Tiny but Trusted: Efficient Vision-Language Reasoning for Time-Series Anomaly Detection
Pith reviewed 2026-06-29 06:54 UTC · model grok-4.3
The pith
A compact vision-language model fine-tuned on a benchmark of reward-selected anomaly explanations outperforms larger baselines in time-series detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
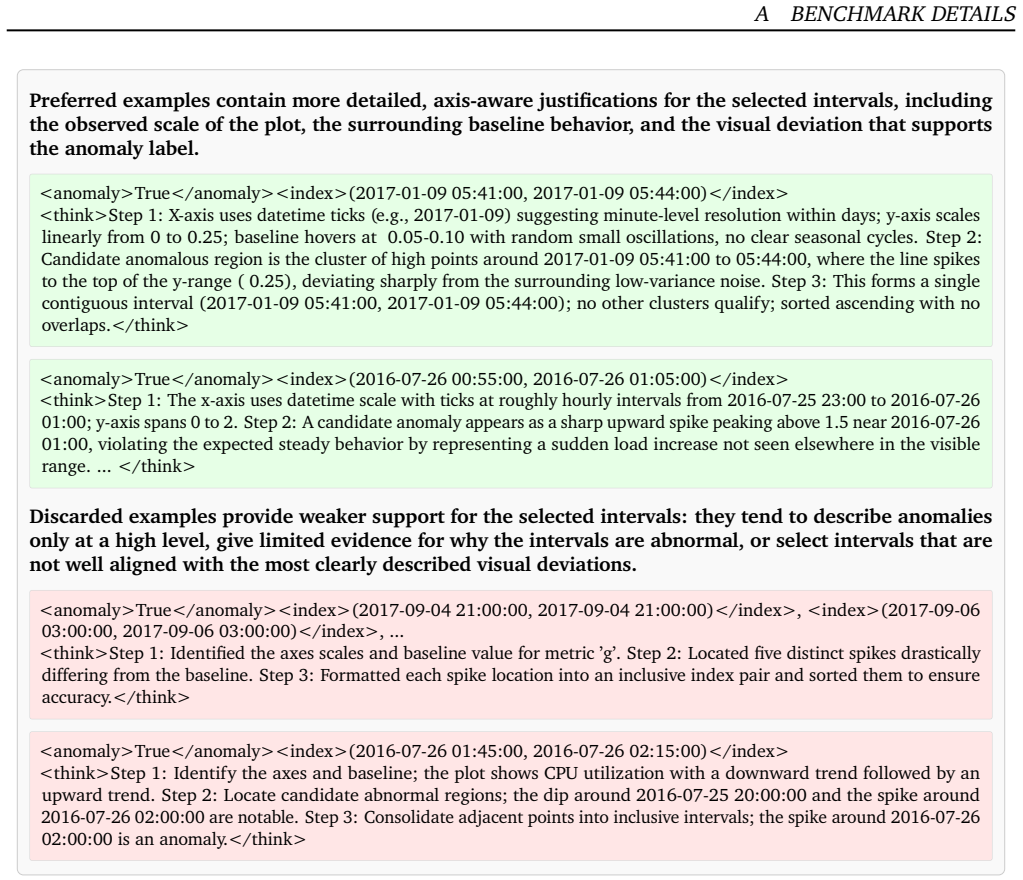
By constructing VisAnomBench with high-quality anomaly explanations selected from large VLMs using fine-grained task-specific rewards and fine-tuning VisAnomReasoner on this benchmark, the model achieves more accurate anomaly localization and consistently outperforms all baselines, with improvements of at least 21.23 and 23.87 percentage points in precision and F1 on VisAnomBench as well as 9.57 and 13.39 points on TSB-AD-U.
What carries the argument
VisAnomBench, the time-series benchmark augmented with reward-selected natural-language anomaly explanations from large VLMs, which enables the parameter-efficient fine-tuning of VisAnomReasoner to produce grounded detections.
If this is right
- VisAnomReasoner achieves more accurate anomaly localization than prior approaches on the benchmark.
- The model improves precision by at least 21.23 percentage points over all baselines on VisAnomBench.
- The model improves F1 by at least 23.87 percentage points over all baselines on VisAnomBench.
- VisAnomReasoner shows cross-benchmark generalization with precision and F1 gains of 9.57 and 13.39 points on TSB-AD-U.
- Parameter-efficient vision-language models can deliver interpretable time-series anomaly decisions after training on explanation-augmented data.
Where Pith is reading between the lines
- Reward-based selection of explanations from large models could be applied to create training data for other sequential tasks such as forecasting or classification.
- Deployments with limited compute resources could use small fine-tuned models for anomaly detection while retaining most of the accuracy of much larger systems.
- Expanding the approach to additional public time-series collections might produce a family of benchmarks that support explainable detection across domains.
Load-bearing premise
The anomaly explanations chosen from large models via rewards are accurate enough and causally useful enough to improve a smaller model's detection performance.
What would settle it
Reproducing the benchmark construction and fine-tuning steps then observing no improvement larger than a few percentage points in precision or F1 over the strongest baseline on VisAnomBench would falsify the performance claim.
Figures







read the original abstract
Recent advances in Vision-Language Models (VLMs) have achieved impressive performance across many tasks, yet prior studies report unsatisfactory performance when applying large language or multimodal models to finding abnormal patterns in sequential data. Public anomaly detection benchmarks typically provide interval annotations but not natural-language rationales, making it difficult to fine-tune VLMs to produce grounded, interpretable decisions. To address this gap, we construct VisAnomBench, a curated benchmark built from public time-series datasets and augmented with high-quality anomaly explanations selected from multiple large VLMs using fine-grained, task-specific rewards. Through fine-tuning on this benchmark, we develop VisAnomReasoner, a parameter-efficient VLM for time-series anomaly detection. Experimental results on VisAnomBench show that VisAnomReasoner achieves more accurate anomaly localization and consistently outperforms all baselines, with improvements of at least 21.23 and 23.87 percentage points in precision and F1, respectively. Additional experiments on the TSB-AD-U benchmark demonstrate strong cross-benchmark generalization, with VisAnomReasoner improving precision and F1 by 9.57 and 13.39 percentage points, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs VisAnomBench by augmenting public time-series anomaly datasets with natural-language explanations generated by multiple large VLMs and filtered via fine-grained task-specific rewards. It then fine-tunes a parameter-efficient VLM (VisAnomReasoner) on this benchmark and reports that the resulting model achieves at least 21.23 and 23.87 percentage-point gains in precision and F1 over baselines on VisAnomBench, plus 9.57 and 13.39 points on the external TSB-AD-U benchmark, with improved anomaly localization.
Significance. If the explanations prove accurate and the gains are shown to be causally due to improved reasoning rather than artifacts of dataset curation or fine-tuning, the work would offer a practical route to interpretable, parameter-efficient VLM-based time-series anomaly detection. The use of public datasets for benchmark construction and the emphasis on cross-benchmark generalization are positive features that reduce circularity risks.
major comments (2)
- [Abstract] Abstract: The central claim that VisAnomReasoner 'achieves more accurate anomaly localization' and the reported 21+ point gains rest on the premise that the reward-selected explanations are accurate, unbiased, and causally responsible for the improvements, yet the manuscript supplies no human validation, inter-annotator agreement scores, or ablation that isolates the explanations' contribution from other factors such as the fine-tuning procedure itself.
- [Abstract] Abstract: No definitions are given for the baselines, no statistical significance tests are described, and the design of the 'fine-grained, task-specific rewards' used to select explanations is not specified, rendering the numeric performance claims impossible to evaluate from the provided information.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that VisAnomReasoner 'achieves more accurate anomaly localization' and the reported 21+ point gains rest on the premise that the reward-selected explanations are accurate, unbiased, and causally responsible for the improvements, yet the manuscript supplies no human validation, inter-annotator agreement scores, or ablation that isolates the explanations' contribution from other factors such as the fine-tuning procedure itself.
Authors: We agree that human validation would provide stronger support for the quality and lack of bias in the reward-selected explanations. The current approach relies on multi-VLM generation followed by fine-grained task-specific reward filtering, but we will add a human evaluation on a representative subset of explanations (including inter-annotator agreement) and an ablation comparing models trained with versus without the reward filtering step. These additions will be included in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: No definitions are given for the baselines, no statistical significance tests are described, and the design of the 'fine-grained, task-specific rewards' used to select explanations is not specified, rendering the numeric performance claims impossible to evaluate from the provided information.
Authors: We acknowledge that the abstract omits explicit definitions and that the reward design requires clearer exposition for standalone evaluation. The full manuscript defines baselines in Section 4, details the reward functions in Section 3.3, and reports results with standard deviations; however, we will expand the abstract with concise baseline and reward definitions, add paired statistical significance tests to the experimental tables, and ensure the reward design is summarized in the abstract or a methods footnote in the revision. revision: yes
Circularity Check
No significant circularity; empirical pipeline is self-contained against external benchmarks
full rationale
The paper constructs VisAnomBench from public time-series datasets, augments it with explanations selected from multiple large VLMs via task-specific rewards, fine-tunes a parameter-efficient VLM (VisAnomReasoner) on the resulting data, and reports empirical gains on VisAnomBench plus cross-benchmark generalization on the independent TSB-AD-U benchmark. No equations, fitted parameters renamed as predictions, self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text. The central performance claims (21+ point gains in precision/F1) are presented as direct experimental outcomes rather than derivations that reduce to the benchmark-construction inputs by definition. The reader's assessment of score 1.0 is consistent with this analysis; any concerns about explanation accuracy fall under assumption validity, not circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Outlier ensembles
Charu C Aggarwal. Outlier ensembles. In Outlier Analysis, pages 185--218. Springer, 2016
2016
-
[2]
Chronos: Learning the language of time series
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series. Transactions on Machine Learning Research (TMLR), 2024
2024
-
[3]
Wearable assistant for parkinson’s disease patients with the freezing of gait symptom
Marc Bachlin, Meir Plotnik, Daniel Roggen, Inbal Maidan, Jeffrey M Hausdorff, Nir Giladi, and Gerhard Troster. Wearable assistant for parkinson’s disease patients with the freezing of gait symptom. IEEE Transactions on Information Technology in Biomedicine, 14 0 (2): 0 436--446, 2009
2009
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Desai, James L
Sriram Baireddy, Sundip R. Desai, James L. Mathieson, Richard H. Foster, Moses W. Chan, Mary L. Comer, and Edward J. Delp. Spacecraft time-series anomaly detection using transfer learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1951--1960, June 2021
1951
-
[6]
A review on outlier/anomaly detection in time series data
Ane Bl\' a zquez-Garc\' a, Angel Conde, Usue Mori, and Jose A Lozano. A review on outlier/anomaly detection in time series data. ACM Computing Surveys (CSUR), 54 0 (3): 0 1--33, 2021. doi:10.1145/3444690
-
[7]
SAND : Streaming subsequence anomaly detection
Paul Boniol, John Paparrizos, Themis Palpanas, and Michael J Franklin. SAND : Streaming subsequence anomaly detection. Proceedings of the VLDB Endowment, 14 0 (10): 0 1717--1729, 2021
2021
-
[8]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. In International Conference on Machine Learning (ICML), 2024
2024
-
[9]
Ensemble grammar induction for detecting anomalies in time series
Yifeng Gao, Jessica Lin, and Constantin Brif. Ensemble grammar induction for detecting anomalies in time series. In International Conference on Extending Database Technology (EDBT), pages 85--96. OpenProceedings.org, 2020. doi:10.5441/002/edbt.2020.09
-
[10]
Temporal signals to images: Monitoring the condition of industrial assets with deep learning image processing algorithms
Gabriel Rodriguez Garcia, Gabriel Michau, M \'e lanie Ducoffe, Jayant Sen Gupta, and Olga Fink. Temporal signals to images: Monitoring the condition of industrial assets with deep learning image processing algorithms. The Institution of Mechanical Engineers, Part O: Journal of Risk and Reliability, 236 0 (4): 0 617--627, 2022
2022
-
[11]
An evaluation of anomaly detection and diagnosis in multivariate time series
Astha Garg, Wenyu Zhang, Jules Samaran, Ramasamy Savitha, and Chuan-Sheng Foo. An evaluation of anomaly detection and diagnosis in multivariate time series. IEEE Transactions on Neural Networks and Learning Systems, 33 0 (6): 0 2508--2517, 2021. doi:https://doi.org/10.48550/arXiv.2109.11428
-
[12]
Gemma Team . Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Large language models are zero-shot time series forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. Large language models are zero-shot time series forecasters. Advances in Neural Information Processing Systems (NeurIPS), 36: 0 19622--19635, 2023
2023
-
[14]
Harnessing vision-language models for time series anomaly detection
Zelin He, Sarah Alnegheimish, and Matthew Reimherr. Harnessing vision-language models for time series anomaly detection. AAAI Conference on Artificial Intelligence (AAAI), 2025
2025
-
[15]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. International Conference on Learning Representations (ICLR), 2022
2022
-
[16]
EvoChart : A benchmark and a self-training approach towards real-world chart understanding
Muye Huang, Han Lai, Xinyu Zhang, Wenjun Wu, Jie Ma, Lingling Zhang, and Jun Liu. EvoChart : A benchmark and a self-training approach towards real-world chart understanding. In AAAI Conference on Artificial Intelligence (AAAI), volume 39, pages 3680--3688, 2025
2025
-
[17]
Local evaluation of time series anomaly detection algorithms
Alexis Huet, Jose Manuel Navarro, and Dario Rossi. Local evaluation of time series anomaly detection algorithms. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 635--645, 2022
2022
-
[18]
Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding
Kyle Hundman, Valentino Constantinou, Christopher Laporte, Ian Colwell, and Tom Soderstrom. Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 387--395, 2018
2018
-
[19]
Finding the most unusual time series subsequence: algorithms and applications
Eamonn Keogh, Jessica Lin, Sang-Hee Lee, and Helga Van Herle. Finding the most unusual time series subsequence: algorithms and applications. Knowledge and Information Systems, 11 0 (1): 0 1--27, 2007
2007
-
[20]
An image grid can be worth a video: Zero-shot video question answering using a VLM
Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. An image grid can be worth a video: Zero-shot video question answering using a VLM . IEEE Access, 12: 0 193057--193075, 2024. doi:10.1109/ACCESS.2024.3517625
-
[21]
Time-MQA : Time series multi-task question answering with context enhancement
Yaxuan Kong, Yiyuan Yang, Yoontae Hwang, Wenjie Du, Stefan Zohren, Zhangyang Wang, Ming Jin, and Qingsong Wen. Time-MQA : Time series multi-task question answering with context enhancement. Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[22]
Revisiting time series outlier detection: Definitions and benchmarks
Kwei-Herng Lai, Daochen Zha, Junjie Xu, Yue Zhao, Guanchu Wang, and Xia Hu. Revisiting time series outlier detection: Definitions and benchmarks. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[23]
Axis: Explainable time series anomaly detection with large language models
Tian Lan, Hao Duong Le, Jinbo Li, Wenjun He, Meng Wang, Chenghao Liu, and Chen Zhang. Axis: Explainable time series anomaly detection with large language models. arXiv preprint arXiv:2509.24378, 2025
-
[24]
S5: A Labeled Anomaly Detection Dataset
Nikolay Laptev, Saeed Amizadeh, and Ian Billawala. S5: A Labeled Anomaly Detection Dataset . Version 1.0, March 2015
2015
-
[25]
Building and better understanding vision-language models: insights and future directions
Hugo Lauren c on, Andr \'e s Marafioti, Victor Sanh, and Leo Tronchon. Building and better understanding vision-language models: insights and future directions. In Workshop on Responsibly Building the Next Generation of Multimodal Foundational Models, 2024
2024
-
[26]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models . In International Conference on Machine Learning (ICML), pages 19730--19742 . Proceedings of Machine Learning Research (PMLR), 2023
2023
-
[27]
Robotic visual instruction
Yanbang Li, Ziyang Gong, Haoyang Li, Xiaoqi Huang, Haolan Kang, Guangping Bai, and Xianzheng Ma. Robotic visual instruction. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12155--12165, 2025
2025
-
[28]
Matrix profile goes MAD : variable-length motif and discord discovery in data series
Michele Linardi, Yan Zhu, Themis Palpanas, and Eamonn Keogh. Matrix profile goes MAD : variable-length motif and discord discovery in data series. Data Mining and Knowledge Discovery, 34 0 (4): 0 1022--1071, 2020
2020
-
[29]
Isolation forest
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In IEEE International Conference on Data Mining, pages 413--422, 2008
2008
-
[30]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in Neural Information Processing Systems (NeurIPS), 36: 0 34892--34916, 2023
2023
-
[31]
Large language models can deliver accurate and interpretable time series anomaly detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. Large language models can deliver accurate and interpretable time series anomaly detection. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4623--4634, 2025
2025
-
[32]
The elephant in the room: Towards a reliable time-series anomaly detection benchmark
Qinghua Liu and John Paparrizos. The elephant in the room: Towards a reliable time-series anomaly detection benchmark. Advances in Neural Information Processing Systems (NeurIPS), 37: 0 108231--108261, 2024
2024
-
[33]
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Yucong Luo, Yitong Zhou, Mingyue Cheng, Jiahao Wang, Daoyu Wang, Tingyue Pan, and Jintao Zhang. Time series forecasting as reasoning: A slow-thinking approach with reinforced LLMs . arXiv preprint arXiv:2506.10630, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
SmolVLM : Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. SmolVLM : Redefining small and efficient multimodal models. Second Conference on Language Model...
2025
-
[35]
LLaMA 4: Open foundation and fine-tuned chat models
Meta AI . LLaMA 4: Open foundation and fine-tuned chat models. https://ai.meta.com/llama, 2025
2025
-
[36]
Pacific Marine Environmental Laboratory Tropical Atmosphere Ocean (TAO) Project
NOAA . Pacific Marine Environmental Laboratory Tropical Atmosphere Ocean (TAO) Project . https://www.pmel.noaa.gov, 2025
2025
-
[37]
TSB-UAD : an end-to-end benchmark suite for univariate time-series anomaly detection
John Paparrizos, Yuhao Kang, Paul Boniol, Ruey S Tsay, Themis Palpanas, and Michael J Franklin. TSB-UAD : an end-to-end benchmark suite for univariate time-series anomaly detection. Proceedings of the VLDB Endowment, 15 0 (8): 0 1697--1711, 2022
2022
-
[38]
Delving into large language models for effective time-series anomaly detection
Junwoo Park, Kyudan Jung, Dohyun Lee, Hyuck Lee, Daehoon Gwak, ChaeHun Park, Jaegul Choo, and Jaewoong Cho. Delving into large language models for effective time-series anomaly detection. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[39]
LERa : Replanning with visual feedback in instruction following
Svyatoslav Pchelintsev, Maxim Patratskiy, Anatoly Onishchenko, Alexandr Korchemnyi, Aleksandr Medvedev, Uliana Vinogradova, Ilya Galuzinsky, Aleksey Postnikov, Alexey K Kovalev, and Aleksandr I Panov. LERa : Replanning with visual feedback in instruction following. In International Conference on Intelligent Robots and Systems (IROS), pages 19218--19225, 2025
2025
-
[40]
Anomaly detection using autoencoders with nonlinear dimensionality reduction
Mayu Sakurada and Takehisa Yairi. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In The MLSDA Workshop on Machine Learning for Sensory Data Analysis, pages 4--11, 2014
2014
-
[41]
Anomaly detection in time series: A comprehensive evaluation
Sebastian Schmidl, Phillip Wenig, and Thorsten Papenbrock. Anomaly detection in time series: A comprehensive evaluation. Proceedings of the VLDB Endowment, 15 0 (9): 0 1779--1797, 2022. doi:10.14778/3538598.3538602
-
[42]
A systematic literature review of IoT time series anomaly detection solutions
Arnaldo Sgueglia, Andrea Di Sorbo, Corrado Aaron Visaggio, and Gerardo Canfora. A systematic literature review of IoT time series anomaly detection solutions. Future Generation Computer Systems, 134: 0 170--186, 2022. doi:https://doi.org/10.1016/j.future.2022.04.005
-
[43]
Timeseriesbench: An industrial-grade benchmark for time series anomaly detection models
Haotian Si, Jianhui Li, Changhua Pei, Hang Cui, Jingwen Yang, Yongqian Sun, Shenglin Zhang, Jingjing Li, Haiming Zhang, Jing Han, et al. Timeseriesbench: An industrial-grade benchmark for time series anomaly detection models. In IEEE International Symposium on Software Reliability Engineering (ISSRE), pages 61--72. IEEE, 2024
2024
-
[44]
ChatTime : A unified multimodal time series foundation model bridging numerical and textual data
Chengsen Wang, Qi Qi, Jingyu Wang, Haifeng Sun, Zirui Zhuang, Jinming Wu, Lei Zhang, and Jianxin Liao. ChatTime : A unified multimodal time series foundation model bridging numerical and textual data. In AAAI Conference on Artificial Intelligence (AAAI), volume 39, pages 12694--12702, 2025 a
2025
-
[45]
Can slow-thinking LLMs reason over time? Empirical studies in time series forecasting
Jiahao Wang, Mingyue Cheng, and Qi Liu. Can slow-thinking LLMs reason over time? Empirical studies in time series forecasting. ACM International Conference on Web Search and Data Mining, 2025 b
2025
-
[46]
OFA: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework
Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. OFA: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework . In International Conference on Machine Learning (ICML), pages 23318--23340 , 2022
2022
-
[47]
TimeEval : A benchmarking toolkit for time series anomaly detection algorithms
Phillip Wenig, Sebastian Schmidl, and Thorsten Papenbrock. TimeEval : A benchmarking toolkit for time series anomaly detection algorithms. Proceedings of the VLDB Endowment, 15 0 (12): 0 3678--3681, 2022. doi:10.14778/3554821.3554873
-
[48]
Current time series anomaly detection benchmarks are flawed and are creating the illusion of progress
Renjie Wu and Eamonn J Keogh. Current time series anomaly detection benchmarks are flawed and are creating the illusion of progress. IEEE Transactions on Knowledge and Data Engineering, 35 0 (3): 0 2421--2429, 2021
2021
-
[49]
Grok-4-fast
xAI . Grok-4-fast. https://x.ai, 2024. Large vision--language model
2024
-
[50]
ChatTS : Aligning time series with LLMs via synthetic data for enhanced understanding and reasoning
Zhe Xie, Zeyan Li, Xiao He, Longlong Xu, Xidao Wen, Tieying Zhang, Jianjun Chen, Rui Shi, and Dan Pei. ChatTS : Aligning time series with LLMs via synthetic data for enhanced understanding and reasoning. Proceedings of the VLDB Endowment, 2025
2025
-
[51]
Unsupervised anomaly detection via variational auto-encoder for seasonal KPIs in web applications
Haowen Xu, Wenxiao Chen, Nengwen Zhao, Zeyan Li, Jiahao Bu, Zhihan Li, Ying Liu, Youjian Zhao, Dan Pei, Yang Feng, et al. Unsupervised anomaly detection via variational auto-encoder for seasonal KPIs in web applications. In World Wide Web Conference, pages 187--196, 2018
2018
-
[52]
Anomaly Transformer : Time series anomaly detection with association discrepancy
Jiehui Xu, Haixu Wu, Jianmin Wang, and Mingsheng Long. Anomaly Transformer : Time series anomaly detection with association discrepancy. In International Conference on Learning Representations (ICLR), 2022
2022
-
[53]
Can multimodal LLMs perform time series anomaly detection? the ACM Web Conference, 2026
Xiongxiao Xu, Haoran Wang, Yueqing Liang, Philip S Yu, Yue Zhao, and Kai Shu. Can multimodal LLMs perform time series anomaly detection? the ACM Web Conference, 2026
2026
-
[54]
Deep learning technologies for time series anomaly detection in healthcare: A review
Xue Yang, Xuejun Qi, and Xiaobo Zhou. Deep learning technologies for time series anomaly detection in healthcare: A review. IEEE Access, 2023. doi:10.1109/ACCESS.2023.3325896
-
[55]
Time-RA: Towards Time Series Reasoning for Anomaly Diagnosis with LLM Feedback
Yiyuan Yang, Zichuan Liu, Lei Song, Kai Ying, Zhiguang Wang, Tom Bamford, Svitlana Vyetrenko, Jiang Bian, and Qingsong Wen. Time-RA : Towards time series reasoning for anomaly diagnosis with LLM feedback. arXiv preprint arXiv:2507.15066, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Effective training data synthesis for improving MLLM chart understanding
Yuwei Yang, Zeyu Zhang, Yunzhong Hou, Zhuowan Li, Gaowen Liu, Ali Payani, Yuan-Sen Ting, and Liang Zheng. Effective training data synthesis for improving MLLM chart understanding. In International Conference on Computer Vision (ICCV), pages 2653--2663, 2025
2025
-
[57]
Deep Learning for Time Series Anomaly Detection : A survey
Zahra Zamanzadeh Darban, Geoffrey I Webb, Shirui Pan, Charu Aggarwal, and Mahsa Salehi. Deep Learning for Time Series Anomaly Detection : A survey. ACM Computing Surveys (CSUR), 57 0 (1): 0 1--42, 2024. doi:https://doi.org/10.1145/3691338
-
[58]
TempoGPT : Enhancing time series reasoning via quantizing embedding
Haochuan Zhang, Chunhua Yang, Jie Han, Liyang Qin, and Xiaoli Wang. TempoGPT : Enhancing time series reasoning via quantizing embedding. arXiv preprint arXiv:2501.07335, 2025 a
-
[59]
Timemaster: Training time-series multimodal LLMs to reason via reinforcement learning
Junru Zhang, Lang Feng, Xu Guo, Yuhan Wu, Yabo Dong, and Duanqing Xu. Timemaster: Training time-series multimodal LLMs to reason via reinforcement learning. Advances in Neural Information Processing Systems (NeurIPS), 2025 b
2025
-
[60]
Contextual and seasonal LSTMs for time series anomaly detection
Lingpei Zhang, Qingming Li, Yong Yang, Jiahao Chen, Rui Zeng, Chenyang Lyu, and Shouling Ji. Contextual and seasonal LSTMs for time series anomaly detection. In International Conference on Learning Representations (ICLR), 2026
2026
-
[61]
mTSBench : Benchmarking multivariate time series anomaly detection and model selection at scale
Xiaona Zhou, Constantin Brif, and Ismini Lourentzou. mTSBench : Benchmarking multivariate time series anomaly detection and model selection at scale. Transactions on Machine Learning Research (TMLR), 2026. doi:10.48550/arXiv.2506.21550
-
[62]
Can LLMs understand time series anomalies? In International Conference on Learning Representations (ICLR), 2025
Zihao Zhou and Rose Yu. Can LLMs understand time series anomalies? In International Conference on Learning Representations (ICLR), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.