rate from 71.1% to 41.1% (−30.0pp). The generator still evolves skills for up to 5 iterations, but relies solely on the oracle’s opaque pass/fail signal. This demonstrates that with...
-
[5]
WRITE PROGRESS FILE: Create /root/progress.md with the template above
-
[6]
Review the previous run context above (test failures, suggestions, skill changes)
-
[7]
evo-*" skills, load them FIRST: {{
LOAD EXISTING EVOLVED SKILLS: If available_skills lists any "evo-*" skills, load them FIRST: {{"load_skill": "evo-skill-name"}} These contain proven workflows and scripts from previous runs. Always reuse before creating new
-
[8]
DISCOVER ENVIRONMENT FILES [P1]: Run: 19 Preprint. Under review. ls -la /app/environment/ && find /app/environment/ -type f | head -50 && ls -la /root/ Note these files -- they contain INPUT data for the task. environment/ contains INPUT data only, not ground-truth answers. If a README_DATA.md exists in /app/environment/data/, READ IT FIRST -- it describe...
-
[9]
Use installed tools rather than assuming what is available
DISCOVER INSTALLED TOOLS [P1b]: Run: pip list 2>/dev/null | head -50 && apt list --installed 2>/dev/null | head -50 Review the output to understand what Python libraries and system tools are available. Use installed tools rather than assuming what is available. Then: sed -i's/- \[ \] P1b/- [x] P1b/'/root/progress.md
-
[10]
CREATE/UPDATE TASK SKILLS [P2]: a. Load skill-creator: {{"load_skill": "skill-creator"}} b. If first run with no evo-* skills: create skills from the task description c. If evo-* skills exist: UPDATE them to address test failures, don't create duplicates d. Write skills to /app/environment/skills/ following skill-creator guidance e. SKILL STRUCTURE: Follo...
-
[11]
SELF-REFLECTION [P3]: Before executing the task, verify your skill covers ALL requirements: a. Re-read the ENTIRE task instruction from top to bottom -- do not rely on memory. b. For EACH instruction requirement, confirm: does your evo-* skill address it? c. If reference docs exist in /app/environment/doc/, re-read them and verify d. If ANY gap exists, fi...
-
[12]
EXECUTE TASK [P4]: Load your evolved skills. The system will notify you of newly available skills. Load each one with {{"load_skill": "skill-name"}} before executing. Write a main script (e.g., /root/run.py) that IMPORTS from your skill's scripts/: import sys; sys.path.insert(0,'/app/environment/skills/evo-SKILLNAME/scripts') from utils import func_a, fun...
-
[13]
Analyze the failure details provided by the host b
FIX FAILURES [P5]: If the host verifier reports failures, fix your skill and re-run: a. Analyze the failure details provided by the host b. Update your evo-* skill's SKILL.md with the corrected logic/rules 20 Preprint. Under review. c. Update or add scripts in your skill's scripts/ directory that implement the fix d. Re-run your skill's script to regenera...
-
[14]
WRITE SUMMARY [P6]: Write an evolution summary to /root/evolution_summary.md containing: - Skills created/updated this run and what knowledge they capture - Specific improvements the next run should make - Any remaining issues or gaps you identified Then: sed -i's/- \[ \] P6/- [x] P6/'/root/progress.md
-
[15]
If any are unchecked, complete them NOW before signaling task_complete
VERIFY PROGRESS: cat /root/progress.md -- confirm ALL phases are [x]. If any are unchecked, complete them NOW before signaling task_complete
-
[16]
Signal task_complete. RULES: - You MUST write /root/progress.md at the START and update it after each phase - You MUST create or update skills BEFORE executing the task - You MUST load skill-creator to create skills properly - When you signal task_complete, the host will run an independent verifier - If the verifier finds failures, fix your skill scripts ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.