Bounded Behavioral Indistinguishability for Black-Box LLM Distillation
Pith reviewed 2026-06-29 08:48 UTC · model grok-4.3
The pith
Black-box LLM distillation improves semantic similarity but leaves measurable behavioral differences detectable by adversaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
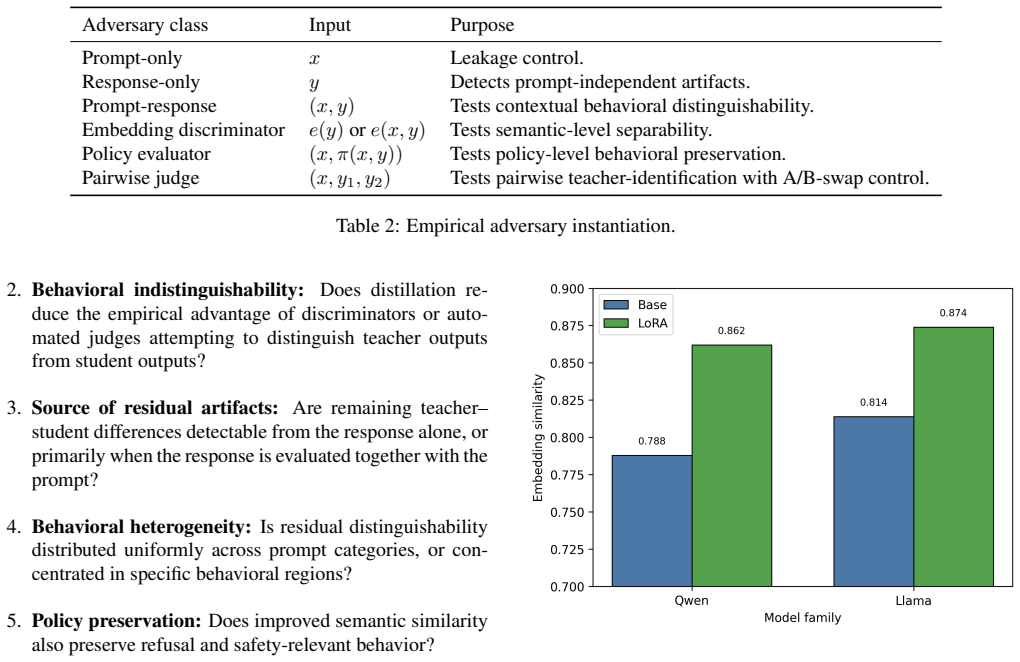
Semantic fidelity is useful but insufficient for black-box LLM distillation; evaluation instead requires bounded, adversarial, and category-aware measures of behavioral indistinguishability, because even after LoRA adaptation the student models retain detectable differences from their teachers on the probe suite.
What carries the argument
The (ε,q,t,𝔸)-behavioral indistinguishability definition over an explicit prompt distribution, operationalized through a controlled 5,000-prompt behavioral probe suite and pairwise teacher-identification adversaries.
Load-bearing premise
The controlled 5,000-prompt behavioral probe suite and chosen adversary class are representative enough to detect meaningful behavioral differences that matter in practice.
What would settle it
An experiment in which a distilled student achieves distinguishing advantage below a chosen ε threshold across all tested categories and adversary classes on the same probe distribution would falsify the claim that semantic measures alone are insufficient.
Figures


read the original abstract
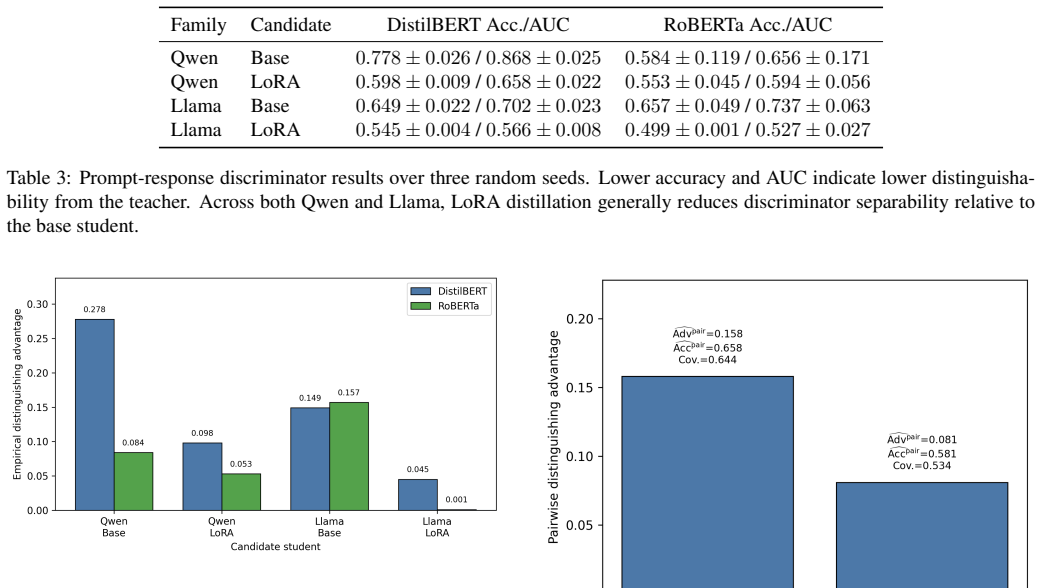
Black-box LLM distillation is usually evaluated as an output-matching problem: a student is considered successful when its responses are semantically similar to, or task-consistent with, those of a teacher. However, output similarity does not imply that the student is behaviorally indistinguishable from the model it imitates. We introduce bounded behavioral indistinguishability, formalized as $(\epsilon,q,t,\mathbb{A})$-behavioral indistinguishability over an explicit prompt distribution, where $\epsilon$ bounds distinguishing advantage, $q$ bounds oracle queries, $t$ bounds computation, and $\mathbb{A}$ denotes the adversary class. We instantiate this notion on Qwen and Llama teacher-student pairs using a controlled $5,000$-prompt behavioral probe suite. For each family, we compare the teacher with both the base student and the LoRA-distilled student, measuring whether distillation reduces distinguishability rather than merely improving similarity. LoRA raises semantic similarity from $0.788$ to $0.862$ for Qwen and from $0.814$ to $0.874$ for Llama. Yet adversarial evaluation reveals remaining behavioral differences: learned discriminators retain nonzero advantage, and pairwise category analysis shows artifacts concentrated in style/format, robustness, and domain-technical prompts. A pairwise teacher-identification adversary confirms this trend. With a different-family Llama judge and A/B-swap consistency filtering, Qwen distinguishing advantage drops from $0.158$ for the base student to $0.081$ after LoRA distillation. Query-budget experiments show that disagreement-guided acquisition does not consistently outperform stratified random sampling, indicating that coverage and diversity remain strong baselines. Our results show that semantic fidelity is useful but insufficient: black-box LLM distillation requires bounded, adversarial, and category-aware evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic similarity metrics are insufficient for evaluating black-box LLM distillation success and introduces a parameterized notion of bounded behavioral indistinguishability, formalized as (ε, q, t, A)-behavioral indistinguishability over an explicit prompt distribution. Using a controlled 5,000-prompt behavioral probe suite on Qwen and Llama teacher-student pairs, it shows that LoRA distillation improves semantic similarity (0.788→0.862 for Qwen; 0.814→0.874 for Llama) but leaves nonzero distinguishing advantage under learned discriminators, pairwise category analysis, and a teacher-identification adversary (e.g., 0.158→0.081 for Qwen with Llama judge). The conclusion is that distillation evaluation requires bounded, adversarial, and category-aware methods rather than relying on output similarity alone.
Significance. If the probe suite and adversary class are representative, the work supplies a clean, query- and compute-bounded formalization that could shift evaluation practices in LLM distillation away from purely semantic metrics toward adversarial testing. The explicit parameterization (with no free parameters in the definition itself) and the empirical demonstration that similarity gains do not imply indistinguishability on two model families are concrete strengths that could support more falsifiable claims about distillation quality.
major comments (2)
- [Abstract] Abstract, instantiation paragraph: the central claim that 'semantic fidelity is useful but insufficient' and that black-box distillation 'requires bounded, adversarial, and category-aware evaluation' rests on the 5,000-prompt suite and adversary class A being adequate to detect practically relevant behavioral differences; the manuscript provides no justification, coverage analysis, or validation that this suite densely samples prompt distributions on which downstream differences would matter or that A is the strongest feasible distinguisher within the stated (q, t) bounds.
- [Abstract] Abstract, results on distinguishing advantage: the reported drop from 0.158 to 0.081 (and the category artifacts in style/format, robustness, domain-technical prompts) is tied to the specific (5,000-prompt, learned-discriminator, Llama-judge) instantiation; without evidence that the probe does not systematically under-sample categories where the distilled model already matches the teacher, the observed gap between similarity and indistinguishability may be an artifact of the chosen suite rather than generic evidence against semantic evaluation.
minor comments (2)
- [Abstract] Abstract: no error bars, confidence intervals, or statistical details are reported for the similarity scores or distinguishing advantages, making it difficult to assess the reliability of the reported deltas.
- [Abstract] Abstract: the query-budget experiments are mentioned but lack any table or quantitative comparison showing how disagreement-guided acquisition compares to stratified random sampling across the two model families.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and commit to revisions that strengthen the justification for our evaluation setup.
read point-by-point responses
-
Referee: Abstract, instantiation paragraph: the central claim that 'semantic fidelity is useful but insufficient' and that black-box distillation 'requires bounded, adversarial, and category-aware evaluation' rests on the 5,000-prompt suite and adversary class A being adequate to detect practically relevant behavioral differences; the manuscript provides no justification, coverage analysis, or validation that this suite densely samples prompt distributions on which downstream differences would matter or that A is the strongest feasible distinguisher within the stated (q, t) bounds.
Authors: We agree that explicit justification and coverage details would strengthen the claims. The 5,000-prompt suite was stratified across categories drawn from prior LLM evaluation literature (style/format, robustness, domain-technical) to promote diversity, with results replicated across Qwen and Llama families. We did not claim A is maximal or provide quantitative coverage metrics. In revision we will expand the methods section with prompt curation details, category distribution statistics, and an explicit limitations paragraph on the scope of the distribution and adversary class. This will better ground the parameterized claim that semantic similarity alone does not imply indistinguishability under the tested (q, t, A). revision: yes
-
Referee: Abstract, results on distinguishing advantage: the reported drop from 0.158 to 0.081 (and the category artifacts in style/format, robustness, domain-technical prompts) is tied to the specific (5,000-prompt, learned-discriminator, Llama-judge) instantiation; without evidence that the probe does not systematically under-sample categories where the distilled model already matches the teacher, the observed gap between similarity and indistinguishability may be an artifact of the chosen suite rather than generic evidence against semantic evaluation.
Authors: The nonzero distinguishing advantage is corroborated by three independent methods (learned discriminators, category-wise pairwise analysis, and teacher-identification adversary) and is consistent across two model families. The category analysis already localizes remaining artifacts rather than claiming uniform gaps. While a full sensitivity study on every possible category is absent, the convergent evidence across methods reduces the likelihood of a pure sampling artifact. In revision we will add a short discussion of prompt diversity and potential under-sampling risks, while clarifying that the results demonstrate insufficiency of semantic metrics in this controlled, bounded setting. revision: partial
Circularity Check
No circularity: definition introduced independently and results are direct empirical comparisons
full rationale
The paper defines bounded behavioral indistinguishability as a new parameterized notion (ε,q,t,A) over an explicit prompt distribution without deriving it from any prior fitted quantities or self-referential equations. Experiments consist of direct measurements on a fixed 5,000-prompt suite comparing base and LoRA students against teachers, reporting similarity scores and distinguishing advantages without any step that renames a fit as a prediction or reduces a claimed result to its own inputs by construction. No load-bearing self-citations or uniqueness theorems appear in the provided text. The derivation chain is therefore self-contained as an empirical instantiation of an independently stated definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 5,000-prompt suite and adversary class A suffice to measure whether distillation reduces behavioral distinguishability.
Reference graph
Works this paper leans on
-
[1]
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test, 2025
Xiaoyuan Zhu, Yaowen Ye, Tianyi Qiu, Hanlin Zhu, Si- jun Tan, Ajraf Mannan, Jonathan Michala, Raluca Ada Popa, and Willie Neiswanger. Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test, 2025
2025
-
[2]
Black-box Optimization of LLM Outputs by Asking for Directions, 2025
Jie Zhang, Meng Ding, Yang Liu, Jue Hong, and Flo- rian Tram `er. Black-box Optimization of LLM Outputs by Asking for Directions, 2025
2025
-
[3]
Beyond Indis- tinguishability: Measuring Extraction Risk in LLM APIs,
Ruixuan Liu, David Evans, and Li Xiong. Beyond Indis- tinguishability: Measuring Extraction Risk in LLM APIs,
-
[4]
IEEE Symposium on Security and Privacy (S&P) 2026
2026
-
[5]
Accessed: May 2026
Qwen.https://github.com/QwenLM. Accessed: May 2026
2026
-
[6]
Accessed: May 2026
Llama.https://www.llama.com/. Accessed: May 2026
2026
-
[7]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. LoRA: Low-Rank Adaptation of Large Lan- guage Models.ICLR, 1(2):3, 2022.https://doi. org/10.48550/arXiv.2106.09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2022
-
[8]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the Knowledge in a Neural Network.arXiv preprint arXiv:1503.02531, 2015.https://doi.org/10. 48550/arXiv.1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
TinyBERT: Distilling BERT for Natural Language Understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: Distilling BERT for Natural Language Understanding. In Findings of the association for computational linguis- tics: EMNLP 2020, pages 4163–4174, 2020.https: //doi.org/10.48550/arXiv.1909.10351
-
[11]
MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge Distillation of Large Language Models. InProceedings of ICLR, 2024
2024
-
[12]
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se- Young Yun. DISTILLM: Towards Streamlined Dis- tillation for Large Language Models.arXiv preprint arXiv:2402.03898, 2024.https://doi.org/10. 48550/arXiv.2402.03898
-
[13]
Stealing machine learning mod- els via prediction{APIs}
Florian Tram `er, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning mod- els via prediction{APIs}. In25th USENIX security sym- posium (USENIX Security 16), pages 601–618, 2016
2016
-
[14]
High Accuracy and High Fidelity Extraction of Neural Networks
Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, and Nicolas Papernot. High Accuracy and High Fidelity Extraction of Neural Networks. In 29th USENIX security symposium (USENIX Security 20), pages 1345–1362, 2020.https://doi.org/10. 48550/arXiv.1909.01838
-
[15]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sen- tence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 conference on empirical meth- ods in natural language processing and the 9th interna- tional joint conference on natural language processing (EMNLP-IJCNLP), pages 3982–3992, 2019.https: //doi.org/10.48550/arXiv.1908.10084
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1908.10084 2019
-
[16]
Probabilistic en- cryption & how to play mental poker keeping secret all partial information
Shafi Goldwasser and Silvio Micali. Probabilistic en- cryption & how to play mental poker keeping secret all partial information. InProviding sound foundations for cryptography: on the work of Shafi Goldwasser and Sil- vio Micali, pages 173–201. 2019
2019
-
[17]
Simplifying Game- Based Definitions Indistinguishability up to Correctness and Its Application to Stateful AE
Phillip Rogaway and Yusi Zhang. Simplifying Game- Based Definitions Indistinguishability up to Correctness and Its Application to Stateful AE. InAnnual Inter- national Cryptology Conference, pages 3–32. Springer, 2018
2018
-
[18]
Sequences of games: A Tool for Taming Complexity in Security Proofs.cryptology eprint archive, 2004
Victor Shoup. Sequences of games: A Tool for Taming Complexity in Security Proofs.cryptology eprint archive, 2004
2004
-
[19]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuo- han Li, Dacheng Li, Eric Xing, et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Advances in neural information processing systems, 36:46595–46623, 2023.https://doi.org/10. 48550/arXiv.2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Tian Lan, Wenwei Zhang, Chen Xu, Heyan Huang, Dahua Lin, Kai Chen, and Xian-ling Mao. CriticE- val: Evaluating Large Language Model as Critic.arXiv preprint arXiv:2402.13764, 2024.https://doi. org/10.48550/arXiv.2402.13764
-
[21]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal ´azs Galambosi, Percy Liang, and Tat- sunori B Hashimoto. Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators.arXiv preprint arXiv:2404.04475, 2024.https://doi. org/10.48550/arXiv.2404.04475
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.04475 2024
-
[22]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI Feed- back.arXiv preprint arXiv:2212.08073, 2022.https: //doi.org/10.48550/arXiv.2212.08073
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073 2022
-
[23]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with hu- man feedback.Advances in neural information process- ing systems, 35:27730–27744, 2022.https://doi. org/10.48550/arXiv.2203.02155
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155 2022
-
[24]
Incompleteness of AI Safety Verification via Kolmogorov Complexity
Munawar Hasan. Incompleteness of AI Safety Veri- fication via Kolmogorov Complexity.arXiv preprint arXiv:2604.04876, 2026.https://doi.org/10. 48550/arXiv.2604.04876
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Active Learning Literature Survey
Burr Settles. Active Learning Literature Survey . 2009
2009
-
[26]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active Learning for Convolutional Neural Networks: A Core-Set Approach. arXiv preprint arXiv:1708.00489, 2017.https:// doi.org/10.48550/arXiv.1708.00489
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1708.00489 2017
-
[27]
Knowledge Distil- lation via Query Selection for Detection Transformer
Yi Liu, Luting Wang, Zongheng Tang, Yue Liao, Yi- fan Sun, Lijun Zhang, and Si Liu. Knowledge Distil- lation via Query Selection for Detection Transformer. arXiv preprint arXiv:2409.06443, 2024.https:// doi.org/10.48550/arXiv.2409.06443
-
[28]
Minghan Li and Guodong Zhou. Retrieval-Feedback- Driven Distillation and Preference Alignment for Ef- ficient LLM-based Query Expansion.arXiv preprint arXiv:2603.13776, 2026.https://doi.org/10. 48550/arXiv.2603.13776
-
[29]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettle- moyer, and Veselin Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[30]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019. 15
work page internal anchor Pith review Pith/arXiv arXiv 1910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.