Anti Mode-Collapse in Mean-Field Transformer via Auxiliary Variables
Pith reviewed 2026-06-29 08:44 UTC · model grok-4.3
The pith
Auxiliary variables prevent mode collapse in mean-field transformers by turning the limiting distribution into a pushforward of their own distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
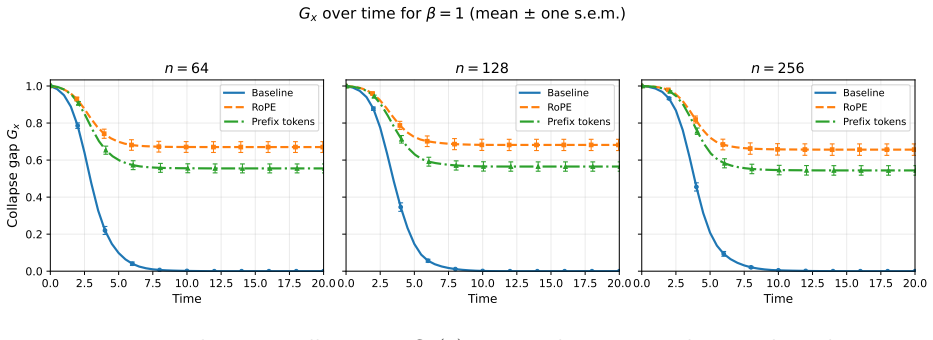
In the mean-field transformer model the introduction of auxiliary variables acts as a counterforce against theoretical mode collapse. The energy-maximizing distribution does not degenerate to a single point; instead it is characterized by a pushforward of the auxiliary variable distribution, thereby avoiding concentration in the Dirac measure. Positional encoding and fixed prompt insertion are the main examples and possess universality of representation in the limit, meaning the limit distribution of inference can exactly represent a wide class of distributions.
What carries the argument
Auxiliary variables inserted into the mean-field transformer energy function, which produce a pushforward of the auxiliary distribution as the long-inference energy maximizer.
If this is right
- The limiting distribution avoids concentration in the Dirac measure when auxiliary variables are present.
- Positional encoding and prompt insertion enable the inference limit to represent a wide class of distributions exactly.
- Properties of positional encoding and metastability admit analysis inside the same energy framework.
- Mathematical experiments confirm that the pushforward characterization prevents the predicted collapse.
Where Pith is reading between the lines
- The same auxiliary-variable construction could be tested for stabilizing other iterative attention or diffusion processes whose energy functions favor concentration.
- If the mean-field limit approximates finite-width networks, the pushforward mechanism supplies a concrete reason positional encodings remain effective at large depth.
- The universality statement implies that auxiliary variables alone may suffice for transformers to reach arbitrary target distributions without extra architectural components.
Load-bearing premise
The mean-field transformer model accurately captures the behavior of self-attention mechanisms in real transformers, particularly the energy function and the long-inference limit.
What would settle it
A direct simulation of the mean-field dynamics without auxiliary variables that produces collapse to a Dirac measure after sufficient layers, together with the same simulation that shows no collapse once auxiliary variables are restored.
Figures

read the original abstract
We use a mean-field-based transformer model to theoretically investigate how auxiliary variables, such as positional encoding, prevent mode collapse of self-attention mechanisms. The use of mean-field transformers to analyze the properties of self-attention mechanisms has garnered significant attention in recent years due to their ability to comprehensively analyze token interactions. However, analysis of this simple model suggests that mode collapse, where token distributions degenerate to a single point, occurs during long inferences (i.e., many layers), indicating a discrepancy with reality. This study investigates this mean-field transformer model and demonstrates that the introduction of auxiliary variables, such as positional encoding, acts as a counterforce against theoretical mode collapse. Specifically, we show that in the theoretical scheme, the energy-maximizing distribution does not degenerate to a single point; instead, it is characterized by a pushforward of the auxiliary variable distribution, thereby avoiding concentration in the Dirac measure. Our main examples are the positional encoding and the fixed prompt insertion treated as a parallel auxiliary-variable mechanism. Furthermore, we demonstrate that positional encoding and prompt insertion possess universality of representation in the limit, meaning that the limit distribution of inference can exactly represent a wide class of distributions. We also analyze several key properties of positional encoding and metastability, and validate our theoretical results through mathematical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes a mean-field transformer model of self-attention and claims that auxiliary variables (positional encodings and fixed prompts) prevent theoretical mode collapse in the long-inference limit. It shows that the energy-maximizing distribution is the pushforward of the auxiliary-variable distribution rather than a Dirac measure, establishes universality of the limiting distribution under these mechanisms, analyzes metastability and other properties of positional encoding, and validates the results via mathematical experiments.
Significance. If the mean-field derivations hold, the work supplies a structural explanation, internal to the model, for why mode collapse is avoided when auxiliary variables are present, together with a universality result on the representable limiting distributions. The explicit treatment of prompts as a parallel auxiliary mechanism is a useful extension.
major comments (2)
- [Introduction, §2] Introduction and §2: the claim that the mean-field energy function and continuum limit resolve the observed discrepancy with real transformers rests on an untested fidelity assumption; no quantitative bound or ablation is given showing that omitted finite-width effects, discrete token geometry, or attention-matrix interactions with positional encodings do not alter the anti-collapse conclusion.
- [Universality section] The universality statement (that the limit distribution can exactly represent a wide class of distributions) is stated for positional encoding and prompt insertion, but the precise conditions on the auxiliary measure (e.g., support requirements or moment conditions) are not made explicit, making it difficult to assess the scope of the result.
minor comments (2)
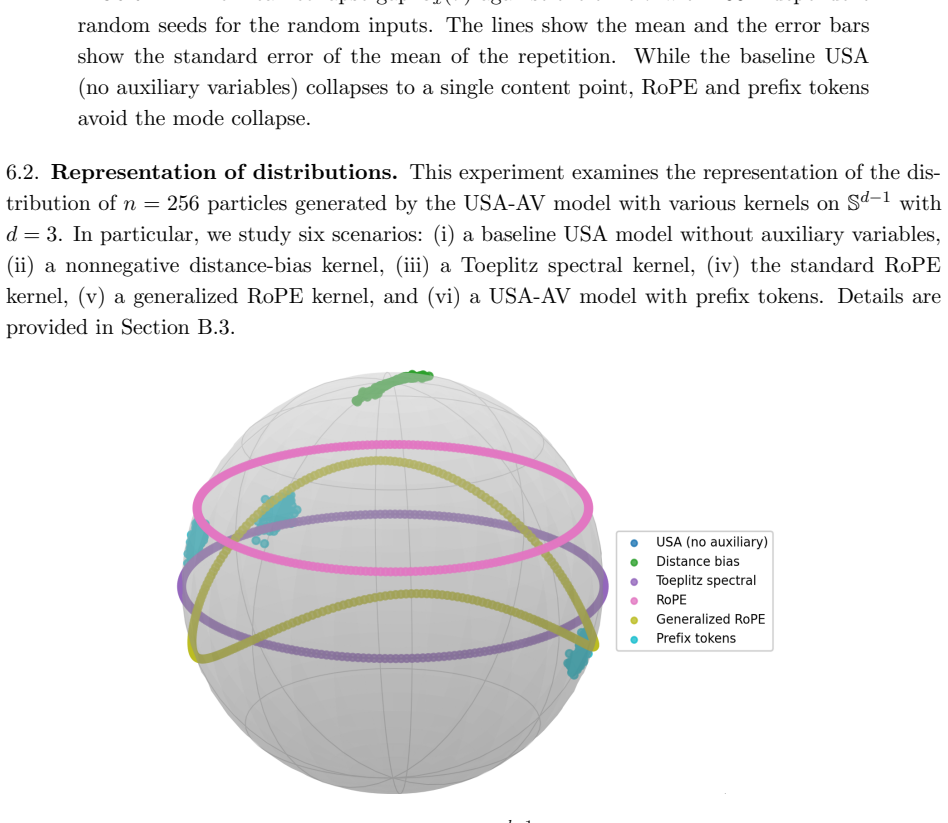
- The abstract refers to 'mathematical experiments' but the corresponding figures or tables lack details on discretization, number of samples, or convergence diagnostics.
- [§2] Notation for the token-interaction kernel and the auxiliary-variable pushforward should be introduced with a short table or diagram in §2 to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we respond point-by-point to the major comments, indicating where revisions will be made to improve clarity and scope.
read point-by-point responses
-
Referee: [Introduction, §2] Introduction and §2: the claim that the mean-field energy function and continuum limit resolve the observed discrepancy with real transformers rests on an untested fidelity assumption; no quantitative bound or ablation is given showing that omitted finite-width effects, discrete token geometry, or attention-matrix interactions with positional encodings do not alter the anti-collapse conclusion.
Authors: We agree that the manuscript does not supply quantitative error bounds between the mean-field limit and finite-width transformers, nor ablations on discrete token geometry or attention-matrix interactions. The core contribution is a rigorous analysis within the mean-field regime (infinite-width limit), where auxiliary variables provably prevent collapse to a Dirac measure. In the revised manuscript we will add an explicit paragraph in the introduction clarifying that the anti-collapse result holds in the mean-field limit and that finite-width fidelity is left for future work; this does not change the stated theorems but addresses the scope concern. revision: partial
-
Referee: [Universality section] The universality statement (that the limit distribution can exactly represent a wide class of distributions) is stated for positional encoding and prompt insertion, but the precise conditions on the auxiliary measure (e.g., support requirements or moment conditions) are not made explicit, making it difficult to assess the scope of the result.
Authors: We accept this criticism. The universality theorems rely on the auxiliary measure having full support (or being absolutely continuous with positive density on a compact domain) so that the pushforward can realize the target class of distributions. In the revised version we will state these conditions explicitly in the theorem statements and add a short remark on the minimal moment requirements needed for the energy functional to be well-defined. revision: yes
- Quantitative bounds or ablations showing that finite-width effects, discrete token geometry, or attention-matrix interactions with positional encodings do not alter the anti-collapse conclusion.
Circularity Check
No circularity: derivation self-contained in mean-field energy analysis
full rationale
The paper's central result—that auxiliary variables yield an energy-maximizing distribution as a pushforward of the auxiliary distribution rather than a Dirac measure—follows directly from the stated mean-field transformer energy function and the explicit insertion of auxiliary variables (positional encoding, fixed prompts). No equations reduce the output to the input by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems imported from the authors' prior work are invoked in the provided text. The universality and metastability claims are presented as consequences of the same energy-maximization scheme. The model-to-reality fidelity gap noted by the reader is an external-validity concern, not a circularity within the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mean-field approximation for transformer self-attention
Reference graph
Works this paper leans on
-
[1]
[ACLY25] Awni Altabaa, Siyu Chen, John Lafferty, and Zhuoran Yang. Unlocking out-of- distribution generalization in transformers via recursive latent space reasoning.arXiv preprint arXiv:2510.14095,
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
[BMR+20] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901,
1901
-
[3]
Longformer: The Long-Document Transformer
[BPC20] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[4]
[Che26] Hung-Hsuan Chen. Thinking deeper, not longer: Depth-recurrent transformers for compositional generalization.arXiv preprint arXiv:2603.21676,
-
[5]
Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
[FDRL24] Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647,
-
[6]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
[GMJ+25] Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test- time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training-Induced Escape from Token Clustering in a Mean-Field Formulation of Transformers
[III26] Noboru Isobe, Daisuke Inoue, and Masaaki Imaizumi. Training-induced escape from token clustering in a mean-field formulation of transformers.arXiv preprint arXiv:2605.07772,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
The power of scale for parameter- efficient prompt tuning
[LARC21] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter- efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059,
2021
-
[9]
The mean-field dynamics of transformers
[Rig25] Philippe Rigollet. The mean-field dynamics of transformers.arXiv preprint arXiv:2512.01868,
-
[10]
Self-attention with relative position representations
[SUV18] Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. InProceedings of the 2018 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468,
2018
-
[11]
Topics in propagation of chaos
[Szn91] Alain-Sol Sznitman. Topics in propagation of chaos. In ´Ecole d’ ´Et´ e de Probabilit´ es de Saint-Flour XIX—1989, volume 1464 ofLecture Notes in Mathematics, pages 165–251. Springer, Berlin, Heidelberg,
1989
-
[12]
[XS24] Kevin Xu and Issei Sato. On expressive power of looped transformers: Theoretical analysis and enhancement via timestep encoding.arXiv preprint arXiv:2410.01405,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.