Cross-Lingual Steering for Figurative Language Generation
Pith reviewed 2026-06-29 07:51 UTC · model grok-4.3
The pith
Activation directions for figurative language learned in one language increase the behavior when applied during generation in another.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
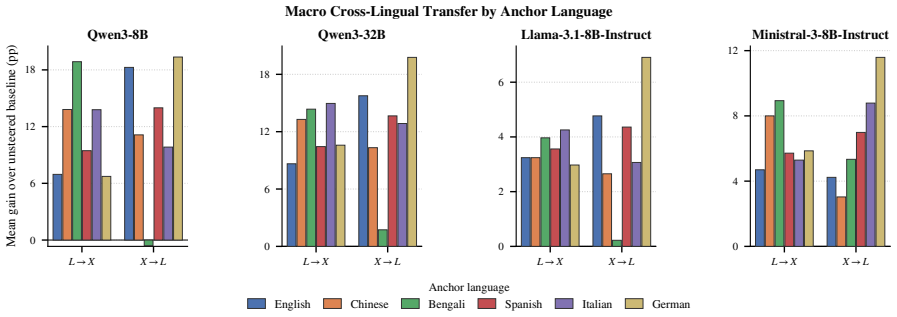
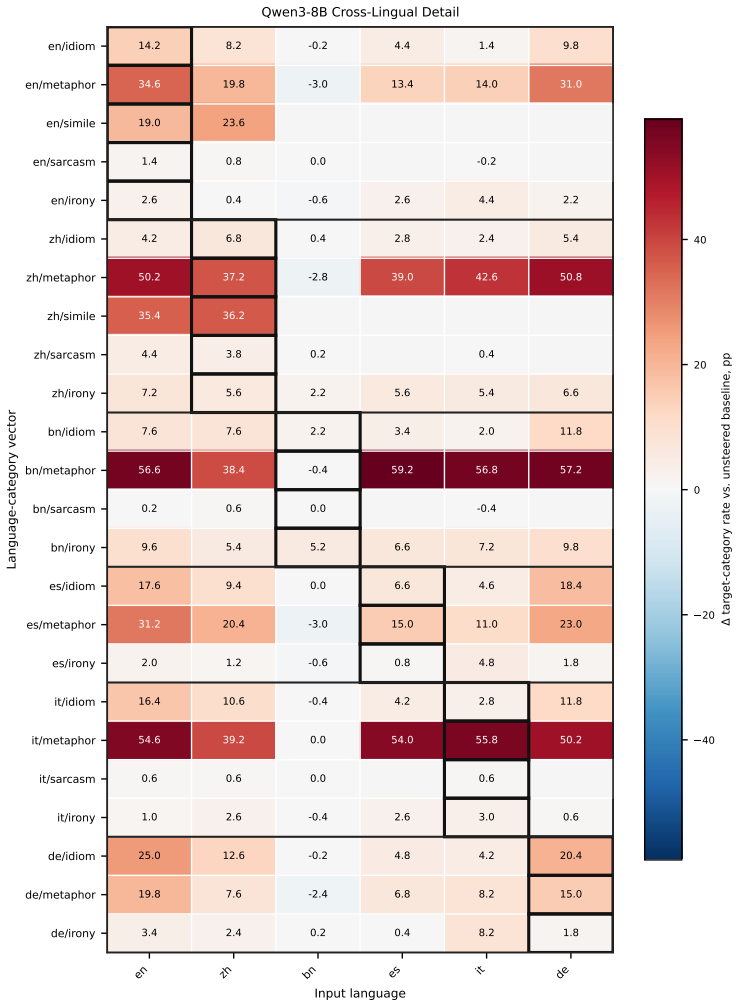
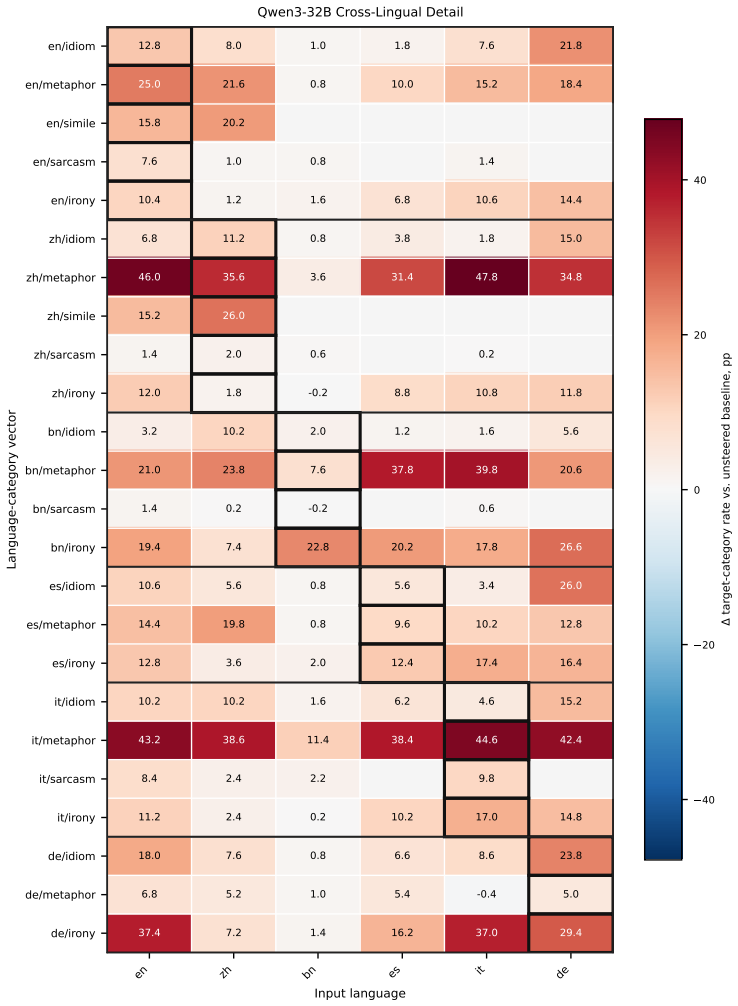
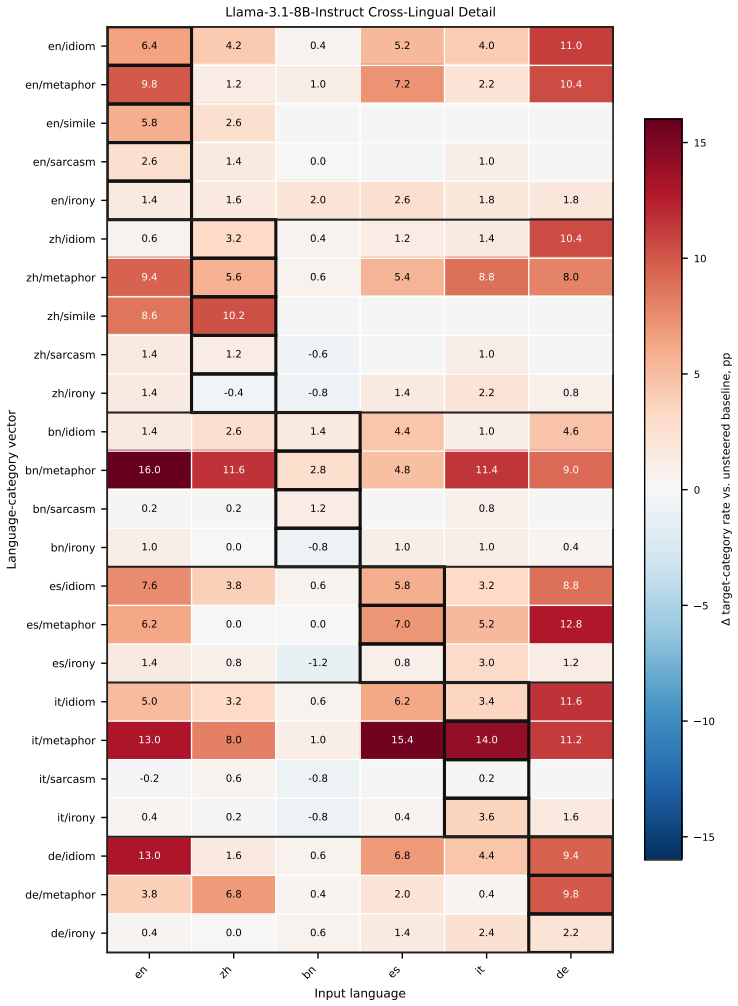
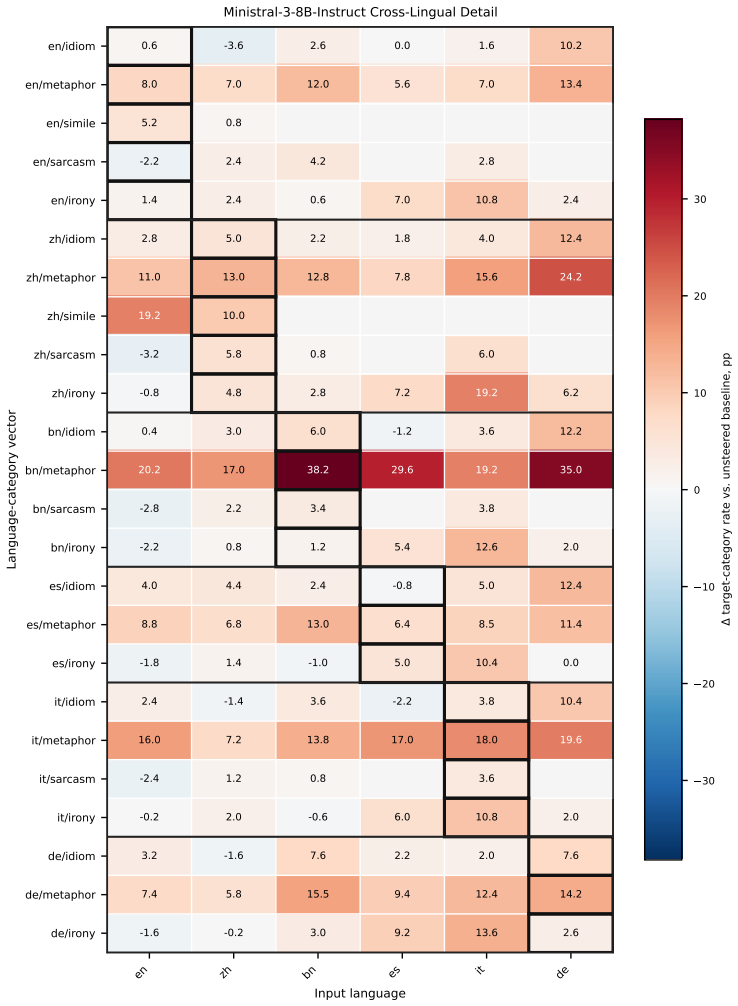
A direction estimated from figurative-minus-literal activation differences in one language steers the same figurative category when added to generation in another language; directions assembled from multiple source languages match or surpass a target language's native direction, while removing the shared component weakens native steering.
What carries the argument
activation steering direction computed from figurative-literal activation differences
If this is right
- Directions transfer across languages and reliably increase the target figurative behavior.
- Assembled directions from other languages can match or exceed a target language's native direction.
- Removing the shared component across languages weakens the effectiveness of native steering.
- Transfer is most robust for metaphor and simile categories.
- German is among the most receptive target languages for incoming directions.
Where Pith is reading between the lines
- Low-resource languages could borrow steering directions from high-resource ones to improve figurative generation without new training data.
- The reusable signal may reflect shared underlying structures in how models represent figurative versus literal meaning.
- Extending the method to additional figurative categories or non-Indo-European languages would test how general the cross-lingual component is.
Load-bearing premise
Differences in activations between figurative and literal generations isolate a causal, language-transferable signal rather than language-specific artifacts or model correlations.
What would settle it
Applying a direction learned from English figurative-literal pairs fails to increase the rate of metaphor or simile outputs when steering German generation, or assembled multi-language directions perform no better than a single native direction.
Figures


read the original abstract
Multilingual large language models can generate figurative language, but whether the internal signals driving this behavior are language-specific or reusable across languages is unclear. Using activation steering as a probe, we estimate a direction for a figurative category from figurative--literal activation differences in one language and apply it during generation. Across five figurative categories, six languages, and four multilingual LLMs, these directions steer reliably within their own language, most robustly for metaphor and simile. More importantly, they transfer across languages: a direction learned in one increases the target behavior when applied to another, with German among the most receptive targets. Going further, directions assembled from other languages can match or even surpass a target language's own native direction, while removing this shared component weakens native steering. Together, these results provide direct evidence of a reusable but target-dependent cross-lingual signal for figurative generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that activation directions computed from figurative-minus-literal differences in one language can be used to steer figurative language generation in other languages. Across five figurative categories, six languages, and four multilingual LLMs, native directions work reliably (especially for metaphor and simile); cross-lingual transfer increases target behavior; directions assembled from other languages can match or exceed a target language's native direction; and ablating the shared component weakens native steering. These results are presented as direct evidence for a reusable but target-dependent cross-lingual signal.
Significance. If the results survive controls for confounds, the work would offer valuable empirical evidence that activation steering can isolate and transfer category-level signals across languages in multilingual LLMs. The breadth of the experimental design (multiple categories, languages, and models) is a clear strength and would make the findings more generalizable than single-language or single-model studies.
major comments (3)
- [Methods / experimental setup] The method for constructing directions (figurative-minus-literal activation differences) does not describe any explicit controls, matching, or regression for generation length, semantic content, syntactic complexity, or lexical bias. This is load-bearing for the central claim that the resulting vector encodes a causal, category-specific, language-transferable figurative signal rather than non-figurative artifacts.
- [Abstract and Results] The abstract and results sections report steering effects across languages and models but provide no information on how steering strength was measured, what baselines or controls were used, or any statistical tests. Without these details the transfer, assembly, and ablation claims cannot be evaluated for reliability or effect size.
- [Ablation experiments] The ablation result (removing the shared component weakens native steering) requires clarification on how the shared component is isolated and whether the procedure controls for changes in vector norm or dimensionality that could produce the observed weakening independently of the cross-lingual interpretation.
minor comments (2)
- [Methods] Clarify the precise definition of each figurative category and the prompt templates used to elicit figurative vs. literal generations.
- [Figures] Add error bars or variance measures to any plots showing cross-lingual transfer performance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the breadth of the experimental design. We address each major comment below, indicating where we agree revisions are needed and where we provide clarification or additional defense based on the manuscript content.
read point-by-point responses
-
Referee: [Methods / experimental setup] The method for constructing directions (figurative-minus-literal activation differences) does not describe any explicit controls, matching, or regression for generation length, semantic content, syntactic complexity, or lexical bias. This is load-bearing for the central claim that the resulting vector encodes a causal, category-specific, language-transferable figurative signal rather than non-figurative artifacts.
Authors: The prompts for figurative and literal examples were constructed to be semantically and structurally matched within each category (e.g., same entities and events described literally vs. figuratively), which reduces but does not eliminate the listed confounds. No explicit regression or matching on length/syntax/lexical bias was performed beyond this design. The cross-lingual transfer and assembly results provide supporting evidence that the directions capture more than language-specific artifacts, as such artifacts would be unlikely to transfer reliably. We will add an explicit limitations paragraph discussing these potential confounds and report basic statistics on prompt length and lexical overlap in the revision. revision: partial
-
Referee: [Abstract and Results] The abstract and results sections report steering effects across languages and models but provide no information on how steering strength was measured, what baselines or controls were used, or any statistical tests. Without these details the transfer, assembly, and ablation claims cannot be evaluated for reliability or effect size.
Authors: The full manuscript details the steering procedure (activation addition with coefficient scaling), measurement via automated figurative classifiers plus human ratings of target behavior rate, baselines including zero-steering and random-vector controls, and statistical tests (paired t-tests over 5 seeds with reported p-values and effect sizes). These were omitted from the abstract for brevity. We will expand the abstract and results summary to include a concise description of measurement, baselines, and significance testing. revision: yes
-
Referee: [Ablation experiments] The ablation result (removing the shared component weakens native steering) requires clarification on how the shared component is isolated and whether the procedure controls for changes in vector norm or dimensionality that could produce the observed weakening independently of the cross-lingual interpretation.
Authors: The shared component was obtained by averaging the native directions across the other five languages and subtracting the result from the target-language direction; all vectors were L2-normalized to unit length both before and after subtraction to control for norm changes. Dimensionality remained identical. We will add a dedicated methods subsection with the exact equations, pre/post-norm values, and a control experiment ablating a random component of matched norm to confirm the weakening is specific to the shared direction. revision: yes
Circularity Check
No circularity: purely empirical activation-steering experiments with no derivations or fitted predictions
full rationale
The paper reports experimental results from applying activation differences (figurative minus literal) as steering vectors across languages and models. No equations, derivations, or parameter-fitting steps are described that could reduce a claimed prediction to its own inputs by construction. All central claims (transfer, assembly, ablation) rest on measured behavioral changes in generation, which are externally falsifiable via the reported metrics rather than self-defined. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. This is a standard empirical study whose validity hinges on experimental controls, not on circular logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Knowledge localization in mixture-of-experts llms using cross-lingual inconsistency.Preprint, arXiv:2603.17102. Lukasz Bartoszcze, Sarthak Munshi, Bryan Sukidi, Jennifer Yen, Zejia Yang, David Williams-King, Linh Le, Kosi Asuzu, and Carsten Maple. 2025. Representation engineering for large-language mod- els: Survey and research challenges.Preprint, arXiv:...
-
[2]
A survey of automatic sarcasm detection: Fundamental theories, formulation, datasets, detec- tion methods, and opportunities.Neurocomputing, 578:127428. Sourav Das and Kripabandhu Ghosh. 2025. Can LLMs be literary companions?: Analysing LLMs on Ben- gali figures of speech identification. InProceedings of the 2025 Conference on Empirical Methods in Natural...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2601.08331 , year=
Clas-bench: A cross-lingual alignment and steering benchmark.Preprint, arXiv:2601.08331. Katharina Hämmerl, Jindˇrich Libovický, and Alexan- der Fraser. 2024. Understanding cross-lingual Alignment—A survey. InFindings of the Associa- tion for Computational Linguistics: ACL 2024, pages 10922–10943, Bangkok, Thailand. Association for Computational Linguisti...
-
[4]
1, pages 980–987, Salvador, Brazil
- Vol. 1, pages 980–987, Salvador, Brazil. As- sociation for Computational Linguistics. Reynier Ortega-Bueno, Francisco Rangel, Delia Irazú Hernández Farías, Paolo Rosso, Manuel Montes-y Gómez, and José E. Medina-Pagola. 2019. Overview of the task on irony detection in spanish variants. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 201...
2019
-
[5]
WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia
Large scale datasets for image and video cap- tioning in italian.Italian Journal of Computational Linguistics, 2(5):49–60. Holger Schwenk, Vishrav Chaudhary, Shuo Sun, Hongyu Gong, and Francisco Guzmán. 2019. Wikimatrix: Mining 135m parallel sentences in 1620 language pairs from wikipedia.Preprint, arXiv:1907.05791. Uliana Sentsova, Debora Ciminari, Josef...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Steering Language Models With Activation Engineering
IMPLI: Investigating NLI models’ perfor- mance on figurative language. InProceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 5375–5388, Dublin, Ireland. Association for Compu- tational Linguistics. Eshaan Tanwar, Subhabrata Dutta, Manish Borthakur, and Tanmoy Chakraborty. 2023. Multiling...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
InProceedings of the 12th Interna- tional Workshop on Semantic Evaluation, New Or- leans, Louisiana
SemEval-2018 task 3: Irony detection in En- glish tweets. InProceedings of the 12th Interna- tional Workshop on Semantic Evaluation, New Or- leans, Louisiana. Association for Computational Lin- guistics. Hetong Wang, Pasquale Minervini, and Edoardo Ponti
2018
-
[8]
InFindings of the As- sociation for Computational Linguistics: ACL 2024, pages 12159–12173, Bangkok, Thailand
Probing the emergence of cross-lingual align- ment during LLM training. InFindings of the As- sociation for Computational Linguistics: ACL 2024, pages 12159–12173, Bangkok, Thailand. Association for Computational Linguistics. Mingyang Wang, Heike Adel, Lukas Lange, Yihong Liu, Ercong Nie, Jannik Strötgen, and Hinrich Schuetze
2024
-
[9]
Lost in multilinguality: Dissecting cross- lingual factual inconsistency in transformer language models. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5075–5094, Vienna, Austria. Association for Computational Linguistics. Zhiyuan Wen, Rui Wang, Qianlong Wang, Lin Gui, Yunfei Long...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
A black-and-white dog stands on the grass
to control the false discovery rate within each model–intervention-family set. For pooled summaries, correction is applied within the dis- played comparison family. B.3 Detector prompt definitions Table 17 shows the shared detector instruction and definitions for the evaluated language–category cells. In addition to target-category detection, we evaluate ...
2019
-
[11]
The input text is written in the evaluation language
Goal Your job is to decide whether the input text contains the TARGET CATEGORY . The input text is written in the evaluation language. All detectors
-
[12]
- The same text may contain multiple figurative categories at once
Core labeling principle - Categories are NOT mutually exclusive. - The same text may contain multiple figurative categories at once. - For this task, check ONLY whether the TARGET CATEGORY is present. - Output YES if the TARGET CATEGORY is present anywhere in the text. - Output NO if the TARGET CATEGORY is absent. All detectors
-
[13]
- Do not assume missing context
Evidence scope - Judge only from the given text unless extra context is explicitly provided. - Do not assume missing context. - Do not infer hidden intent unless it is reasonably supported by the text. All detectors
-
[14]
- Do not list multiple possible answers
Ambiguity policy - Do not ask follow-up questions. - Do not list multiple possible answers. - Make the best single decision from the text alone. - If the case is uncertain, output YES only when there is clear textual evidence for the TARGET CATEGORY; otherwise output NO. All detectors
-
[15]
spill the beans
Output rule Output exactly 2 lines and nothing else: Reason: <one short sentence> Label: <YES or NO> English (en) Idiom Definition An idiom is a conventionalized, multi-word expression whose intended meaning cannot be fully derived from the literal meanings of its individual words. It acts as its own established explanation to convey ideas implicitly. Thi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.