VPG: Visual Prefix Guidance for Autoregressive Image and Video Generation
Pith reviewed 2026-06-29 07:57 UTC · model grok-4.3
The pith
Visual Prefix Guidance improves autoregressive image and video generation by steering next predictions toward stronger support for the generated prefix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
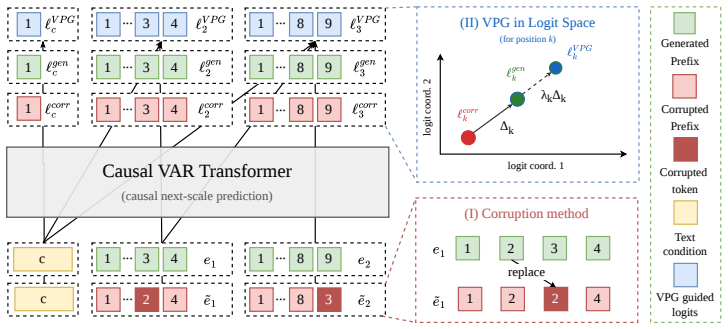
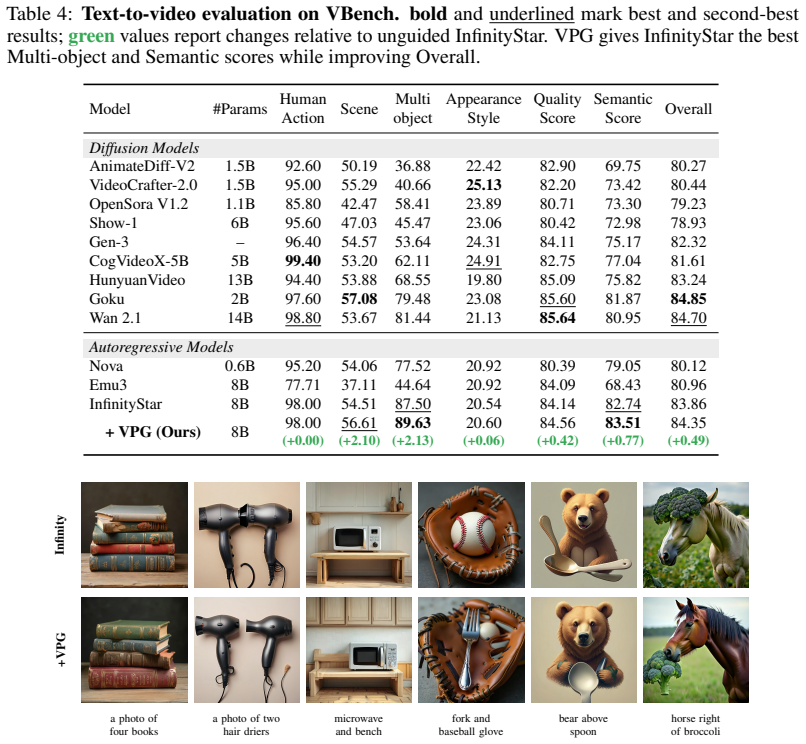
VPG improves next-step prediction by contrasting the model's output under the generated prefix with its output under a corrupted prefix, then extrapolating logits toward candidates that strengthen the posterior support of the generated prefix. Across class-conditional image generation with VAR, text-to-image generation with Infinity, and text-to-video generation with InfinityStar, VPG improves generation quality without retraining the base model, reducing FID on VAR by 0.36 on average and improving benchmark performance on both image and video generation.
What carries the argument
Visual Prefix Guidance (VPG), which contrasts model outputs on the generated prefix versus a corrupted prefix and extrapolates logits to favor stronger posterior support for the prefix.
If this is right
- Reduces average FID by 0.36 on class-conditional image generation using the VAR model.
- Raises benchmark scores for text-to-image generation using the Infinity model.
- Raises benchmark scores for text-to-video generation using the InfinityStar model.
- Delivers these gains at inference time without any modification to the base model's training.
- Targets internal prefix consistency rather than external conditioning signals such as class labels or text prompts.
Where Pith is reading between the lines
- The same contrast-and-extrapolate pattern could be tested on autoregressive models for other sequential data such as audio waveforms.
- VPG might be stacked with existing classifier-free guidance or classifier guidance to obtain combined effects.
- If the corrupted-prefix construction proves robust, it could serve as a general template for self-consistency checks in other sampling-time correction methods.
Load-bearing premise
Contrasting the model's outputs under the generated prefix versus a corrupted prefix reliably identifies and strengthens predictions that genuinely support the prefix rather than introducing new artifacts.
What would settle it
Running the same generation benchmarks with and without VPG and finding that FID scores and other quality metrics show no improvement or become worse when VPG is applied.
Figures













read the original abstract
Autoregressive image and video generators are trained with teacher-forced histories but must sample from their own generated prefixes at inference time, making them vulnerable to exposure bias and prefix drift. Existing remedies either modify training or apply sampling-time guidance aimed primarily at external semantic conditions, such as class labels or text prompts, rather than testing whether a next-step prediction provides strong posterior support for the generated prefix itself. We propose Visual Prefix Guidance (VPG), a training-free inference-time guidance method for autoregressive image and video generation. VPG improves next-step prediction by contrasting the model's output under the generated prefix with its output under a corrupted prefix, then extrapolating logits toward candidates that strengthen the posterior support of the generated prefix. Across class-conditional image generation with VAR, text-to-image generation with Infinity, and text-to-video generation with InfinityStar, VPG improves generation quality without retraining the base model, reducing FID on VAR by 0.36 on average and improving benchmark performance on both image and video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Visual Prefix Guidance (VPG), a training-free inference-time method for autoregressive image and video generators. VPG contrasts the model's output logits under the generated prefix with those under a corrupted prefix to identify and amplify next-token predictions that increase the posterior probability of the generated prefix, thereby reducing exposure bias. The method is evaluated on class-conditional image generation using VAR, text-to-image using Infinity, and text-to-video using InfinityStar, reporting an average FID reduction of 0.36 on VAR and improved benchmark performance without retraining the base models.
Significance. If the reported improvements are shown to be robust, VPG offers a practical contribution by providing a model-agnostic, training-free approach to mitigating exposure bias and prefix drift specifically in autoregressive vision models. The focus on internal prefix support rather than external conditions, combined with applicability across multiple base models, strengthens its potential utility.
major comments (2)
- [§3] The central mechanism relies on the contrast between generated and corrupted prefixes to identify genuine posterior support, but the manuscript provides insufficient detail on the corruption procedure (e.g., masking ratio, noise schedule, or selection of corrupted tokens) in the method section; this is load-bearing because an arbitrary corruption could introduce biases rather than isolate prefix support, undermining the claim that the extrapolation strengthens the true posterior.
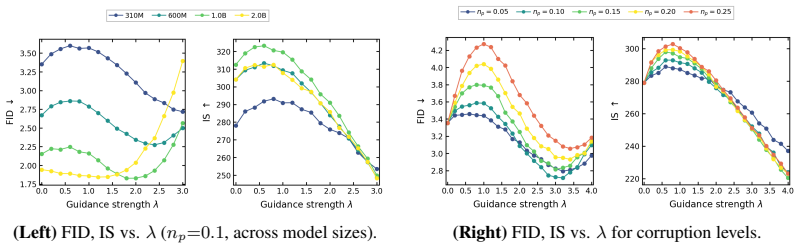
- [Table 1, §4.2] Table 1 and §4.2 report an average FID reduction of 0.36 on VAR without accompanying standard deviations across multiple runs, ablation on the guidance scale, or comparison to simple baselines such as temperature scaling; this weakens the ability to attribute gains specifically to the prefix-contrast mechanism rather than generic logit adjustment.
minor comments (1)
- The abstract states quantitative gains but the main text should include a dedicated limitations paragraph discussing potential failure modes when the corrupted prefix contrast fails to correlate with true posterior support.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3] The central mechanism relies on the contrast between generated and corrupted prefixes to identify genuine posterior support, but the manuscript provides insufficient detail on the corruption procedure (e.g., masking ratio, noise schedule, or selection of corrupted tokens) in the method section; this is load-bearing because an arbitrary corruption could introduce biases rather than isolate prefix support, undermining the claim that the extrapolation strengthens the true posterior.
Authors: We agree that explicit details on the corruption procedure are necessary for reproducibility and to substantiate the mechanism. Section 3 describes random token masking to create the corrupted prefix, but we acknowledge that the specific masking ratio and selection process were not stated with sufficient precision. In the revised manuscript we will expand §3 to specify a fixed masking ratio of 0.5 applied to randomly selected tokens with no additional noise schedule, thereby clarifying that the corruption is a controlled disruption of prefix support rather than an arbitrary modification. revision: yes
-
Referee: [Table 1, §4.2] Table 1 and §4.2 report an average FID reduction of 0.36 on VAR without accompanying standard deviations across multiple runs, ablation on the guidance scale, or comparison to simple baselines such as temperature scaling; this weakens the ability to attribute gains specifically to the prefix-contrast mechanism rather than generic logit adjustment.
Authors: We acknowledge that standard deviations, guidance-scale ablations, and baseline comparisons would strengthen attribution of gains to the prefix-contrast mechanism. Due to computational constraints we are unable to provide standard deviations from multiple independent runs. However, we will add an ablation on the guidance scale and a direct comparison against temperature scaling in the revised §4.2 and Table 1 to better isolate the contribution of VPG from generic logit adjustments. revision: partial
- Reporting standard deviations across multiple independent runs due to computational resource limitations.
Circularity Check
No significant circularity identified
full rationale
The paper presents VPG as a training-free inference-time method that contrasts model outputs on generated vs. corrupted prefixes to guide next-token logits toward stronger posterior support. No equations, fitted parameters, or self-citations are described in the provided abstract or mechanism that reduce the claimed FID improvements or guidance effect to a quantity defined by construction from the inputs themselves. The central claim rests on an empirical contrast-and-extrapolation procedure whose value is demonstrated by reported quality gains on external benchmarks (VAR, Infinity, InfinityStar), with no load-bearing step that renames a fit as a prediction or imports uniqueness via author self-citation. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Self-rectifying diffusion sampling with perturbed-attention guidance
Donghoon Ahn, Hyoungwon Cho, Jaewon Min, Wooseok Jang, Jungwoo Kim, SeonHwa Kim, Hyun Hee Park, Kyong Hwan Jin, and Seungryong Kim. Self-rectifying diffusion sampling with perturbed-attention guidance. InEuropean Conference on Computer Vision, pages 1–17. Springer, 2024
2024
-
[3]
Kushal Arora, Layla El Asri, Hareesh Bahuleyan, and Jackie Cheung. Why exposure bias matters: An imitation learning perspective of error accumulation in language generation. InFindings of the Association for Computational Linguistics: ACL 2022, pages 700–710, 2022. doi: 10.18653/v1/2022.findings-acl.58. URLhttps://aclanthology.org/2022.findings-acl.58/
-
[4]
Scheduled sampling for sequence prediction with recurrent neural networks.Advances in Neural Information Processing Systems, 28, 2015
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[5]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020
2020
-
[6]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[8]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[9]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[10]
Deep autoregressive networks
Karol Gregor, Ivo Danihelka, Andriy Mnih, Charles Blundell, and Daan Wierstra. Deep autoregressive networks. InInternational Conference on Machine Learning, pages 1242–1250. PMLR, 2014
2014
-
[11]
Suboptimal behavior of bayes and mdl in classification under misspecification.Machine Learning, 66(2):119–149, 2007
Peter Grünwald and John Langford. Suboptimal behavior of bayes and mdl in classification under misspecification.Machine Learning, 66(2):119–149, 2007
2007
-
[12]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15733–15744, June 2025
2025
-
[13]
Conceptrol: Concept control of zero-shot personalized image generation
Qiyuan He and Angela Yao. Conceptrol: Concept control of zero-shot personalized image generation. arXiv preprint arXiv:2503.06568, 2025
-
[14]
Aid: Attention interpolation of text-to-image diffusion.arXiv preprint arXiv:2403.17924, 2024
Qiyuan He, Jinghao Wang, Ziwei Liu, and Angela Yao. Aid: Attention interpolation of text-to-image diffusion.arXiv preprint arXiv:2403.17924, 2024
-
[15]
Qiyuan He, Yicong Li, Haotian Ye, Jinghao Wang, Xinyao Liao, Pheng-Ann Heng, Stefano Ermon, James Zou, and Angela Yao. REAR: Rethinking visual autoregressive models via generator-tokenizer consistency regularization.arXiv preprint arXiv:2510.04450, 2025
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention.Advances in Neural Information Processing Systems, 37:66743–66772, 2024
Susung Hong. Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention.Advances in Neural Information Processing Systems, 37:66743–66772, 2024
2024
-
[18]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion, 2025. URLhttps://arxiv.org/abs/2506.08009. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
2024
-
[21]
Guiding a diffusion model with a bad version of itself
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[22]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models, 2024. URLhttps://arxiv.org/abs/2412.03603
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[24]
Lamb, Anirudh Goyal, Ying Zhang, Saizheng Zhang, Aaron C
Alex M. Lamb, Anirudh Goyal, Ying Zhang, Saizheng Zhang, Aaron C. Courville, and Yoshua Bengio. Professor forcing: A new algorithm for training recurrent networks. InAdvances in Neural Information Processing Systems, volume 29, 2016
2016
-
[25]
Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024
2024
-
[26]
Xinyao Liao, Qiyuan He, Kai Xu, Xiaoye Qu, Yicong Li, Wei Wei, and Angela Yao. V A-π: Variational policy alignment for pixel-aware autoregressive generation.arXiv preprint arXiv:2512.19680, 2025
-
[27]
Xinyao Liao, Wei Wei, Xiaoye Qu, and Yu Cheng. Step-level reward for free in rl-based t2i diffusion model fine-tuning.arXiv preprint arXiv:2505.19196, 2025
-
[28]
Infinitystar: Unified spacetime autoregressive modeling for visual generation
Jinlai Liu, Jian Han, Bin Yan, Hui Wu, Fengda Zhu, Xing Wang, Yi Jiang, Bingyue Peng, and Zehuan Yuan. Infinitystar: Unified spacetime autoregressive modeling for visual generation, 2025. URL https: //arxiv.org/abs/2511.04675
-
[29]
Interp3d: Correspondence-aware interpolation for generative textured 3d morphing
Xiaolu Liu, Yicong Li, Qiyuan He, Jiayin Zhu, Wei Ji, Angela Yao, and Jianke Zhu. Interp3d: Correspondence-aware interpolation for generative textured 3d morphing. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026. URL https://openreview.net/forum?id= au6cziMtGM
2026
-
[30]
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, and Xiaojuan Qi. Unitok: A unified tokenizer for visual generation and understanding.arXiv preprint arXiv:2502.20321, 2025
-
[31]
Finite Scalar Quantization: VQ-VAE Made Simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Image transformer
Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. InInternational conference on machine learning, pages 4055–4064. PMLR, 2018
2018
-
[33]
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, and Liang-Chieh Chen. Beyond next-token: Next-x prediction for autoregressive visual generation.arXiv preprint arXiv:2502.20388, 2025
-
[34]
A reduction of imitation learning and structured prediction to no-regret online learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 627–635, 2011. URLhttps://proceedings.mlr.press/v15/ross11a.html
2011
-
[35]
Generalization in generation: A closer look at exposure bias
Florian Schmidt. Generalization in generation: A closer look at exposure bias. InProceedings of the 3rd Workshop on Neural Generation and Translation, pages 157–167, 2019. doi: 10.18653/v1/D19-5616. URLhttps://aclanthology.org/D19-5616/
-
[36]
SSG: Scaled spatial guidance for multi-scale visual autoregressive generation
Youngwoo Shin, Jiwan Hur, and Junmo Kim. SSG: Scaled spatial guidance for multi-scale visual autoregressive generation. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=S6oLw7VixT
2026
-
[37]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autore- gressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
2024
-
[41]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[42]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Chaojun Wang and Rico Sennrich. On exposure bias, hallucination and domain shift in neural machine translation.arXiv preprint arXiv:2005.03642, 2020
-
[44]
Blaschko
Dongli Xu, Aleksei Tiulpin, and Matthew B. Blaschko. SoftCFG: Uncertainty-guided stable guidance for visual autoregressive model. InThe Fourteenth International Conference on Learning Representations,
-
[45]
URLhttps://openreview.net/forum?id=G7tqQ5Upcs
-
[46]
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Haotian Ye, Qiyuan He, Jiaqi Han, Puheng Li, Jiaojiao Fan, Zekun Hao, Fitsum Reda, Yogesh Balaji, Huayu Chen, Sheng Liu, et al. Infotok: Adaptive discrete video tokenizer via information-theoretic compression.arXiv preprint arXiv:2512.16975, 2025
-
[47]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, et al. Language model beats diffusion–tokenizer is key to visual generation.arXiv preprint arXiv:2310.05737, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
An image is worth 32 tokens for reconstruction and generation.Advances in Neural Information Processing Systems, 37:128940–128966, 2024
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An image is worth 32 tokens for reconstruction and generation.Advances in Neural Information Processing Systems, 37:128940–128966, 2024
2024
-
[49]
Guiding a Diffusion Model by Swapping Its Tokens
Weijia Zhang, Yuehao Liu, Shanyan Guan, Wu Ran, Yanhao Ge, Wei Li, and Chao Ma. Guiding a diffusion model by swapping its tokens, 2026. URLhttps://arxiv.org/abs/2604.08048
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Bridging the gap between training and inference for neural machine translation
Wen Zhang, Yang Feng, Fandong Meng, Di You, and Qun Liu. Bridging the gap between training and inference for neural machine translation. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4334–4343, 2019. doi: 10.18653/v1/P19-1426. URL https: //aclanthology.org/P19-1426/
-
[51]
Image and video tokenization with binary spherical quantization, 2024
Yue Zhao, Yuanjun Xiong, and Philipp Krähenbühl. Image and video tokenization with binary spherical quantization, 2024. URLhttps://arxiv.org/abs/2406.07548
-
[52]
RelaxFlow: Text-Driven Amodal 3D Generation
Jiayin Zhu, Guoji Fu, Xiaolu Liu, Qiyuan He, Yicong Li, and Angela Yao. Relaxflow: Text-driven amodal 3d generation, 2026. URLhttps://arxiv.org/abs/2603.05425. 12 A Theoretical derivations This section gives the full compatibility-augmentation derivations for CFG (Sec. 3.2) and VPG (Sec. 4.1) in next-scale visual autoregression. Both methods are obtained ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.