Recognition: 2 theorem links
· Lean TheoremTraining-Induced Escape from Token Clustering in a Mean-Field Formulation of Transformers
Pith reviewed 2026-05-11 02:39 UTC · model grok-4.3
The pith
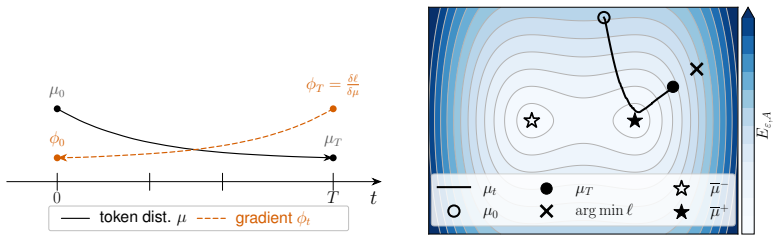
Training can make token distributions escape attention-driven clusters near the final layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the noisy mean-field Transformer with a parameter-linear FFN trained under L2 regularization, the token distribution initially follows attention-driven clustering but then escapes the clustered regime near the final layers. This training-induced phase is derived from an entropy-regularized interaction energy that captures the clustering bias of attention.
What carries the argument
Entropy-regularized interaction energy, which quantifies attention's bias toward clustering and serves as the lens for analyzing how training perturbs the token distribution across layers.
If this is right
- Token distributions exhibit greater diversity in the output layers than attention alone predicts.
- Mean-field theories of Transformers must treat training and inference dynamics jointly to describe late-layer behavior.
- L2 regularization on the feed-forward parameters enables the escape from clustering in this model.
- The transition from clustering to escape occurs progressively and becomes prominent near the final layers.
Where Pith is reading between the lines
- If the escape occurs in full Transformers, it may explain why final embeddings support tasks that require distinguishing tokens.
- Adjusting regularization strength or layer depth could be used to tune the degree of clustering at the output.
- Extending the analysis to include training of attention weights might reveal whether the escape phase persists or changes form.
Load-bearing premise
The noisy mean-field Transformer with only a parameter-linear FFN trained under L2 regularization captures the essential interaction between training and attention-driven clustering.
What would settle it
Direct measurements in a trained Transformer showing whether token representations remain clustered or disperse specifically in the final layers versus earlier layers would confirm or refute the predicted escape.
Figures




read the original abstract
Transformers perform inference by iteratively transforming token representations across layers. This layerwise computation has been studied empirically, and recent mean-field theories of Transformer dynamics explain how attention can drive token distributions toward clustering. However, existing mean-field analyses largely treat model parameters as prescribed, leaving open how training reshapes this clustering picture. We study this question in a noisy mean-field Transformer in which only a parameter-linear FFN is trained under $L^2$ regularization. We find and analyze a training-induced phase in the dynamics: after initially following attention-driven clustering, the token distribution can leave the clustered regime near the final layers. Our mathematical analysis is based on an entropy-regularized interaction energy that captures the clustering bias of attention. More broadly, our results point toward a training-aware mean-field theory of Transformer dynamics, in which training and inference dynamics are treated together.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a noisy mean-field formulation of Transformer dynamics in which only a parameter-linear feed-forward network is trained under L2 regularization. It identifies and analyzes a training-induced phase in the layerwise token evolution: after initially following attention-driven clustering, the token distribution escapes the clustered regime near the final layers. The analysis relies on an entropy-regularized interaction energy that quantifies the clustering bias of attention, with the goal of moving toward a training-aware mean-field theory that couples training and inference.
Significance. If the derivations hold, the work provides a concrete mathematical example of how training can counteract attention-induced clustering, advancing beyond prior mean-field analyses that treat parameters as fixed. The entropy-regularized interaction energy offers a clean, rigorous handle on the dynamics and is a clear strength. This could stimulate further research on integrated training-inference theories for attention models, though the extreme simplifications (linear FFN, L2 only) limit immediate generality to practical Transformers.
major comments (1)
- [Model and Setup] The escape phase is demonstrated exclusively in the parameter-linear FFN + L2-regularized setup (as stated in the abstract and model section). This modeling choice is load-bearing for interpreting the phase as a general 'training-induced' effect rather than an artifact; without a robustness analysis or explicit discussion of what happens under a nonlinear FFN (while keeping the same regularization and noise), it remains unclear whether the reported escape would persist in more standard Transformer components.
minor comments (2)
- The abstract and introduction could more explicitly flag the linear-FFN restriction upfront so readers immediately understand the scope of the claimed phase.
- [Analysis] Clarify the precise definition and derivation steps of the entropy-regularized interaction energy, including any approximations introduced by the mean-field limit and noise.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper accordingly to better contextualize our modeling choices.
read point-by-point responses
-
Referee: [Model and Setup] The escape phase is demonstrated exclusively in the parameter-linear FFN + L2-regularized setup (as stated in the abstract and model section). This modeling choice is load-bearing for interpreting the phase as a general 'training-induced' effect rather than an artifact; without a robustness analysis or explicit discussion of what happens under a nonlinear FFN (while keeping the same regularization and noise), it remains unclear whether the reported escape would persist in more standard Transformer components.
Authors: We thank the referee for this observation. The parameter-linear FFN under L2 regularization was deliberately chosen to obtain a tractable noisy mean-field limit in which the coupled training and inference dynamics admit explicit analysis via the entropy-regularized interaction energy. This setup isolates the mechanism by which regularized training can counteract attention-driven clustering, providing a concrete mathematical example of training-aware dynamics. We do not claim that the escape phase holds identically for nonlinear FFNs; the linear case serves as a first step toward a training-aware mean-field theory. In the revision we will add explicit discussion in the model section and conclusion explaining the rationale for the linear FFN, its analytical advantages, and the open question of extensions to nonlinear components, while noting that a full robustness analysis lies beyond the present scope. revision: partial
Circularity Check
No circularity: derivation is self-contained within explicitly defined simplified model
full rationale
The paper defines a specific noisy mean-field Transformer with parameter-linear FFN under L2 regularization as the setting for analysis, then derives the training-induced escape phase via an entropy-regularized interaction energy applied to the model's dynamics. No steps reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the escape behavior is obtained as a mathematical consequence of the stated equations rather than an input. The model is presented as a deliberate simplification to study training effects, with no load-bearing self-citations or ansatzes imported from prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our mathematical analysis is based on an entropy-regularized interaction energy that captures the clustering bias of attention.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the token distribution can leave the clustered regime near the final layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Attention is All you Need , url =. Advances in Neural Information Processing Systems , editor =
-
[2]
Layer Normalization , author =. 2016 , eprint =. doi:10.48550/arXiv.1607.06450 , note =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.06450 2016
-
[3]
The emergence of clusters in self-attention dynamics , url =
Geshkovski, Borjan and Letrouit, Cyril and Polyanskiy, Yury and Rigollet, Philippe , booktitle =. The emergence of clusters in self-attention dynamics , url =
-
[4]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
A multiscale analysis of mean-field transformers in the moderate interaction regime , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Emergence of meta-stable clustering in mean-field transformer models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
Diederik P. Kingma and Jimmy Ba , title =. The Third International Conference on Learning Representations , year =
-
[7]
Geshkovski, Borjan and Letrouit, Cyril and Polyanskiy, Yury and Rigollet, Philippe , title =. Bull. Am. Math. Soc., New Ser. , issn =. 2025 , doi =
work page 2025
-
[8]
Perceptrons and localization of attention's mean-field landscape , author=. 2026 , eprint=
work page 2026
-
[9]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[10]
Burger, Martin and Kabri, Samira and Korolev, Yury and Roith, Tim and Weigand, Lukas , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2025 , month =. doi:10.1098/rsta.2024.0233 , url =
-
[11]
Quantitative Clustering in Mean-Field Transformer Models , author=. 2025 , eprint=
work page 2025
- [12]
-
[13]
Mathematics of Control, Signals, and Systems , volume =
Integral and measure-turnpike properties for infinite-dimensional optimal control systems , author =. Mathematics of Control, Signals, and Systems , volume =. 2018 , doi =
work page 2018
-
[14]
Systems & Control Letters , volume =
On the relation between strict dissipativity and turnpike properties , author =. Systems & Control Letters , volume =. 2016 , doi =
work page 2016
-
[15]
Mathematics of Control, Signals, and Systems , year =
Manifold Turnpikes and their Role in Nonlinear Optimal Control , author =. Mathematics of Control, Signals, and Systems , year =
-
[16]
European Journal of Applied Mathematics , author=
Exponential turnpike property for particle systems and mean-field limit , volume=. European Journal of Applied Mathematics , author=. 2025 , pages=. doi:10.1017/S0956792524000871 , number=
-
[17]
Faulwasser, Timm and Gr. Turnpike properties in optimal control: an overview of discrete-time and continuous-time results , booktitle =. 2022 , publisher =
work page 2022
-
[18]
Baernstein II, Albert and Taylor, B. A. , title =. Duke Mathematical Journal , volume =. 1976 , doi =
work page 1976
-
[19]
Fatkullin, I. and Slastikov, V. , title =. Nonlinearity , volume =. 2005 , doi =
work page 2005
-
[20]
Communications in Mathematical Sciences , volume =
Liu, Hailiang and Zhang, Hui and Zhang, Pingwen , title =. Communications in Mathematical Sciences , volume =. 2005 , doi =
work page 2005
-
[21]
Vollmer, Michaela A. C. , title =. Archive for Rational Mechanics and Analysis , volume =. 2017 , doi =
work page 2017
-
[22]
Ball, J. M. , title =. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =. 2021 , doi =
work page 2021
- [23]
- [24]
-
[25]
A measure theoretical approach to the mean-field maximum principle for training NeurODEs , journal =
Beno\^. A measure theoretical approach to the mean-field maximum principle for training NeurODEs , journal =. 2023 , issn =. doi:https://doi.org/10.1016/j.na.2022.113161 , url =
-
[26]
Beno\^. A Pontryagin Maximum Principle in Wasserstein spaces for constrained optimal control problems* , DOI= "10.1051/cocv/2019044", url= "https://doi.org/10.1051/cocv/2019044", journal =
-
[27]
Turnpike in optimal control of PDEs, ResNets, and beyond , volume=
Geshkovski, Borjan and Zuazua, Enrique , year=. Turnpike in optimal control of PDEs, ResNets, and beyond , volume=. doi:10.1017/S0962492922000046 , journal=
- [28]
- [29]
-
[30]
The Exponential Turnpike Property for Neural Differential Equations , year=
Gugat, Martin , booktitle=. The Exponential Turnpike Property for Neural Differential Equations , year=
-
[31]
Exponential Turnpike Theorems for Nonlinear Deterministic Meanfield Optimal Control Problems , author=. 2026 , eprint=
work page 2026
-
[32]
Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages =
Sinkformers: Transformers with Doubly Stochastic Attention , author =. Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages =. 2022 , editor =
work page 2022
-
[33]
Kojima, Takeshi and Okimura, Itsuki and Iwasawa, Yusuke and Yanaka, Hitomi and Matsuo, Yutaka. On the Multilingual Ability of Decoder-based Pre-trained Language Models: Finding and Controlling Language-Specific Neurons. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[34]
Suppressing Final Layer Hidden State Jumps in Transformer Pretraining , booktitle =
Keigo Shibata and Kazuki Yano and Ryosuke Takahashi and Jaesung Lee and Wataru Ikeda and Jun Suzuki , editor =. Suppressing Final Layer Hidden State Jumps in Transformer Pretraining , booktitle =. 2026 , url =
work page 2026
-
[35]
Barboni, Rapha\". On global convergence of ResNets: From finite to infinite width using linear parameterization , url =. Advances in Neural Information Processing Systems , editor =
-
[36]
Chen, Ricky T. Q. and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David K , booktitle =. Neural Ordinary Differential Equations , url =
-
[37]
Communications in Mathematics and Statistics , year=
E, Weinan , title=. Communications in Mathematics and Statistics , year=. doi:10.1007/s40304-017-0103-z , url=
-
[38]
Research in the Mathematical Sciences , year=
E, Weinan and Han, Jiequn and Li, Qianxiao , title=. Research in the Mathematical Sciences , year=. doi:10.1007/s40687-018-0172-y , url=
-
[39]
Dynamical Systems and Optimal Control Approach to Deep Learning , booktitle=
Han, Jiequn and E, Weinan and Li, Qianxiao , editor=. Dynamical Systems and Optimal Control Approach to Deep Learning , booktitle=. 2022 , pages=
work page 2022
-
[40]
Journal of Machine Learning , year=
Variational Formulations of ODE-Net as a Mean-Field Optimal Control Problem and Existence Results , author=. Journal of Machine Learning , year=. doi:10.4208/jml.231210 , number=
-
[41]
Scagliotti, A. , title=. Journal of Dynamical and Control Systems , year=. doi:10.1007/s10883-022-09604-2 , url=
-
[42]
Dissecting Neural ODEs , url =
Massaroli, Stefano and Poli, Michael and Park, Jinkyoo and Yamashita, Atsushi and Asama, Hajime , booktitle =. Dissecting Neural ODEs , url =
-
[43]
Clustering in Causal Attention Masking , url =
Karagodin, Nikita and Polyanskiy, Yury and Rigollet, Philippe , booktitle =. Clustering in Causal Attention Masking , url =. doi:10.52202/079017-3673 , editor =
-
[44]
Generalization bounds for neural ordinary differential equations and deep residual networks , url =
Marion, Pierre , booktitle =. Generalization bounds for neural ordinary differential equations and deep residual networks , url =
-
[45]
Bogachev and Michael Röckner and Stanislav V
Vladimir I. Bogachev and Michael Röckner and Stanislav V. Shaposhnikov , keywords =. Convergence in variation of solutions of nonlinear Fokker--Planck--Kolmogorov equations to stationary measures , journal =. 2019 , issn =. doi:https://doi.org/10.1016/j.jfa.2019.03.014 , url =
-
[46]
Estimates of heat kernels on Riemannian manifolds , booktitle=
Grigor'yan, Alexander , editor=. Estimates of heat kernels on Riemannian manifolds , booktitle=. 1999 , pages=
work page 1999
-
[47]
Propagation of chaos: A review of models, methods and applications
Louis-Pierre Chaintron and Antoine Diez , keywords =. Propagation of chaos: A review of models, methods and applications. II. Applications , journal =. 2022 , issn =. doi:10.3934/krm.2022018 , url =
-
[48]
Bag-of-Words as Target for Neural Machine Translation
Ma, Shuming and Sun, Xu and Wang, Yizhong and Lin, Junyang. Bag-of-Words as Target for Neural Machine Translation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. doi:10.18653/v1/P18-2053
-
[49]
Turnpike in optimal control and beyond: a survey , author=. 2025 , eprint=
work page 2025
-
[50]
Esteve-Yagüe, Carlos and Geshkovski, Borjan and Pighin, Dario and Zuazua, Enrique , title =. 2022 , month =. doi:10.1088/1361-6544/ac4e61 , url =
-
[51]
Spaces of Measures and Related Differential Calculus
Carmona, Ren \'e and Delarue, Fran c ois. Spaces of Measures and Related Differential Calculus. Probabilistic Theory of Mean Field Games with Applications I: Mean Field FBSDEs, Control, and Games. 2018. doi:10.1007/978-3-319-58920-6_5
-
[52]
Journal of Evolution Equations , year=
Fukao, Takeshi and Stefanelli, Ulisse and Voso, Riccardo , title=. Journal of Evolution Equations , year=. doi:10.1007/s00028-025-01086-6 , url=
- [53]
-
[54]
Burger, Martin and Pinnau, Ren\'. Mean-Field Optimal Control and Optimality Conditions in the Space of Probability Measures , journal =. 2021 , doi =
work page 2021
-
[55]
A Mechanistic Analysis of Looped Reasoning Language Models , author=. 2026 , eprint=
work page 2026
-
[56]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Recurrent Self-Attention Dynamics: An Energy-Agnostic Perspective from Jacobians , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[57]
On the Structure of Stationary Solutions to McKean-Vlasov Equations with Applications to Noisy Transformers , author=. 2025 , eprint=
work page 2025
-
[58]
Advances in Nonlinear Analysis , doi =
Solutions of stationary McKean--Vlasov equation on a high-dimensional sphere and other Riemannian manifolds , author =. Advances in Nonlinear Analysis , doi =. 2026 , lastchecked =
work page 2026
-
[59]
Stochastic Scaling Limits and Synchronization by Noise in Deep Transformer Models , author=. 2026 , eprint=
work page 2026
-
[60]
Spectral Selection in Symmetric Self-Attention Dynamics , author=. 2026 , eprint=
work page 2026
-
[61]
Zhao, Haiyan and Chen, Hanjie and Yang, Fan and Liu, Ninghao and Deng, Huiqi and Cai, Hengyi and Wang, Shuaiqiang and Yin, Dawei and Du, Mengnan , title =. 2024 , issue_date =. doi:10.1145/3639372 , journal =
-
[62]
Mechanistic Interpretability for
Leonard Bereska and Stratis Gavves , journal=. Mechanistic Interpretability for. 2024 , url=
work page 2024
-
[63]
A Primer in BERT ology: What We Know About How BERT Works
Rogers, Anna and Kovaleva, Olga and Rumshisky, Anna. A Primer in BERT ology: What We Know About How BERT Works. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00349
-
[64]
Locating and Editing Factual Associations in GPT , url =
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in GPT , url =
-
[65]
Quantifying attention flow in transformers
Abnar, Samira and Zuidema, Willem. Quantifying Attention Flow in Transformers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.385
-
[66]
Causal Abstractions of Neural Networks , url =
Geiger, Atticus and Lu, Hanson and Icard, Thomas and Potts, Christopher , booktitle =. Causal Abstractions of Neural Networks , url =
- [67]
-
[68]
Synchronization of mean-field models on the circle , author=. 2025 , eprint=
work page 2025
-
[69]
Synchronization on circles and spheres with nonlinear interactions , author=. 2026 , eprint=
work page 2026
-
[70]
Dynamic metastability in the self-attention model , author=. 2024 , eprint=
work page 2024
-
[71]
Proceedings of the 40th International Conference on Machine Learning , pages =
Transformers Learn In-Context by Gradient Descent , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[72]
The Impact of LoRA on the Emergence of Clusters in Transformers , author=. 2024 , eprint=
work page 2024
-
[73]
Rate of convergence for ergodic continuous Markov processes: Lyapunov versus Poincaré , journal =
Dominique Bakry and Patrick Cattiaux and Arnaud Guillin , keywords =. Rate of convergence for ergodic continuous Markov processes: Lyapunov versus Poincaré , journal =. 2008 , issn =. doi:https://doi.org/10.1016/j.jfa.2007.11.002 , url =
-
[74]
Bakry, Dominique and Gentil, Ivan and Ledoux, Michel , title =. 2014 , publisher =. doi:10.1007/978-3-319-00227-9 , keywords =
-
[75]
Annales de l'Institut Fourier , pages =
Duprez, Michel and Lissy, Pierre , title =. Annales de l'Institut Fourier , pages =. 2022 , publisher =. doi:10.5802/aif.3501 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.