Dial HEALTHDIAL for Advice: A Multilingual and Multi-Parallel Spoken Dialogue Dataset for Knowledge-Grounded Information Seeking
Pith reviewed 2026-06-29 07:53 UTC · model grok-4.3
The pith
HEALTHDIAL supplies 6000 spoken dialogues across Arabic, Chinese, English and Spanish grounded in World Health Organization content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
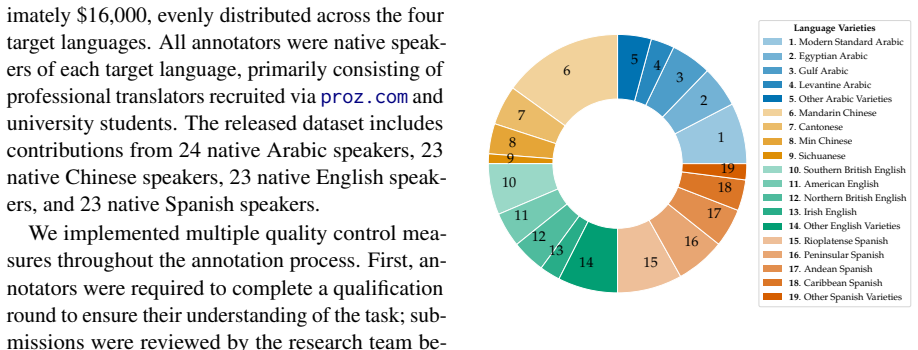
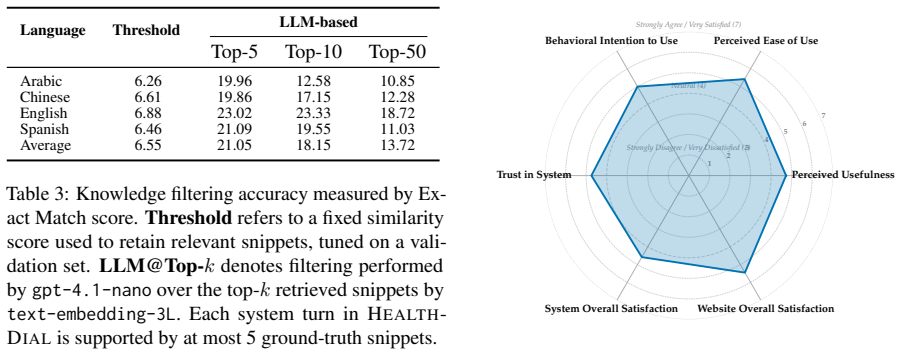
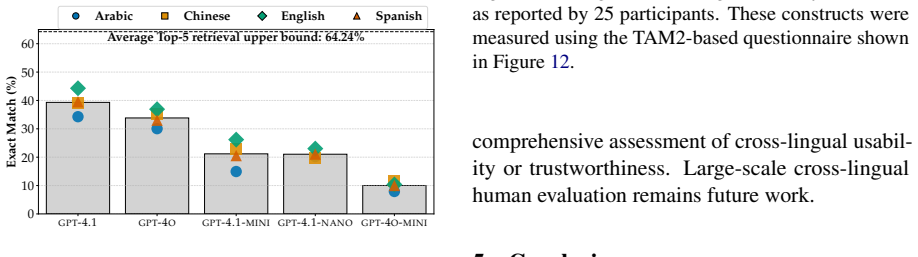
The authors establish that HEALTHDIAL comprises 6000 information-seeking dialogues (1500 per language) grounded in World Health Organization content across Arabic, Chinese, English, and Spanish, together with 163 hours of recorded user speech from native speakers of varied dialects and detailed speaker annotations, and that benchmarks on key dialogue tasks using this resource reveal consistent performance disparities across languages.
What carries the argument
The HEALTHDIAL dataset, a multilingual multi-parallel collection of spoken dialogues each grounded in the same WHO source material, serves as the central object that enables cross-language comparison and evaluation of RAG-based spoken dialogue systems.
If this is right
- Benchmark results indicate that even high-resource languages exhibit measurable performance gaps on the same health-grounded tasks.
- Speaker annotations permit analysis of how demographic and regional factors correlate with dialogue quality and system accuracy.
- The multi-parallel alignment across languages supports direct testing of cross-lingual consistency in retrieval and response generation.
- Release of the accompanying toolkit allows other researchers to replicate the collection process for additional languages or domains.
Where Pith is reading between the lines
- The dataset could be used to test whether language-specific fine-tuning or adapter modules can close the observed performance gaps.
- Speech recordings open the possibility of studying how dialectal pronunciation affects retrieval accuracy in spoken health queries.
- Similar collection methods might be applied to other factual domains where grounding in authoritative sources is required.
- The parallel structure may support experiments on whether joint training across languages improves factual consistency in generated advice.
Load-bearing premise
The collected dialogues and speech recordings accurately represent natural spoken information-seeking behavior and remain faithfully grounded in the WHO source material without collection-induced artifacts.
What would settle it
A controlled comparison showing that the recorded dialogues contain significantly more scripted or unnatural phrasing than spontaneous health consultations collected in the field would undermine the dataset's claim to represent real spoken behavior.
Figures



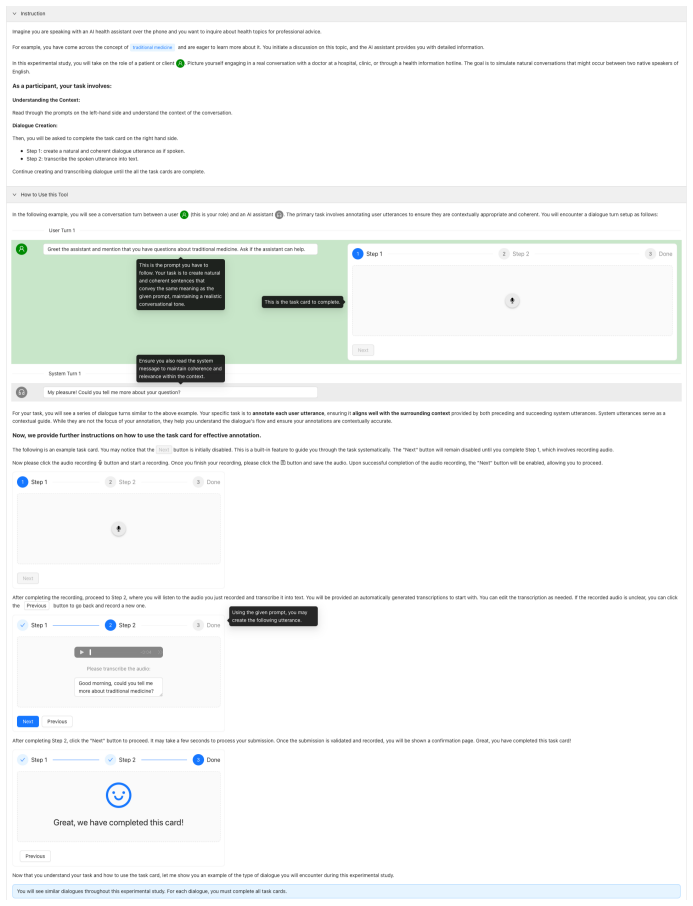

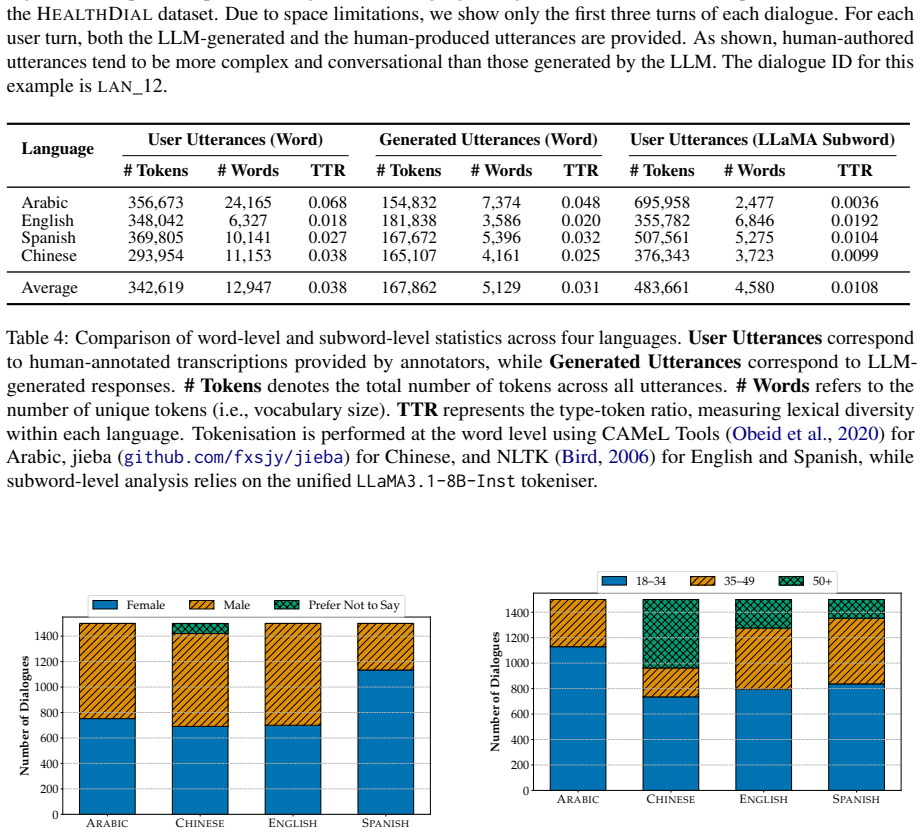
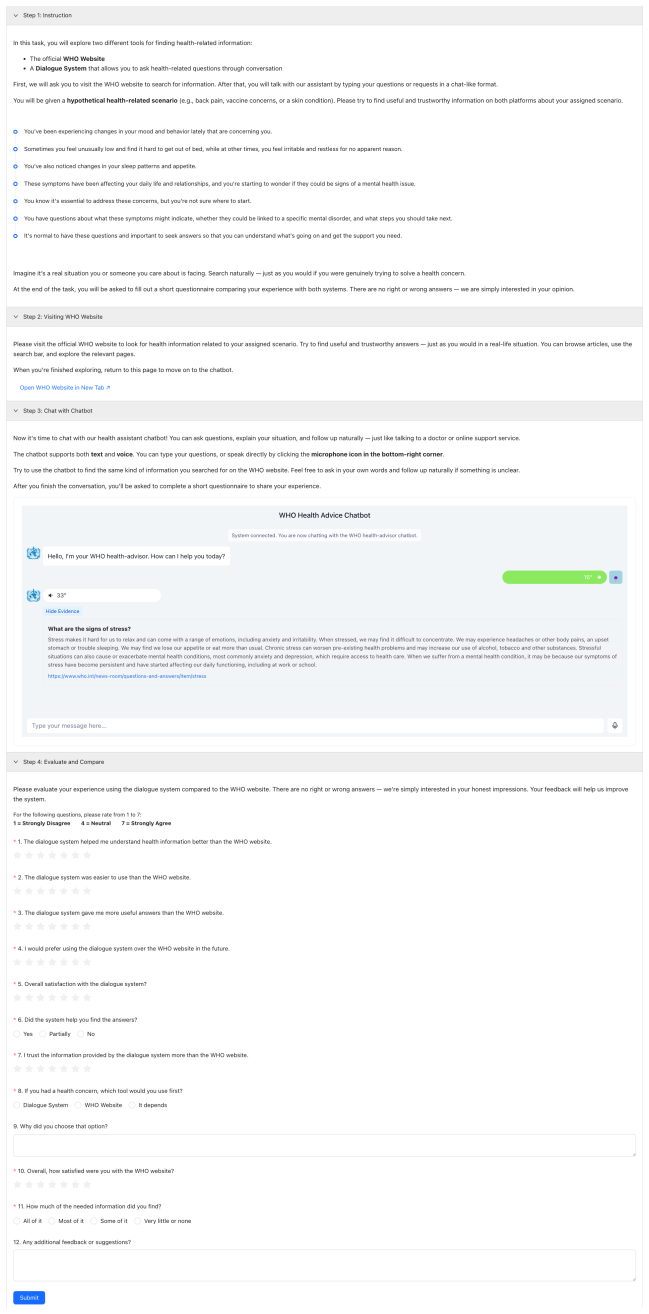
read the original abstract
Creating spoken dialogue datasets is methodologically challenging, and these challenges are amplified when the goal is to build multilingual, multi-parallel datasets at scale. This work introduces HEALTHDIAL, a large-scale, multilingual, and multi-parallel dataset for developing and evaluating retrieval-augmented generation (RAG)-based spoken dialogue systems. The dataset comprises 6,000 information-seeking dialogues (1,500 per language) grounded in trusted content from the World Health Organization (WHO) and 163 hours of user speech recorded from native speakers of diverse dialects across four official WHO languages: Arabic, Chinese, English, and Spanish. Each speaker is annotated with demographic (e.g., gender, age) and sociolinguistic (e.g., primary language, region of origin) variables. We report benchmark results across key dialogue tasks, which reveal consistent performance disparities across languages, even among high-resource ones. To support future research, we release the dataset, a prototype system, and a toolkit for data collection and system evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HEALTHDIAL, a multilingual and multi-parallel spoken dialogue dataset for knowledge-grounded information seeking. It consists of 6,000 dialogues (1,500 per language) in Arabic, Chinese, English, and Spanish, grounded in World Health Organization (WHO) content, accompanied by 163 hours of recorded user speech from native speakers of diverse dialects. Each dialogue includes annotations for speaker demographics and sociolinguistic variables. The authors provide benchmark results on key dialogue tasks that demonstrate consistent performance disparities across languages and release the dataset, a prototype system, and a toolkit for collection and evaluation.
Significance. If the dialogues are accurately grounded and representative of natural spoken behavior, this dataset would fill an important gap in resources for developing and evaluating multilingual RAG-based spoken dialogue systems, especially in the health domain. The multi-parallel structure across four languages with dialectal variation and demographic annotations enables detailed cross-lingual and sociolinguistic analyses. The public release of the dataset, prototype, and toolkit supports reproducibility and future work. This is particularly valuable given the challenges of creating such datasets at scale.
major comments (2)
- [Dataset Construction section] Dataset Construction section: No quantitative verification metrics are reported for grounding accuracy (e.g., percentage of dialogues manually audited against WHO sources) or naturalness (e.g., ratings against spontaneous speech baselines). This is load-bearing for the central claim because the reported benchmark disparities across languages could reflect collection artifacts from prompting or translation mediation rather than genuine cross-lingual differences.
- [Benchmark Results section] Benchmark Results section: The exact computation of the reported performance metrics for dialogue tasks (e.g., retrieval precision or generation quality) is not defined with formulas or implementation details, preventing independent verification of the disparity findings.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence summary of the collection protocol to allow standalone assessment of the dataset's claimed properties.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We appreciate the emphasis on ensuring the robustness of our claims regarding dataset quality and metric transparency. Below, we provide point-by-point responses to the major comments and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Dataset Construction section] Dataset Construction section: No quantitative verification metrics are reported for grounding accuracy (e.g., percentage of dialogues manually audited against WHO sources) or naturalness (e.g., ratings against spontaneous speech baselines). This is load-bearing for the central claim because the reported benchmark disparities across languages could reflect collection artifacts from prompting or translation mediation rather than genuine cross-lingual differences.
Authors: We agree that providing quantitative verification metrics is crucial to support the dataset's quality and to address potential concerns about collection artifacts. The current manuscript does not include these metrics. In the revised version, we will add a dedicated subsection in the Dataset Construction section reporting the results of manual audits for grounding accuracy (including the percentage of dialogues verified against WHO sources) and human evaluation ratings for naturalness relative to spontaneous speech baselines. This will help substantiate that the observed performance disparities reflect genuine cross-lingual differences. revision: yes
-
Referee: [Benchmark Results section] Benchmark Results section: The exact computation of the reported performance metrics for dialogue tasks (e.g., retrieval precision or generation quality) is not defined with formulas or implementation details, preventing independent verification of the disparity findings.
Authors: We acknowledge the need for precise definitions of the metrics to allow for reproducibility and independent verification. The manuscript currently lacks explicit formulas and implementation details. We will revise the Benchmark Results section to include detailed formulas for all metrics (e.g., retrieval precision@K, generation quality measures such as BLEU or ROUGE with exact computation methods) along with implementation specifics, such as the libraries and parameters used. revision: yes
Circularity Check
No circularity: dataset release with empirical benchmarks only
full rationale
The paper is a data-release contribution that describes collection of 6000 dialogues, records speech, annotates demographics, and reports benchmark results on standard dialogue tasks. No equations, fitted parameters, predictions, or uniqueness theorems are claimed. The central claims (dataset size, language coverage, observed performance disparities) are direct descriptions of the released artifact and its measured properties rather than quantities derived from internal definitions or self-citations. No load-bearing step reduces to a fit or to a prior result by the same authors. This is the normal non-circular outcome for a resource paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard practices in spoken dialogue data collection produce dialogues that remain faithful to the source material and representative of natural user behavior.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1912.06670 , year=
SpeechT5: Unified-modal encoder-decoder pre-training for spoken language processing. InPro- ceedings of the 60th Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 5723–5738, Dublin, Ireland. Associa- tion for Computational Linguistics. Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohle...
-
[2]
Exploring and controlling diversity in llm-agent conversation.arXiv preprint arXiv:2412.21102. Jan Clusmann, Fiona R Kolbinger, Hannah Sophie Muti, Zunamys I Carrero, Jan-Niklas Eckardt, Narmin Ghaffari Laleh, Chiara Maria Lavinia Löf- fler, Sophie-Caroline Schwarzkopf, Michaela Unger, Gregory P Veldhuizen, and 1 others. 2023. The fu- ture landscape of la...
-
[3]
XTREME: A massively multilingual multi- task benchmark for evaluating cross-lingual gener- alisation. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 4411–4421. PMLR. Songbo Hu, Abigail Oppong, Ebele Mogo, Charlotte Collins, Giulia Occhini, Anna Barford, and Anna Korhone...
-
[4]
InInter- speech, pages 47–51
Jee haan, i’d like both, por favor: Elicita- tion of a code-switched corpus of hindi-english and spanish-english human-machine dialog. InInter- speech, pages 47–51. Evgeniia Razumovskaia, Goran Glavaš, Olga Majew- ska, Edoardo Maria Ponti, Anna Korhonen, and Ivan Vuli´c. 2022. Crossing the conversational chasm: A primer on natural language processing for ...
2022
-
[5]
Differentially private speaker anonymization. Proceedings on Privacy Enhancing Technologies, 2023:98–114. Shuichiro Shimizu, Chenhui Chu, Sheng Li, and Sadao Kurohashi. 2023. Towards speech dialogue transla- tion mediating speakers of different languages. In Findings of the Association for Computational Lin- guistics: ACL 2023, pages 1122–1134, Toronto, C...
-
[6]
Example (System):Hello, I’m your virtual health assistant
Opening:Thesysteminitiates the conversa- tion with a greeting and an introduction to its role or the service provided. Example (System):Hello, I’m your virtual health assistant. How can I help you today?
-
[7]
Example (User):Hey, I burned my hand cook- ing last week
Health Concern Presentation:Theuser states their primary health concern, symptom, or question. Example (User):Hey, I burned my hand cook- ing last week. It’s really painful, red, and swollen
-
[8]
Example (System):Were you vaccinated for yellow fever before your trip?
Information Gathering:Thesystemasks clarification questions to gather more context about the user’s symptoms or medical history. Example (System):Were you vaccinated for yellow fever before your trip?
-
[9]
Example (System):If the burn is larger than 3 inches or on your face, hands, or joints, you should definitely see a doctor
Explanation / Medical Education:The systemprovides in-depth information or edu- cates the user about their condition, treatment options, and preventive measures. Example (System):If the burn is larger than 3 inches or on your face, hands, or joints, you should definitely see a doctor
-
[10]
Example (System):Until you see a doctor, keep the burn clean and covered with a sterile, non- stick bandage
Care Planning and Guidance:Thesystem offers specific advice on managing the health issue, including treatment options, preventive measures, lifestyle modifications, and self-care techniques. Example (System):Until you see a doctor, keep the burn clean and covered with a sterile, non- stick bandage
-
[11]
Example (System):It’s important to consider your options and what feels right for you
Decision Support:Theuser or systemmay discuss different options, relevant risks and ben- efits, and explore user preferences. Example (System):It’s important to consider your options and what feels right for you. You can also seek support from a trusted friend, family member, or a professional counsellor
-
[12]
Example (System):You can find a local urgent care centre or call your primary care doctor to schedule an appointment
Healthcare System Navigation:Theuser or systemmay discuss guidance on navigat- ing the healthcare system, including finding a provider, making an appointment, and under- standing insurance coverage and costs. Example (System):You can find a local urgent care centre or call your primary care doctor to schedule an appointment
-
[13]
Example (System):In the UK, your medical records are confidential and protected by law
Legal and Ethical Considerations:The user or systemmay discuss legal and ethical considerations, including informed consent and patient rights. Example (System):In the UK, your medical records are confidential and protected by law
-
[14]
Example (System):Your information is safe with us
Privacy and Confidentiality:Theuser or systemmay inquire about, or proactively assure, the privacy and confidentiality of the user’s information. Example (System):Your information is safe with us. We take your privacy very seriously
-
[15]
It’s completely normal to feel scared and overwhelmed
Emotional Support:Thesystemoffers emotional support, empathy, and reassurance to the user.Example (System):I’m sorry to hear that you’re going through this. It’s completely normal to feel scared and overwhelmed
-
[16]
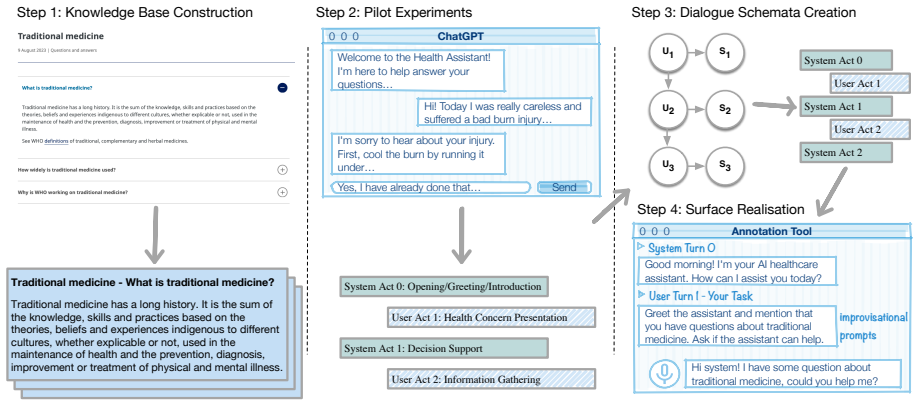
Goodbye! A.3 Dialogue Schemata Creation Figure 7shows the transition probabilities in our hierarchical Markov model
Closing:Thesystemends the conversation with a summary, an offer of further assistance, or a farewell.Example (System):You’re wel- come! Take care, and I hope you feel better soon. Goodbye! A.3 Dialogue Schemata Creation Figure 7shows the transition probabilities in our hierarchical Markov model. Let au i and as i de- note the discourse acts associated wit...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.