Why Far Looks Up: Probing Spatial Representation in Vision-Language Models
Pith reviewed 2026-06-29 08:04 UTC · model grok-4.3
The pith
Vision-language models consistently entangle vertical image position with distance in their embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
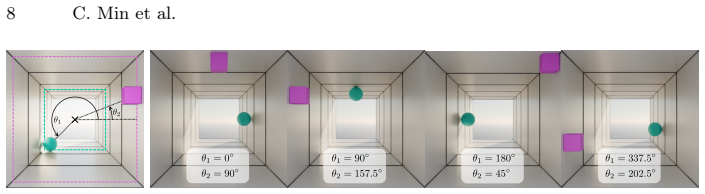
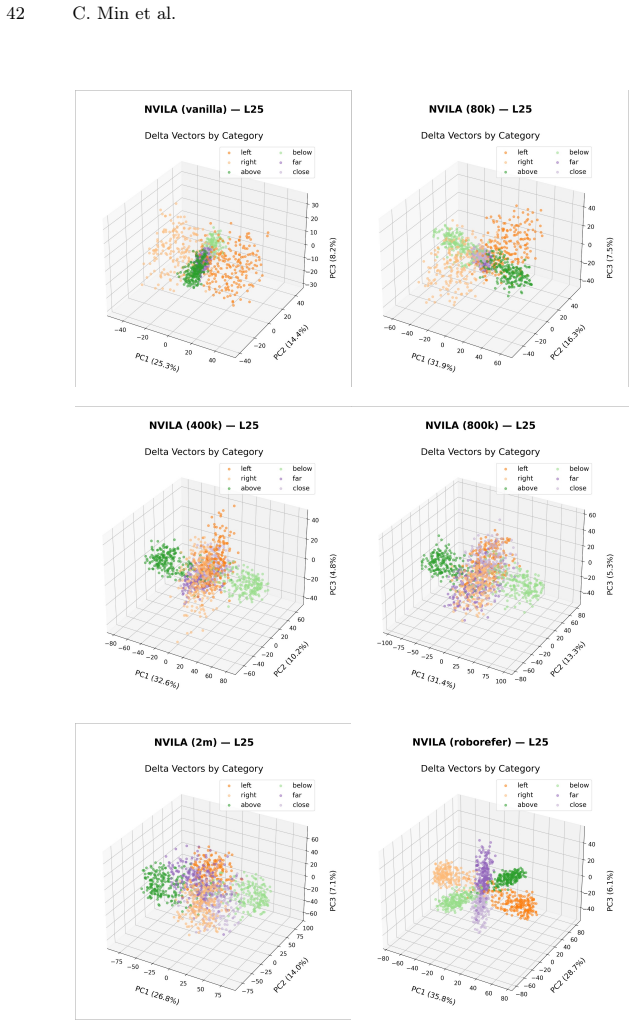
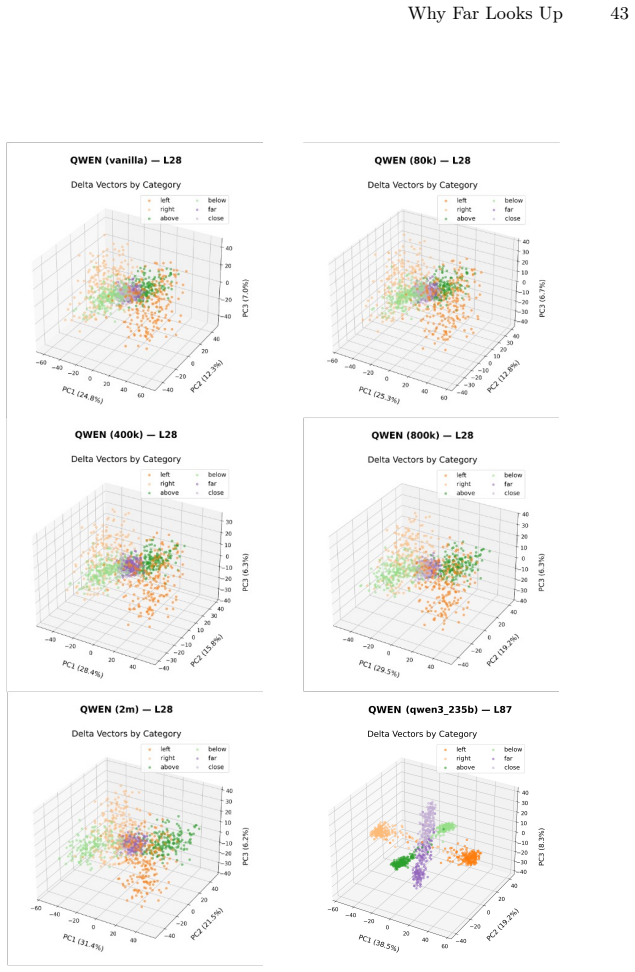
VLMs organize spatial information such that vertical position in the image plane becomes entangled with inferred distance, reproducing the perspective statistics of training photographs; this produces measurable accuracy gaps on counter-heuristic cases, scales with data volume, and is isolated from evaluation skew by the SpatialTunnel benchmark.
What carries the argument
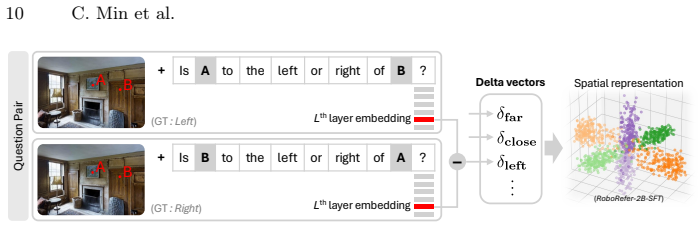
Minimal contrastive pairs that probe organization and disentanglement of spatial axes inside VLM embeddings, together with the SpatialTunnel synthetic benchmark that removes natural-image correlations.
If this is right
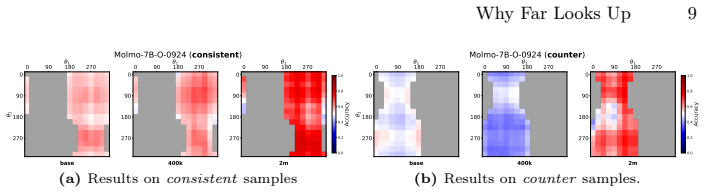
- Accuracy differs systematically between perspective-consistent and counter-heuristic test items.
- The vertical-distance entanglement strengthens under continued data scaling.
- Models with similar benchmark scores can still differ in internal spatial structure, and those differences forecast performance on other spatial tasks.
- Greater separation of spatial axes inside the model predicts better robustness across benchmarks.
Where Pith is reading between the lines
- Training on photographic data may embed perspective statistics so deeply that they resist removal by scale alone.
- The contrastive-pair method could be reused to diagnose other unintended entanglements, such as between lighting and material properties.
- Architectures that explicitly encourage axis separation during pre-training might reduce reliance on such shortcuts.
- Synthetic benchmarks like SpatialTunnel offer a route to measure whether future models have moved beyond image-plane heuristics.
Load-bearing premise
The constructed contrastive pairs and SpatialTunnel benchmark succeed in isolating only the targeted spatial axes without introducing new unintended correlations.
What would settle it
Finding a model family that exhibits no measurable vertical-distance correlation on the contrastive pairs yet still shows the same accuracy gap on counter-perspective examples, or a model where forcing axis separation produces no robustness gain on SpatialTunnel.
Figures









read the original abstract
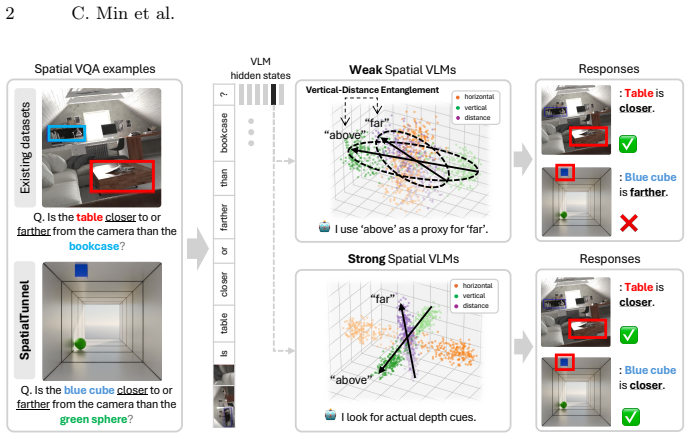
Vision-language models (VLMs) achieve strong performance on spatial reasoning benchmarks, yet it remains unclear whether this reflects structured 3D understanding or reliance on statistical shortcuts in natural images. We introduce a representation-level analysis framework that constructs minimal contrastive pairs to measure how spatial axes are organized and disentangled within VLM embeddings. Our analysis across multiple model families reveals a consistent vertical-distance entanglement: models conflate vertical image position with distance, mirroring the perspective bias of natural photographs. This bias produces a significant accuracy gap between perspective-consistent and counter-heuristic examples, and intensifies under data scaling even as overall benchmark accuracy improves. We further show that models with similar benchmark scores can exhibit different internal representations, and that these differences predict accuracy and robustness across diverse spatial reasoning benchmarks. To isolate this bias from evaluation-set skew, we introduce SpatialTunnel, a synthetic benchmark designed to expose spatial shortcut biases by removing common correlations present in natural images. Experiments confirm that the entanglement is model-intrinsic, and that models with well-separated spatial axes exhibit greater robustness, suggesting that well-structured spatial representations lead to more reliable spatial reasoning across diverse benchmarks. Code and benchmark are available on the project page: https://cheolhong0916.github.io/whyfarlooksup.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a representation-level analysis framework using minimal contrastive pairs to probe how VLMs organize spatial axes in embeddings. Across model families it reports a consistent vertical-distance entanglement that mirrors perspective bias in natural photographs; this produces accuracy gaps on perspective-consistent vs. counter-heuristic examples, persists under scaling, and is isolated from evaluation skew via the new synthetic SpatialTunnel benchmark. The work further claims that models with better-separated spatial axes show greater robustness on diverse spatial-reasoning benchmarks, with code and benchmark released.
Significance. If the isolation claims hold, the results would demonstrate that apparent spatial competence in VLMs often reflects statistical shortcuts rather than structured 3D understanding, and that internal representational geometry predicts downstream robustness. The release of code and the SpatialTunnel benchmark is a clear strength for reproducibility and follow-up work.
major comments (2)
- [Framework and benchmark construction] Framework and benchmark construction (abstract and § on SpatialTunnel): the central claim that the entanglement is model-intrinsic rests on the assertion that minimal contrastive pairs isolate only vertical position and distance while SpatialTunnel removes all common correlations. No quantitative verification (e.g., statistical tests on low-level image statistics such as scale, lighting gradients, or edge distributions before/after position changes) is described; without such checks the measured entanglement could arise from residual synthesis artifacts rather than internal bias.
- [Scaling and robustness experiments] Results on scaling and robustness (section reporting scaling experiments): the claim that the bias intensifies under data scaling while overall accuracy improves is load-bearing for the argument that shortcut reliance is not alleviated by scale. The reported accuracy gaps and correlation with representation quality should be accompanied by explicit controls for model size, training data volume, and benchmark difficulty to ensure the entanglement metric is not confounded by these factors.
minor comments (2)
- Notation for embedding axes and distance metrics should be defined once in a dedicated subsection rather than introduced piecemeal across figures.
- Figure captions for the contrastive-pair examples should explicitly state the exact pixel or 3D coordinate changes applied while holding the orthogonal axis fixed.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which help clarify the presentation of our results. Below we address the major comments point by point.
read point-by-point responses
-
Referee: [Framework and benchmark construction] Framework and benchmark construction (abstract and § on SpatialTunnel): the central claim that the entanglement is model-intrinsic rests on the assertion that minimal contrastive pairs isolate only vertical position and distance while SpatialTunnel removes all common correlations. No quantitative verification (e.g., statistical tests on low-level image statistics such as scale, lighting gradients, or edge distributions before/after position changes) is described; without such checks the measured entanglement could arise from residual synthesis artifacts rather than internal bias.
Authors: We agree that providing quantitative verification of the isolation in SpatialTunnel would strengthen the manuscript. In the revised version, we will add an analysis section reporting statistical tests (such as t-tests or distribution comparisons) on low-level image statistics including scale, lighting gradients, and edge distributions for the minimal contrastive pairs and benchmark variants. This will confirm that position changes do not introduce unintended correlations. revision: yes
-
Referee: [Scaling and robustness experiments] Results on scaling and robustness (section reporting scaling experiments): the claim that the bias intensifies under data scaling while overall accuracy improves is load-bearing for the argument that shortcut reliance is not alleviated by scale. The reported accuracy gaps and correlation with representation quality should be accompanied by explicit controls for model size, training data volume, and benchmark difficulty to ensure the entanglement metric is not confounded by these factors.
Authors: We appreciate this point. Our scaling experiments compare models of different sizes within and across families, but we acknowledge the need for more explicit controls. In revision, we will add controls by reporting the entanglement metric alongside model parameter counts and include a discussion of how benchmark difficulty is held constant by using identical test sets. For training data volume, as this information is not always available for proprietary models, we will note this limitation and focus on available controls for model size. revision: partial
Circularity Check
No circularity: empirical measurements on external models and new benchmark
full rationale
The paper reports direct empirical observations of spatial representations in existing VLMs via minimal contrastive pairs and the newly introduced SpatialTunnel benchmark. No equations, derivations, fitted parameters presented as predictions, or self-citation chains are used to establish the central claims. The analysis measures entanglement in model embeddings and benchmark performance gaps without reducing any result to a tautological input from the same data or prior self-work. This is a standard self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive image pairs can isolate individual spatial axes in VLM embeddings
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al.: Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691 (2022) 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Anthropic: Claude opus 4 & claude sonnet 4 system card. Tech. rep., Anthropic (May 2025),https : / / www - cdn . anthropic . com / 4263b940cabb546aa0e3283f35b686f4f3b2ff47.pdf1
2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 2, 5, 7, 11, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 2, 5, 7, 11, 21
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Blender Foundation (2025),https://www.blender.org/7
Blender Online Community: Blender - a 3D modelling and rendering package. Blender Foundation (2025),https://www.blender.org/7
2025
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brazil, G., Kumar, A., Straub, J., Ravi, N., Johnson, J., Gkioxari, G.: Omni3d: A large benchmark and model for 3d object detection in the wild. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13154– 13164 (2023) 24
2023
-
[7]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., Zhang, Y.: Matterport3d: Learning from rgb-d data in indoor envi- ronments. arXiv preprint arXiv:1709.06158 (2017) 24
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012 (2015) 23
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spa- tialvlm: Endowing vision-language models with spatial reasoning capabilities. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 14455–14465 (2024) 5
2024
-
[10]
arXiv e-prints pp
Chen, H., Lin, J., Chen, X., Fan, Y., Jin, X., Su, H., Dong, J., Fu, J., Shen, X.: Rethinking visual layer selection in multimodal llms. arXiv e-prints pp. arXiv–2504 (2025) 12, 32
2025
-
[11]
In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=k7vcuqLK4X3, 4
Chen, S., Zhu, T., Zhou, R., Zhang, J., Gao, S., Niebles, J.C., Geva, M., He, J., Wu, J., Li, M.: Why is spatial reasoning hard for VLMs? an attention mechanism perspective on focus areas. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=k7vcuqLK4X3, 4
2025
-
[12]
SpaceTools: Tool-Augmented Spatial Reasoning via Double Interactive RL
Chen, S., Uy, M.A., Song, C.H., Ladhak, F., Murali, A., Qu, Q., Birchfield, S., Blukis, V., Tremblay, J.: SpaceTools: Tool-augmented spatial reasoning via double interactive RL. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026),https://arxiv.org/abs/2512.04069, to appear 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
In: Advances in Neural Information Processing Systems (NeurIPS) (2024) 2
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: Spatialrgpt: Grounded spatial reasoning in vision-language models. In: Advances in Neural Information Processing Systems (NeurIPS) (2024) 2
2024
-
[14]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017) 22, 24 16 C. Min et al
2017
-
[15]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Danier, D., Aygün, M., Li, C., Bilen, H., Mac Aodha, O.: Depthcues: Evaluating monocular depth perception in large vision models. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 20049–20059 (2025) 4, 5, 21
2025
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muen- nighoff, N., Lo, K., Soldaini, L., et al.: Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 91–104 (2025) 2, 5, 7, 11, 21
2025
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023) 23
2023
-
[18]
Advances in Neural Information Processing Systems 35, 5982–5994 (2022) 22
Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Ehsani, K., Salvador, J., Han, W., Kolve, E., Kembhavi, A., Mottaghi, R.: Procthor: Large-scale embodied ai using procedural generation. Advances in Neural Information Processing Systems 35, 5982–5994 (2022) 22
2022
-
[19]
arXiv preprint arXiv:2505.13441 (2025) 5, 6, 23, 24
Deshpande, A., Deng, Y., Ray, A., Salvador, J., Han, W., Duan, J., Zeng, K.H., Zhu, Y., Krishna, R., Hendrix, R.: Graspmolmo: Generalizable task-oriented grasp- ing via large-scale synthetic data generation. arXiv preprint arXiv:2505.13441 (2025) 5, 6, 23, 24
-
[20]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Du, M., Wu, B., Li, Z., Huang, X.J., Wei, Z.: Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). pp. 346–355 (2024) 2, 3, 4, 6, 12, 24
2024
-
[21]
In: 2021 IEEE International Conference on Robotics and Automation (ICRA)
Eppner, C., Mousavian, A., Fox, D.: Acronym: A large-scale grasp dataset based on simulation. In: 2021 IEEE International Conference on Robotics and Automation (ICRA). pp. 6222–6227. IEEE (2021) 23
2021
-
[22]
Journal of Open Source Software10(105), 7561 (2025) 23
Eppner, C., Murali, A., Garrett, C., O’Flaherty, R., Hermans, T., Yang, W., Fox, D.: scene_synthesizer: A python library for procedural scene generation in robot manipulation. Journal of Open Source Software10(105), 7561 (2025) 23
2025
-
[23]
In: European Conference on Computer Vision
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not per- ceive. In: European Conference on Computer Vision. pp. 148–166. Springer (2024) 2, 3, 10, 25
2024
-
[24]
Google: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities (2025),https://arxiv.org/ abs/2507.062611, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y
Gurnee, W., Tegmark, M.: Language models represent space and time. In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on Learning Representations. vol. 2024, pp. 2483– 2503 (2024),https://proceedings.iclr.cc/paper_files/paper/2024/file/ 0a6059857ae5c82ea9726ee9282a7145-Paper-Conference.pdf12, 32
2024
-
[26]
url: https://web
Hata, K., Savarese, S.: Cs231a course notes 1: Camera models. url: https://web. stanford. edu/class/cs231a/course_ notes/01-camera-models. pdf (2015) 20
2015
-
[27]
Springer Nature (2022) 21
Hoiem, D., Savarese, S.: Representations and techniques for 3D object recognition and scene interpretation. Springer Nature (2022) 21
2022
-
[28]
In: Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing
Hu, J., Levy, R.: Prompting is not a substitute for probability measurements in large language models. In: Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing. pp. 5040–5060 (2023) 8 Why Far Looks Up 17
2023
-
[29]
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springenberg, J.T., Stachow...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
In: Proceedings of the Con- ference on Empirical Methods in Natural Language Processing (EMNLP) (2023) 3
Kamath, A., Hessel, J., Chang, K.W.: What’s “up” with vision-language models? investigating their struggle with spatial reasoning. In: Proceedings of the Con- ference on Empirical Methods in Natural Language Processing (EMNLP) (2023) 3
2023
-
[31]
arXiv preprint arXiv:2601.12626 (2026) 4
Kang, R., Chen, H., Gkioxari, G., Perona, P.: Linear mechanisms for spatiotem- poral reasoning in vision language models. arXiv preprint arXiv:2601.12626 (2026) 4
-
[32]
In: Agrawal, P., Kroemer, O., Burgard, W
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., Finn, C.: Openvla: An open-source vision-language-action model. In: Agrawal, P., Kroemer, O., Burgard, W. (eds.) Proceedings of the 8th Conference on R...
2025
-
[33]
AI2-THOR: An Interactive 3D Environment for Visual AI
Kolve, E., Mottaghi, R., Han, W., VanderBilt, E., Weihs, L., Herrasti, A., Deitke, M.,Ehsani,K.,Gordon,D.,Zhu,Y.,etal.:Ai2-thor:Aninteractive3denvironment for visual ai. arXiv preprint arXiv:1712.05474 (2017) 24
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
International journal of computer vision123(1), 32–73 (2017) 24
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision123(1), 32–73 (2017) 24
2017
-
[35]
International journal of computer vision128(7), 1956–1981 (2020) 23
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Ka- mali, S., Popov, S., Malloci, M., Kolesnikov, A., et al.: The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision128(7), 1956–1981 (2020) 23
1956
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lazarow, J., Griffiths, D., Kohavi, G., Crespo, F., Dehghan, A.: Cubify anything: Scaling indoor 3d object detection. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22225–22233 (2025) 23
2025
-
[37]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model
Li, F., Song, W., Zhao, H., Wang, J., Ding, P., Wang, D., Zeng, L., Li, H.: Spatial forcing: Implicit spatial representation alignment for vision-language-action model. arXiv preprint arXiv:2510.12276 (2025) 4
-
[38]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014) 24
2014
-
[39]
Improved Baselines with Visual Instruction Tuning
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744 (2023) 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y., Yang, S., Xi, H., Cao, S., Gu, Y., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4122– 4134 (2025) 5, 7, 11, 21
2025
-
[41]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L.J., Fang, Y., Fox, D., Hu, F., Huang, S., Jang, J., Jiang, Z., Kautz, J., Kundalia, K., Lao, L., Li, Z., Lin, Z., Lin, K., Liu, G., Llontop, E., Magne, L., Mandlekar, A., 18 C. Min et al. Narayan, A., Nasiriany, S., Reed, S., Tan, Y.L., Wang, G., Wang, Z., Wang, J., Wang, Q., X...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
OpenAI: Openai gpt-5 system card (2025),https://arxiv.org/abs/2601.03267 1, 27
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 32
2021
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Raistrick, A., Mei, L., Kayan, K., Yan, D., Zuo, Y., Han, B., Wen, H., Parakh, M., Alexandropoulos, S., Lipson, L., et al.: Infinigen indoors: Photorealistic indoor scenes using procedural generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21783–21794 (2024) 23
2024
-
[45]
In: Second Conference on Language Modeling (2025),https://openreview.net/forum?id=DW8U8ZWa1U 4, 5, 6, 22, 24
Ray, A., Duan, J., II, E.L.B., Tan, R., Bashkirova, D., Hendrix, R., Ehsani, K., Kembhavi,A.,Plummer,B.A.,Krishna,R.,Zeng,K.H.,Saenko,K.:SAT:Dynamic spatial aptitude training for multimodal language models. In: Second Conference on Language Modeling (2025),https://openreview.net/forum?id=DW8U8ZWa1U 4, 5, 6, 22, 24
2025
-
[46]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops
Savva, M., Chang, A.X., Hanrahan, P.: Semantically-enriched 3d models for common-sense knowledge. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp. 24–31 (2015) 23
2015
-
[47]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations
Sheta, H., Huang, E.H., Wu, S., Alenabi, I., Hong, J., Lin, R., Ning, R., Wei, D., Yang, J., Zhou, J., et al.: From behavioral performance to internal compe- tence: Interpreting vision-language models with vlm-lens. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. pp. 886–895 (2025) 4
2025
-
[48]
V2xp-asg: Generating adversarial scenes for vehicle-to-everything perception
Singh, I., Blukis, V., Mousavian, A., Goyal, A., Xu, D., Tremblay, J., Fox, D., Thomason, J., Garg, A.: Progprompt: Generating situated robot task plans us- ing large language models. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 11523–11530 (2023).https://doi.org/10.1109/ ICRA48891.2023.101613171
-
[49]
In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=WGXb7UdvTX12, 32
Skean, O., Arefin, M.R., Zhao, D., Patel, N.N., Naghiyev, J., LeCun, Y., Shwartz- Ziv, R.: Layer by layer: Uncovering hidden representations in language models. In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=WGXb7UdvTX12, 32
2025
-
[50]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Song, C.H., Blukis, V., Tremblay, J., Tyree, S., Su, Y., Birchfield, S.: Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15768–15780 (2025) 2, 4, 5, 6, 22, 24
2025
-
[51]
In: ICCV (2023) 1
Song, C.H., Wu, J., Washington, C., Sadler, B.M., Chao, W.L., Su, Y.: Llm- planner: Few-shot grounded planning for embodied agents with large language models. In: ICCV (2023) 1
2023
-
[52]
Springer Nature (2022) 20
Szeliski, R.: Computer vision: algorithms and applications. Springer Nature (2022) 20
2022
-
[53]
arXiv preprint arXiv:2601.14352 (2026) 2 Why Far Looks Up 19
Tan, H., Zhou, E., Li, Z., Xu, Y., Ji, Y., Chen, X., Chi, C., Wang, P., Jia, H., Ao, Y., Cao, M., Chen, S., Li, Z., Liu, M., Wang, Z., Rong, S., Lyu, Y., Zhao, Z., Co, P., Li, Y., Han, Y., Xie, S., Yao, G., Wang, S., Zhang, L., Yang, X., Jiao, Y., Shi, D., Xie, K., Nie, S., Men, C., Lin, Y., Wang, Z., Huang, T., Zhang, S.: Robobrain 2.5: Depth in sight, t...
-
[54]
Gemini Robotics: Bringing AI into the Physical World
Team, G.R., Abeyruwan, S., Ainslie, J., Alayrac, J.B., Arenas, M.G., Armstrong, T., Balakrishna, A., Baruch, R., Bauza, M., Blokzijl, M., et al.: Gemini robotics: Bringing ai into the physical world. arXiv preprint arXiv:2503.20020 (2025) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https:// openreview.net/forum?id=Vi8AepAXGy2, 3, 4, 6, 24, 32
Tong, S., II, E.L.B., Wu, P., Woo, S., IYER, A.J., Akula, S.C., Yang, S., Yang, J., Middepogu, M., Wang, Z., Pan, X., Fergus, R., LeCun, Y., Xie, S.: Cambrian-1: A fully open, vision-centric exploration of multimodal LLMs. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https:// openreview.net/forum?id=Vi8AepAXGy2, ...
2024
-
[56]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) 32
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Wang, X., Ma, W., Zhang, T., de Melo, C.M., Chen, J., Yuille, A.: Spatial457: A diagnostic benchmark for 6d spatial reasoning of large mutimodal models. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 24669– 24679 (2025) 4
2025
-
[58]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Wang,Y.,Shi,F.:Logicalformscomplementprobabilityinunderstandinglanguage model (and human) performance. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 16862–16877 (2025) 8
2025
-
[59]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22 (2023) 22
2023
-
[60]
From flatland to space: Teaching vision-language models to perceive and reason in 3d
Zhang, J., Chen, Y., Zhou, Y., Xu, Y., Huang, Z., Mei, J., Chen, J., Yuan, Y.J., Cai, X., Huang, G., et al.: From flatland to space: Teaching vision-language models to perceive and reason in 3d. arXiv preprint arXiv:2503.22976 (2025) 5, 6, 22, 24
- [61]
-
[62]
In: The Thirteenth International Conference on Learning Rep- resentations (2025),https://openreview.net/forum?id=84pDoCD4lH3, 8
Zhang, Z., Hu, F., Lee, J., Shi, F., Kordjamshidi, P., Chai, J., Ma, Z.: Do vision- language models represent space and how? evaluating spatial frame of reference under ambiguities. In: The Thirteenth International Conference on Learning Rep- resentations (2025),https://openreview.net/forum?id=84pDoCD4lH3, 8
2025
-
[63]
In: European Conference on Computer Vision
Zheng, J., Zhang, J., Li, J., Tang, R., Gao, S., Zhou, Z.: Structured3d: A large photo-realistic dataset for structured 3d modeling. In: European Conference on Computer Vision. pp. 519–535. Springer (2020) 22
2020
-
[64]
International journal of computer vision127(3), 302–321 (2019) 24
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., Torralba, A.: Se- mantic understanding of scenes through the ade20k dataset. International journal of computer vision127(3), 302–321 (2019) 24
2019
-
[65]
Is the {obj1} closer to the camera than the {obj2}?
Zhou, E., An, J., Chi, C., Han, Y., Rong, S., Zhang, C., Wang, P., Wang, Z., Huang, T., Sheng, L., Zhang, S.: Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum? id=OGxalNUHbJ2, 4, 5, 6, 7, 9, 11, 13,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.