EvoRepair: Enhancing Vulnerability Repair Agents Through Experience-Based Self-Evolution
Pith reviewed 2026-06-29 06:14 UTC · model grok-4.3
The pith
EvoRepair lets LLMs accumulate and reuse repair experiences across vulnerabilities via a cyclic learn-and-repair loop with quality scoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvoRepair is the first experience-based self-evolving AVR agent framework that enables LLMs to accumulate, refine, and leverage domain-specific knowledge across long-horizon vulnerability repairs through a cyclic learn-and-repair process that retrieves relevant past experiences to guide repair, extracts new experiences from repair trajectories, and updates an experience bank using quality-aware scoring.
What carries the argument
The experience bank maintained by a cyclic retrieve-repair-extract-update loop that applies quality-aware scoring to decide what repair trajectories to retain and reuse.
If this is right
- LLMs avoid repeating similar mistakes across iterative repairs of the same vulnerability.
- Repair knowledge extracted from one vulnerability becomes available for unrelated future cases.
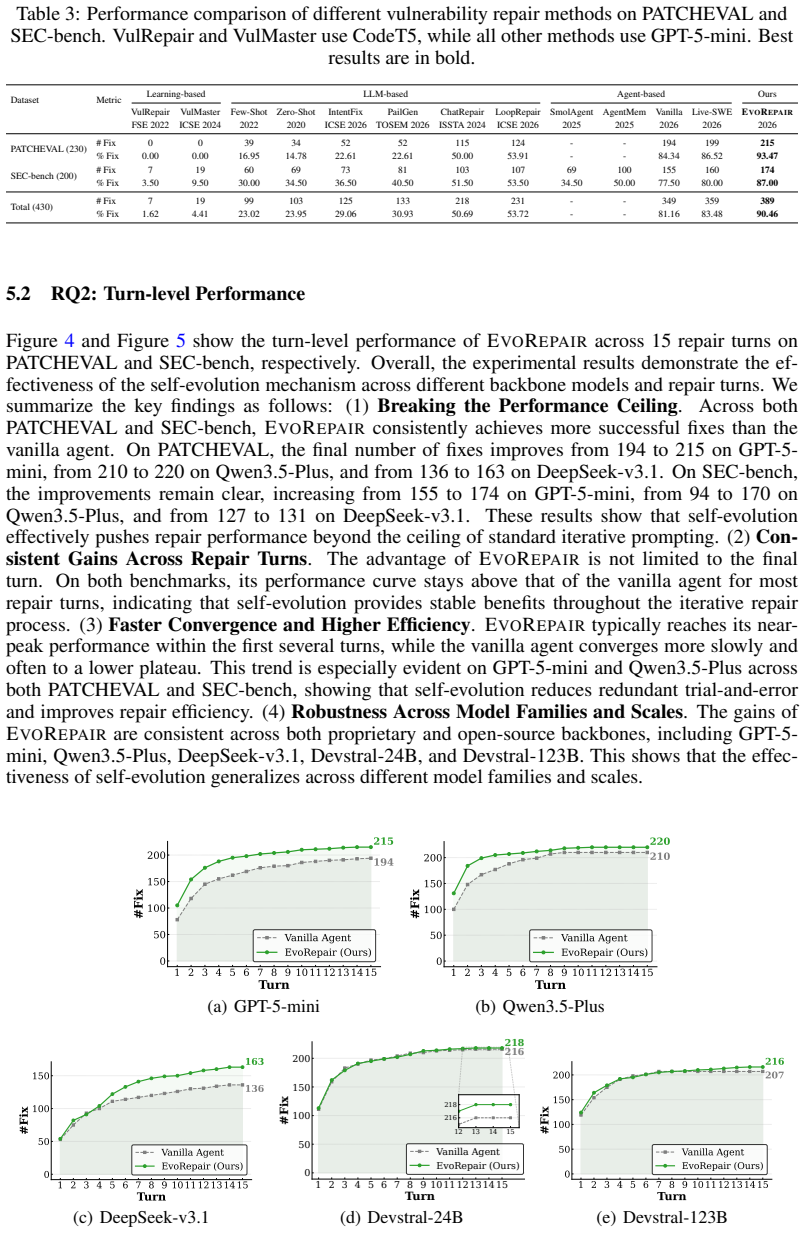
- Overall success reaches 93.47 percent on PATCHEVAL and 87.00 percent on SEC-bench when using GPT-5-mini.
- The approach exceeds recent LLM-based baselines such as LoopRepair by more than 33 percentage points on both benchmarks.
- Transfer experiments confirm the same gains hold across different models, programming languages, and datasets such as VUL4J.
Where Pith is reading between the lines
- The same retrieve-and-score loop could be applied to other agentic code tasks such as general bug fixing or test generation.
- Quality-aware scoring acts as a filter that may be essential for preventing degradation when experience volume grows large.
- Explicit generalization of stored experiences beyond direct retrieval could further increase reuse efficiency.
Load-bearing premise
The cyclic learn-and-repair process together with quality-aware scoring of repair trajectories will produce net-positive, reusable experiences rather than noise or harmful patterns that degrade future performance.
What would settle it
An experiment that runs EvoRepair on a long sequence of vulnerabilities and measures whether success rate on fresh cases falls below a non-evolving baseline after multiple cycles.
Figures


read the original abstract
Large Language Models (LLMs) have shown promise for automated vulnerability repair (AVR), but they still face several limitations, including the lack of intra-vulnerability experience accumulation and the lack of cross-vulnerability experience reuse. As a result, LLMs may repeatedly make similar mistakes during iterative repair and underutilize valuable repair knowledge from historical vulnerabilities. To address these challenges, we propose EvoRepair, the first experience-based self-evolving AVR agent framework that enables LLMs to accumulate, refine, and leverage domain-specific knowledge across long-horizon vulnerability repairs. EvoRepair follows a cyclic learn-and-repair process that retrieves relevant past experiences to guide repair, extracts new experiences from repair trajectories, and updates an experience bank using quality-aware scoring. We evaluate EvoRepair against 12 representative vulnerability repair baselines on PATCHEVAL and SEC-bench using GPT-5-mini. Results show that EvoRepair achieves the best overall performance, reaching 93.47% on PATCHEVAL, 87.00% on SEC-bench, and 90.46% overall. In particular, EvoRepair outperforms latest LLM-based baseline LoopRepair by 39.56% and 33.50% on PATCHEVAL and SEC-bench, respectively, and surpasses IntentFix by 70.86% and 50.50%. Across both benchmarks, EvoRepair also exceeds the recent self-evolving agent Live-SWE-Agent by 6.98% overall. Additional transfer experiments on VUL4J further demonstrate the robustness of EvoRepair across models, programming languages, and datasets. These findings demonstrate that experience-based self-evolution substantially strengthens agentic AVR and goes beyond existing self-evolving techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvoRepair, the first experience-based self-evolving agent framework for automated vulnerability repair (AVR). It introduces a cyclic learn-and-repair process in which an LLM agent retrieves relevant past experiences from an 'experience bank' to guide repairs, extracts new experiences from repair trajectories, and updates the bank using quality-aware scoring. The framework is evaluated against 12 baselines on PATCHEVAL and SEC-bench using GPT-5-mini, claiming best overall performance (93.47% on PATCHEVAL, 87.00% on SEC-bench, 90.46% overall) with large margins over LoopRepair, IntentFix, and Live-SWE-Agent; additional transfer results on VUL4J are reported.
Significance. If the empirical claims hold under rigorous evaluation, the work would be significant for the AVR and agentic LLM literature by demonstrating that explicit experience accumulation and cross-vulnerability reuse can substantially improve repair success rates beyond existing self-evolving techniques. The introduction of a reusable, quality-scored experience bank as a first-class component is a concrete architectural contribution that could be adopted more broadly.
major comments (2)
- [Abstract] Abstract: The performance claims (93.47% on PATCHEVAL, 87.00% on SEC-bench, and specific margins over LoopRepair and IntentFix) are presented without any description of the experimental protocol, baseline implementations, statistical tests, number of runs, or error analysis, rendering the central empirical claims impossible to evaluate from the supplied text.
- [Abstract] Abstract (paragraph describing the framework): The core assumption that the cyclic learn-and-repair process together with quality-aware scoring will produce net-positive, reusable experiences rather than noise or harmful patterns is stated but not supported by any analysis, ablation, or failure-case examination in the provided description; this assumption is load-bearing for the claim that experience-based self-evolution strengthens AVR.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract. We address each point below and will revise the manuscript accordingly to improve clarity and self-containment of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (93.47% on PATCHEVAL, 87.00% on SEC-bench, and specific margins over LoopRepair and IntentFix) are presented without any description of the experimental protocol, baseline implementations, statistical tests, number of runs, or error analysis, rendering the central empirical claims impossible to evaluate from the supplied text.
Authors: We acknowledge that the abstract's brevity precludes full experimental details. The complete protocol, baseline implementations, use of GPT-5-mini, three-run averages with standard deviations, and error analysis appear in Sections 4 and 5 of the manuscript. To make the abstract more self-contained, we will add a concise clause noting the evaluation setup and directing readers to the full experimental sections. revision: yes
-
Referee: [Abstract] Abstract (paragraph describing the framework): The core assumption that the cyclic learn-and-repair process together with quality-aware scoring will produce net-positive, reusable experiences rather than noise or harmful patterns is stated but not supported by any analysis, ablation, or failure-case examination in the provided description; this assumption is load-bearing for the claim that experience-based self-evolution strengthens AVR.
Authors: The abstract summarizes the framework at a high level. The manuscript supports the assumption with ablation studies on the experience bank (Section 5), quantitative metrics on experience quality and reuse rates, and failure-case analysis (Section 6) showing net-positive outcomes. We will revise the abstract to include a short qualifier indicating that these benefits are validated through ablations and analyses presented in the paper body. revision: partial
Circularity Check
No significant circularity; empirical agent framework with no derivation chain
full rationale
The paper presents an empirical agent framework for vulnerability repair, describing a cyclic learn-and-repair process evaluated on benchmarks (PATCHEVAL, SEC-bench, VUL4J) against baselines. No equations, fitted parameters, predictions derived from inputs, or mathematical derivations are present. Claims of performance improvements are supported by direct experimental comparisons rather than any self-referential reduction or self-citation chain that would make results equivalent to inputs by construction. The core assumption about experience accumulation is an empirical hypothesis tested via evaluation, not a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs benefit from retrieving and updating domain-specific repair experiences across multiple vulnerabilities
invented entities (1)
-
experience bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Last accessed: November 20, 2022
Infer static analyzer, 2022. Last accessed: November 20, 2022
2022
-
[2]
Last accessed: November 20, 2022
Spotbugs: Find bugs in java programs, 2022. Last accessed: November 20, 2022. 15
2022
-
[3]
Ahmad, S
B. Ahmad, S. Thakur, B. Tan, R. Karri, and H. Pearce. On hardware security bug code fixes by prompting large language models.IEEE Transactions on Information Forensics and Security, 19:4043–4057, 2024
2024
-
[4]
Bao and S
K. Bao and S. Chen. A smart contract vulnerability detection method based on graph neural networks and zero-shot learning. InInternational Conference on Blockchain and Trustworthy Systems, pages 32–46. Springer, 2025
2025
-
[5]
Belleville, W
B. Belleville, W. Shen, S. V olckaert, A. M. Azab, and M. Franz. KALD: detecting direct pointer disclosure vulnerabilities.IEEE Trans. Dependable Secur. Comput., 18(3):1369–1377,
-
[6]
URL https://doi.org/10.1109/TDSC.2019.2915829
doi: 10.1109/TDSC.2019.2915829. URL https://doi.org/10.1109/TDSC.2019.2915829
-
[7]
G. P. Bhandari, A. Naseer, and L. Moonen. Cvefixes: Automated collection of vulnerabilities and their fixes from open-source software.CoRR, abs/2107.08760, 2021. URL https://arxiv. org/abs/2107.08760
arXiv 2021
-
[8]
Bilge and T
L. Bilge and T. Dumitra¸ s. Before we knew it: an empirical study of zero-day attacks in the real world. InProceedings of the 2012 ACM conference on Computer and communications security, pages 833–844, 2012
2012
-
[9]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[10]
Q.-C. Bui, R. Scandariato, and N. E. D. Ferreyra. Vul4j: A dataset of reproducible java vul- nerabilities geared towards the study of program repair techniques. InProceedings of the 19th International Conference on Mining Software Repositories, pages 464–468, 2022
2022
-
[11]
Q.-C. Bui, R. Paramitha, D.-L. Vu, F. Massacci, and R. Scandariato. Apr4vul: an empirical study of automatic program repair techniques on real-world java vulnerabilities.Empirical software engineering, 29(1):18, 2024
2024
-
[12]
S. Chen, S. Lin, X. Gu, Y . Shi, H. Lian, L. Yun, D. Chen, W. Sun, L. Cao, and Q. Wang. Swe- exp: Experience-driven software issue resolution.arXiv preprint arXiv:2507.23361, 2025
arXiv 2025
-
[13]
Y . Chen, Y . Wang, S. Zhu, H. Yu, T. Feng, M. Zhang, M. Patwary, and J. You. Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595, 2025
arXiv 2025
-
[14]
Z. Chen, S. Kommrusch, and M. Monperrus. Neural transfer learning for repairing security vulnerabilities in C code.IEEE Trans. Software Eng., 49(1):147–165, 2023. doi: 10.1109/ TSE.2022.3147265. URL https://doi.org/10.1109/TSE.2022.3147265
-
[15]
Cheng, Q
S. Cheng, Q. Yu, Y . Zhu, and Z. Huang. Automated vulnerability repair based on retrieval- augmented generation. In2025 7th International Conference on Information Science, Electri- cal and Automation Engineering (ISEAE), pages 941–947. IEEE, 2025
2025
-
[16]
J. Chi, Y . Qu, T. Liu, Q. Zheng, and H. Yin. Seqtrans: Automatic vulnerability fix via sequence to sequence learning.IEEE Trans. Software Eng., 49(2):564–585, 2023. doi: 10.1109/TSE. 2022.3156637. URL https://doi.org/10.1109/TSE.2022.3156637
work page doi:10.1109/tse 2023
-
[17]
Costin, H
A. Costin, H. Turtiainen, N. Yousefnezhad, V . Bogulean, and T. Hämäläinen. Evaluating zero- shot chatgpt performance on predicting cve data from vulnerability descriptions. InProceed- ings of the European Conference on Cyber Warfare and Security, number 1. Academic Con- ferences International Ltd, 2024
2024
-
[18]
Y . Ding and L. Zhang. Swe-replay: Efficient test-time scaling for software engineering agents. arXiv preprint arXiv:2601.22129, 2026
arXiv 2026
-
[19]
R. Duan, A. Bijlani, Y . Ji, O. Alrawi, Y . Xiong, M. Ike, B. Saltaformag- gio, and W. Lee. Automating patching of vulnerable open-source software ver- sions in application binaries. In26th Annual Network and Distributed System Security Symposium, NDSS 2019, San Diego, California, USA, February 24-27,
2019
-
[20]
URL https://www.ndss-symposium.org/ndss-paper/ automating-patching-of-vulnerable-open-source-software-versions-in-application-binaries/
The Internet Society, 2019. URL https://www.ndss-symposium.org/ndss-paper/ automating-patching-of-vulnerable-open-source-software-versions-in-application-binaries/. 16
2019
-
[21]
M. Fakih, R. Dharmaji, H. Bouzidi, G. Q. Araya, O. Ogundare, M. Siddika, and M. A. A. Faruque. LLM4CVE: enabling iterative automated vulnerability repair with large language models. In28th Euromicro Conference on Digital System Design, DSD 2025, Salerno, Italy, September 10-12, 2025, pages 592–599. IEEE, 2025. doi: 10.1109/DSD67783.2025.00087. URL https:/...
-
[22]
Fakih, R
M. Fakih, R. Dharmaji, H. Bouzidi, G. Q. Araya, O. Ogundare, M. A. Siddika, and M. A. Al Faruque. Llm4cve: Enabling iterative automated vulnerability repair with large language models. In2025 28th Euromicro Conference on Digital System Design (DSD), pages 592–599. IEEE, 2025
2025
-
[23]
M. A. Ferrag, A. Battah, N. Tihanyi, R. Jain, D. Maimut, F. Alwahedi, T. Lestable, N. S. Thandi, A. Mechri, M. Debbah, and L. C. Cordeiro. Securefalcon: Are we there yet in automated software vulnerability detection with llms?IEEE Trans. Software Eng., 51(4): 1248–1265, 2025. doi: 10.1109/TSE.2025.3548168. URL https://doi.org/10.1109/TSE.2025. 3548168
-
[24]
M. Fu. Toward more effective deep learning-based automated software vulnerability predic- tion, classification, and repair. In2023 IEEE/ACM 45th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), pages 208–212. IEEE, 2023
2023
-
[25]
M. Fu, C. Tantithamthavorn, T. Le, V . Nguyen, and D. Phung. Vulrepair: a t5-based automated software vulnerability repair. InProceedings of the 30th ACM joint european software engi- neering conference and symposium on the foundations of software engineering, pages 935– 947, 2022
2022
-
[26]
X. Gao, S. Mechtaev, and A. Roychoudhury. Crash-avoiding program repair. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 8–18, 2019
2019
-
[27]
X. Gao, B. Wang, G. J. Duck, R. Ji, Y . Xiong, and A. Roychoudhury. Beyond tests: Program vulnerability repair via crash constraint extraction.ACM Transactions on Software Engineer- ing and Methodology (TOSEM), 30(2):1–27, 2021
2021
-
[28]
W. Han, Y . Kwak, M. Yu, K. Kim, Y . Lee, H. Moon, and Y . Paek. Rethinking the ca- pability of fine-tuned language models for automated vulnerability repair.arXiv preprint arXiv:2512.22633, 2025
arXiv 2025
-
[29]
Z. Hao, H. Wang, J. Luo, J. Zhang, Y . Zhou, Q. Lin, C. Wang, H. Dong, and J. Chen. Recreate: Reasoning and creating domain agents driven by experience.arXiv preprint arXiv:2601.11100, 2026
Pith/arXiv arXiv 2026
-
[30]
S. Hong, J. Lee, J. Lee, and H. Oh. Saver: scalable, precise, and safe memory-error repair. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, pages 271–283, 2020
2020
-
[31]
H. Hu, Y . Shang, W. Sun, and Q. Zhang. Tsapr: A tree search framework for automated program repair.arXiv preprint arXiv:2507.01827, 2025
arXiv 2025
-
[32]
T. Hu, R. Chen, S. Zhang, J. Yin, M. X. Feng, J. Liu, S. Zhang, W. Jiang, Y . Fang, S. Hu, et al. Controlled self-evolution for algorithmic code optimization.arXiv preprint arXiv:2601.07348, 2026
arXiv 2026
-
[33]
C. Huang, W. Yu, X. Wang, H. Zhang, Z. Li, R. Li, J. Huang, H. Mi, and D. Yu. R-zero: Self-evolving reasoning llm from zero data.arXiv preprint arXiv:2508.05004, 2025
Pith/arXiv arXiv 2025
-
[34]
Huang, J
K. Huang, J. Zhang, X. Meng, and Y . Liu. Template-guided program repair in the era of large language models. InICSE, pages 1895–1907, 2025
1907
-
[35]
Huang, D
Z. Huang, D. Lie, G. Tan, and T. Jaeger. Using safety properties to generate vulnerability patches. In2019 IEEE symposium on security and privacy (SP), pages 539–554. IEEE, 2019. 17
2019
-
[36]
R. Jiao, Y . Zhang, J. Li, and J. Ma. Hit the bullseye on the first shot: Improving llms using multi-sample self-reward feedback for vulnerability repair. In2025 40th IEEE/ACM Interna- tional Conference on Automated Software Engineering (ASE), pages 791–803. IEEE, 2025
2025
-
[37]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
Pith/arXiv arXiv 2023
-
[38]
Jinseok, C
H. Jinseok, C. Dongwook, K. Jinyoung, K. Misoo, and L. Eunseok. Intentfix: Automated logic vulnerability repair via llm-driven intent modeling. InProceedings of the IEEE/ACM 48th International Conference on Software Engineering, ICSE ’26. Association for Computing Machinery, 2026
2026
-
[39]
W. Kim, S. Min, M. Gwon, D. Baik, H. Lee, H. Heo, M. Lee, M. W. Baek, Y . Jin, Y . Park, Y . Choi, T. Kim, S. Park, and I. Yun. Patchisland: Orchestration of llm agents for continuous vulnerability repair.arXiv preprint arXiv:2601.17471, 2026
arXiv 2026
-
[40]
Y . Kim, S. Shin, H. Kim, and J. Yoon. Logs in, patches out: Automated vulnerability repair via {Tree-of-Thought}{LLM}analysis. In34th USENIX Security Symposium (USENIX Security 25), pages 4401–4419, 2025
2025
-
[41]
Kojima, S
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[42]
Kulsum, H
U. Kulsum, H. Zhu, B. Xu, and M. d’Amorim. A case study of llm for automated vulnerability repair: Assessing impact of reasoning and patch validation feedback. InProceedings of the 1st ACM International Conference on AI-Powered Software, pages 103–111, 2024
2024
-
[43]
H. Lee, Z. Zhang, H. Lu, and L. Zhang. Sec-bench: Automated benchmarking of llm agents on real-world software security tasks.arXiv preprint arXiv:2506.11791, 2025
arXiv 2025
-
[44]
J. Lin, Y . Guo, Y . Han, S. Hu, Z. Ni, L. Wang, M. Chen, H. Liu, R. Chen, Y . He, et al. Se- agent: Self-evolution trajectory optimization in multi-step reasoning with llm-based agents. arXiv preprint arXiv:2508.02085, 2025
arXiv 2025
-
[45]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[47]
Q. Mao, Z. Li, X. Hu, K. Liu, X. Xia, and J. Sun. Towards explainable vulnerability detection with large language models.IEEE Trans. Software Eng., 51(10):2957–2971, 2025. doi: 10. 1109/TSE.2025.3605442. URL https://doi.org/10.1109/TSE.2025.3605442
-
[48]
Y . Noller, R. Shariffdeen, X. Gao, and A. Roychoudhury. Trust enhancement issues in program repair. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022, pages 2228–2240. ACM, 2022. doi: 10.1145/3510003. 3510040. URL https://doi.org/10.1145/3510003.3510040
-
[49]
A. Rastogi, A. Yang, A. Q. Jiang, A. H. Liu, A. Sablayrolles, A. Héliou, A. Martin, A. Agar- wal, A. Ehrenberg, A. Lo, et al. Devstral: Fine-tuning language models for coding agent applications.arXiv preprint arXiv:2509.25193, 2025
arXiv 2025
-
[50]
S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, N. Sundaresan, M. Zhou, A. Blanco, and S. Ma. Codebleu: a method for automatic evaluation of code synthesis.arXiv preprint arXiv:2009.10297, 2020
Pith/arXiv arXiv 2009
-
[51]
Roucher, A
A. Roucher, A. V . del Moral, T. Wolf, L. von Werra, and E. Kaunismäki. smolagents: A smol library to build great agentic systems.Hugging Face, 2025. 18
2025
-
[52]
C. Seas, G. Fitzpatrick, J. A. H. Jr., and M. C. Carlisle. Automated vulnerability detection in source code using deep representation learning. In R. Paul and A. Kundu, editors,14th IEEE Annual Computing and Communication Workshop and Conference, CCWC 2024, Las Vegas, NV , USA, January 8-10, 2024, pages 484–490. IEEE, 2024. doi: 10.1109/CCWC60891.2024. 10...
-
[53]
Neural Machine Translation of Rare Words with Subword Units
R. Sennrich, B. Haddow, and A. Birch. Neural machine translation of rare words with sub- word units. InProceedings of the 54th Annual Meeting of the Association for Computa- tional Linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, Volume 1: Long Pa- pers. The Association for Computer Linguistics, 2016. doi: 10.18653/V1/P16-1162. URL https://doi.o...
-
[54]
Shahriar, S
A. Shahriar, S. J. Hisham, K. A. Rahman, M. R. Islam, M. S. Hossain, R.-H. Hwang, and Y .-D. Lin. 5gpt: 5g vulnerability detection by combining zero-shot capabilities of gpt-4 with domain aware strategies through prompt engineering.IEEE Transactions on Information Forensics and Security, 2025
2025
-
[55]
M. Shao, Y . Ding, C. Gao, J. Wang, and G. Zhu. Fix pattern-aware vulnerability patch gener- ation via in-context learning.ACM Transactions on Software Engineering and Methodology, 2026
2026
-
[56]
Shen and S
Z. Shen and S. Chen. A survey of automatic software vulnerability detection, program repair, and defect prediction techniques.Security and Communication Networks, 2020(1):8858010, 2020
2020
-
[57]
Y . Shin, A. Meneely, L. Williams, and J. A. Osborne. Evaluating complexity, code churn, and developer activity metrics as indicators of software vulnerabilities.IEEE transactions on software engineering, 37(6):772–787, 2010
2010
-
[58]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[59]
P. Wang, X. Liu, and C. Xiao. Cve-bench: Benchmarking llm-based software engineer- ing agent’s ability to repair real-world CVE vulnerabilities. In L. Chiruzzo, A. Ritter, and L. Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chap- ter of the Association for Computational Linguistics: Human Language Technologies, NAACL 202...
-
[61]
X. Wang, B. Li, Y . Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y . Song, B. Li, J. Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
Pith/arXiv arXiv 2024
-
[62]
Z. Wei, J. Zeng, M. Wen, Z. Yu, K. Cheng, Y . Zhu, J. Guo, S. Zhou, L. Yin, X. Su, et al. Patcheval: A new benchmark for evaluating llms on patching real-world vulnerabilities.arXiv preprint arXiv:2511.11019, 2025
arXiv 2025
-
[63]
X. Wen, Z. Lin, Y . Yang, C. Gao, and D. Ye. Vul-r2: A reasoning LLM for automated vulnera- bility repair. In40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, Korea, Republic of, November 16-20, 2025, pages 26–38. IEEE, 2025. doi: 10.1109/ASE63991.2025.00011. URL https://doi.org/10.1109/ASE63991.2025.00011
-
[64]
Z. Weng, A. Antoniades, D. Nathani, Z. Zhang, X. Pu, and X. E. Wang. Group-evolving agents: Open-ended self-improvement via experience sharing.arXiv preprint arXiv:2602.04837, 2026. 19
arXiv 2026
-
[65]
R. Wu, X. Wang, J. Mei, P. Cai, D. Fu, C. Yang, L. Wen, X. Yang, Y . Shen, Y . Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
Pith/arXiv arXiv 2025
-
[66]
C. S. Xia and L. Zhang. Automated program repair via conversation: Fixing 162 out of 337 bugs for $0.42 each using chatgpt. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, pages 819–831, 2024
2024
-
[67]
C. S. Xia, Z. Wang, Y . Yang, Y . Wei, and L. Zhang. Live-swe-agent: Can software engineering agents self-evolve on the fly?arXiv preprint arXiv:2511.13646, 2025
arXiv 2025
-
[68]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang. A-mem: Agentic memory for llm agents. InAdvances in Neural Information Processing Systems, 2025
2025
-
[69]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[70]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe- agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[71]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[72]
Z. Ye, X. Sun, S. Cao, L. Bo, and B. Li. Well begun is half done: Location-aware and trace- guided iterative automated vulnerability repair.arXiv preprint arXiv:2512.20203, 2025
arXiv 2025
-
[73]
Z. Ye, X. Sun, S. Cao, L. Bo, and B. Li. Well begun is half done: Location-aware and trace- guided iterative automated vulnerability repair. InProceedings of the IEEE/ACM 48th Interna- tional Conference on Software Engineering, ICSE ’26. Association for Computing Machinery, 2026
2026
-
[74]
Zhang, C
J. Zhang, C. Wang, A. Li, W. Wang, T. Li, and Y . Liu. Vuladvisor: Natural language sug- gestion generation for software vulnerability repair. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 1932–1944, 2024
1932
- [77]
-
[78]
Design Initiative for a 10 TeV pCM Wakefield Collider,
Q. Zhang, Y . Zhao, W. Sun, C. Fang, Z. Wang, and L. Zhang. Program repair: Automated vs. manual.CoRR, abs/2203.05166, 2022. doi: 10.48550/ARXIV .2203.05166. URL https: //doi.org/10.48550/arXiv.2203.05166
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[79]
Zhang, C
Q. Zhang, C. Fang, B. Yu, W. Sun, T. Zhang, and Z. Chen. Pre-trained model-based automated software vulnerability repair: How far are we?IEEE Transactions on Dependable and Secure Computing, 21(4):2507–2525, 2023
2023
-
[80]
A. Zhao, D. Huang, Q. Xu, M. Lin, Y .-J. Liu, and G. Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
2024
-
[81]
A. Zhao, Y . Wu, Y . Yue, T. Wu, Q. Xu, M. Lin, S. Wang, Q. Wu, Z. Zheng, and G. Huang. Ab- solute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
Pith/arXiv arXiv 2025
-
[82]
X. Zhou, K. Kim, B. Xu, D. Han, and D. Lo. Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE ’24. Association for Computing Machinery, 2024. 20
2024
-
[83]
X. Zhou, K. Kim, B. Xu, D. Han, and D. Lo. Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources. InProceedings of the IEEE/ACM 46th international conference on software engineering, pages 1–13, 2024
2024
-
[84]
X. Zhou, S. Cao, X. Sun, and D. Lo. Large language model for vulnerability detection and repair: Literature review and the road ahead.ACM Trans. Softw. Eng. Methodol., 34(5):145:1– 145:31, 2025. doi: 10.1145/3708522. URL https://doi.org/10.1145/3708522
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.