AdaState: Self-Evolving Anchors for Streaming Video Generation
Pith reviewed 2026-06-29 08:21 UTC · model grok-4.3
The pith
Replacing the static first-frame anchor with a self-evolving hidden state allows autoregressive video models to produce richer motion and natural scene changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
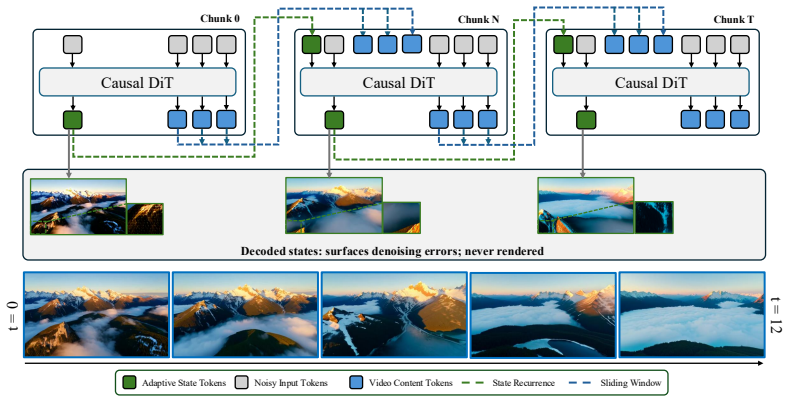
The paper claims that the adaptive state, a hidden latent denoised but never rendered, generates its own scene reference at each chunk by attending to the previous state and current content. Because the formulation makes every generation step see identical relative positional structure, the state transition becomes the same recurrence at every step, carried by the KV cache and trained solely with the standard diffusion objective.
What carries the argument
The adaptive state, a hidden latent that the model denoises alongside visible content but never renders, serving as an evolving scene anchor through recurrence in the KV cache.
If this is right
- Generated videos exhibit richer motion and natural scene progression instead of being locked to the initial viewpoint.
- Every generation step uses the same positional structure, so the state transition remains identical regardless of how far generation has progressed.
- The recurrence is carried entirely by the KV cache and standard diffusion training, requiring no external module.
- Scene references evolve at each step by attending to both the prior state and current content rather than a frozen first frame.
Where Pith is reading between the lines
- The same recurrence pattern could be tested in autoregressive generation of other modalities where a fixed initial token limits later variation.
- Longer sequences might maintain coherence longer if the state continues to evolve without accumulating drift toward the opening frame.
- The approach could be combined with explicit camera or motion controls to see whether the evolving anchor amplifies or interferes with those signals.
Load-bearing premise
The model can learn an effective denoising transition for the hidden state using only the standard diffusion objective and the existing KV cache, without any auxiliary loss or external supervision on the state itself.
What would settle it
Side-by-side generation of the same prompts with and without the adaptive state, scored on motion magnitude and scene-change metrics, would show no measurable increase in dynamics if the central claim is false.
Figures


read the original abstract
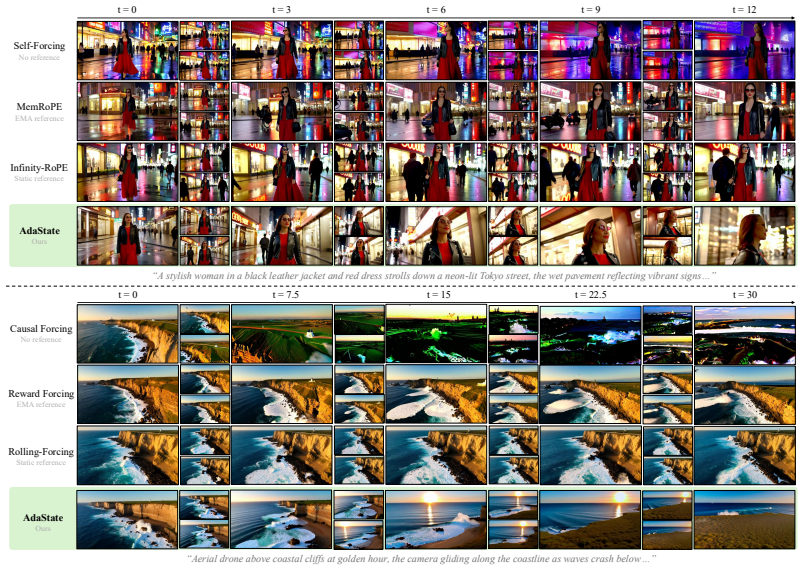
Autoregressive video diffusion models generate streaming video by producing frames sequentially, conditioning each chunk on previously generated content. These models are structurally anchored to the first frame: its key-value representation occupies a privileged position in the attention cache and serves as the primary scene reference throughout generation. As the cleanest and most error-free position in the cache, this anchor draws disproportionate attention, suppressing video dynamics, and locking scene composition to the initial viewpoint even as the scene naturally evolves. The result is a temporally shallow video in which motion, camera movement, and scene progression are dampened in favor of static consistency. To address this, we replace the static anchor with an adaptive state, a hidden latent that the model denoises alongside content at every chunk but never renders. Rather than referencing a frozen first frame, the model generates its own scene anchor at each step by attending to both the previous state and the current content, producing a reference that evolves with the generated content. Unlike standard video generation, which encodes an absolute notion of time, our formulation treats time as relative: every generation step sees the same positional structure regardless of how far generation has progressed, and the state transition is identical at every chunk. Together, these properties introduce a recurrence into the generation process, where denoising serves as the transition function, and the KV cache serves as the carrier, requiring no external module. Experiments demonstrate that the adaptive state substantially improves video dynamics, enabling richer motion and natural scene progression within generated videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaState for autoregressive video diffusion models in streaming generation. It identifies the fixed first-frame KV anchor as causing suppressed dynamics and static scene locking, and replaces it with a hidden adaptive state that is denoised at each chunk (but never rendered) by attending to the prior state and current content inside the existing KV cache. The approach treats time as relative with identical positional structure at every step, turning denoising into a recurrence transition carried by the KV cache without external modules. The abstract asserts that experiments show the adaptive state yields richer motion and natural scene progression.
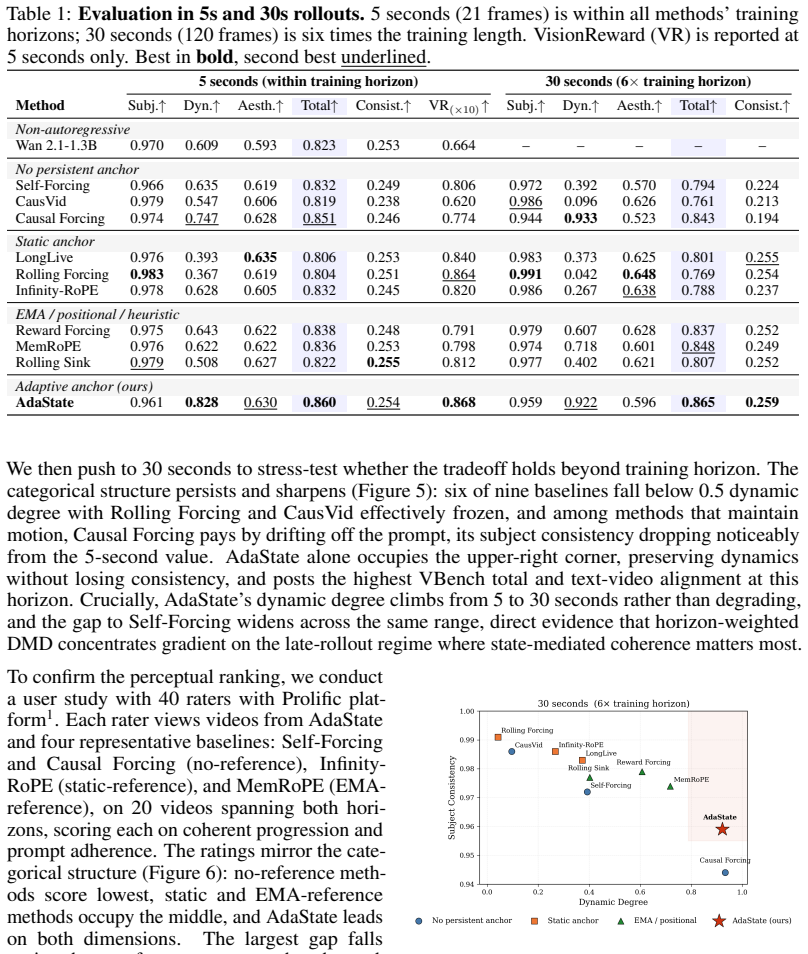
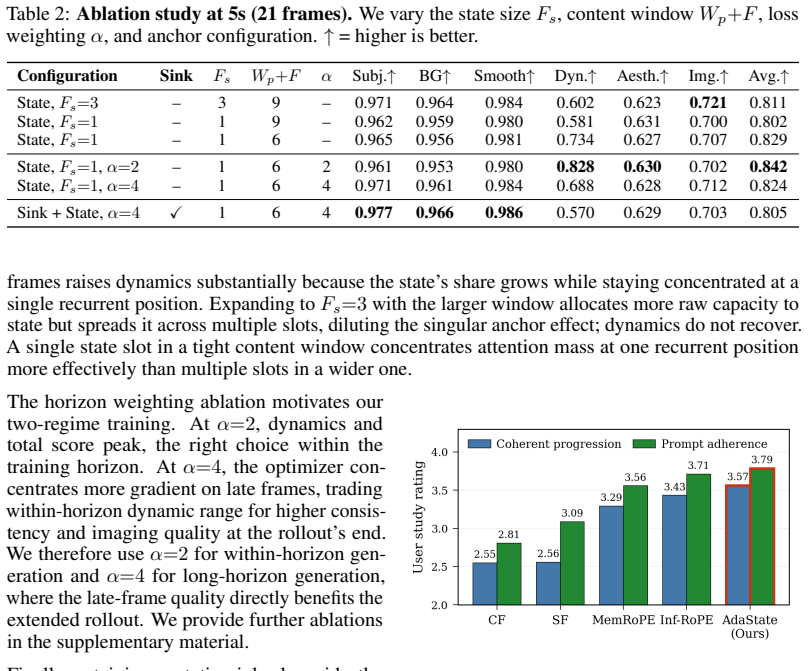
Significance. If the empirical claims hold, the method would offer a lightweight architectural change that introduces recurrence into streaming video diffusion without auxiliary losses or new modules, potentially addressing a structural limitation in temporal dynamics. The absence of any reported metrics, baselines, ablations, or state analysis, however, prevents assessment of whether the claimed gains materialize or whether the state carries meaningful scene-evolution information.
major comments (2)
- [Abstract] Abstract: the central claim that 'experiments demonstrate that the adaptive state substantially improves video dynamics' is unsupported by any quantitative metrics, baseline comparisons, dataset details, ablation results, or state-trajectory analysis, rendering the empirical contribution unevaluable.
- [Abstract] Abstract (method description): the state transition is trained solely via the standard diffusion objective on visible frames with no auxiliary loss, reconstruction target, or consistency regularizer on the hidden state itself; no evidence is supplied that the state avoids collapse to a constant representation or carries scene-evolution information, leaving the recurrence mechanism and claimed motion gains unverified.
minor comments (1)
- [Abstract] The description of 'time as relative' and identical positional structure across chunks would benefit from an explicit diagram or pseudocode showing the KV-cache layout and attention pattern at successive steps.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to strengthen the empirical grounding of the abstract. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'experiments demonstrate that the adaptive state substantially improves video dynamics' is unsupported by any quantitative metrics, baseline comparisons, dataset details, ablation results, or state-trajectory analysis, rendering the empirical contribution unevaluable.
Authors: The referee is correct that the current abstract asserts empirical gains without accompanying quantitative details, baselines, or analysis. We will revise the abstract to remove or qualify the unsupported claim and will add a concise summary of key metrics, datasets, and references to the experimental sections in the revised version. revision: yes
-
Referee: [Abstract] Abstract (method description): the state transition is trained solely via the standard diffusion objective on visible frames with no auxiliary loss, reconstruction target, or consistency regularizer on the hidden state itself; no evidence is supplied that the state avoids collapse to a constant representation or carries scene-evolution information, leaving the recurrence mechanism and claimed motion gains unverified.
Authors: The description is accurate: training uses only the standard diffusion loss with no auxiliary terms on the hidden state. We acknowledge that this leaves open the possibility of collapse and that no direct verification is currently provided. In revision we will add state-trajectory visualizations and simple quantitative checks (e.g., state variance across chunks) to demonstrate that the hidden state evolves meaningfully rather than collapsing. revision: yes
Circularity Check
No circularity: architectural proposal validated empirically
full rationale
The paper proposes an architectural replacement of the static first-frame KV anchor with a hidden adaptive state that is denoised jointly but never rendered. The claimed benefit in video dynamics is presented solely as an experimental outcome from applying the standard diffusion objective. No equations, derivations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the provided text. The construction is self-contained as a modeling change whose effectiveness is asserted via results rather than reduced to its inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can jointly denoise content and an auxiliary hidden state using the standard noise-prediction objective.
invented entities (1)
-
adaptive state (hidden latent)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Mode seeking meets mean seeking for fast long video generation.arXiv preprint arXiv:2602.24289, 2026
Shengqu Cai, Weili Nie, Chao Liu, Julius Berner, Lvmin Zhang, Nanye Ma, Hansheng Chen, Maneesh Agrawala, Leonidas Guibas, Gordon Wetzstein, et al. Mode seeking meets mean seeking for fast long video generation.arXiv preprint arXiv:2602.24289, 2026
-
[3]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling.arXiv preprint arXiv:1412.3555, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Self-forcing++: Towards minute-scale high-quality video generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=DzvPiqh23f
2026
-
[5]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024. URL https:...
2024
-
[6]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum...
2026
-
[7]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=ph04CRkPdC
2024
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= Itxz7S4Ip3
2025
-
[10]
Reasoning with latent tokens in diffusion language models.arXiv preprint arXiv:2602.03769, 2026
Andre He, Sean Welleck, and Daniel Fried. Reasoning with latent tokens in diffusion language models.arXiv preprint arXiv:2602.03769, 2026
-
[11]
Long short-term memory.Neural computation, 9(8): 1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural computation, 9(8): 1735–1780, 1997. 10
1997
-
[12]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelli...
-
[14]
Youngrae Kim, Qixin Hu, C-C Jay Kuo, and Peter A Beerel. Memrope: Training-free infinite video generation via evolving memory tokens.arXiv preprint arXiv:2603.12513, 2026
-
[15]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion.arXiv preprint arXiv:2602.07775, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, et al. Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation.arXiv preprint arXiv:2512.04678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Xiaofeng Mao, Shaohao Rui, Kaining Ying, Bo Zheng, Chuanhao Li, Mingmin Chi, and Kaipeng Zhang. Packforcing: Short video training suffices for long video sampling and long context inference.arXiv preprint arXiv:2603.25730, 2026
-
[19]
Show your work: Scratchpads for intermediate computation with language models
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models. InDeep Learning for Code Workshop, 2022. URL https://openreview.net/ forum?id=HBlx2idbkbq
2022
-
[20]
Jacob Pfau, William Merrill, and Samuel R. Bowman. Let’s think dot by dot: Hidden computa- tion in transformer language models. InFirst Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=NikbrdtYvG
2024
-
[21]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Learning internal representa- tions by error propagation
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning internal representa- tions by error propagation. Technical report, 1985
1985
-
[23]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
2025
-
[24]
Learning to (learn at test time): RNNs with expressive hidden states
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): RNNs with expressive hidden states. InForty-second Inter- national Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=wXfuOj9C7L
2025
-
[25]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=NG7sS51zVF. 11
2024
-
[27]
Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11269–11277, 2026
2026
-
[28]
Longlive: Real-time interactive long video generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Ying-Cong Chen, Yao Lu, Song Han, and Yukang Chen. Longlive: Real-time interactive long video generation. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=nCAODkpsPJ
2026
-
[29]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self- rollout.arXiv preprint arXiv:2511.20649, 2025
-
[30]
Deep forcing: Training-free long video generation with deep sink and participative compression
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081, 2025
-
[31]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[32]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In CVPR, 2025
2025
-
[33]
Yifei Yu, Xiaoshan Wu, Xinting Hu, Tao Hu, Yangtian Sun, Xiaoyang Lyu, Bo Wang, Lin Ma, Yuewen Ma, Zhongrui Wang, et al. Videossm: Autoregressive long video generation with hybrid state-space memory.arXiv preprint arXiv:2512.04519, 2025
-
[34]
Tianyuan Zhang, Sai Bi, Yicong Hong, Kai Zhang, Fujun Luan, Songlin Yang, Kalyan Sunkavalli, William T Freeman, and Hao Tan. Test-time training done right.arXiv preprint arXiv:2505.23884, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint arXiv:2602.02214, 2026. 12 Table of Contents A Implementation Details 14 B User Study Details 14 C Evaluation Details 15 D Supplementary Video Results...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.