DTG-Restore: Training-Free Diffusion Refinement for Generative Video Super-Resolution
Pith reviewed 2026-06-29 08:09 UTC · model grok-4.3
The pith
Decoupling the unconditional branch to a cleaner diffusion timestep restores geometry in distorted videos without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
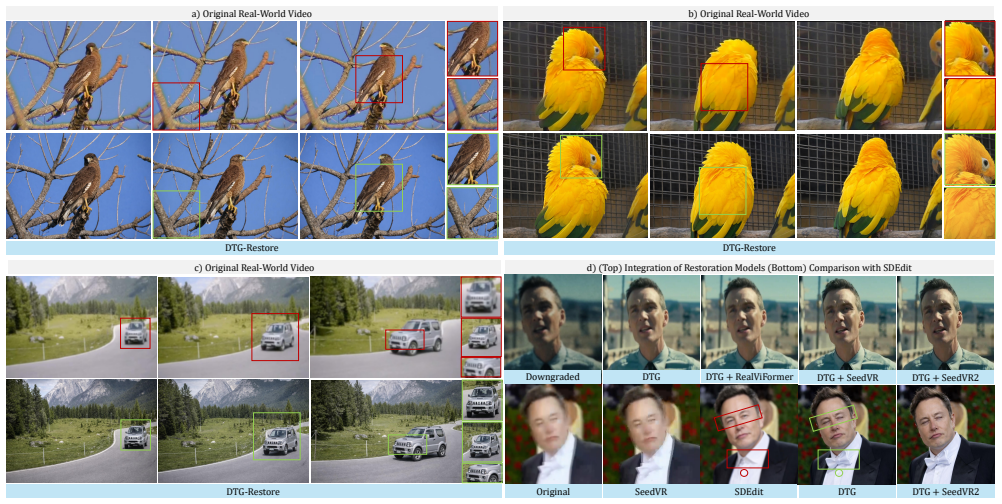
Decoupled Time Guidance evaluates the unconditional branch at a cleaner diffusion timestep to obtain a lookahead prior that preserves geometry while suppressing replication of warped content; annealing this temporal bias throughout sampling lets the model move from structure correction to detail refinement, yielding higher structural fidelity and temporal stability when combined with any off-the-shelf restoration module.
What carries the argument
Decoupled Time Guidance (DTG), which runs the unconditional score at an earlier timestep than the conditional score and anneals the resulting temporal offset during denoising.
If this is right
- Structural fidelity improves on videos containing warped faces, body misalignments, and spatial artifacts from generative models.
- Temporal stability increases without any model retraining or fine-tuning.
- The approach combines plug-and-play with existing restoration modules for both AI-generated and real-world low-resolution video.
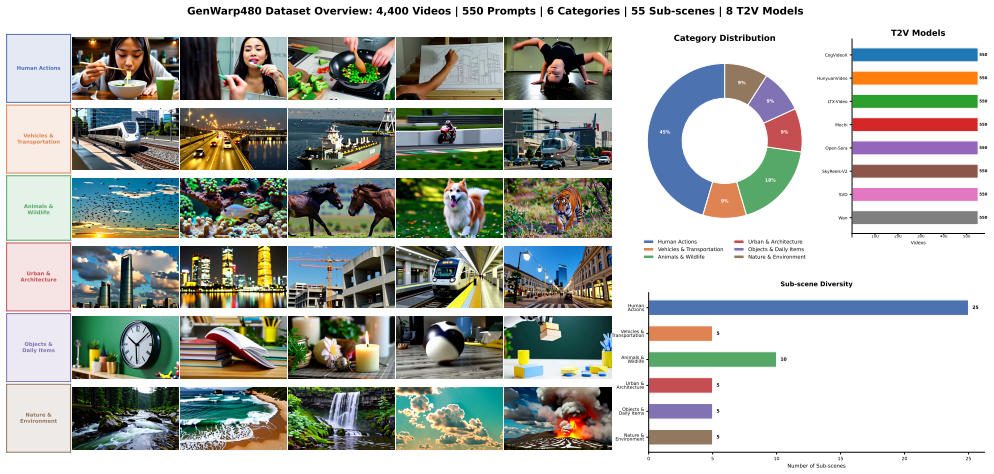
- A dedicated benchmark of 4,400 distorted 480p clips enables targeted testing of robustness to generative errors.
Where Pith is reading between the lines
- The same temporal decoupling might apply to other diffusion tasks that require consistent geometry, such as image-to-video or 3D asset generation.
- Removing the need for task-specific retraining could lower the barrier to deploying diffusion restorers on new degradation types.
- Annealing schedules derived from this principle could be tested for stability when the base diffusion model changes architecture or training data.
Load-bearing premise
Evaluating the unconditional branch at a cleaner timestep produces a reliable lookahead prior whose annealing schedule works across varied generative degradations without any per-model tuning.
What would settle it
Running the method on multiple text-to-video models and measuring no gain in face-warping or body-alignment metrics relative to standard classifier-free guidance would falsify the central claim.
Figures



read the original abstract
Recent progress in video diffusion models has enabled remarkable generative fidelity, yet leveraging these priors for restoration remains limited by the strong coupling between conditional and unconditional branches in standard classifier-free guidance. We introduce a training-free framework that enhances distorted and low-resolution videos by decoupling these signals in time. Our proposed Decoupled Time Guidance (DTG) evaluates the unconditional branch at a cleaner diffusion timestep, providing a lookahead prior that preserves geometry while suppressing replication of warped content. This temporal bias is annealed throughout sampling, allowing the model to transition from structure correction to detail refinement without retraining. Combined with any off-the-shelf restoration module in a plug-and-play manner, our approach improves perceptual coherence and restores plausible structure in AIgenerated and real-world videos alike. To facilitate evaluation, we curate GenWarp480, a benchmark of 4,400 distorted 480p videos synthesized from diverse text-to-video models. GenWarp480 focuses on characteristic generative degradations such as warped faces, body misalignments, and spatial artifacts, providing a purpose-built testbed for assessing robustness to generative errors. Extensive experiments demonstrate that our method achieves significant improvements in structural fidelity and temporal stability without any model training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DTG-Restore, a training-free plug-and-play framework for generative video super-resolution. It proposes Decoupled Time Guidance (DTG) that evaluates the unconditional branch of classifier-free guidance at a cleaner diffusion timestep to supply a lookahead prior, which is annealed over the sampling process to shift from structure correction to detail refinement. The method is combined with off-the-shelf restoration modules and evaluated on a new benchmark, GenWarp480, consisting of 4,400 distorted 480p videos exhibiting generative artifacts such as warped faces and body misalignments. Experiments claim improvements in structural fidelity and temporal stability without retraining any model.
Significance. If the central mechanism holds, the work provides a practical, training-free way to leverage existing video diffusion priors for restoration of both AI-generated and real-world content, addressing a gap in handling characteristic generative degradations. The introduction of GenWarp480 as a purpose-built benchmark focused on these artifacts is a concrete contribution that could facilitate future comparisons.
major comments (2)
- [§3] §3: The description of DTG states that the unconditional branch is evaluated at a cleaner timestep and the resulting temporal bias is annealed, but provides no explicit functional form for the annealing schedule or the rule for selecting the timestep offset. This is load-bearing for the claim that a single fixed schedule reliably transitions from structure correction to detail refinement across arbitrary generative degradations without model-specific tuning.
- [§4] §4 (experiments on GenWarp480): The evaluation uses a fixed DTG configuration on videos synthesized from diverse text-to-video models, yet reports no ablations that vary the base diffusion model, noise schedule, or degradation statistics to test whether the lookahead prior and annealing remain effective without retuning. This directly bears on the training-free and plug-and-play assertions.
minor comments (2)
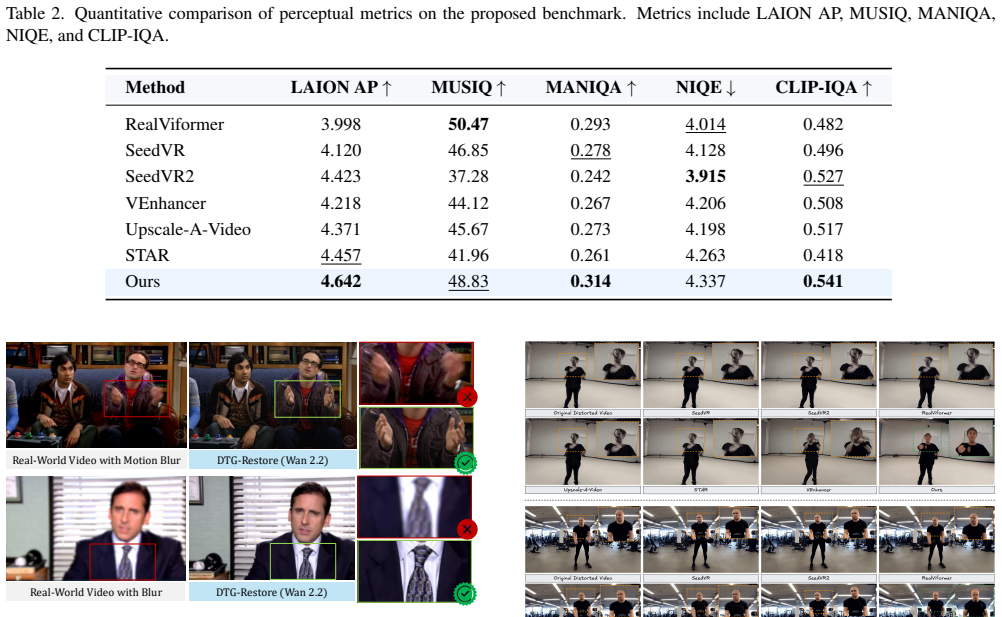
- The abstract and §1 refer to 'significant improvements' but the quantitative tables should include per-metric standard deviations or statistical significance tests to support the cross-method comparisons.
- [§3] Notation for the decoupled guidance scale and timestep offset should be introduced with a clear equation in §3 rather than only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address the two major comments point by point below, agreeing that additional explicit details and experiments will strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3: The description of DTG states that the unconditional branch is evaluated at a cleaner diffusion timestep and the resulting temporal bias is annealed, but provides no explicit functional form for the annealing schedule or the rule for selecting the timestep offset. This is load-bearing for the claim that a single fixed schedule reliably transitions from structure correction to detail refinement across arbitrary generative degradations without model-specific tuning.
Authors: We agree that the current qualitative description in Section 3 would benefit from explicit mathematical details to support reproducibility and the training-free claim. In the revised manuscript we will add the precise functional form of the annealing schedule together with the rule used to select the timestep offset. revision: yes
-
Referee: [§4] §4 (experiments on GenWarp480): The evaluation uses a fixed DTG configuration on videos synthesized from diverse text-to-video models, yet reports no ablations that vary the base diffusion model, noise schedule, or degradation statistics to test whether the lookahead prior and annealing remain effective without retuning. This directly bears on the training-free and plug-and-play assertions.
Authors: GenWarp480 already draws from multiple distinct text-to-video models and therefore contains variation in generative artifacts. We nevertheless acknowledge that dedicated ablations on base model, noise schedule, and degradation statistics are absent. We will conduct and report these additional experiments in the revision to further substantiate the fixed-schedule robustness. revision: yes
Circularity Check
No circularity: method is a procedural heuristic with no self-referential derivations or fitted predictions.
full rationale
The paper introduces DTG as a training-free procedural modification to classifier-free guidance: evaluate the unconditional branch at a cleaner timestep and anneal the bias. No equations, parameters, or predictions are presented that reduce by construction to inputs from the same data or self-citations. The central claim is an empirical procedural bias whose effectiveness is tested on GenWarp480 rather than derived from prior fitted quantities. This is the common case of a self-contained heuristic description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
BasicVSR: The search for essential com- ponents in video super-resolution and beyond
Kelvin CK Chan, Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. BasicVSR: The search for essential com- ponents in video super-resolution and beyond. InCVPR,
-
[3]
BasicVSR++: Improving video super- resolution with enhanced propagation and alignment
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. BasicVSR++: Improving video super- resolution with enhanced propagation and alignment. In CVPR, 2022. 1, 2
2022
-
[4]
Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy
Kelvin C.K. Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. Investigating tradeoffs in real-world video super-resolution. InCVPR, 2022. 2
2022
-
[5]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Videocrafter2: Overcoming data limitations for high-quality video diffu- sion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7310– 7320, 2024. 3
2024
-
[7]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13320–13331, 2024. 2
2024
-
[8]
Yusuf Dalva, Hidir Yesiltepe, and Pinar Yanardag. Gantastic: Gan-based transfer of interpretable directions for disentan- gled image editing in text-to-image diffusion models.arXiv preprint arXiv:2403.19645, 2024. 1
-
[9]
Yusuf Dalva, Hidir Yesiltepe, and Pinar Yanardag. Lo- rashop: Training-free multi-concept image generation and editing with rectified flow transformers.arXiv preprint arXiv:2505.23758, 2025. 1
-
[10]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. 2024. 3
2024
-
[11]
Rstt: Real-time spatial temporal transformer for space-time video super-resolution
Zhicheng Geng, Luming Liang, Tianyu Ding, and Ilya Zharkov. Rstt: Real-time spatial temporal transformer for space-time video super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17441–17451, 2022. 1, 2
2022
-
[12]
Make a cheap scaling: A self-cascade diffusion model for higher-resolution adapta- tion
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xin- tao Wang, Qifeng Chen, et al. Make a cheap scaling: A self-cascade diffusion model for higher-resolution adapta- tion. InEuropean conference on computer vision, pages 39–
-
[13]
Springer, 2024. 2, 3
2024
-
[14]
Jingwen He, Tianfan Xue, Dongyang Liu, Xinqi Lin, Peng Gao, Dahua Lin, Yu Qiao, Wanli Ouyang, and Ziwei Liu. Venhancer: Generative space-time enhancement for video generation.arXiv preprint arXiv:2407.07667, 2024. 1, 2, 6, 8
-
[15]
Scalecrafter: Tuning-free higher- resolution visual generation with diffusion models
Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, and Ying Shan. Scalecrafter: Tuning-free higher- resolution visual generation with diffusion models. InThe Twelfth International Conference on Learning Representa- tions, 2023. 3
2023
-
[16]
Video super-resolution with recurrent structure-detail network
Takashi Isobe, Xu Jia, Shuhang Gu, Songjiang Li, Shengjin Wang, and Qi Tian. Video super-resolution with recurrent structure-detail network. InECCV, 2020. 2
2020
-
[17]
Rave: Randomized noise shuf- fling for fast and consistent video editing with diffusion mod- els
Ozgur Kara, Bariscan Kurtkaya, Hidir Yesiltepe, James M Rehg, and Pinar Yanardag. Rave: Randomized noise shuf- fling for fast and consistent video editing with diffusion mod- els. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6507–6516,
-
[18]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding varia- tional bayes.arXiv preprint arXiv:1312.6114, 2013. 3
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[19]
A simple baseline for video restoration with grouped spatial- temporal shift
Dasong Li, Xiaoyu Shi, Yi Zhang, Ka Chun Cheung, Simon See, Xiaogang Wang, Hongwei Qin, and Hongsheng Li. A simple baseline for video restoration with grouped spatial- temporal shift. InCVPR, 2023. 2
2023
-
[20]
Recurrent video restoration trans- former with guided deformable attention.NeurIPS, 2022
Jingyun Liang, Yuchen Fan, Xiaoyu Xiang, Rakesh Ranjan, Eddy Ilg, Simon Green, Jiezhang Cao, Kai Zhang, Radu Timofte, and Luc V Gool. Recurrent video restoration trans- former with guided deformable attention.NeurIPS, 2022. 2
2022
-
[21]
VRT: A video restoration transformer.IEEE TIP, 2024
Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, and Luc Van Gool. VRT: A video restoration transformer.IEEE TIP, 2024. 1
2024
-
[22]
Learning trajectory-aware transformer for video super- resolution
Chengxu Liu, Huan Yang, Jianlong Fu, and Xueming Qian. Learning trajectory-aware transformer for video super- resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5687–5696,
-
[23]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jian- feng Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Zi- wei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jia- jun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equa- tions.arXiv preprint arXiv:2108.01073, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Motionflow: Attention-driven mo- tion transfer in video diffusion models
Tuna Han Salih Meral, Hidir Yesiltepe, Connor Dunlop, and Pinar Yanardag. Motionflow: Attention-driven mo- tion transfer in video diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8043– 8051, 2026. 1
2026
-
[27]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 1, 2, 3
2023
-
[29]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InICLR, 2023. 3
2023
-
[30]
Rethinking alignment in video super- resolution transformers.Advances in Neural Information Processing Systems, 35:36081–36093, 2022
Shuwei Shi, Jinjin Gu, Liangbin Xie, Xintao Wang, Yujiu Yang, and Chao Dong. Rethinking alignment in video super- resolution transformers.Advances in Neural Information Processing Systems, 35:36081–36093, 2022. 2
2022
-
[31]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Jianyi Wang, Shanchuan Lin, Zhijie Lin, Yuxi Ren, Meng Wei, Zongsheng Yue, Shangchen Zhou, Hao Chen, Yang Zhao, Ceyuan Yang, et al. Seedvr2: One-step video restora- tion via diffusion adversarial post-training.arXiv preprint arXiv:2506.05301, 2025. 1, 2, 6, 8
-
[34]
Seedvr: Seeding in- finity in diffusion transformer towards generic video restora- tion
Jianyi Wang, Zhijie Lin, Meng Wei, Yang Zhao, Ceyuan Yang, Chen Change Loy, and Lu Jiang. Seedvr: Seeding in- finity in diffusion transformer towards generic video restora- tion. InCVPR, 2025. 6
2025
-
[35]
Edvr: Video restoration with enhanced deformable convolutional networks
Xintao Wang, Kelvin CK Chan, Ke Yu, Chao Dong, and Chen Change Loy. Edvr: Video restoration with enhanced deformable convolutional networks. InCVPRW, 2019. 2
2019
-
[36]
Lavie: High-quality video generation with cascaded latent diffusion models.International Journal of Computer Vision, 133(5):3059–3078, 2025
Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models.International Journal of Computer Vision, 133(5):3059–3078, 2025. 2
2025
-
[37]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7623–7633, 2023. 2
2023
-
[38]
Rui Xie, Yinhong Liu, Penghao Zhou, Chen Zhao, Jun Zhou, Kai Zhang, Zhenyu Zhang, Jian Yang, Zhenheng Yang, and Ying Tai. Star: Spatial-temporal augmentation with text-to- video models for real-world video super-resolution.arXiv preprint arXiv:2501.02976, 2025. 1, 2, 6, 8
-
[39]
Motion- guided latent diffusion for temporally consistent real-world video super-resolution
Xi Yang, Chenhang He, Jianqi Ma, and Lei Zhang. Motion- guided latent diffusion for temporally consistent real-world video super-resolution. InECCV, 2024. 1, 2, 6, 7
2024
-
[40]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 1, 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Dynamic view synthe- sis as an inverse problem.arXiv preprint arXiv:2506.08004,
Hidir Yesiltepe and Pinar Yanardag. Dynamic view synthe- sis as an inverse problem.arXiv preprint arXiv:2506.08004,
-
[42]
Hidir Yesiltepe, Kiymet Akdemir, and Pinar Yanardag. Mist: Mitigating intersectional bias with disentangled cross- attention editing in text-to-image diffusion models.arXiv preprint arXiv:2403.19738, 2024. 1
-
[43]
Motionshop: Zero-shot motion transfer in video diffusion models with mixture of score guidance
Hidir Yesiltepe, Tuna Han Salih Meral, Connor Dunlop, and Pinar Yanardag. Motionshop: Zero-shot motion transfer in video diffusion models with mixture of score guidance. arXiv preprint arXiv:2412.05355, 2024. 1
-
[44]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action- controllable infinite video generation emerges from autore- gressive self-rollout.arXiv preprint arXiv:2511.20649,
-
[45]
FMA- Net: Flow-guided dynamic filtering and iterative feature re- finement with multi-attention for joint video super-resolution and deblurring
Geunhyuk Youk, Jihyong Oh, and Munchurl Kim. FMA- Net: Flow-guided dynamic filtering and iterative feature re- finement with multi-attention for joint video super-resolution and deblurring. InCVPR, 2024. 2
2024
-
[46]
Show-1: Marrying pixel and latent diffusion models for text-to-video generation.International Journal of Com- puter Vision, 133(4):1879–1893, 2025
David Junhao Zhang, Jay Zhangjie Wu, Jia-Wei Liu, Rui Zhao, Lingmin Ran, Yuchao Gu, Difei Gao, and Mike Zheng Shou. Show-1: Marrying pixel and latent diffusion models for text-to-video generation.International Journal of Com- puter Vision, 133(4):1879–1893, 2025. 2
2025
-
[47]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, and Jingren Zhou. I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models.arXiv preprint arXiv:2311.04145, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
RealViformer: Investigating attention for real-world video super-resolution.ECCV, 2024
Yuehan Zhang and Angela Yao. RealViformer: Investigating attention for real-world video super-resolution.ECCV, 2024. 2, 6, 7
2024
-
[49]
Stylebreeder: Exploring and democratizing artistic styles through text-to- image models.Advances in Neural Information Processing Systems, 37:34098–34122, 2024
Matthew Zheng, Enis Simsar, Hidir Yesiltepe, Federico Tombari, Joel Simon, and Pinar Yanardag. Stylebreeder: Exploring and democratizing artistic styles through text-to- image models.Advances in Neural Information Processing Systems, 37:34098–34122, 2024. 1 10
2024
-
[50]
How would you rate the perceived clarity and sharpness of the video?
Shangchen Zhou, Peiqing Yang, Jianyi Wang, Yihang Luo, and Chen Change Loy. Upscale-A-Video: Temporal- consistent diffusion model for real-world video super- resolution. InCVPR, 2024. 1, 2, 6, 8 1 DTG-Restore: Training-Free Diffusion Refinement for Generative Video Super-Resolution Supplementary Material A. Details on User Study We conducted a user study ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.