Accurate and Efficient MCMC for Latent Position Models
Pith reviewed 2026-06-28 23:31 UTC · model grok-4.3
The pith
Two MCMC algorithms for latent position models achieve near-linear running times with improved accuracy guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a simple auxiliary data structure, maintained and updated during MCMC steps, enables algorithms with amortized running time almost O(|E|) or O(|V|) while delivering stronger or comparable accuracy guarantees for posterior approximation in latent position models.
What carries the argument
The auxiliary data structure that can be cheaply updated during MCMC steps to preserve accuracy guarantees without introducing bias.
If this is right
- The fast algorithm matches the running time of Rastelli et al but supplies much stronger accuracy guarantees.
- The faster algorithm reduces runtime further to almost O(|V|) while slightly improving accuracy over prior work.
- The auxiliary structure is suspected to apply to other MCMC algorithms for graph models.
- Bayesian fitting of latent position models becomes feasible for larger observed graphs.
Where Pith is reading between the lines
- The sketch technique could transfer to other expensive-likelihood models in network analysis or spatial statistics.
- Similar cheap updates might improve mixing or reduce variance in related sampling schemes for point processes.
- Empirical tests on graphs with millions of vertices would clarify whether the O(|V|) bound holds in practice.
Load-bearing premise
The auxiliary data structure can be maintained and updated during MCMC steps in a way that preserves the stated accuracy guarantees without introducing bias that would invalidate the posterior approximation.
What would settle it
Compare posterior samples from the new algorithms against exact MCMC on a small graph where exact computation is feasible; large discrepancies would show the approximations introduce unacceptable bias.
Figures

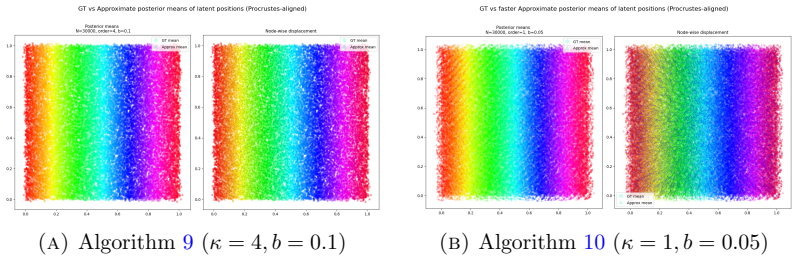
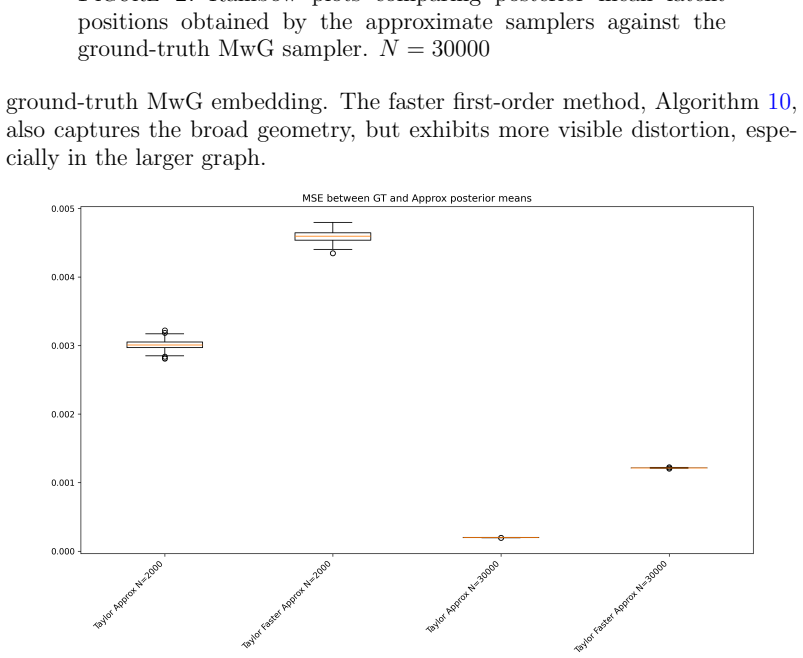
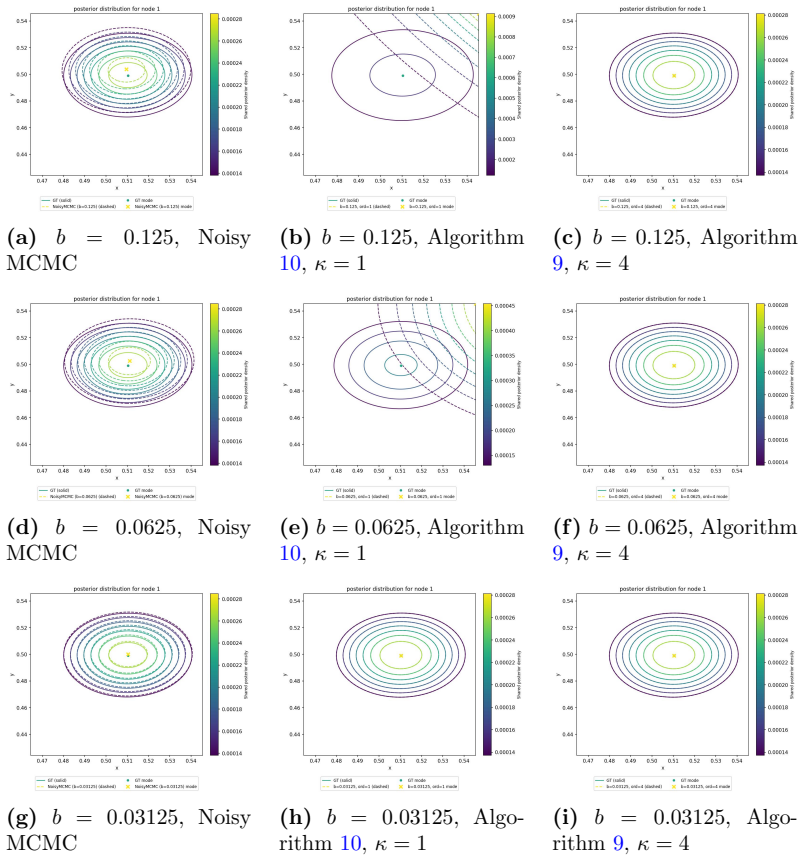
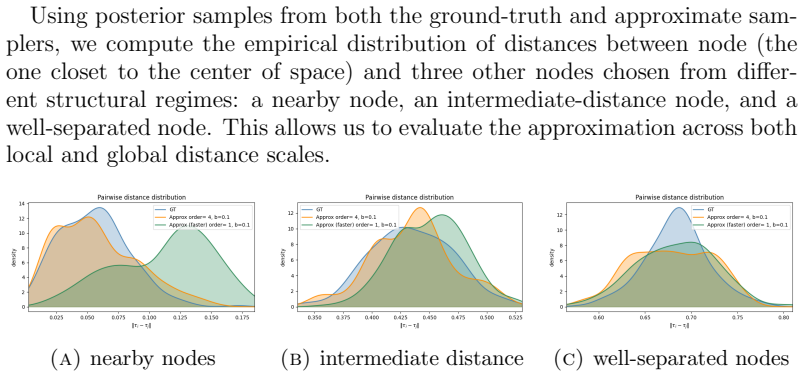
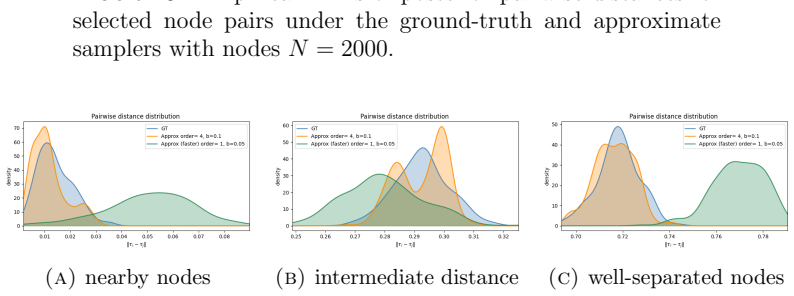
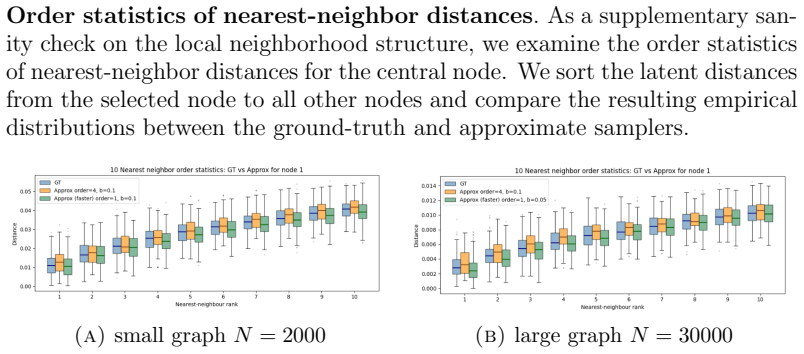

read the original abstract
Latent position models (LPMs) are a large and popular class of models for random graphs. However, fitting Bayesian LPMs is computationally challenging - computing the likelihood even once takes time that is quadratic in the number of vertices $|V|$ of the observed graph $G = (V,E)$. Many previous papers have introduced approximate MCMC algorithms to speed this up, with the most similar to ours, Rastelli et al (2024), presenting an algorithm that has amortized running time that can be reduced almost to $O(|E|)$ and good empirical performance on reasonable inference problems. The present paper offers two algorithms for solving the same problem: a ``fast" algorithm with running time of the same almost-$O(|E|)$ order as astelli et al and much stronger accuracy guarantees, and a ``faster" algorithm with an improved running time of almost $O(|V|)$, and accuracy guarantees that are slightly improved compared to Rastelli et al (but not sufficient for all tasks). The main improvements come from the introduction of a simple auxiliary data structure that can be cheaply updated during an MCMC run; we suspect that the same ``cheap sketch" may be useful for other MCMC algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces two MCMC algorithms for Bayesian inference in latent position models (LPMs) for graphs, where exact likelihood evaluation is O(|V|^2). Building on Rastelli et al. (2024), it proposes a 'fast' algorithm with amortized runtime almost O(|E|) and stronger accuracy guarantees, plus a 'faster' algorithm with runtime almost O(|V|) and modestly improved accuracy (though insufficient for all tasks). Both rely on a simple auxiliary 'cheap sketch' data structure that is maintained and updated during MCMC steps to enable the speedups while preserving the claimed accuracy properties; the authors suggest the sketch may apply more broadly.
Significance. If the accuracy guarantees hold and the sketch updates introduce no bias into the Metropolis-Hastings ratio or stationary distribution, the work would deliver a meaningful advance in scalable, theoretically grounded MCMC for LPMs, with the fast variant offering substantially tighter error control than the closest prior method. The potential reusability of the cheap sketch for other graph MCMC algorithms is a secondary strength.
major comments (1)
- [Abstract] Abstract (description of the main improvements): The central accuracy claims for both algorithms rest on the assertion that the cheap sketch 'can be cheaply updated during an MCMC run' while preserving the stated guarantees. No mechanism, update rule, or argument is supplied showing that these updates leave the Metropolis-Hastings acceptance probability unbiased with respect to the true likelihood; any systematic discrepancy would alter the target posterior. This is load-bearing for the comparison to Rastelli et al. and must be supplied with a precise statement of the maintained invariant and a proof (or rigorous bound) that the stationary distribution remains correct.
minor comments (1)
- [Abstract] Abstract: the phrase 'as astelli et al' is a typographical error and should read 'as Rastelli et al'.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting this important point about the cheap sketch. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (description of the main improvements): The central accuracy claims for both algorithms rest on the assertion that the cheap sketch 'can be cheaply updated during an MCMC run' while preserving the stated guarantees. No mechanism, update rule, or argument is supplied showing that these updates leave the Metropolis-Hastings acceptance probability unbiased with respect to the true likelihood; any systematic discrepancy would alter the target posterior. This is load-bearing for the comparison to Rastelli et al. and must be supplied with a precise statement of the maintained invariant and a proof (or rigorous bound) that the stationary distribution remains correct.
Authors: We agree that a precise description of the update rules for the cheap sketch together with a formal argument establishing that the Metropolis-Hastings ratio remains unbiased is essential for the correctness claims. The manuscript contains the algorithmic description of the sketch and its maintenance, but we acknowledge that an explicit statement of the maintained invariant and the accompanying proof were not presented with sufficient clarity. In the revised version we will insert a dedicated subsection that states the invariant, gives the exact update procedure, and supplies a rigorous proof that the acceptance probability is computed with respect to the true likelihood, thereby ensuring the target posterior is the stationary distribution. revision: yes
Circularity Check
No significant circularity; claims rest on external comparison
full rationale
The paper's central improvements are attributed to a new auxiliary data structure ('cheap sketch') whose maintenance is asserted to preserve accuracy guarantees, with explicit comparison to the independently cited Rastelli et al (2024) work for both runtime and accuracy. No equations or steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the derivation chain is presented as building on external benchmarks rather than renaming or tautologically re-deriving its own inputs. The reader's assessment of score 1.0 aligns with the absence of any load-bearing self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv:2501.13597. [DSD+16] Dingxiong Deng, Cyrus Shahabi, Ugur Demiryurek, Linhong Zhu, Rose Yu, and Yan Liu. Latent space model for road networks to predict time-varying traffic. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1525–1534,
-
[2]
Priebe, and Patrick Rubin-Delanchy
[GJB+24] Ian Gallagher, Andrew Jones, Anna Bertiger, Carey E. Priebe, and Patrick Rubin-Delanchy. Spectral embedding of weighted graphs.Journal of the American Statistical Association, 119(547):1923–1932,
1923
-
[3]
[JPS26] James E. Johndrow, Natesh S. Pillai, and Aaron Smith. No free lunch for approximate MCMC.arXiv preprint arXiv:2010.12514, 37 2026+. [KHRH09] Pavel N Krivitsky, Mark S Handcock, Adrian E Raftery, and Pe- ter D Hoff. Representing degree distributions, clustering, and homophily in social networks with latent cluster random effects models.Social Netwo...
-
[4]
Firefly Monte Carlo: Exact MCMC with Subsets of Data
[MA14] Dougal Maclaurin and Ryan P Adams. Firefly Monte Carlo: Exact MCMC with subsets of data.arXiv preprint arXiv:1403.5693,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The True Cost of Stochastic Gradient Langevin Dynamics
[NDH+17] Tigran Nagapetyan, Andrew B Duncan, Leonard Hasenclever, Se- bastian J Vollmer, Lukasz Szpruch, and Konstantinos Zygalakis. The true cost of stochastic gradient Langevin dynamics.arXiv preprint arXiv:1706.02692,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Pillai, Aaron Smith, and Azeem Zaman
[PSZ26] Natesh S. Pillai, Aaron Smith, and Azeem Zaman. No free lunch for stochastic gradient Langevin dynamics.Journal of Applied Probability, 2026+. [RMF24] Riccardo Rastelli, Florian Maire, and Nial Friel. Computationally efficient inference for latent position network models.Electronic Journal of Statistics, 18(1):2531–2570,
2026
-
[7]
Perturbations of Markov chains.arXiv preprint arXiv:2404.10251,
[RSQ24] Daniel Rudolf, Aaron Smith, and Matias Quiroz. Perturbations of Markov chains.arXiv preprint arXiv:2404.10251,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.