IP-Adapter Is All You Need: Towards Fine-Tuning-Free Diffusion-Based Talking Face Generation
Pith reviewed 2026-06-29 07:48 UTC · model grok-4.3
The pith
Pretrained IP-Adapter mines lip semantics from Stable Diffusion to generate talking faces without any fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
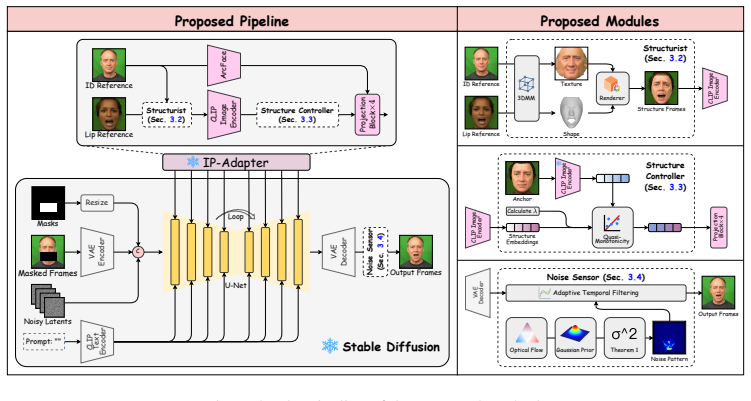
Leveraging the visual embedding capability of the pretrained IP-Adapter to mine lip-related semantics from Stable Diffusion, together with three trainable-parameterfree components—the Structurist that disentangles and reassembles lip and appearance features, the Structure Controller that refines embeddings according to quasi-monotonic motion trends, and the Noise Sensor that uses Gaussian prior to suppress flicker—enables direct talking face generation from pretrained weights.
What carries the argument
IP-Adapter visual embedding for lip semantics extraction, augmented by the Structurist, Structure Controller, and Noise Sensor to correct drift, sync, and instability.
If this is right
- Talking face generation can run directly on existing pretrained diffusion checkpoints without new training runs.
- The approach removes dependence on large-scale audiovisual datasets for this task.
- Lip-sync accuracy improves by at least 0.16 in PCLD and visual fidelity by at least 0.7 in FID relative to prior state-of-the-art methods.
- The same backbone supports both image and video output while maintaining temporal consistency.
Where Pith is reading between the lines
- Similar parameter-free correction modules could be tested on other conditional video tasks that reuse pretrained diffusion backbones.
- The disentanglement strategy in the Structurist may generalize to other appearance-lip separation problems in face animation.
- If the modules remain effective at higher resolutions, the method could support higher-quality output without additional compute.
Load-bearing premise
The pretrained IP-Adapter can extract usable lip semantics from Stable Diffusion without fine-tuning, and the three added components are sufficient to prevent identity drift, synchronization errors, and temporal instability.
What would settle it
Run the method on video inputs with rapid lip motion or strong appearance changes and measure whether lip-sync accuracy drops below prior methods or visible identity distortion appears.
Figures








read the original abstract
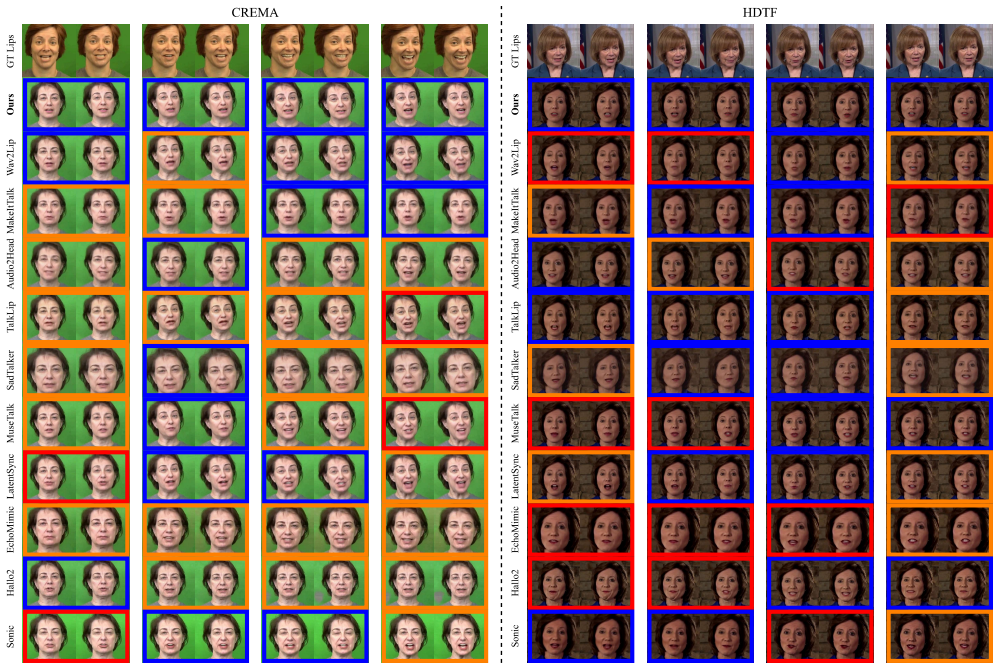
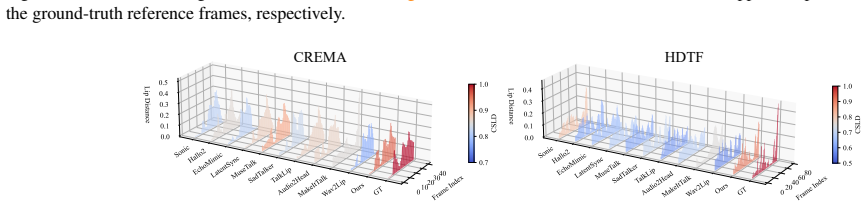
With the rapid advancement of diffusion models, talking face generation has made remarkable progress. However, existing diffusion-based methods still require task-specific fine-tuning and large-scale audiovisual datasets, resulting in high computational costs that hinder scalability and accessibility of diffusion-based approaches across the research community. To address this, we propose a finetuning-free paradigm that directly performs talking face generation using the pretrained weights of Stable Diffusion and IP-Adapter. This backbone leverages the visual embedding capability of IP-Adapter to mine lip-related semantics from the pretrained Stable Diffusion. To address the challenges of identity drift, synchronization errors, and temporal instability, we also design three trainable-parameterfree components: (1) the Structurist, which explicitly disentangles and reassembles lip and appearance features to mitigate identity drift and appearance distortion; (2) the Structure Controller, which adaptively refines embeddings based on quasi-monotonic motion trends for precise lip synchronization; and (3) the Noise Sensor, which introduces Gaussian prior to detect and suppress flicker and jitter artifacts and enhance temporal consistency. Experimental results show that our method outperforms existing SOTA approaches in both lip-sync accuracy (at least 0.16 gain in PCLD) and visual fidelity (at least 0.7 improvement in FID), establishing a novel fine-tuning-free diffusion framework for talking face generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fine-tuning-free diffusion-based method for talking face generation that repurposes pretrained Stable Diffusion and IP-Adapter weights. It introduces three explicitly trainable-parameter-free components—the Structurist (to disentangle and reassemble lip and appearance features), the Structure Controller (to adaptively refine embeddings using quasi-monotonic motion trends), and the Noise Sensor (to introduce Gaussian prior for suppressing flicker)—to mitigate identity drift, synchronization errors, and temporal instability. The authors report that the method outperforms existing SOTA approaches by at least 0.16 in PCLD for lip-sync accuracy and 0.7 in FID for visual fidelity.
Significance. If the central claims hold and the components are verifiably parameter-free, the work would be significant for lowering the barrier to diffusion-based talking face generation by eliminating task-specific fine-tuning and large-scale audiovisual dataset requirements. The explicit use of off-the-shelf pretrained models without additional training is a potential strength that could improve accessibility and reproducibility in the field.
major comments (2)
- [Abstract] Abstract: The claim that the three components are 'trainable-parameterfree' and sufficient to 'explicitly disentangle,' 'adaptively refine,' and 'introduce Gaussian prior' to resolve the three listed failure modes is load-bearing for the fine-tuning-free premise, yet the manuscript supplies no equations, pseudocode, or mechanistic description of how zero trainable parameters achieve feature disentanglement or motion correction.
- [Abstract] Abstract: The quantitative claims of 'at least 0.16 gain in PCLD' and 'at least 0.7 improvement in FID' over SOTA cannot be assessed because the text provides no experimental protocol, dataset description, baseline implementations, ablation studies, or statistical details, which directly undermines verification of the outperformance result.
minor comments (1)
- [Abstract] Abstract: The compound term 'trainable-parameterfree' is missing hyphens and should read 'trainable-parameter-free' for standard readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the three components are 'trainable-parameterfree' and sufficient to 'explicitly disentangle,' 'adaptively refine,' and 'introduce Gaussian prior' to resolve the three listed failure modes is load-bearing for the fine-tuning-free premise, yet the manuscript supplies no equations, pseudocode, or mechanistic description of how zero trainable parameters achieve feature disentanglement or motion correction.
Authors: We agree the abstract is high-level and does not include equations or pseudocode. The full manuscript describes the Structurist, Structure Controller, and Noise Sensor via fixed, non-trainable operations derived from the pretrained models (detailed in Section 3). To make the parameter-free mechanisms explicit and verifiable from the abstract, we will revise the abstract to include concise mechanistic descriptions and add pseudocode to the Methods section. revision: yes
-
Referee: [Abstract] Abstract: The quantitative claims of 'at least 0.16 gain in PCLD' and 'at least 0.7 improvement in FID' over SOTA cannot be assessed because the text provides no experimental protocol, dataset description, baseline implementations, ablation studies, or statistical details, which directly undermines verification of the outperformance result.
Authors: We acknowledge that the abstract alone does not contain the experimental protocol or dataset details. The manuscript includes these in the Experiments section. To allow direct assessment of the reported gains, we will expand the abstract with a brief outline of the evaluation protocol, datasets, and comparison setup. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper proposes a fine-tuning-free method by repurposing pretrained Stable Diffusion and IP-Adapter weights, then introduces three explicitly parameter-free modules (Structurist, Structure Controller, Noise Sensor) whose roles are described at the level of functional intent rather than derived equations. No fitted parameters are renamed as predictions, no self-citations supply load-bearing uniqueness theorems, and no ansatz or renaming of known results is invoked. The central claims rest on experimental metrics (PCLD, FID) rather than any closed derivation chain that reduces outputs to inputs by construction. The absence of equations or parameter-fitting steps in the abstract and described method makes circularity patterns inapplicable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A morphable model for the synthesis of 3d faces
V olker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 157–164. 2023. 4
2023
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
A no reference image blur detection using cu- mulative probability blur detection (cpbd) metric.Interna- tional Journal of Science and Modern Engineering, 1(5),
P Bohr, Rupali Gargote, Rupali Vhorkate, RU Yawle, and VK Bairagi. A no reference image blur detection using cu- mulative probability blur detection (cpbd) metric.Interna- tional Journal of Science and Modern Engineering, 1(5),
-
[4]
Crema-d: Crowd-sourced emotional multimodal actors dataset.IEEE transactions on affective computing, 5(4):377–390, 2014
Houwei Cao, David G Cooper, Michael K Keutmann, Ruben C Gur, Ani Nenkova, and Ragini Verma. Crema-d: Crowd-sourced emotional multimodal actors dataset.IEEE transactions on affective computing, 5(4):377–390, 2014. 2, 6
2014
-
[5]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 2403–2410, 2025. 2, 3, 6
2025
-
[6]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling.arXiv preprint arXiv:1412.3555, 2014. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Out of time: auto- mated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: auto- mated lip sync in the wild. InAsian conference on computer vision, pages 251–263. Springer, 2016. 2
2016
-
[8]
V oxceleb2: Deep speaker recognition.arXiv preprint arXiv:1806.05622, 2018
Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. V oxceleb2: Deep speaker recognition.arXiv preprint arXiv:1806.05622, 2018. 2
-
[9]
Hallo2: Long-duration and high-resolution audio-driven portrait im- age animation
Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu, and Jingdong Wang. Hallo2: Long-duration and high-resolution audio-driven portrait im- age animation. InThe Thirteenth International Conference on Learning Representations, 2025. 2, 3, 6
2025
-
[10]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 4690–4699, 2019. 3, 4
2019
-
[11]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 1, 2
2020
-
[12]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 1, 2
2014
-
[13]
Generalized procrustes analysis.Psychome- trika, 40(1):33–51, 1975
John C Gower. Generalized procrustes analysis.Psychome- trika, 40(1):33–51, 1975. 6
1975
-
[14]
Animatediff: Animate your personalized text- to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text- to-image diffusion models without specific tuning. InThe Twelfth International Conference on Learning Representa- tions, 2024. 2
2024
-
[15]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 6
2017
-
[16]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1, 3
2020
-
[17]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997. 1, 2
1997
-
[18]
A multiresolution 3d morphable face model and fitting framework
Patrik Huber, Guosheng Hu, Rafael Tena, Pouria Mor- tazavian, Willem P Koppen, William Christmas, Matthias R¨atsch, and Josef Kittler. A multiresolution 3d morphable face model and fitting framework. InProceedings of the 11th joint conference on computer vision, imaging and computer graphics theory and applications, pages 79–86. SciTePress,
-
[19]
Eamm: One-shot emotional talking face via audio-based emotion-aware motion model
Xinya Ji, Hang Zhou, Kaisiyuan Wang, Qianyi Wu, Wayne Wu, Feng Xu, and Xun Cao. Eamm: One-shot emotional talking face via audio-based emotion-aware motion model. InACM SIGGRAPH 2022 conference proceedings, pages 1– 10, 2022. 1
2022
-
[20]
Sonic: Shifting focus to global au- dio perception in portrait animation
Xiaozhong Ji, Xiaobin Hu, Zhihong Xu, Junwei Zhu, Chum- ing Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, et al. Sonic: Shifting focus to global au- dio perception in portrait animation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 193–203, 2025. 2, 3, 6
2025
-
[21]
Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, and Yanbo Zheng. Loopy: Taming audio-driven portrait avatar with long-term motion dependency.arXiv preprint arXiv:2409.02634, 2024. 2, 3
-
[22]
Modular primitives for high-performance differentiable rendering.ACM Transac- tions on Graphics (ToG), 39(6):1–14, 2020
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering.ACM Transac- tions on Graphics (ToG), 39(6):1–14, 2020. 4
2020
-
[23]
Chunyu Li, Chao Zhang, Weikai Xu, Jingyu Lin, Jinghui Xie, Weiguo Feng, Bingyue Peng, Cunjian Chen, and Wei- wei Xing. Latentsync: Taming audio-conditioned latent dif- fusion models for lip sync with syncnet supervision.arXiv preprint arXiv:2412.09262, 2024. 2, 3, 6
-
[24]
Dpm-solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Machine Intelligence Research, pages 1–22, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Machine Intelligence Research, pages 1–22, 2025. 6
2025
-
[25]
Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29):861,
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. Umap: Uniform manifold approximation and projection.Journal of Open Source Software, 3(29):861,
-
[26]
Echomimicv2: Towards striking, simplified, and semi- body human animation
Rang Meng, Xingyu Zhang, Yuming Li, and Chenguang Ma. Echomimicv2: Towards striking, simplified, and semi- body human animation. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 5489–5498,
-
[27]
Conditional Generative Adversarial Nets
Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784, 2014. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[28]
A lip sync expert is all you need for speech to lip generation in the wild
KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Nambood- iri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. InProceedings of the 28th ACM international conference on multimedia, pages 484–492, 2020. 2, 6
2020
-
[29]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, and Soumith Chintala. Un- supervised representation learning with deep convolu- tional generative adversarial networks.arXiv preprint arXiv:1511.06434, 2015. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[30]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3
2021
-
[31]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2, 3, 6
2022
-
[32]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 4
2015
-
[33]
Has ¸im Sak, Andrew Senior, and Franc ¸oise Beaufays. Long short-term memory based recurrent neural network architec- tures for large vocabulary speech recognition.arXiv preprint arXiv:1402.1128, 2014. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022. 6
2022
-
[35]
An analysis of variance test for normality.Biometrika, 52(3):591–611, 1965
S Shaphiro and MBJB Wilk. An analysis of variance test for normality.Biometrika, 52(3):591–611, 1965. 5
1965
-
[36]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Seeing what you said: Talking face gen- eration guided by a lip reading expert
Jiadong Wang, Xinyuan Qian, Malu Zhang, Robby T Tan, and Haizhou Li. Seeing what you said: Talking face gen- eration guided by a lip reading expert. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14653–14662, 2023. 3, 6
2023
-
[38]
Mengchao Wang, Qiang Wang, Fan Jiang, Yaqi Fan, Yun- peng Zhang, Yonggang Qi, Kun Zhao, and Mu Xu. Fanta- sytalking: Realistic talking portrait generation via coherent motion synthesis.arXiv preprint arXiv:2504.04842, 2025. 1
-
[39]
Audio2head: Audio-driven one-shot talking-head generation with natural head motion
S Wang, L Li, Y Ding, C Fan, and X Yu. Audio2head: Audio-driven one-shot talking-head generation with natural head motion. InIJCAI International Joint Conference on Artificial Intelligence, pages 1098–1105, 2021. 3, 6
2021
-
[40]
Aniportrait: Audio-driven synthesis of photorealistic portrait animation
Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint arXiv:2403.17694, 2024. 2, 3
-
[41]
Vfhq: A high-quality dataset and bench- mark for video face super-resolution
Liangbin Xie, Xintao Wang, Honglun Zhang, Chao Dong, and Ying Shan. Vfhq: A high-quality dataset and bench- mark for video face super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 657–666, 2022. 2
2022
-
[42]
Mingwang Xu, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Yao Yao, and Siyu Zhu. Hallo: Hierhical audio-driven visual synthesis for portrait image animation.arXiv preprint arXiv:2406.08801, 2024. 3
-
[43]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Celebv-text: A large-scale facial text-video dataset
Jianhui Yu, Hao Zhu, Liming Jiang, Chen Change Loy, Wei- dong Cai, and Wayne Wu. Celebv-text: A large-scale facial text-video dataset. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14805–14814, 2023. 2
2023
-
[45]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
2023
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 6
2018
-
[47]
Sadtalker: Learning realistic 3d motion coefficients for stylized audio- driven single image talking face animation
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio- driven single image talking face animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8652–8661, 2023. 3, 6
2023
-
[48]
Musetalk: Real-time high quality lip synchronization with latent space inpainting
Yue Zhang, LIU Minhao, Zhaokang Chen, Bin Wu, Chao Zhan, Yingjie He, JUNXIN HUANG, Wenjiang Zhou, et al. Musetalk: Real-time high quality lip synchronization with latent space inpainting. 2024. 2, 3, 6
2024
-
[49]
Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3661–3670, 2021. 2, 6
2021
-
[50]
Hearing lips: Improving lip reading by dis- tilling speech recognizers
Ya Zhao, Rui Xu, Xinchao Wang, Peng Hou, Haihong Tang, and Mingli Song. Hearing lips: Improving lip reading by dis- tilling speech recognizers. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 6917–6924, 2020. 3
2020
-
[51]
Makelttalk: speaker-aware talking-head animation.ACM Transactions On Graphics (TOG), 39(6):1–15, 2020
Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevar- ria, Evangelos Kalogerakis, and Dingzeyu Li. Makelttalk: speaker-aware talking-head animation.ACM Transactions On Graphics (TOG), 39(6):1–15, 2020. 1, 2, 6
2020
-
[52]
Celebv- hq: A large-scale video facial attributes dataset
Hao Zhu, Wayne Wu, Wentao Zhu, Liming Jiang, Siwei Tang, Li Zhang, Ziwei Liu, and Chen Change Loy. Celebv- hq: A large-scale video facial attributes dataset. InEuropean conference on computer vision, pages 650–667. Springer,
-
[53]
2 IP-Adapter Is All You Need: Towards Fine-Tuning-Free Diffusion-Based Talking Face Generation Supplementary Material
-
[54]
All derivations and intermediate steps are included to ensure completeness and clarity
The proof of Theorem 1 This section provides a detailed proof of Theorem 1, aim- ing to rigorously justify the theoretical claims presented in the main paper. All derivations and intermediate steps are included to ensure completeness and clarity. Taking thex-direction component of the random vari- ableV ij as an example, we define it as a new random vari-...
-
[55]
AnimateDiff + IP-Adapter
Discussion In this section, we discuss several key aspects of our work. We first explore the controllability of mouth expressions under few-shot settings, then examine the potential devel- opment of AnimateDiff and IP-Adapter communities as a backbone for fine-tuning-free talking face generation, and finally analyze the effectiveness of pretrained Control...
-
[56]
To mitigate such risks, all generated videos in our study can be clearly marked as synthetic (Fig
Ethical considerations we recognize that realistic talking face generation may raise ethical concerns regarding potential misuse, such as creat- ing deceptive or malicious deepfake content. To mitigate such risks, all generated videos in our study can be clearly marked as synthetic (Fig. 3), ensuring transparent presenta- tion of results. We strongly advo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.