DAMEL: Dual-Axis Multi-Expert Learning for Class-Imbalanced Learning
Pith reviewed 2026-06-29 08:38 UTC · model grok-4.3
The pith
DAMEL reduces both bias and variance in class-imbalanced learning by operating multiple experts along representation and time axes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
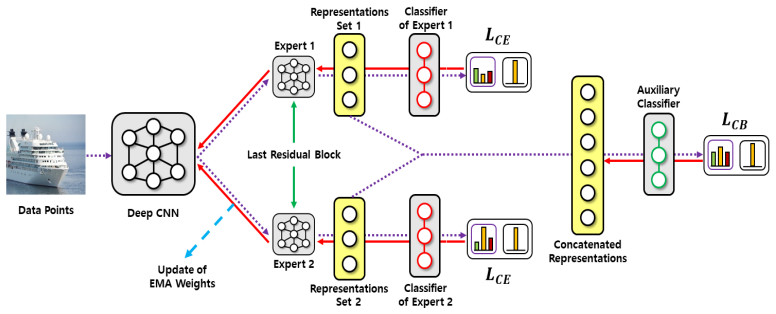
DAMEL reduces both bias and variance of predictions by using multiple experts along both representation and time axes. Along the representation axis, DAMEL concatenates the representations of multiple experts and trains an auxiliary balanced classifier simultaneously with the concatenated representations. Along the time axis, DAMEL aggregates network weights across training epochs, employing these aggregated weights during testing.
What carries the argument
Dual-axis multi-expert learning: concatenation of expert representations plus an auxiliary balanced classifier on the representation axis, combined with epoch-wise weight aggregation on the time axis.
Load-bearing premise
That combining expert representations via concatenation plus an auxiliary balanced classifier and epoch-wise weight aggregation will simultaneously lower bias and variance without introducing offsetting increases in either or in computational cost.
What would settle it
On a standard long-tailed benchmark such as CIFAR-100-LT, run DAMEL against rebalancing baselines and multi-expert baselines; if measured bias or variance is not lower under DAMEL, the central claim does not hold.
Figures

read the original abstract
Various algorithms have been proposed to address the challenges posed by class-imbalanced learning from real-world data with long-tailed distributions. While these algorithms reduce prediction bias through rebalancing techniques, they often introduce increased prediction variance as a trade-off. Several multi-expert learning algorithms aim to address this variance but involve complex procedures. We propose a new multi-expert learning algorithm, called the dual-axis multi-expert learning (DAMEL), which reduces both bias and variance of predictions by using multiple experts along both representation and time axes. Along the representation axis, DAMEL concatenates the representations of multiple experts and trains an auxiliary balanced classifier simultaneously with the concatenated representations. Along the time axis, DAMEL aggregates network weights across training epochs, employing these aggregated weights during testing. Experimental results demonstrate that DAMEL reduces both bias and variance of predictions, highlighting its effectiveness in class-imbalanced learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DAMEL, a dual-axis multi-expert learning algorithm for class-imbalanced (long-tailed) classification. Along the representation axis, multiple expert representations are concatenated and an auxiliary balanced classifier is trained jointly; along the time axis, network weights are aggregated across training epochs and the aggregated weights are used at test time. The central claim is that this approach simultaneously reduces both prediction bias and variance relative to prior rebalancing and multi-expert methods.
Significance. If the experimental results hold and the inference pipeline is clarified, DAMEL would supply a comparatively lightweight mechanism for addressing the bias-variance trade-off that commonly arises in imbalanced learning, without the complex procedures of some existing multi-expert ensembles.
major comments (1)
- [Abstract] Abstract (and §3, inference description): the test-time model is not fully specified. The abstract states that aggregated weights are used during testing but does not indicate whether the auxiliary balanced classifier or the concatenated multi-expert representation remains part of the inference pipeline. Because the bias-reduction claim is explicitly attributed to the representation-axis component, this omission is load-bearing for the dual-axis thesis.
minor comments (1)
- The abstract supplies no datasets, metrics, baselines, or quantitative results, which hinders immediate assessment of the strength of the experimental support.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on clarifying the test-time inference pipeline. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and §3, inference description): the test-time model is not fully specified. The abstract states that aggregated weights are used during testing but does not indicate whether the auxiliary balanced classifier or the concatenated multi-expert representation remains part of the inference pipeline. Because the bias-reduction claim is explicitly attributed to the representation-axis component, this omission is load-bearing for the dual-axis thesis.
Authors: We agree this is a valid observation that affects clarity. The current abstract and §3 description of inference is incomplete regarding whether the concatenated representations and auxiliary balanced classifier are retained at test time. In the revised manuscript we will explicitly state that inference uses the aggregated weights applied to the concatenated multi-expert representations, which are then classified by the auxiliary balanced classifier. The same clarification will be added to §3. This change directly addresses the load-bearing aspect of the dual-axis claim. revision: yes
Circularity Check
No circularity; algorithmic proposal with experimental validation
full rationale
The paper proposes DAMEL as a new multi-expert algorithm that concatenates expert representations, trains an auxiliary balanced classifier, and aggregates weights over epochs. No equations, parameter fittings, derivations, or self-referential claims appear in the abstract or description. Central claims rest on experimental results rather than any reduction of outputs to inputs by construction. No self-citations are invoked as load-bearing premises. The method is self-contained as an empirical algorithmic contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard deep learning optimization assumptions (e.g., SGD convergence on neural networks) hold for the multi-expert training procedure.
Reference graph
Works this paper leans on
-
[1]
Why resampling outperforms reweight- ing for correcting sampling bias with stochastic gradients, in: Interna- tional Conference on Learning Representations
An, J., Ying, L., Zhu, Y., 2021. Why resampling outperforms reweight- ing for correcting sampling bias with stochastic gradients, in: Interna- tional Conference on Learning Representations
2021
-
[2]
Re- stricted decontamination for the imbalanced training sample problem, in: Iberoamerican Congress on Pattern Recognition, Springer
Barandela, R., Rangel, E., Sánchez, J.S., Ferri, F.J., 2003. Re- stricted decontamination for the imbalanced training sample problem, in: Iberoamerican Congress on Pattern Recognition, Springer. pp. 424– 431
2003
-
[3]
Weight uncertainty in neural network, in: International Conference on Machine Learning, PMLR
Blundell, C., Cornebise, J., Kavukcuoglu, K., Wierstra, D., 2015. Weight uncertainty in neural network, in: International Conference on Machine Learning, PMLR. pp. 1613–1622
2015
-
[4]
Ace: Ally complementary experts for solving long-tailed recognition in one-shot, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Cai, J., Wang, Y., Hwang, J.N., 2021. Ace: Ally complementary experts for solving long-tailed recognition in one-shot, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 112–121
2021
-
[5]
Learn- ing imbalanced datasets with label-distribution-aware margin loss, in: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R
Cao, K., Wei, C., Gaidon, A., Arechiga, N., Ma, T., 2019. Learn- ing imbalanced datasets with label-distribution-aware margin loss, in: Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc
2019
-
[6]
Smote: synthetic minority over-sampling technique
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P., 2002. Smote: synthetic minority over-sampling technique. Journal of Arti- ficial Intelligence Research 16, 321–357
2002
-
[7]
Prediction of highly imbalanced semi- conductor chip-level defects in module tests using multimodal fusion and logit adjustment
Cho, H., Koo, W., Kim, H., 2023. Prediction of highly imbalanced semi- conductor chip-level defects in module tests using multimodal fusion and logit adjustment. IEEE Transactions on Semiconductor Manufacturing 36, 425–433
2023
-
[8]
Remix: Rebalanced mixup, in: European Conference on Computer Vision, Springer
Chou, H.P., Chang, S.C., Pan, J.Y., Wei, W., Juan, D.C., 2020. Remix: Rebalanced mixup, in: European Conference on Computer Vision, Springer. pp. 95–110
2020
-
[9]
Choy, M., Kim, D., Lee, J.G., Kim, H., Motoda, H., 2016. Looking back on the current day: interruptibility prediction using daily behavioral 25 features, in: Proceedings of the 2016 ACM international joint conference on pervasive and ubiquitous computing, pp. 1004–1015
2016
-
[10]
Crime risk maps: A multivariate spatial analysis of crime data
Chung, J., Kim, H., 2019. Crime risk maps: A multivariate spatial analysis of crime data. Geographical analysis 51, 475–499
2019
-
[11]
Au- toaugment: Learning augmentation strategies from data, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Cubuk, E.D., Zoph, B., Mane, D., Vasudevan, V., Le, Q.V., 2019. Au- toaugment: Learning augmentation strategies from data, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 113–123
2019
-
[12]
Reslt: Residual learn- ing for long-tailed recognition
Cui, J., Liu, S., Tian, Z., Zhong, Z., Jia, J., 2022. Reslt: Residual learn- ing for long-tailed recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 3695–3706
2022
-
[13]
Parametric contrastive learning, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Cui, J., Zhong, Z., Liu, S., Yu, B., Jia, J., 2021. Parametric contrastive learning, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 715–724
2021
-
[14]
Class- balanced loss based on effective number of samples, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pp
Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S., 2019. Class- balanced loss based on effective number of samples, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pp. 9268–9277
2019
-
[15]
On supervised class-imbalanced learning: An updated perspective and some key challenges
Das, S., Mullick, S.S., Zelinka, I., 2022. On supervised class-imbalanced learning: An updated perspective and some key challenges. IEEE Trans- actions on Artificial Intelligence 3, 973–993
2022
-
[16]
Ima- genet: A large-scale hierarchical image database, in: 2009 IEEE confer- ence on computer vision and pattern recognition, Ieee
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L., 2009. Ima- genet: A large-scale hierarchical image database, in: 2009 IEEE confer- ence on computer vision and pattern recognition, Ieee. pp. 248–255
2009
-
[17]
Improved Regularization of Convolutional Neural Networks with Cutout
DeVries, T., Taylor, G.W., 2017. Improved regularization of convolu- tional neural networks with cutout. arXiv preprint arXiv:1708.04552
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Probabilistic contrastive learningforlong-tailedvisualrecognition
Du, C., Wang, Y., Song, S., Huang, G., 2024. Probabilistic contrastive learningforlong-tailedvisualrecognition. IEEETransactionsonPattern Analysis and Machine Intelligence 46, 5890–5904. 26
2024
-
[19]
Fan, Y., Dai, D., Kukleva, A., Schiele, B., 2022. Cossl: Co-learning of representation and classifier for imbalanced semi-supervised learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14574–14584
2022
-
[20]
Deep Ensem- bles: A Loss Landscape Perspective,
Fort, S., Hu, H., Lakshminarayanan, B., 2019. Deep ensembles: A loss landscape perspective. arXiv preprint arXiv:1912.02757
-
[21]
Learning from imbalanced data
He, H., Garcia, E.A., 2009. Learning from imbalanced data. IEEE Transactions on knowledge and data engineering 21, 1263–1284
2009
-
[22]
Momentum contrast for unsupervised visual representation learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R., 2020. Momentum contrast for unsupervised visual representation learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738
2020
-
[23]
Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
2016
-
[24]
Searching for mo- bilenetv3, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp
Howard, A., Sandler, M., Chu, G., Chen, L.C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., et al., 2019. Searching for mo- bilenetv3, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1314–1324
2019
-
[25]
Learning deep representa- tion for imbalanced classification, in: Proceedings of the IEEE confer- ence on computer vision and pattern recognition, pp
Huang, C., Li, Y., Loy, C.C., Tang, X., 2016. Learning deep representa- tion for imbalanced classification, in: Proceedings of the IEEE confer- ence on computer vision and pattern recognition, pp. 5375–5384
2016
-
[26]
Class-balanced distil- lation for long-tailed visual recognition
Iscen, A., Araujo, A., Gong, B., Schmid, C., 2021. Class-balanced distil- lation for long-tailed visual recognition. arXiv preprint arXiv:2104.05279
-
[27]
Izmailov, P., Podoprikhin, D., Garipov, T., Vetrov, D., Wilson, A.G.,
-
[28]
Averaging weights leads to wider optima and better generalization, in: 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, Association For Uncertainty in Artificial Intelligence (AUAI). pp. 876–885
2018
-
[29]
Jamal, M.A., Brown, M., Yang, M.H., Wang, L., Gong, B., 2020. Re- thinking class-balanced methods for long-tailed visual recognition from a 27 domain adaptation perspective, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pp. 7610–7619
2020
-
[30]
The class imbalance problem: Significance and strategies, in: Proc
JAPKOWICZ, N., 2000. The class imbalance problem: Significance and strategies, in: Proc. 2000 International Conference on Artificial Intelligence, pp. 111–117
2000
-
[31]
Exploring balanced feature spaces for representation learning, in: International Conference on Learning Representations
Kang, B., Li, Y., Xie, S., Yuan, Z., Feng, J., 2020a. Exploring balanced feature spaces for representation learning, in: International Conference on Learning Representations
-
[32]
Decoupling representation and classifier for long-tailed recognition, in: International Conference on Learning Representations
Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., Kalan- tidis, Y., 2020b. Decoupling representation and classifier for long-tailed recognition, in: International Conference on Learning Representations
-
[33]
Exploiting shape cues for weakly supervised semantic segmentation
Kho, S., Lee, P., Lee, W., Ki, M., Byun, H., 2022. Exploiting shape cues for weakly supervised semantic segmentation. Pattern Recognition 132, 108953
2022
-
[34]
Contextual anomaly detection for high- dimensional data using dirichlet process variational autoencoder
Kim, H., Kim, H., 2023. Contextual anomaly detection for high- dimensional data using dirichlet process variational autoencoder. IISE Transactions 55, 433–444
2023
-
[35]
M2m: Imbalanced classification via major-to-minor translation, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pp
Kim, J., Jeong, J., Shin, J., 2020. M2m: Imbalanced classification via major-to-minor translation, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pp. 13896–13905
2020
-
[36]
Locally most powerful bayesian test for out-of-distribution detection using deep generative models
Kim, K., Shin, J., Kim, H., 2021. Locally most powerful bayesian test for out-of-distribution detection using deep generative models. Advances in Neural Information Processing Systems 34, 14913–14924
2021
-
[37]
Flexible model weighting for one-dependence estimators based on point-wise independence analysis
Kong, H., Wang, L., 2023. Flexible model weighting for one-dependence estimators based on point-wise independence analysis. Pattern Recog- nition 139, 109473
2023
-
[38]
Learning multiple layers of features from tiny images
Krizhevsky, A., 2009. Learning multiple layers of features from tiny images. Technical report, Department of Computer Science, University of Toronto
2009
-
[39]
Simple and scal- able predictive uncertainty estimation using deep ensembles
Lakshminarayanan, B., Pritzel, A., Blundell, C., 2017. Simple and scal- able predictive uncertainty estimation using deep ensembles. Advances in Neural Information Processing Systems 30. 28
2017
-
[40]
Semi-supervised learning for simulta- neous location detection and classification of mixed-type defect patterns in wafer bin maps
Lee, H., Lee, J., Kim, H., 2023a. Semi-supervised learning for simulta- neous location detection and classification of mixed-type defect patterns in wafer bin maps. IEEE Transactions on Semiconductor Manufacturing 36, 220–230
-
[41]
Lee, H., Park, T., Kim, H., 2025. Learnable logit adjustment for imbal- anced semi-supervised learning under class distribution mismatch, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2664–2674
2025
-
[42]
Abc: Auxiliary balanced classifier for class-imbalanced semi-supervised learning
Lee, H., Shin, S., Kim, H., 2021. Abc: Auxiliary balanced classifier for class-imbalanced semi-supervised learning. Advances in Neural Informa- tion Processing Systems 34
2021
-
[43]
Resampling approach for one-class classification
Lee, H.H., Park, S., Im, J., 2023b. Resampling approach for one-class classification. Pattern Recognition , 109731
-
[44]
Dependence maps, a dimensionality reduction with dependence distance for high-dimensional data
Lee, K., Gray, A., Kim, H., 2013. Dependence maps, a dimensionality reduction with dependence distance for high-dimensional data. Data Mining and Knowledge Discovery 26, 512–532
2013
-
[45]
Trustworthy long- tailed classification, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Li, B., Han, Z., Li, H., Fu, H., Zhang, C., 2022a. Trustworthy long- tailed classification, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6970–6979
-
[46]
Targeted supervised contrastive learning for long- tailed recognition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Li, T., Cao, P., Yuan, Y., Fan, L., Yang, Y., Feris, R.S., Indyk, P., Katabi, D., 2022b. Targeted supervised contrastive learning for long- tailed recognition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6918–6928
-
[47]
Self supervision to distillation for long-tailed visual recognition, in: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pp
Li, T., Wang, L., Wu, G., 2021. Self supervision to distillation for long-tailed visual recognition, in: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pp. 630–639
2021
-
[48]
Large- scale long-tailed recognition in an open world, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Liu, Z., Miao, Z., Zhan, X., Wang, J., Gong, B., Yu, S.X., 2019. Large- scale long-tailed recognition in an open world, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2537–2546. 29
2019
-
[49]
A high-bias, low-variance introduction to machine learning for physicists
Mehta, P., Bukov, M., Wang, C.H., Day, A.G., Richardson, C., Fisher, C.K., Schwab, D.J., 2019. A high-bias, low-variance introduction to machine learning for physicists. Physics reports 810, 1–124
2019
-
[50]
Long-tail learning via logit adjustment, in: International Con- ference on Learning Representations
Menon, A.K., Jayasumana, S., Rawat, A.S., Jain, H., Veit, A., Kumar, S., 2020. Long-tail learning via logit adjustment, in: International Con- ference on Learning Representations
2020
-
[51]
Distributed representations of words and phrases and their composi- tionality, in: Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J., 2013. Distributed representations of words and phrases and their composi- tionality, in: Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q. (Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc
2013
-
[52]
Eigen-cam: Class activation map using principal components, in: 2020 International Joint Conference on Neural Networks (IJCNN), IEEE
Muhammad, M.B., Yeasin, M., 2020. Eigen-cam: Class activation map using principal components, in: 2020 International Joint Conference on Neural Networks (IJCNN), IEEE. pp. 1–7
2020
-
[53]
Diversity matters when learning from ensembles
Nam, G., Yoon, J., Lee, Y., Lee, J., 2021. Diversity matters when learning from ensembles. Advances in Neural Information Processing Systems 34
2021
-
[54]
Prediction of highly imbalanced semi- conductor chip-level defects using uncertainty-based adaptive margin learning
Park, S., Kim, K., Kim, H., 2022. Prediction of highly imbalanced semi- conductor chip-level defects using uncertainty-based adaptive margin learning. IISE Transactions 55, 147–155
2022
-
[55]
Rebalancing using estimated class dis- tribution for imbalanced semi-supervised learning under class distribu- tion mismatch, in: European Conference on Computer Vision, Springer
Park, T., Lee, H., Kim, H., 2024. Rebalancing using estimated class dis- tribution for imbalanced semi-supervised learning under class distribu- tion mismatch, in: European Conference on Computer Vision, Springer. pp. 388–404
2024
-
[56]
Bal- anced meta-softmax for long-tailed visual recognition, in: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H
Ren, J., Yu, C., sheng, s., Ma, X., Zhao, H., Yi, S., Li, h., 2020. Bal- anced meta-softmax for long-tailed visual recognition, in: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc.. pp. 4175–4186
2020
-
[57]
Learning to reweight examples for robust deep learning, in: International Conference on Ma- chine Learning, PMLR
Ren, M., Zeng, W., Yang, B., Urtasun, R., 2018. Learning to reweight examples for robust deep learning, in: International Conference on Ma- chine Learning, PMLR. pp. 4334–4343. 30
2018
-
[58]
How re-sampling helps for long-tail learning?, in: Advances in Neural Information Processing Systems
Shi, J.X., Wei, T., Xiang, Y., Li, Y.F., 2023. How re-sampling helps for long-tail learning?, in: Advances in Neural Information Processing Systems
2023
-
[59]
Application of kernel principal component analysis to multi-characteristic parameter design problems
Soh, W., Kim, H., Yum, B.J., 2018. Application of kernel principal component analysis to multi-characteristic parameter design problems. Annals of Operations Research 263, 69–91
2018
-
[60]
Mnasnet: Platform-aware neural architecture search for mobile, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp
Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., Le, Q.V., 2019. Mnasnet: Platform-aware neural architecture search for mobile, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2820–2828
2019
-
[61]
Efficientnet: Rethinking model scaling for con- volutional neural networks, in: International Conference on Machine Learning, PMLR
Tan, M., Le, Q., 2019. Efficientnet: Rethinking model scaling for con- volutional neural networks, in: International Conference on Machine Learning, PMLR. pp. 6105–6114
2019
-
[62]
Tarvainen, A., Valpola, H., 2017. Mean teachers are better role mod- els: Weight-averaged consistency targets improve semi-supervised deep learning results, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 1195–1204
2017
-
[63]
The inaturalist species classi- fication and detection dataset, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
Van Horn, G., Mac Aodha, O., Song, Y., Cui, Y., Sun, C., Shepard, A., Adam, H., Perona, P., Belongie, S., 2018. The inaturalist species classi- fication and detection dataset, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8769–8778
2018
-
[64]
Contrastive learning based hybrid networks for long-tailed image classification, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pp
Wang, P., Han, K., Wei, X.S., Zhang, L., Wang, L., 2021a. Contrastive learning based hybrid networks for long-tailed image classification, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pp. 943–952
-
[65]
Long-tailed recog- nition by routing diverse distribution-aware experts, in: International Conference on Learning Representations
Wang, X., Lian, L., Miao, Z., Liu, Z., Yu, S., 2021b. Long-tailed recog- nition by routing diverse distribution-aware experts, in: International Conference on Learning Representations
-
[66]
Multiple contrastive experts for long-tailed image classification
Wang, Y., Sun, K., Guo, C., Zhong, S., Liu, H., Ma, Y., 2024. Multiple contrastive experts for long-tailed image classification. Expert Systems with Applications 255, 124613. 31
2024
-
[67]
Learning to model the tail, in: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Wang, Y.X., Ramanan, D., Hebert, M., 2017. Learning to model the tail, in: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (Eds.), Advances in Neural Information Processing Systems, Curran Associates, Inc
2017
-
[68]
Open-sampling: Exploring out-of-distribution data for re-balancing long-tailed datasets, in: International Conference on Machine Learning, PMLR
Wei, H., Tao, L., Xie, R., Feng, L., An, B., 2022. Open-sampling: Exploring out-of-distribution data for re-balancing long-tailed datasets, in: International Conference on Machine Learning, PMLR. pp. 23615– 23630
2022
-
[69]
Flipout: Efficient pseudo-independent weight perturbations on mini-batches, in: Interna- tional Conference on Learning Representations
Wen, Y., Vicol, P., Ba, J., Tran, D., Grosse, R., 2018. Flipout: Efficient pseudo-independent weight perturbations on mini-batches, in: Interna- tional Conference on Learning Representations
2018
-
[70]
Learning from multiple experts: Self- paced knowledge distillation for long-tailed classification, in: European Conference on Computer Vision, Springer
Xiang, L., Ding, G., Han, J., 2020. Learning from multiple experts: Self- paced knowledge distillation for long-tailed classification, in: European Conference on Computer Vision, Springer. pp. 247–263
2020
-
[71]
Aggregated residual transformations for deep neural networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K., 2017. Aggregated residual transformations for deep neural networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1492–1500
2017
-
[72]
Feature transfer learning for deep face recognition with under-represented data
Yin, X., Yu, X., Sohn, K., Liu, X., Chandraker, M., 2018. Feature transfer learning for deep face recognition with under-represented data. arXiv e-prints , arXiv–1803
2018
-
[73]
Multimodal deep generative model for semi- supervised learning under class imbalance
Yoon, H., Kim, H., 2026. Multimodal deep generative model for semi- supervised learning under class imbalance. Technometrics , 1–24
2026
-
[74]
Uncertainty estimation by density aware evi- dential deep learning
Yoon, T., Kim, H., 2024. Uncertainty estimation by density aware evi- dential deep learning. arXiv preprint arXiv:2409.08754
-
[75]
Pure noise to the rescue of insuffi- cient data: Improving imbalanced classification by training on random noiseimages, in: InternationalConferenceonMachineLearning, PMLR
Zada, S., Benou, I., Irani, M., 2022. Pure noise to the rescue of insuffi- cient data: Improving imbalanced classification by training on random noiseimages, in: InternationalConferenceonMachineLearning, PMLR. pp. 25817–25833
2022
-
[76]
mixup: Beyond Empirical Risk Minimization
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D., 2017. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 . 32
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
mixup: Beyond empirical risk minimization, in: International Conference on Learning Representations
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D., 2018. mixup: Beyond empirical risk minimization, in: International Conference on Learning Representations. URL:https://openreview.net/forum?id= r1Ddp1-Rb
2018
-
[78]
Siamese networks with an online reweighted example for imbalanced data learning
Zhao, L., Shang, Z., Tan, J., Zhou, M., Zhang, M., Gu, D., Zhang, T., Tang, Y.Y., 2022. Siamese networks with an online reweighted example for imbalanced data learning. Pattern Recognition 132, 108947
2022
-
[79]
Zhou, B., Cui, Q., Wei, X.S., Chen, Z.M., 2020. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pp. 9719–9728
2020
-
[80]
Class and attribute-aware logit adjustment for generalized long-tail learning, in: Proceedings of the AAAI Conference on Artificial Intelligence
Zhou, X., Wu, O., Yang, N., 2025. Class and attribute-aware logit adjustment for generalized long-tail learning, in: Proceedings of the AAAI Conference on Artificial Intelligence. 33
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.