Hamiltonian-Inspired Attention Mechanism for Scalable RF Transmitter Fingerprinting
Pith reviewed 2026-06-30 19:19 UTC · model grok-4.3
The pith
A Hamiltonian-inspired attention mechanism preserves norms in value updates to scale RF transmitter fingerprinting to 150 devices on raw I/Q signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
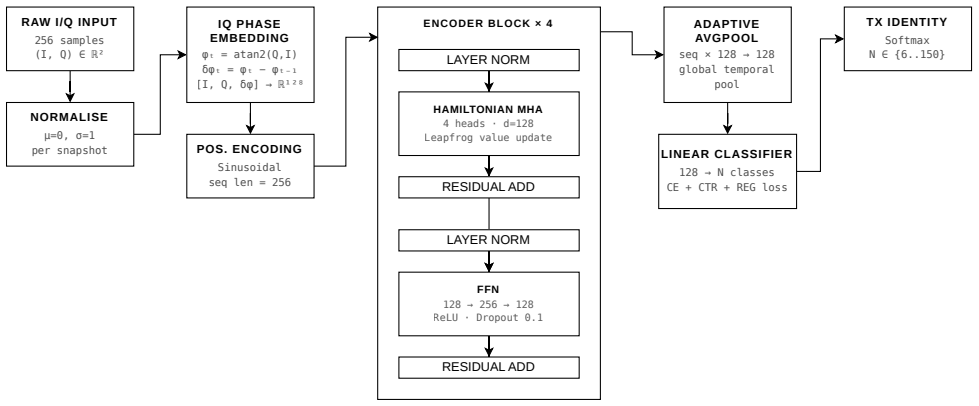
The central claim is that embedding Hamiltonian dynamics into attention—specifically by learning a skew-symmetric generator and applying Störmer-Verlet leapfrog integration to enforce norm-preserving value updates, together with phase-increment embeddings—supplies an inductive bias that improves both accuracy and scaling behavior for large-scale RF transmitter identification on non-equalized raw baseband I/Q signals.
What carries the argument
Hamiltonian attention head that applies a learned skew-symmetric matrix as generator and Störmer-Verlet leapfrog integration to enforce norm-preserving value dynamics.
If this is right
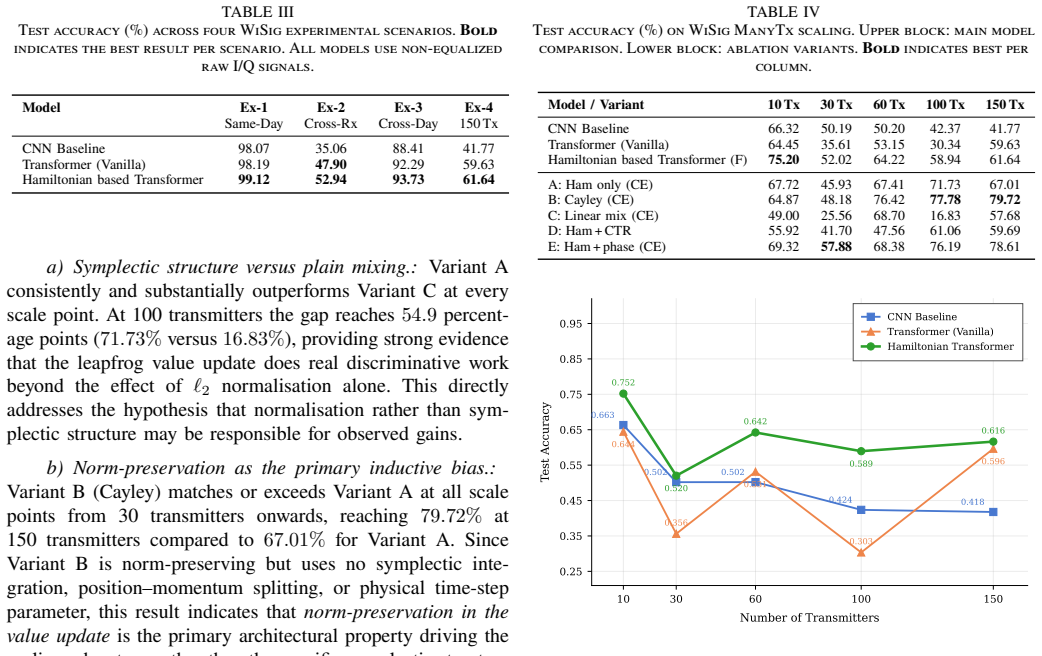
- The model reaches 99.12 percent same-day accuracy and 61.64 percent accuracy at 150 transmitters while outperforming CNN and Transformer baselines at every scale point tested.
- Norm preservation inside the value update is the dominant inductive bias responsible for the scaling improvement.
- The phase-increment embedding supplies the single largest per-component accuracy lift.
- The same architecture improves cross-receiver and cross-day generalization on raw I/Q signals.
Where Pith is reading between the lines
- The same conservation prior could be tested on other signal-classification problems where amplitude or energy should remain stable across layers.
- If the mechanism works because it limits representational drift, similar constraints might help attention models in domains with known conservation laws.
- Extending the phase-increment idea to capture additional hardware impairments such as amplifier nonlinearity would be a direct next measurement.
Load-bearing premise
That the learned skew-symmetric generator combined with Störmer-Verlet leapfrog integration actually produces and maintains norm-preserving value dynamics that supply a useful inductive bias for transmitter scaling.
What would settle it
An ablation that disables the leapfrog integration step and measures whether accuracy at 150 transmitters falls to the level of the plain Transformer baseline would directly test whether norm preservation drives the reported scaling gain.
Figures



read the original abstract
Radio-frequency (RF) fingerprinting identifies wire-less transmitters using hardware-induced imperfections present in baseband I/Q signals. However, deep learning models often degrade under receiver and channel distribution shifts, particularly as transmitter populations grow. This work proposes the Hamiltonian Transformer, a physics-informed attention architecture that enforces norm preserving value dynamics within each attention head using a learned skew-symmetric generator and a St\"ormer-Verlet leapfrog integration step. An additional phase-increment embedding exposes oscillator dynamics at the input layer. All experiments use non-equalized raw I/Q signals from the WiSig dataset under four protocols: same-day classification, cross-receiver generalisation, cross-day generalisation, and transmitter scaling up to 150 devices. The Hamiltonian Transformer achieves 99.12% accuracy under same-day conditions and 61.64% at 150 transmitters, consistently outperforming CNN and Transformer baselines across all scale points. A controlled ablation study identifies norm-preservation in the value update as the primary inductive bias driving the scaling advantage, with the phase increment embedding providing the single largest per-component improvement. These results indicate that embedding physics-informed structural priors into attention mechanisms is an effective approach to large-scale transmitter identification on raw wireless signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hamiltonian Transformer, a physics-informed attention architecture for RF transmitter fingerprinting on raw I/Q signals. It enforces norm-preserving value dynamics in each attention head via a learned skew-symmetric generator combined with Störmer-Verlet leapfrog integration, and adds a phase-increment embedding for oscillator dynamics. Experiments on the WiSig dataset under same-day, cross-receiver, cross-day, and scaling protocols (up to 150 transmitters) report 99.12% same-day accuracy and 61.64% at 150 transmitters, outperforming CNN and standard Transformer baselines. A controlled ablation attributes the scaling gains primarily to the norm-preservation mechanism, with the phase embedding providing the largest single-component gain.
Significance. If the results and ablation hold, the work demonstrates that Hamiltonian structural priors can be embedded into attention mechanisms to yield beneficial inductive biases for generalization and scaling in large-scale RF fingerprinting tasks. The controlled ablation identifying norm-preservation as the key driver, along with explicit comparison to baselines across multiple protocols, strengthens the case for physics-informed attention in wireless signal processing.
major comments (2)
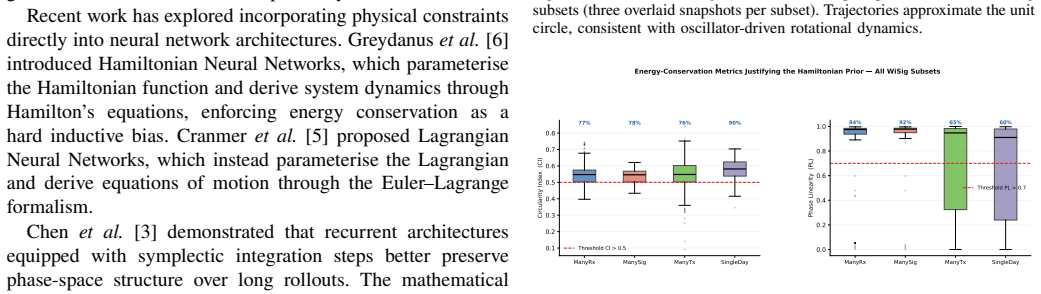
- [§4.3] §4.3 (Ablation study): The claim that norm-preservation is the primary driver of the scaling advantage requires confirmation that the ablation controls isolate this component without confounding changes to other hyperparameters or training dynamics; the reported accuracy deltas should be accompanied by standard deviations over multiple random seeds to establish statistical reliability.
- [§3.2] §3.2, Eq. (8)–(10): The Störmer-Verlet leapfrog step is stated to enforce exact norm preservation, but the discretization and handling of the learned skew-symmetric generator A should be shown to guarantee that the value update remains on the unit sphere for finite step sizes; any deviation would weaken the inductive-bias argument.
minor comments (3)
- [§3.1] The phase-increment embedding is described as exposing oscillator dynamics, but its precise formulation (e.g., how the increment is computed from the I/Q samples) should be given explicitly with a short derivation or pseudocode.
- [Figure 3] Figure 3 (scaling curves) would benefit from error bars or shaded regions indicating variability across runs, especially at the 150-transmitter point where the gap to baselines is largest.
- [§4.1] The WiSig dataset preprocessing (e.g., exact windowing, normalization, and handling of non-equalized signals) is referenced but should include a brief table or paragraph listing the precise parameters used for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additional results.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Ablation study): The claim that norm-preservation is the primary driver of the scaling advantage requires confirmation that the ablation controls isolate this component without confounding changes to other hyperparameters or training dynamics; the reported accuracy deltas should be accompanied by standard deviations over multiple random seeds to establish statistical reliability.
Authors: The ablation variants were constructed by changing only the value-update rule while freezing all other architectural components, hyperparameters, and training schedules. We agree that standard deviations across seeds would strengthen statistical reliability of the reported deltas. In the revision we will rerun the full ablation suite with five independent random seeds and report means together with standard deviations. revision: yes
-
Referee: [§3.2] §3.2, Eq. (8)–(10): The Störmer-Verlet leapfrog step is stated to enforce exact norm preservation, but the discretization and handling of the learned skew-symmetric generator A should be shown to guarantee that the value update remains on the unit sphere for finite step sizes; any deviation would weaken the inductive-bias argument.
Authors: We will insert a short derivation immediately after Eq. (10) showing that the leapfrog update with skew-symmetric A produces an orthogonal transformation and therefore preserves the Euclidean norm exactly for any finite step size h. The derivation relies on the property that each half-step is equivalent to multiplication by an orthogonal matrix generated from the skew-symmetric generator. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new architecture (Hamiltonian Transformer) with explicit components (skew-symmetric generator, Störmer-Verlet integration, phase-increment embedding) and evaluates it via controlled ablation on the WiSig dataset across multiple protocols. The scaling advantage is attributed to norm-preservation identified empirically in ablation, not by construction or self-citation. No load-bearing step reduces a claimed result to a fitted parameter renamed as prediction, a self-defined quantity, or an unverified self-citation chain. The derivation chain consists of architectural design choices followed by independent empirical measurement.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learned skew-symmetric generator
axioms (2)
- standard math Hamiltonian dynamics can be discretized using Störmer-Verlet leapfrog to preserve norms in attention value updates
- domain assumption Norm preservation provides an inductive bias beneficial for scaling in transmitter classification
Reference graph
Works this paper leans on
-
[1]
Chowdhury, and Tommaso Melodia
Amani Al-Shawabka, Francesco Restuccia, Salvatore D’Oro, Tong Jian, Bruno Costa Rendon, Nasim Soltani, Jennifer Dy, Stratis Ioannidis, Kaushik R. Chowdhury, and Tommaso Melodia. Exposing the fin- gerprint: Dissecting the impact of the wireless channel on radio fin- gerprinting. InProc. IEEE Conference on Computer Communications (INFOCOM), pages 646–655. I...
2020
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer nor- malization. InProc. NeurIPS Workshop on Deep Learning Symposium, 2016
2016
-
[3]
Symplectic recurrent neural networks
Zhengdao Chen, Jianyu Zhang, Martín Arjovsky, and Léon Bottou. Symplectic recurrent neural networks. InProc. International Conference on Learning Representations (ICLR), 2020
2020
-
[4]
Learning a similarity metric discriminatively, with application to face verification
Sumit Chopra, Raia Hadsell, and Yann LeCun. Learning a similarity metric discriminatively, with application to face verification. InProc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 539–546. IEEE, 2005
2005
-
[5]
Lagrangian neural networks.arXiv preprint arXiv:2003.04630, 2020
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho. Lagrangian neural networks.arXiv preprint arXiv:2003.04630, 2020
-
[6]
Hamiltonian neural networks
Samuel Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), pages 15353–15363, 2019
2019
-
[7]
Springer, 2nd edition, 2006
Ernst Hairer, Christian Lubich, and Gerhard Wanner.Geometric Numerical Integration: Structure-Preserving Algorithms for Ordinary Differential Equations, volume 31 ofSpringer Series in Computational Mathematics. Springer, 2nd edition, 2006
2006
-
[8]
Open set wireless transmitter authorization: Deep learning approaches and dataset considerations.IEEE Transactions on Cognitive Communications and Networking, 7(1):59–72, 2021
Samer Hanna, Samurdhi Karunaratne, and Danijela Cabric. Open set wireless transmitter authorization: Deep learning approaches and dataset considerations.IEEE Transactions on Cognitive Communications and Networking, 7(1):59–72, 2021
2021
-
[9]
WiSig: A large-scale WiFi signal dataset for receiver and channel agnostic RF fingerprinting.IEEE Access, 10:22808–22818, 2022
Samer Hanna, Samurdhi Karunaratne, and Danijela Cabric. WiSig: A large-scale WiFi signal dataset for receiver and channel agnostic RF fingerprinting.IEEE Access, 10:22808–22818, 2022
2022
-
[10]
Helfrich, Devin Willmott, and Qiang Ye
Kyle E. Helfrich, Devin Willmott, and Qiang Ye. Orthogonal recurrent neural networks with scaled Cayley transform. InProc. International Conference on Machine Learning (ICML), pages 1970–1978, 2018
1970
-
[11]
Chowdhury, and Stratis Ioannidis
Tong Jian, Bruno Costa Rendon, Emmanuel Ojuba, Nasim Soltani, Zifeng Wang, Kunal Sankhe, Andrey Gritsenko, Jennifer Dy, Kaushik R. Chowdhury, and Stratis Ioannidis. Deep learning for RF fingerprinting: A massive experimental study.IEEE Internet of Things Magazine, 3(1):50–57, 2020
2020
-
[12]
Kosiorek, Seungjin Choi, and Yee Whye Teh
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam R. Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention- based permutation-invariant neural networks. InProc. International Conference on Machine Learning (ICML), pages 3744–3753, 2019
2019
-
[13]
Decoupled weight decay regulariza- tion
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regulariza- tion. InProc. International Conference on Learning Representations (ICLR), 2019
2019
-
[14]
O’Shea, Johnathan Corgan, and T
Timothy J. O’Shea, Johnathan Corgan, and T. Charles Clancy. Convo- lutional radio modulation recognition networks. InProc. International Conference on Engineering Applications of Neural Networks (EANN), pages 213–226. Springer, 2016
2016
-
[15]
Overview of the ORBIT radio grid testbed for evaluation of next-generation wireless network protocols
Dipankar Raychaudhuri, Ivan Seskar, Max Ott, Sachin Ganu, Kishore Ramachandran, Haris Kremo, Robert Siracusa, Hang Liu, and Manpreet Singh. Overview of the ORBIT radio grid testbed for evaluation of next-generation wireless network protocols. InProc. IEEE Wireless Communications and Networking Conference (WCNC), volume 3, pages 1664–1669. IEEE, 2005
2005
-
[16]
Chowdhury
Shamnaz Riyaz, Kunal Sankhe, Stratis Ioannidis, and Kaushik R. Chowdhury. Deep learning convolutional neural networks for radio identification.IEEE Communications Magazine, 56(9):146–152, 2018
2018
-
[17]
Chowdhury
Kunal Sankhe, Mauro Belgiovine, Fan Zhou, Luca Angioloni, Francesco Restuccia, Salvatore D’Oro, Tommaso Melodia, Stratis Ioannidis, and Kaushik R. Chowdhury. No radio left behind: Radio fingerprinting through deep learning of physical-layer hardware impairments.IEEE Transactions on Cognitive Communications and Networking, 6(1):165– 178, 2020
2020
-
[18]
ORACLE: Optimized radio clAs- sification through Convolutional neuraL nEtworks
Kunal Sankhe, Mauro Belgiovine, Fan Zhou, Shamnaz Riyaz, Stratis Ioannidis, and Kaushik Chowdhury. ORACLE: Optimized radio clAs- sification through Convolutional neuraL nEtworks. InProc. IEEE Conference on Computer Communications (INFOCOM), pages 370–378. IEEE, 2019
2019
-
[19]
Caval- laro
Guanxiong Shen, Junqing Zhang, Alan Marshall, and Joseph R. Caval- laro. Towards scalable and channel-robust radio frequency fingerprint identification for LoRa.IEEE Transactions on Information Forensics and Security, 17:774–787, 2022
2022
-
[20]
Dy, Stratis Ioannidis, and Kaushik R
Nasim Soltani, Kunal Sankhe, Jennifer G. Dy, Stratis Ioannidis, and Kaushik R. Chowdhury. More is better: Data augmentation for channel- resilientRFfingerprinting.IEEECommunicationsMagazine,58(10):66– 72, 2020
2020
-
[21]
Zico Kolter
Asher Trockman and J. Zico Kolter. Orthogonalizing convolutional layers with the Cayley transform. InProc. International Conference on Learning Representations (ICLR), 2021
2021
-
[22]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5998–6008, 2017
2017
-
[23]
Radio frequency fingerprint identi- fication for narrowband systems: Modelling and classification.IEEE Transactions on Information Forensics and Security, 16:3974–3987, 2021
Junqing Zhang, Roger Woods, Magnus Sandell, Mikko Valkama, Alan Marshall, and Joseph Cavallaro. Radio frequency fingerprint identi- fication for narrowband systems: Modelling and classification.IEEE Transactions on Information Forensics and Security, 16:3974–3987, 2021
2021
-
[24]
GAN-RXA: A practical scalable solution to receiver-agnostic transmitter fingerprinting.IEEE Transactions on Cognitive Communications and Networking, 10(2):523–537, 2024
Tianyi Zhao, Shamik Sarkar, Enes Krijestorac, and Danijela Cabric. GAN-RXA: A practical scalable solution to receiver-agnostic transmitter fingerprinting.IEEE Transactions on Cognitive Communications and Networking, 10(2):523–537, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.